こんな記事も書いてます
【忙しい人向けシリーズ】ニュースを30秒で呼ぶために構文解析で要約してみた
TL;DR
パソコンだって人間と一緒に早押しクイズに参加できる...(はず)
概要
NTTコミュニケーションズが提供している 自然言語処理・音声処理APIプラットフォームCOTOHA API を使って**クイズをパソコンに解かせてみた!**という内容です。
「パソコンにクイズ?」
「そんなの普通に検索すればできるやんけ」
「何をいまさら。あほなん??」
そう思った方も少なからずいるでしょう。しかし、実際に私たちが検索をする際には、不要な助詞などを省いて検索している場合がほとんどです。
例えば、このような問題が与えられたとします。
「"エッセイも人気だったが、ガンで53歳で亡くなったちびまるこちゃんの作者といえばだれ?"」
ネットで検索するときには、このように検索したりしませんか?
「ちびまる子ちゃん 作者」
「エッセイスト ガン 53歳」
人間にとってはどの単語が重要でどの単語が不要なのかが、なんとなくで分かりますが、パソコンにはそんなこと分かったもんじゃありません。
それを今回は自然言語処理を使って、パソコンにも人間と同じような問題文を与えて回答できるのかどうかを試してみたいと思います!
PCに問題を解かせるまで
今回作成するコードを先に掲載しておきます。折り畳み式になっているので、展開してご覧ください。
サンプルコード
import requests
import json
import sys
from urllib import parse
from bs4 import BeautifulSoup
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
})
def Search(self, keyword, type = 'text', maximum = 3):
'''Google検索'''
# print('Google', type.capitalize(), 'Search :', keyword)
result, total = [], 0
query = self.query_gen(keyword, type)
while True:
# 検索
html = self.session.get(next(query)).text
links = self.get_links(html, type)
# 検索結果の追加
if not len(links):
print('-> No more links')
break
elif len(links) > maximum - total:
result += links[:maximum - total]
break
else:
result += links
total += len(links)
return result
def query_gen(self, keyword, type):
'''検索クエリジェネレータ'''
page = 0
while True:
if type == 'text':
params = parse.urlencode({
'q': keyword,
'num': '100',
'filter': '0',
'start': str(page * 100)
})
elif type == 'image':
params = parse.urlencode({
'q': keyword,
'tbm': 'isch',
'filter': '0',
'ijn': str(page)
})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
def get_links(self, html, type):
'''リンク取得'''
soup = BeautifulSoup(html, 'html5lib')
if type == 'text':
elements = soup.select('.rc > .r > a')
links = [e['href'] for e in elements]
elif type == 'image':
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
links = [js['ou'] for js in jsons]
return links
class WebSite:
def __init__(self, url):
self.session = requests.session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
})
html = self.session.get(url).text
self.soup = BeautifulSoup(html, 'html5lib')
def get_title(self):
return self.soup.find('title').text
def get_titles(self, urls):
for url in urls:
html = self.session.get(url).text
self.soup = BeautifulSoup(html, 'html5lib')
print(self.soup.find('title').text)
class Cotoha:
BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/"
CLIENT_ID = "YOUR_CLIENT_ID"
CLIENT_SECRET = "YOUR_CLIENT_SECRET"
ACCESS_TOKEN = ""
def auth(self):
token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
headers = {
"Content-Type": "application/json",
"charset": "UTF-8"
}
data = {
"grantType": "client_credentials",
"clientId": self.CLIENT_ID,
"clientSecret": self.CLIENT_SECRET
}
r = requests.post(
token_url,
headers = headers,
data = json.dumps(data)
)
self.ACCESS_TOKEN = r.json()["access_token"]
return
def parser(self, sentence):
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(self.ACCESS_TOKEN)
}
data = {
"sentence": sentence,
"type": "default"
}
r = requests.post(
self.BASE_URL + "v1/parse",
headers = headers,
data = json.dumps(data)
)
return r.json()
if __name__ == '__main__':
google = Google()
cotoha = Cotoha()
cotoha.auth()
result_sentence = ""
questions = [
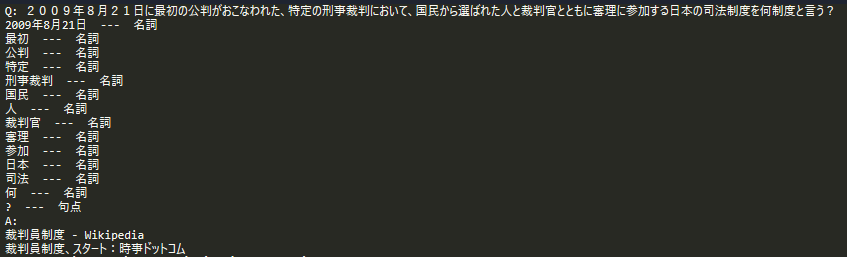
"2009年8月21日に最初の公判がおこなわれた、特定の刑事裁判において、国民から選ばれた人と裁判官とともに審理に参加する日本の司法制度を何制度と言う?",
"エッセイも人気だったが、ガンで53歳で亡くなったちびまるこちゃんの作者といえばだれ?",
"直訳すると「ペラペラ円盤」。パソコンでデータを保存する時に使うものといえば何?",
"硬式テニスで0点のことを2文字で何と言うでしょう?"
]
for question in questions:
print("Q: {}".format(question))
parse_result = cotoha.parser(question)
for chunks in parse_result["result"]:
for token in chunks["tokens"]:
if token["pos"] in ["形容詞語幹", "名詞", "句点", "連体", "助数詞", "Number"]:
print("{} --- {}".format(token["lemma"], token["pos"]))
result_sentence += token["lemma"] + " "
search_result = google.Search(result_sentence, type='text')
website = WebSite(search_result[0])
print("A:")
website.get_titles(search_result)
準備
今回はこのような環境で行いました。
- Python3
- COTOHA API
- Windows10
- Sublime Text3
COTOHA APIを利用するためにはCOTOHA API 無償アカウント for Developers に登録する必要があります。
登録が完了すると、マイページに「CLIENT ID」「CLIENT SECRET」が記載されているので、ソース内に記載してください。
今回はソースコードの主要部分だけの解説になります。詳しい説明が必要な場合は、コメント等でお知らせください。
構文解析部分
def parser(self, sentence):
headers = {
"Content-Type": "application/json",
"charset": "UTF-8",
"Authorization": "Bearer {}".format(self.ACCESS_TOKEN)
}
data = {
"sentence": sentence,
"type": "default"
}
r = requests.post(
self.BASE_URL + "v1/parse",
headers = headers,
data = json.dumps(data)
)
return r.json()
:
:(省略)
:
if __name__ == '__main__':
parse_result = cotoha.parser("私は猫になりたい。")
print(parse_result)
headers, data の中身については、COTOHA API の公式リファレンスに詳細が書いてあるので、参照してください。
data = {
"sentence": sentence,
"type": "default"
}
今回与えるクイズの文は、一般的な文であり、体裁が著しく崩れていないのでtypeはdefaultとしてあります(省略時は自動でdefaultが指定されます)。この他にkuzureというtypeが存在しますが、SNSなどで使われる崩れた文を解析する際に指定します。
単語抽出
result_sentence = ""
for chunks in parse_result["result"]:
for token in chunks["tokens"]:
if token["pos"] in ["形容詞語幹", "名詞", "句点", "連体", "助数詞", "Number"]:
print("{} --- {}".format(token["lemma"], token["pos"]))
result_sentence += token["lemma"] + " "
今回は構文解析後の結果から、助詞などを省いて「"形容詞語幹", "名詞", "句点", "連体", "助数詞", "Number"」だけを抽出するようにしました。Googleで検索を行う際に、助詞などが変に含まれていると正常に検索できないので、省きました。
Google検索
Google検索に関するClassは少し長いので、展開して見てください。
Google Class コード
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'
})
def Search(self, keyword, type = 'text', maximum = 3):
'''Google検索'''
# print('Google', type.capitalize(), 'Search :', keyword)
result, total = [], 0
query = self.query_gen(keyword, type)
while True:
# 検索
html = self.session.get(next(query)).text
links = self.get_links(html, type)
# 検索結果の追加
if not len(links):
print('-> No more links')
break
elif len(links) > maximum - total:
result += links[:maximum - total]
break
else:
result += links
total += len(links)
return result
def query_gen(self, keyword, type):
'''検索クエリジェネレータ'''
page = 0
while True:
if type == 'text':
params = parse.urlencode({
'q': keyword,
'num': '100',
'filter': '0',
'start': str(page * 100)
})
elif type == 'image':
params = parse.urlencode({
'q': keyword,
'tbm': 'isch',
'filter': '0',
'ijn': str(page)
})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
def get_links(self, html, type):
'''リンク取得'''
soup = BeautifulSoup(html, 'html5lib')
if type == 'text':
elements = soup.select('.rc > .r > a')
links = [e['href'] for e in elements]
elif type == 'image':
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
links = [js['ou'] for js in jsons]
return links
google = Google()
search_result = google.Search(result_sentence, type='text')
使い方としては、Googleのクラスをインスタンス化します。検索にはSearchメソッドを使います。第1引数は検索したい文字列, 第2引数のtypeにはtext, imageを選択することができます。今回の場合は普通に検索するのでtextを指定します。
サイトタイトルを取得
class WebSite:
def __init__(self):
self.session = requests.session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_32; rv:57.0) Gecko/20100101 Firefox/57.0'
})
def get_title(self, url):
html = self.session.get(url).text
soup = BeautifulSoup(html, 'html5lib')
return soup.find('title').text
def get_titles(self, urls):
for url in urls:
html = self.session.get(url).text
soup = BeautifulSoup(html, 'html5lib')
print(soup.find('title').text)
:
:
:
website = WebSite()
website.get_titles(search_result)
Google検索によって得られたURLから、サイトのタイトルを取得していきます。サイトのタイトル取得にはBeautifulSoupを使います。サイトにtitleタグが存在するはずなので、titleタグを取得してそれを表示します。
get_titleは与えられたURLから、get_titlesはURLの配列を引数としていて、すべてのURLのタイトルを取得します。
問題を解かせる
今回の正誤判定基準は以下のようにしました。
- 問題に対して検索結果を上位3つ表示
- 上位3つ分のサイトのタイトルを表示
- そのどれかに問題の答えが記載されていれば正解とする
今回解かせた問題と結果はこちら
-
2009年8月21日に最初の公判がおこなわれた、特定の刑事裁判において、国民から選ばれた人と裁判官とともに審理に参加する日本の司法制度を何制度と言う?(答:裁判員制度)
-
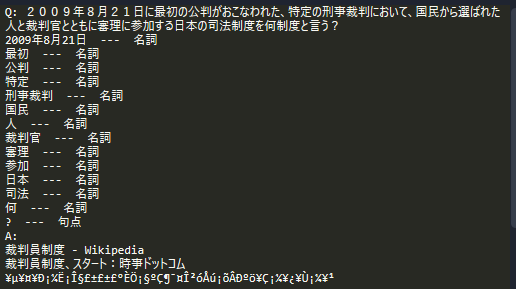
日本列島を囲む4つの海は東シナ海、オホーツク海、太平洋とあと1つは何?(答:日本海)
-
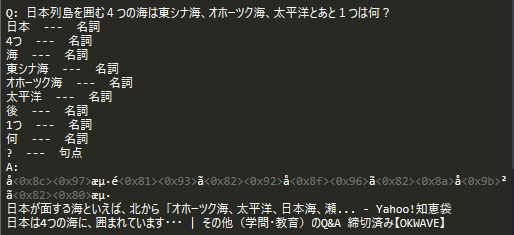
幕末の志士「新撰組」の旗に記された漢字1文字は何?(答:誠)
-
日が照っているのに雨が降る天気のことを何の嫁入りと言うでしょう?(答:狐の嫁入り)
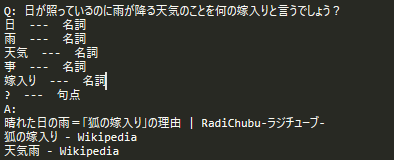
まとめ
実際に問題を解かせてみた結果、割といい感じに回答が出ていました。が、文字化けとかに関しては考慮してないので、そこらへんも考慮する必要がありますが、結果的にはいい感じになったのではないでしょうか!!