初めに
こちらの記事などでを紹介していきましたが、ファイルを読み込んだ後には当然、何かしらの処理を行うと思います。
- GeoPandasをやるならFlatGeobufより10倍早いGeoParquetを使おう!
- GeoPandas(GeoDataFrame)のread/writeなら1000万レコードを10秒で読み込めるpyogrioを使って高速に行おう!
大きなデータを処理する際に、数十GB級のデータだとデータの読み込み自体を高速で完了させたとしても、空間検索に膨大な時間を要したり、そもそもデータがメモリに乗り切らず処理できないということもあるでしょう。
こんな時には分散・並列処理などを行うのが一般的ですが、GISデータでそれを行うためのパッケージが存在しています。
daskは、numpy配列やPandasDataFrameと互換性のある、並列化されたDataFrameを作成し分散処理を行うことができるパッケージですが、dask-geopandasはGeoDataFrameでそれを可能にします。
dask-geopandas: https://dask-geopandas.readthedocs.io/en/latest/index.html
dask-geopandasを利用して大規模データを処理する
dask-geopandasのインストール
例の如く、利用までの環境は以下を参考にしてみてください。
- MacでGISデータ分析を始めるためにサクッとAnacondaとjupyter labをインストールしてみる
- jupyter labで最低限これだけは入れとけっていう拡張機能の紹介!
- Pythonで地理空間情報(GIS)やるために必要なパッケージ全部入りの「geospatial」が便利すぎた
上記で紹介している「geospatial」パッケージをインストールすれば、同時にdask-geopandasもインストールされます。
dask-geopandasを利用してみる
まず原則として、書き込み・読み込みの両方がサポートされているのはfeatherとparquetのみで、従来のGISファイルは読み込むことはできますが、書き込みはできません。
ただ、dask-geopandasで作ったGeoDataFrameは通常のGeoDataFrameに変換することも可能ですし、GeoDataFrameをdask-geopandasのGeoDataFrameに変換することも可能ですので、I/O処理にはさほど困らないかと思います。
また、daskで作成したDataFrameや通常のpandasで作成したDataFrameなども柔軟に取り込むことができます。
上記を踏まえた上で、早速dask-geopandasを利用して分散GeoDataFrameを作成してみましょう。
dask-geopandasで大規模な空間演算を行っているブログ記事がありましたので、こちらを参考にして同じようなことをやってみましょう。
Dask-GeoPandas vs PostGIS vs GPU: Performance and Spatial Joins: https://martinfleischmann.net/dask-geopandas-vs-postgis-vs-gpu-performance-and-spatial-joins/
必要なデータをダウンロード
まずは必要なパッケージをインポートします。
import subprocess
import dask.dataframe
import dask_geopandas
import download
import geopandas
from dask.distributed import Client, LocalCluster
ポイント情報の載ったcsvと、その周辺のポリゴンをダウンロードしましょう。
csvの方は1.2GB超あるので通信量制限のあるネット環境の方はお気をつけください。
# 約900万レコード・1.2GBのcsv
subprocess.run(
"curl 'https://phl.carto.com/api/v2/sql?filename=parking_violations&format=csv&skipfields=cartodb_id,the_geom,the_geom_webmercator&q=SELECT%20*%20FROM%20parking_violations%20WHERE%20issue_datetime%20%3E=%20%272012-01-01%27%20AND%20issue_datetime%20%3C%20%272017-12-31%27' > phl_parking.csv",
shell=True,
)
# 上記csvの地物の周辺にある158ポリゴン
download.download(
"https://github.com/azavea/geo-data/raw/master/Neighborhoods_Philadelphia/Neighborhoods_Philadelphia.zip",
"Neighborhoods_Philadelphia",
kind="zip",
)
クライアントの設定
daskは利用するcpu数などの設定が可能です。
私は8コアのマシンを使っているので、その半分くらいを割り当てましたが、みなさんお好みでお選びください。(特に指定しなければいい感じのCPUすうが割り当てられると思います。)
# クライアントは8コアのマシンを使っているので半分の4つくらいで
client = Client(LocalCluster(n_workers=4, threads_per_worker=1))
daskとdask-geopandasにデータを読み込ませていく
csvのデータをまずはdaskのDataFrameに読み込ませていきましょう。
daskはblocksize(bytes)を指定することで、元のデータ(今回であればcsv)を内部で分割して保持することができます。
また、assume_missingをTrueにするとdtypeを指定していない場合、欠損値を含むデータとして整数列はfloatに変換されます。
デフォルトはFalseですので、お好みで指定しましょう。
%%time
# 25MBごとに1つのパーティションに区切る
# カラム名が指定されていないものはfloatとして扱う
# まずはdaskでcsvを読み込み、DataFrameを作成する
ddf = dask.dataframe.read_csv(
"phl_parking.csv", blocksize=25000000, assume_missing=True
)
# CPU times: user 13.2 ms, sys: 5.41 ms, total: 18.6 ms
# Wall time: 17.2 ms
データを読み込むと11msで完了していることがわかります。とても早いですね。
1.2GB弱のデータを25MBのブロックで区切ったので、パーティションは47個できました。
%%time
# 47のパーティションに区切られた
ddf.npartitions
# CPU times: user 6 µs, sys: 0 ns, total: 6 µs
# Wall time: 11 µs
# 47
このようなデータになっています。
ddf.head()
# anon_ticket_number issue_datetime state anon_plate_id division location violation_desc fine issuing_agency lat lon gps zip_code
# 0 1777797.0 2013-08-22 12:36:00 PA 878255.0 1.0 212 N 12TH ST EXPIRED INSPECTION 41.0 PPA 39.956252 -75.158937 False 19107.0
# 1 1777798.0 2013-09-23 21:52:00 PA 878255.0 1.0 900 RACE ST METER EXPIRED CC 36.0 PPA 39.955233 -75.154730 False 19107.0
# 2 1777799.0 2013-11-23 12:25:00 NJ 328900.0 1.0 5448 GERMANTOWN AVE METER EXPIRED 26.0 PPA 40.034175 -75.172386 False 19144.0
# 3 1777800.0 2013-01-18 22:56:00 NJ 244961.0 NaN 400 SPRINGGA METER EXPIRED CC 36.0 PPA NaN NaN NaN NaN
# 4 1777801.0 2013-05-17 12:11:00 PA 665834.0 1.0 1000 FILBERT ST METER EXPIRED CC 36.0 PPA 39.952661 -75.157291 False 19107.0
レコード数を確認すると940万レコード超あることがわかります。
len(ddf)
# 9412119
続いて、csvのlat/lonの列を利用してgeometryに変換していきましょう。
%%time
# csvからx座標とy座標をもつカラムを取得し、geometryとして割り当てる
ddf = ddf.set_geometry(dask_geopandas.points_from_xy(ddf, x="lon", y="lat", crs=4326))
# CPU times: user 26.6 ms, sys: 5.98 ms, total: 32.6 ms
# Wall time: 39.3 ms
そのままポリゴンも読み込みましょう。
%%time
# shapefileからポリゴンのGeoDataFrameを作成
neigh = geopandas.read_file("Neighborhoods_Philadelphia").to_crs(4326)
# CPU times: user 57.7 ms, sys: 17.3 ms, total: 75 ms
# Wall time: 117 ms
空間結合してみる
読み込みが完了したらwithinを利用してポリゴン内部のデータだけ取り出してみましょう。
%%time
# ポリゴン内部のポイントだけ取り出す
joined = dask_geopandas.sjoin(ddf, neigh, predicate="within")
# CPU times: user 18.4 ms, sys: 3.02 ms, total: 21.4 ms
# Wall time: 23.8 ms
おや?と思った方もいるかもしれませんが、いくらdaskが早いって言ったって4コアCPUで900万行 × 158行の空間結合を行うにしては早すぎますね。
daskではメソッドを実行した段階で処理が実行されることはなく、タスクとして積み上がっていきます。
そして以下のようにcomputeメソッドを実行した時に積み上がったタスクを処理します。(また、computeメソッドの戻り値は通常のpandas.DataFrameやgeopandasのGeoDataFrameになります。)
%%time
# computeをすることで初めて計算される
r = joined.compute()
# CPU times: user 7.65 s, sys: 2.75 s, total: 10.4 s
# Wall time: 27.7 s
と、言いつつも27sで処理が完了しました。とても早いです。
ポリゴンの中には860万レコードほど入っていたようです。
len(r)
# 8652608
出力してデータを確認してみる
実際にデータをGUIで確認してみましょう。
csv読み込み時にdtypeを指定していないためか、ファイル書き出し時にValueError: Could not encode value 'False' in field 'gps' to stringのように出力されてしまいます。
一部の属性がうまくエンコードできていないようなので、object型になっているものをstrに変更しましょう。
r.dtypes
# anon_ticket_number float64
# issue_datetime object
# state object
# anon_plate_id float64
# division float64
# location object
# violation_desc object
# fine float64
# issuing_agency object
# lat float64
# lon float64
# gps object
# zip_code float64
# geometry geometry
# index_right int64
# NAME object
# LISTNAME object
# MAPNAME object
# Shape_Leng float64
# Shape_Area float64
# dtype: object
dtypeを変更します。
r = r.astype(
{
"issue_datetime": bool,
"state": str,
"location": str,
"violation_desc": str,
"issuing_agency": str,
"gps": str,
"NAME": str,
"LISTNAME": str,
"MAPNAME": str,
}
)
変更した列はobjectのままですが内部的には切り替わっているのでOKです!(dtypeにstrという型はありません。)
r.dtypes
# anon_ticket_number float64
# issue_datetime bool
# state object
# anon_plate_id float64
# division float64
# location object
# violation_desc object
# fine float64
# issuing_agency object
# lat float64
# lon float64
# gps object
# zip_code float64
# geometry geometry
# index_right int64
# NAME object
# LISTNAME object
# MAPNAME object
# Shape_Leng float64
# Shape_Area float64
# dtype: object
pyogrioを利用してFlatGeobufで出力してみましょう。
%%time
import pyogrio
pyogrio.write_dataframe(r, "joined.fgb", index=True, driver="FlatGeobuf")
# CPU times: user 2min 28s, sys: 19.7 s, total: 2min 47s
# Wall time: 3min 8s
また、ポリゴンの方も出力しておきます。
%%time
import pyogrio
pyogrio.write_dataframe(neigh, "neigh.fgb", index=True, driver="FlatGeobuf")
# CPU times: user 4.75 ms, sys: 3.71 ms, total: 8.46 ms
# Wall time: 10.4 ms
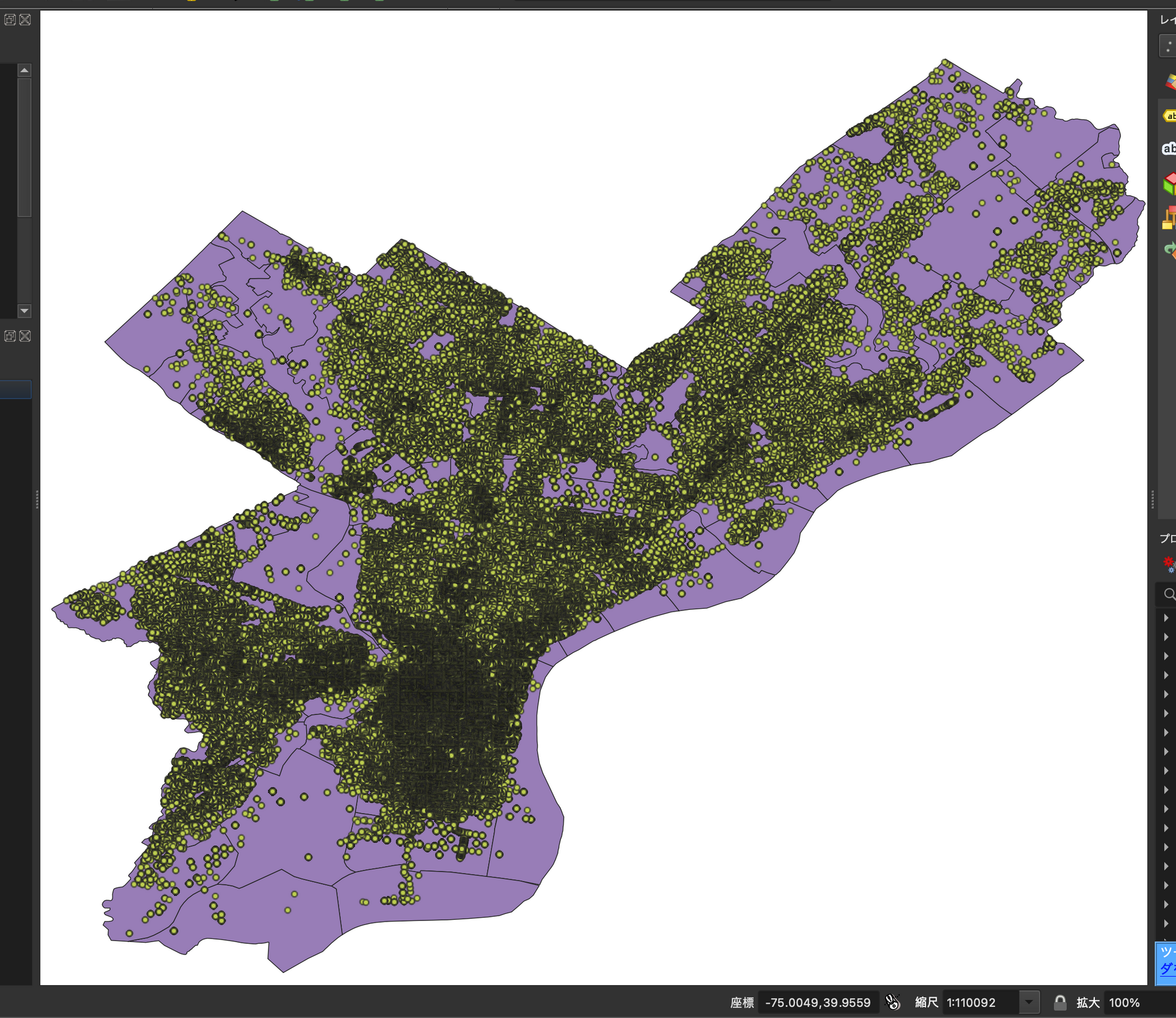
QGISなどで表示させてみましょう。ポリゴン外の点は除外されていそうですね。
最後に
このように、dask-geopandasを有効活用すればGB級のデータも20sちょいで空間結合できます。
小さすぎるデータではパーティションを区切るオーバーヘッドの方が大きくなってしまったり、大きすぎるとcompute時に結局メモリの限界を超えて処理落ちしてしまったりと、万能ではありませんが、用途を選べばものすごい効力を発揮しますので、みなさんも使ってみてください。