私が 3 年前から続けているいつもの Update 速報です。今年の Microsoft Build 2026 における Foundry IQ(Azure AI Search)のアップデートでは、Azure AI Search が従来の検索サービスから、エージェント向けの「フルマネージドな知識レイヤー」へと進化したことが示されました。さらに、Microsoft におけるコンテキストエンジニアリングプラットフォームとして位置づけられています。
アップデートの中心は Azure AI Search の ナレッジベース、ナレッジソース、Agentic Retrieval で、Microsoft Foundry Portal、Foundry Agent Service、MCP から利用することができます。
そして本日、Foundry IQ Serverless という新たな Tier が登場しました。とうとう来ましたね。これは Agentic AI 時代の利用法に適応した Azure AI Search の歴史的な転換点と言える気がします。

🎉新機能
-
Foundry IQ Serverless(プレビュー)
使用したコンピューティング リソースとストレージ容量に応じて課金され、アイドル状態になるとサービスはゼロまでスケールダウンします。 -
新しいナレッジ ソースが追加
Work IQ、Fabric IQ、File Search、Azure SQL、MCP Server などをナレッジ ベース経由で参照でき、社内外の知識を横断した Agentic Retrieval を構成しやすくなります。 -
ナレッジ ベースの GA とアップデート
2026-04-01API で主要なナレッジ ベース機能が GA となり、2026-05-01-previewでは検索既定値、GPT-5、CORS などの拡張が追加されています。 -
Web IQ が Foundry IQ で利用可能に
社内データだけでは不足する最新の Web 情報を、Foundry IQ の検索フローに組み込んで回答の根拠として利用できます。 -
エージェント検索エンジンの検索品質が向上
クエリ計画、ソース選択、リランキング、回答合成が改善され、複数ソースをまたぐ質問でも必要な根拠を見つけやすくなっています。 -
データ パイプラインのアップデート(プレビュー)
SharePoint ページや Lists、セマンティック チャンク分割、画像説明、Image Serving により、文書構造や視覚情報を検索に活用しやすくなります。 -
検索実行と運用 API の追加(プレビュー)
Retrieve Action の新パラメーター、サービス統計、List API ページングにより、検索結果の量、障害時の扱い、運用監視を細かく制御できます。 -
セキュリティ / ガバナンス アップデート(プレビュー)
Purview 秘密度ラベル、SharePoint 権限同期、プライベート接続、Managed Identity 連携により、企業データを安全に検索へ接続しやすくなります。
1. Foundry IQ Serverless(プレビュー)
Foundry IQ Serverless は、エージェントワークロードの「使う時だけ急に検索が必要になり、使わない時は止まっている」という性質に合わせた実行モデルです。従来の Azure AI Search SKU は パーティション / レプリカ / 検索ユニットを常時確保する考え方ですが、Serverless はアイドル時にゼロスケールし、コンピューティングユニット(CU)ベースで消費を測る設計として発表されています。PoC、イベント駆動のエージェント、利用量が読みにくい初期導入で特に有効です。
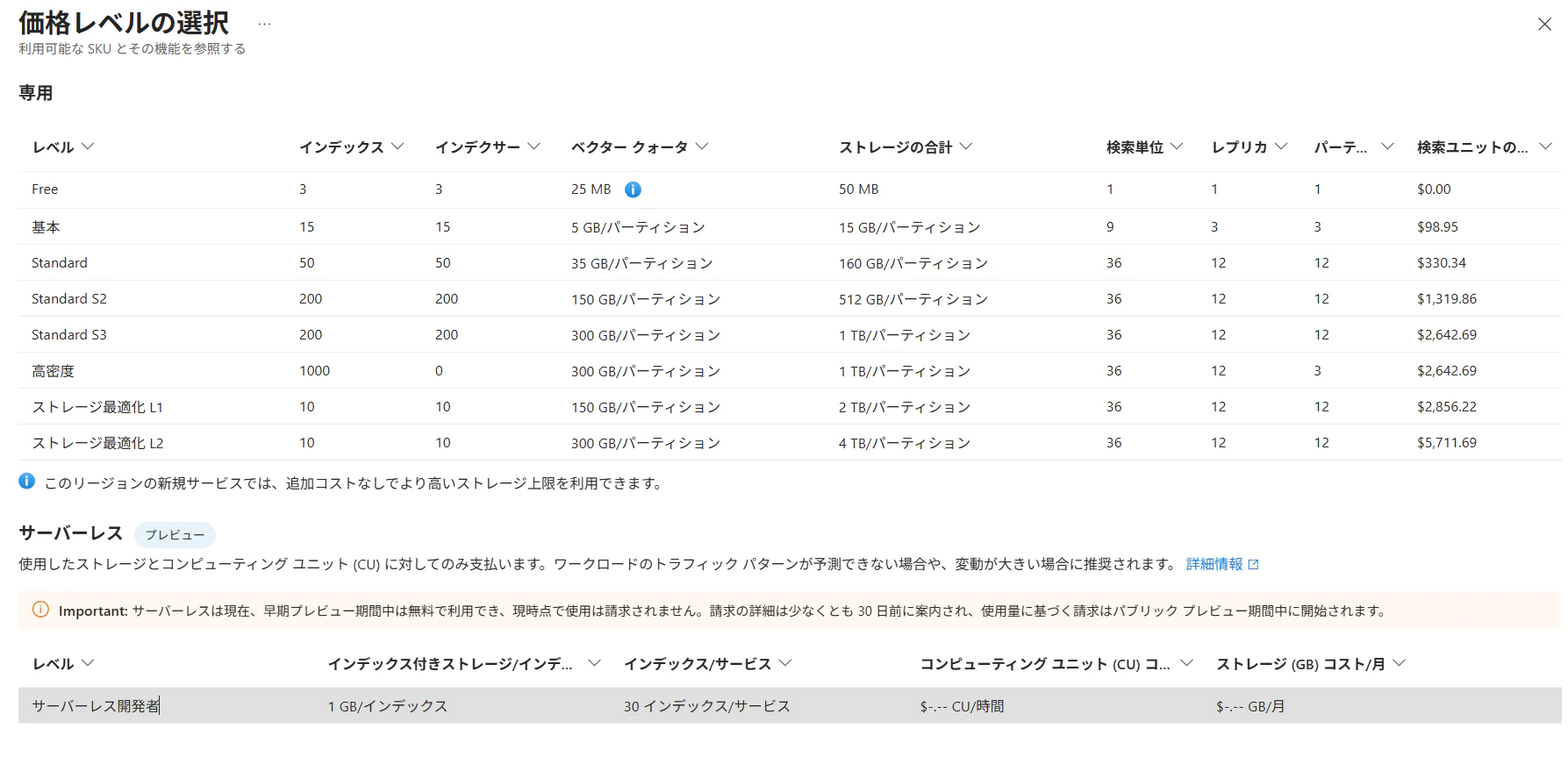
| 能力 | Developer Tier |
|---|---|
| コンピューティング使用量 | 0.24 CU/時間 |
| インデックス付きストレージ | 最大 $0.29/GB/月。GB あたりの料金は地域によって異なります。 |
| インデックスごとのインデックス付きストレージ | 1 GB / インデックス |
| サービスごとのインデックス | 30 インデックス / サービス |
| 地域ごとのサブスクリプションあたりのサービス数 | 5 つのサービス / サブスクリプション / 地域 |
※プレビューは West Central US, Switzerland North, Japan East で利用可能です。
※課金は2026年後半に開始予定で、詳細は少なくとも30日前までに通知されます。Serverless Developer は課金開始前に料金は発生しません。現在のコンピューティングユニットの測定値は概算値であり、課金開始前に変更される可能性があります。
2. 新しいナレッジソースが追加
新しいナレッジ ソースは、エージェントが「文書の中を探す」だけでなく、「組織の会話・会議・メール」「Fabric 上の業務概念とライブデータ」「SQL の構造化データ」「MCP で公開された外部ツールや知識」まで扱えるようにするための拡張です。これにより、たとえば営業エージェントが顧客会議の文脈、Fabric の売上データ、契約書、外部 MCP の専門ナレッジを同じナレッジ ベース経由で参照する設計が可能です。
| ナレッジ ソース | 内容 |
|---|---|
| Work IQ | Microsoft 365 のメール、会議、ファイル、Teams メッセージなどの組織内コラボレーション情報を、権限を考慮して利用する。 |
| Fabric Data Agent | Fabric Data Agent をナレッジ ソースとして利用する。 |
| Fabric Ontology | Fabric IQ のオントロジー、セマンティック レイヤー、OneLake データとつながる構造化された業務知識を利用する。 |
| File Search / File Knowledge Source | ナレッジ ベースへファイルを直接アップロードして利用する。 |
| Azure SQL / Indexed SQL | リレーショナル データをナレッジ ベースに取り込む。 |
| MCP Server | Model Context Protocol で提供される外部ナレッジをナレッジ ソースとして接続する。 |
2.1. 知識ソースに基本フィルターを永続化する(プレビュー)
検索インデックスのナレッジソースは、永続的な取得デフォルトをサポートするようになりました。これには、すべての取得に適用される baseFilter と、AND ロジックを使用して baseFilter と組み合わせるランタイム filterAddOn が含まれます。
2.2. インデックス付き知識ソースの鮮度を考慮した検索(プレビュー)
インデックス化された知識ソースに対して鮮度ポリシーを設定し、最近更新されたドキュメントを優先的に検索できるようにします。
3. ナレッジベースの GA
ナレッジベースは、Azure AI Search 上の最上位リソースとして GA になりました。GA バージョンの 2026-04-01 API では、一般提供済みのナレッジ ソース種別に対する抽出型検索をサポートします。
3.1. ナレッジベース GPT-5 および CORS サポート(プレビュー)
ナレッジ ベースが GPT-5 ファミリー モデルをサポートし、gpt-5.4-mini などをクエリ計画や応答生成に利用できるようになりました。より小さいモデルを使って応答性やコストを調整しながら、ナレッジベース側の Agentic Retrieval を活用する設計がしやすくなります。新しい corsOptions プロパティを使用して CORS を設定すると、ブラウザからサービスへの直接取得呼び出しが可能になります。
3.2. 取得アクションまたは MCP エンドポイントを使用してナレッジベースを照会(プレビュー)
取得アクション(Retrieve action)は、ナレッジベースに対して問い合わせを投げる API です。リクエストには、ユーザー質問や会話履歴を含む messages、または検索意図を直接渡す intents、さらに対象 ナレッジソースを制御する knowledgeSourceParams を含められます。2026-05-01-preview の場合、messages にチャット履歴を渡すと、LLM が会話文脈から検索すべきクエリを判断します
エージェントによる情報取得パイプラインでは、取得アクションによってナレッジベースから並列クエリ処理が呼び出されます。取得アクションは、検索サービス REST API または Azure SDK を使用して直接呼び出すことができます。各ナレッジベースには、MCP 互換エージェントが利用できる MCP エンドポイントも用意されています。
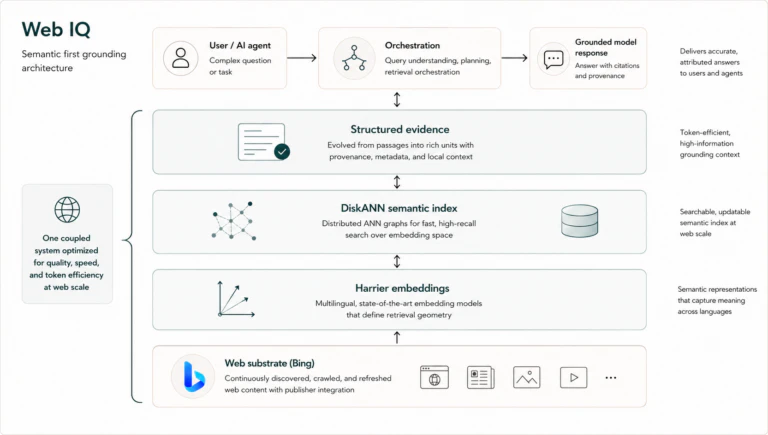
4. Web IQ が Foundry IQ で利用可能に
Web IQ は、モデルの知識カットオフや社内データだけでは答えられない質問に対して、Web、ニュース、画像、動画、ショッピングなどの外部情報を検索ソースとして使うための新機能です。Grounding with Bing の進化版であり、Web 検索ページを人間に見せるのではなく、LLM / エージェント ワークフローのグラウンディング ソースとして低遅延に使う設計である点です。社内ナレッジ ソースと組み合わせると、社内ポリシーや製品資料に加えて、最新の市場情報や公開情報で補完するエージェントを作れます。

5. エージェント検索エンジン(Agentic Retrieval)の検索品質が向上
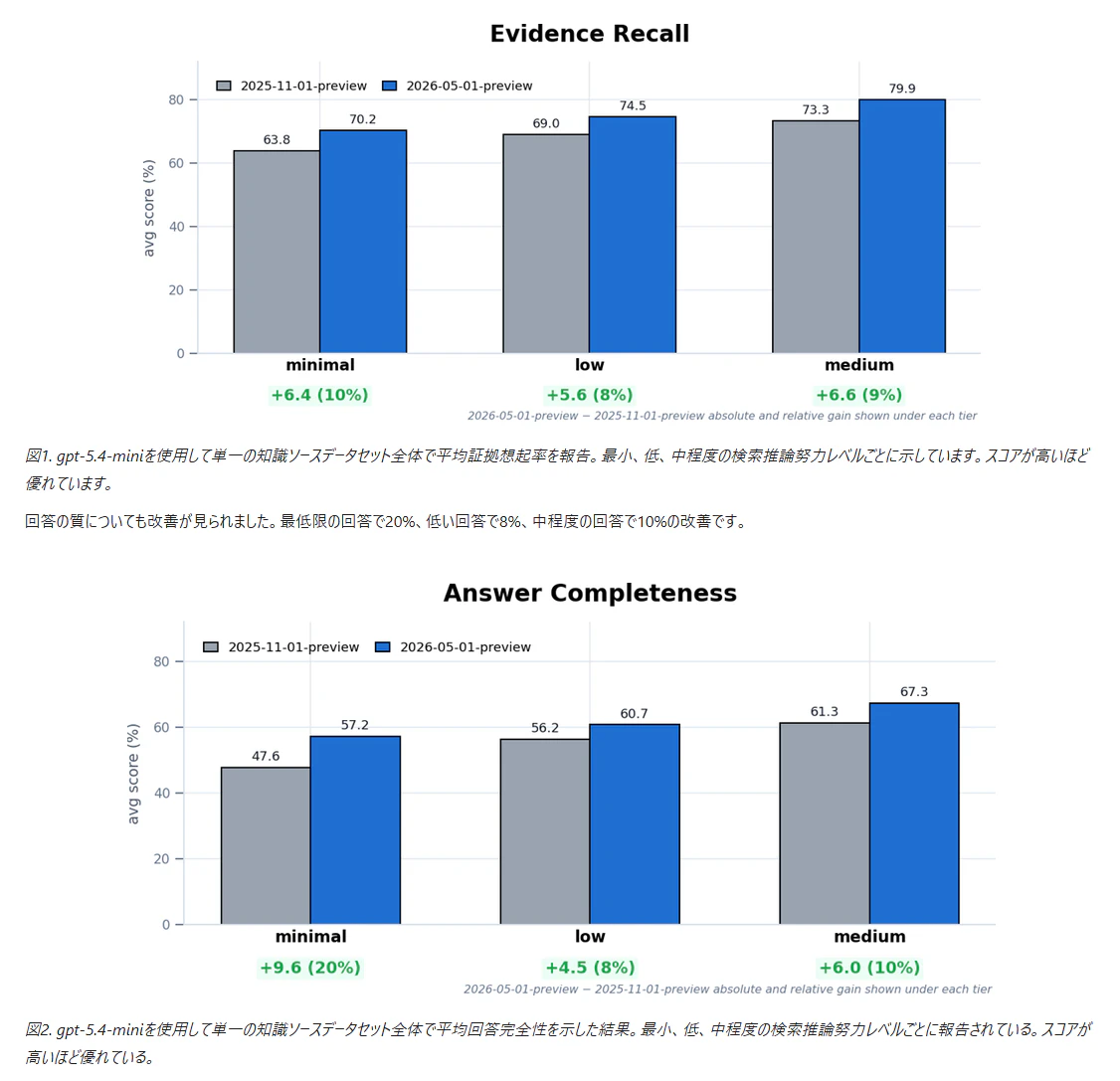
Agentic Retrieval は、ユーザーの質問をそのまま 1 回検索するのではなく、質問を分解し、必要なナレッジ ソースを選び、複数の検索を並列・反復し、Semantic Ranker や分類器で結果を絞り込む検索方式です。2026-05-01-preview の改善では、検索の Recall(厳密には主に answer accuracy そのものではなく、evidence recall / 根拠文書の取得再現率の改善)、回答の完全性、トークン効率が改善されています。
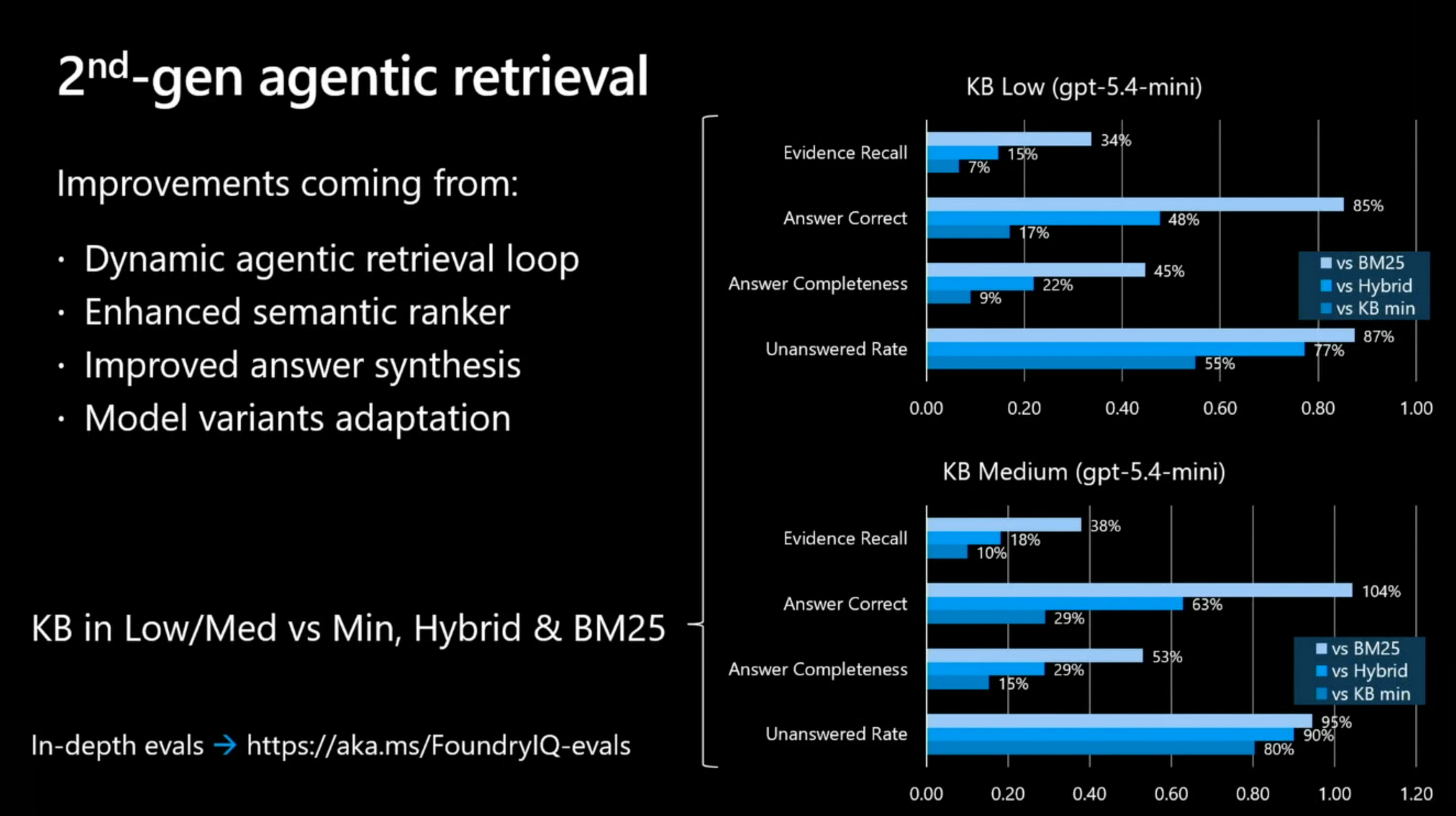
- 単発 RAG をナレッジ ベースに置き換えると、根拠の Recall が最大 46% 改善。
- 小さめのエージェント モデルと Agentic Retrieval を組み合わせると、根拠の Recall が最大 54% 改善
- 検索ツール呼び出しの削減により、トークン コストを 34% 節約
- 前回リリース比で根拠の Recall は Minimal +10%、Low +8%、Medium +9%
- 回答品質は Minimal +20%、Low +8%、Medium +10%
- BM25 比では無回答率を 94.5% 削減し、根拠の Recall を 37.9% 改善
5.1. なぜ改善したのか?
今回の品質向上においては、Agentic Retrieval パイプラインにおける各フェーズで以下のような改善が行われました。

| 改善要因 | 解説 |
|---|---|
| 動的な Agentic Retrieval ループ | 固定的に全ソースを検索するのではなく、質問に応じてナレッジ ソースを選び、クエリを分解し、必要なら追加検索を行う。 |
| ナレッジ ソース別のクエリ最適化 | 同じ質問でも、Web、SQL、Fabric、文書インデックスでは有効な検索語や制約が異なるため、ソースごとに検索要求を調整する。 |
| Semantic Ranker の再学習 | 大量の候補文書から、回答に使える可能性が高い文書を上位に出すよう再ランキングの品質を高めている。 |
| 回答合成の改善 | 取得した根拠を単に並べるのではなく、より完全で構造化された回答にまとめる。根拠から外れた推測を抑えることも狙い。 |
| トークン キャッシュとプロンプト効率化 | モデル呼び出しをキャッシュしやすい形にして、同じ情報の再処理を減らし、品質を保ちながらトークン コストを下げる。 |
| MCP スキーマの動的最適化 | 呼び出し側モデルのサイズや検索モードに応じて MCP ツール説明を変え、小さいモデルには余計な検索を避ける強めの制約を与える。 |
5.2. 品質評価の分析・インサイト
- ナレッジベースは、スタンドアロン検索ツールより根拠の Recall と回答品質を高めつつ、検索ツール呼び出しを減らしている
- 小さめのエージェントモデルでも、検索をナレッジベースへ任せることで、高い検索品質と応答性を両立しやすい
- BM25 や単純なハイブリッド検索より、ナレッジベースの Minimal / Low / Medium 構成は、根拠取得、回答完全性、無回答率の面で段階的に有利になる
- MCP、Fabric、SQL のような異種ソースを含む評価でも効果が確認されており、構造化データと非構造化文書をまたぐ検索に向いている
-
検索推論努力パラメータ
Mediumは品質重視のため、応答時間やトークン コストとのバランスを見て採用する必要がある
5.2. エージェントによる情報検索のためのオプションのセマンティック設定(プレビュー)
2026-05-01-preview 以降、エージェントによる検索フローではセマンティック設定はオプションとなります。従来のセマンティック検索では、引き続き明示的なセマンティック設定が必要です。
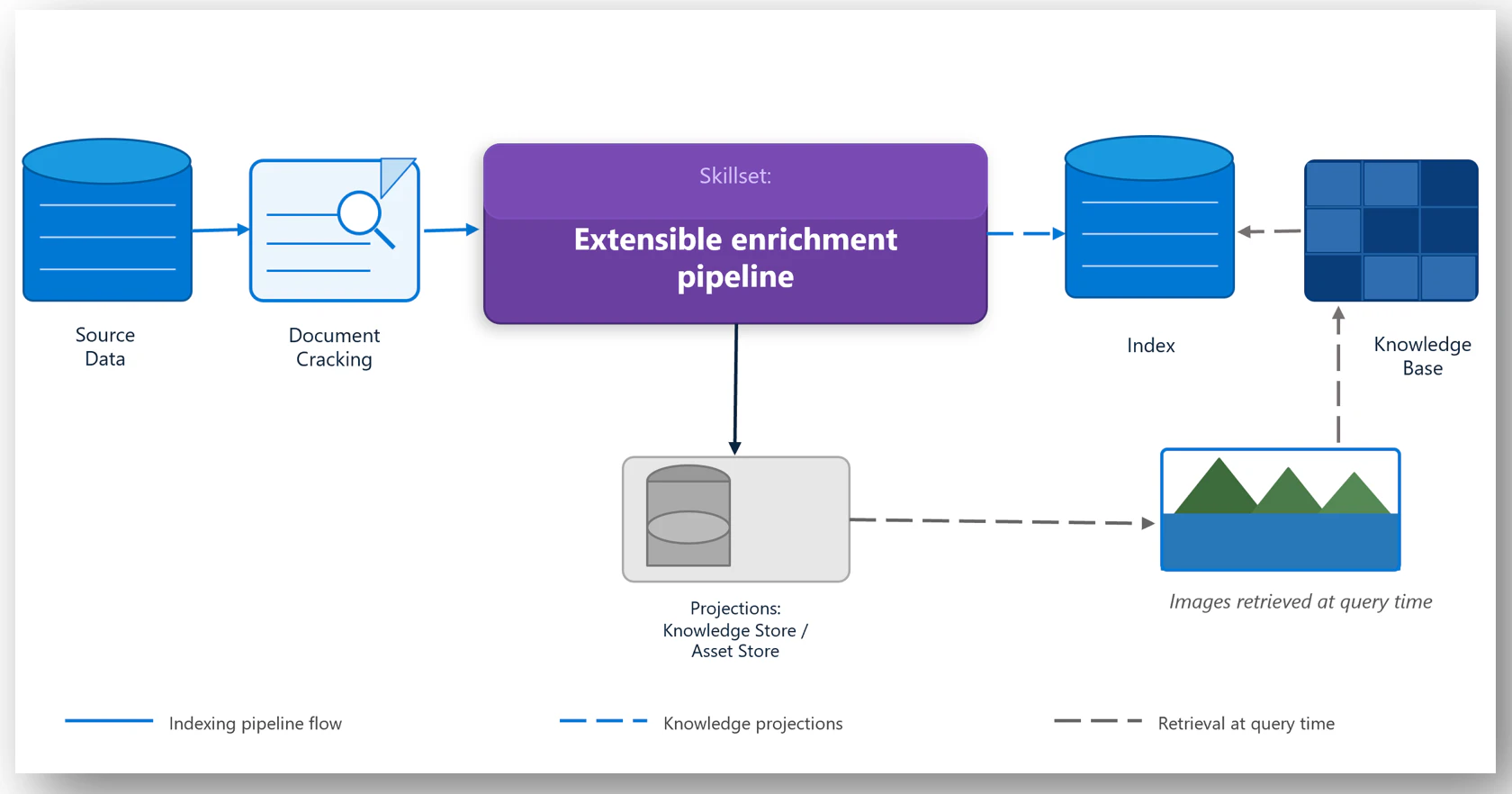
6. データパイプラインのアップデート(プレビュー)
データ パイプライン更新は、検索時のアルゴリズム以前に、元データをどれだけ正しく取り込めるかを改善する更新です。RAG の失敗は、検索ロジックではなく「表が崩れている」「画像内の情報が落ちている」「SharePoint のページやリストが取り込まれていない」といった取り込み側に原因があることが多いです。今回の更新は、SharePoint の対象拡大、Content Understanding による構造理解、Image Serving による視覚情報の保持を通じて、エージェントが参照できる根拠を増やします
6.1. SharePoint indexing 拡張
SharePoint インデックス作成拡張は、企業内の知識が「ファイル」だけでなく、ページ、リスト、サブサイトにも存在する現実に対応する機能です。ASPX ページや Lists を取り込めると、社内ポータル、手順書、業務台帳、運用状況などをエージェントの検索対象にできます。ソース URL の追跡性は、回答の根拠から元 SharePoint コンテンツへ戻るためにも重要です
SharePoint インデクサーが以下をプレビューでサポートします。
- モダン ASPX サイト ページ
- SharePoint Lists
- ドキュメント ライブラリ
- 再帰的なサブサイト検出
- ソース URL の追跡性
6.2. Content Understanding 連携
Content Understanding 連携は、PDF、Office 文書、画像を含む複雑な文書から、レイアウトや表構造を意識して検索可能なテキストを抽出する機能です。通常のテキスト抽出では、表の行列関係、図の意味、ページをまたぐ表などが崩れやすく、回答品質に影響します。Content Understanding を取り込みパイプラインに組み込むことで、文書構造をより保ったチャンクと説明文を作り、後段の検索・回答生成に渡せます。
Foundry Tools の Content Understanding 連携では、次がプレビューで強化されています。
- セマンティック チャンク分割
- AI による画像説明の生成
- レイアウト認識型の抽出
- tables / diagrams / scanned images などの意味表現の保持
6.3. Image Serving
Image Serving は、文書内から抽出された画像を検索時に返せるようにする機能です。図面、チャート、スクリーンショット、スキャンされた帳票などは、テキストだけに変換すると重要な根拠が抜けることがあります。Image Serving により、エージェントやマルチモーダル モデルが元画像を参照し、視覚的な根拠を含めて判断できるようになります。
6.4. APIM / プライベート接続 / モデル エンドポイント対応
APIM / プライベート接続 / モデル エンドポイント対応は、企業内のネットワーク、認証、監査、トラフィック制御に合わせて AI エンリッチメントやベクトル化を運用するための更新です。Azure API Management を挟むことで、モデル呼び出しに対するポリシー、ルーティング、監視を中央管理しやすくなります。プライベート接続は、機密データを扱う取り込み / エンリッチメントの通信をパブリック経路に出しにくくするために重要です。
6.4.1. Azure OpenAIスキルおよびベクトライザーに対するAPIMのサポート(プレビュー)
Azure OpenAI Embedding スキル、GenAI Prompt スキル、およびAzure OpenAI Vectorizer は、Azure API Management を介したルーティングのための azure-api.net エンドポイントを受け入れるようになりました。
7. 検索実行と運用 API の追加
7.1. リストAPIのページング(プレビュー)
List API ページングにより、$top、$skip、継続トークンで大きな一覧を段階的に取得できます。
7.2. ナレッジベースおよびナレッジソース サービスの統計情報(プレビュー)
Get Service Statistics が knowledgeBasesCount と knowledgeSourcesCount を返すようになり、サービス内のナレッジ ベース数とナレッジ ソース数を把握しやすくなりました。
8. セキュリティ / ガバナンスアップデート(プレビュー)
セキュリティ / ガバナンス更新は、Foundry IQ を企業データで使うための中核です。エージェントが回答できる範囲は、単に検索にヒットしたかではなく、ユーザーがその情報にアクセスする権限を持つか、機密ラベルをどう扱うか、管理者の調査アクセスが監査されるか、通信経路が許可された境界内にあるかで決まります。
8.1. SharePoint 権限同期
SharePoint 権限同期は、SharePoint 側で変わる権限を検索インデックス側へ継続的に反映するための機能です。権限が変わったのに検索インデックスが古い ACL のままだと、エージェントが見せてはいけない情報を返す、または見せるべき情報を返さないリスクがあります。増分同期によって、SharePoint と Foundry IQ の間の権限のずれを小さくできます
2026-05-01-preview では、SharePoint 権限同期が改善されています。
- スケジュールされたインデクサー実行で、ドキュメント ACL の増分更新を取得。
- Foundry IQ のナレッジ ソース設定経由のスケジュールにも対応。
- SharePoint グループをサポート。
- ドキュメント ライブラリだけでなく、Lists / ASPX ページの ACL にも対応。
- クエリ時の ACL 適用と組み合わせ、ソース システムと検索レイヤーの権限のずれを減らす。
8.2. Microsoft Purviewの感度ラベルを取得応答に表示する(プレビュー)
Purview 秘密度ラベルは、文書の分類や機密度を AI 検索の流れに持ち込むための機能です。検索結果が取得できるだけではなく、その文書が Confidential なのか、社外秘なのか、暗号化や保護ポリシーがあるのかを、インデックス、ナレッジ ベース、Foundry Agent 体験、MCP 連携の中で扱えるようにします。これにより、回答生成時にもラベル文脈を失いにくくなります。
Foundry IQ のナレッジ ベース シナリオで、Microsoft Purview 秘密度ラベルの伝搬がサポートされています。
- ソース システムからインデックスへラベルを取り込む
- ナレッジベースの検索フローにラベル コンテキストを通す
- MCP ベースのやり取りや Foundry ポータルのナレッジでもラベル文脈を扱う
- ユーザー認可と組み合わせ、分類・保護されたコンテンツを AI ワークフローでも扱えるようにする
8.3. Microsoft Foundry向けネットワークセキュリティ境界と共有プライベートリンク(プレビュー)
Azure AI Search は、Microsoft Foundry リソースへの接続において、ネットワーク セキュリティ境界と共有プライベート リンクをサポートするようになりました。これにより、スキル、ベクトル化ツール、ナレッジ ベースへの安全なプライベート接続が可能になります。
🎉 Microsoft Foundry の Build 2026 Updates
今月は様々なパートナー様と Build 2026 Update Recap ができることを楽しみにしています。
参考
OSS プロジェクト
RAGOps Studio — for Azure AI Search にも Build 2026 の最新機能を実装予定です。