[NEWS!]🚀 RAGOps Studio シリーズ第二弾、公開!! Content Understanding の次世代 UI 🆕
RAGOps Studio — for Document Intelligence / Content Understanding
はじめに
Azure AI Content Understanding は Microsoft Ignite 2024 にて発表されたマルチモーダル データの取り込みとコンテンツの抽出を行う生成 AI ベースの新サービスです。このサービスは、ドキュメント、画像、音声、ビデオなどのさまざまなデータ タイプを取り込み、簡単に処理および分析できる構造化された形式に変換します。

準備
West US, Sweden Central, Australia East リージョンの Azure AI services multi-services リソースを作成
制限
サービスクォータ制限
言語の制限
- Document: 英語※
- Image: 英語
- Audio: 英語、簡体中国語、フランス語、ドイツ語、ヒンディー語、ヒンディー語、日本語、韓国語、スペイン語、(ブラジル)
- Video: 英語、簡体中国語、フランス語、ドイツ語、ヒンディー語、ヒンディー語、日本語、韓国語、スペイン語、(ブラジル)
※ただし、以下の注意書きが追加されていました。
- 以下のサポート対象言語は、後処理で単語のロケールを考慮した正規化が有効になっている言語です。
- コンテンツの理解はさまざまな言語に対応していますので、ぜひお試しいただき、価値そのものではなく、コンテンツに焦点を当ててください。
Azure AI Foundry のプロジェクトから接続設定を追加
Azure AI Foundry 上から扱うためには、管理センターから接続設定を開き、作成した「Azure AI サービス」から追加する必要があります。


Azure AI Content Understanding プロジェクト
Azure AI Content Understanding の TOP へ移動し、「Create new Content Understanding project」ボタンを押下します。
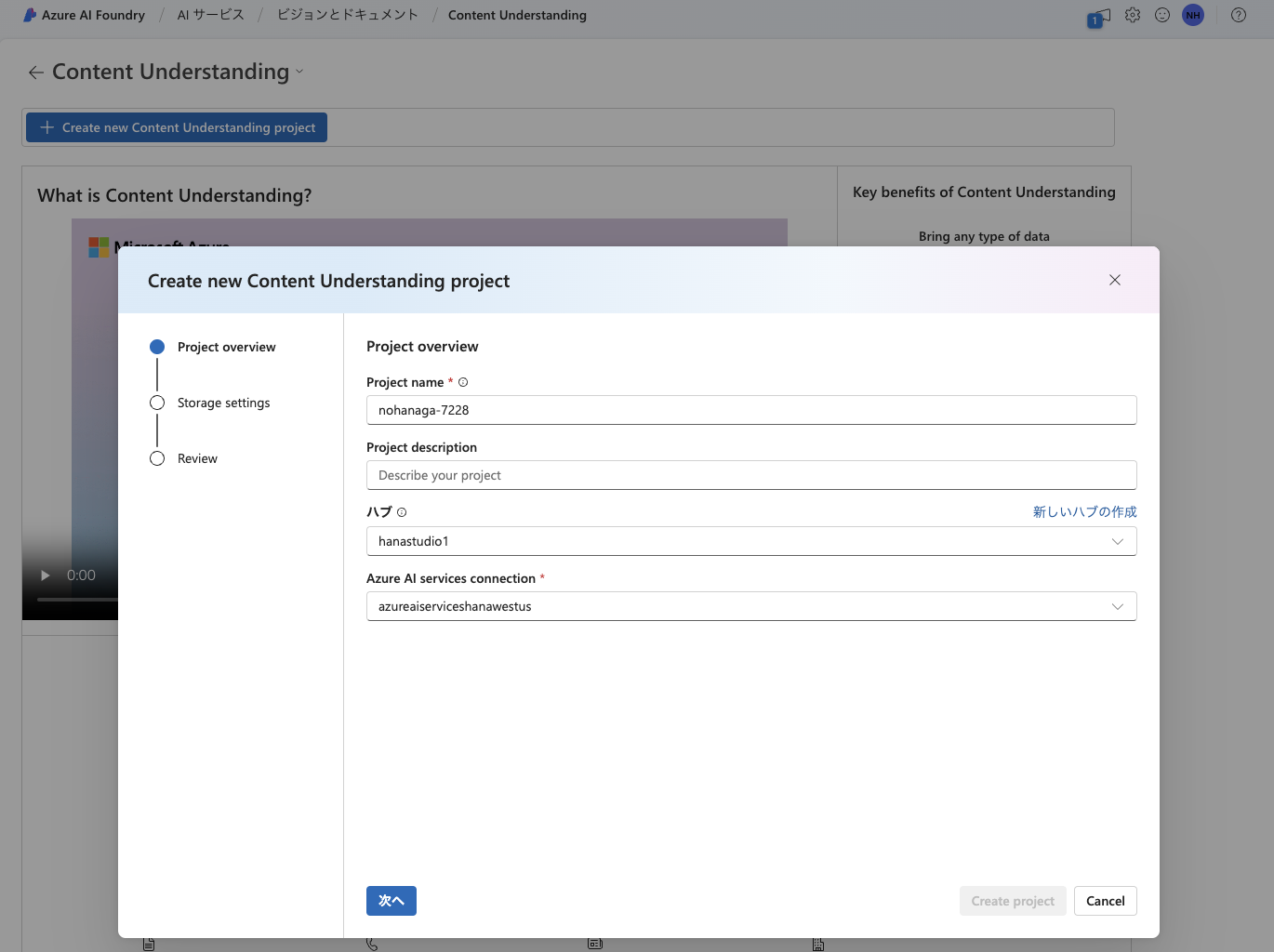
接続設定が完了していれば、ここでハブを選択した時に Azure AI services connection が選択できるようになっています。次に Blob storage を選択して「Create project」ボタンを押せば作成されます。
作成後は Azure AI Foundry のプロジェクト一覧からアクセスできます。
アナライザーをビルドする
Azure AI Content Understanding では、ファイルからコンテンツを抽出する抽出器のことをアナライザーと呼び、このアナライザーを特定のニーズに合わせてカスタマイズすることができます。そして最後にビルドという作業をすることで REST API から呼び出すことができます。
スキーマ定義
読み取りたいファイルをアップロードします。ファイルの形式によって、どのようなテンプレート(モデル)が使用できるかが変わります。たとえば、PDF の場合は Document analysis のみとなります。

フィールドの追加
抽出したいフィールドの名前、説明、型、方法を自分で設定する必要があります。このサービスでは、多様なデータセットでトレーニングされた機械学習モデルに加えて生成 AI の支援を受けて抽出したいフィールドとのマッピングが行われます。

抽出したいスキーマ定義ができたら、「Save」ボタンを押下して保存します。
テスト
Test analyzer から「Run analysis」ボタンを押して抽出できるかどうか確認します。

いいですね。生成 AI の力を借りているので、帳票内に明確な Key を表すラベルが無かったとしても、意図を汲んでマッピングされていることがわかります。
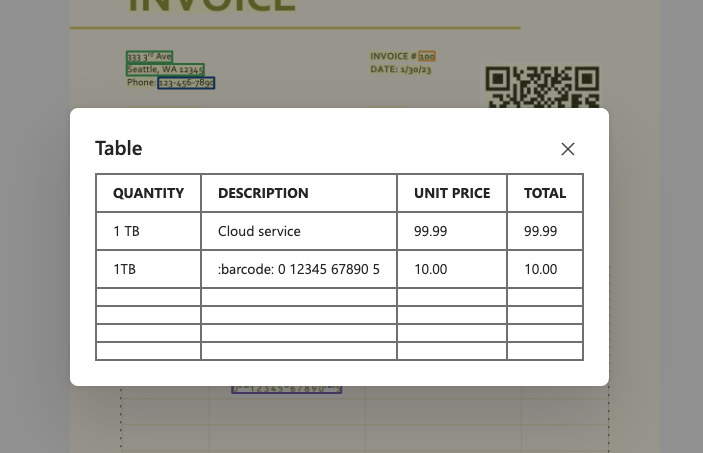
注文表のところもしっかりと構造化抽出できていますね。オプションでバーコードや数式の読み取りにも対応しています。テーブル型もしっかりとスキーマ定義してあります。

ビルド
テストを繰り返して求める精度を達成したらビルドを行います。ビルドしたアナライザーはいつでも UI からテストできますし、REST API から呼び出してプログラムと統合することができます。

REST API
アナライザーの実行
import requests
# 必要なパラメータを設定
endpoint = "https://<YourAIServices>.openai.azure.com/" # 適切なエンドポイントに置き換え
analyzer_id = "InvoiceAnalyzer" # 実際のAnalyzer IDに置き換え
subscription_key = "" # 実際のキーに置き換え
file_url = "" # 実際のファイルURLに置き換え
# リクエストのURL
url = f"{endpoint}/contentunderstanding/analyzers/{analyzer_id}:analyze"
params = {
"stringEncoding": "codePoint",
"api-version": "2024-12-01-preview"
}
# ヘッダーとデータ
headers = {
"Ocp-Apim-Subscription-Key": subscription_key,
"Content-Type": "application/json"
}
data = {
"url": file_url
}
# POSTリクエストを送信
response = requests.post(url, headers=headers, params=params, json=data)
# 結果を表示
print("Status Code:", response.status_code)
print("Response Body:", response.json())
print("Operation-Location:", response.headers['Operation-Location'])
Status Code: 202 が返ります。分析は非同期で実行されます。レスポンスヘッダー Operation-Location には分析結果を得るための完全な URL が含まれます。
Status Code: 202
Response Body: {'id': '590c644a-e044-42dd-87bc-941ff950a873', 'status': 'Running', 'result': {'analyzerId': 'InvoiceAnalyzer', 'apiVersion': '2024-12-01-preview', 'createdAt': '2024-11-26T11:47:28Z', 'warnings': [], 'contents': []}}
Operation-Location: https://<YourAIServices>.openai.azure.com/contentunderstanding/analyzers/InvoiceAnalyzer/results/590c644a-e044-42dd-87bc-941ff950a873?api-version=2024-12-01-preview
結果の取得
アナライザーの実行時に得た id を result_id にセットします。Operation-Location をそのままリクエストしても OK です。
result_id = "590c644a-e044-42dd-87bc-941ff950a873"
# リクエストのURL
url = f"{endpoint}/contentunderstanding/analyzers/{analyzer_id}/results/{result_id}"
params = {
"api-version": "2024-12-01-preview"
}
# ヘッダー
headers = {
"Ocp-Apim-Subscription-Key": subscription_key
}
# GETリクエストを送信
response = requests.get(url, headers=headers, params=params)
# 結果を表示
print("Status Code:", response.status_code)
print("Response Body:", response.json())
はい、分析結果が JSON で得られましたね。fields 以下に抽出結果が入ります。JSON の構造を見るに、後半部は Document Intellingence の出力構造ですねはい。
[{'markdown': '# INVOICE\n\n333 3rd Ave\nSeattle, WA 12345\nPhone: 123-456-7890\n\nPURCHASED BY:\nLiane Cormier\nThe Social Strategists\n4321 Maplewood Ave\nNashville, TN 54321\n\nPhone: 111-222-3333\n\nINVOICE # 100\n\nDATE: 1/30/23\n\nSHIP TO:\nLiane Cormier\nThe Social Strategists\n4321 Maplewood Ave\nNashville, TN 54321\n\nPhone: 111-222-3333\n\n\n\nCOMMENTS OR SPECIAL INSTRUCTIONS:\nDue upon receipt\n\n\n<table>\n<tr>\n<th>QUANTITY</th>\n<th>DESCRIPTION</th>\n<th>UNIT PRICE</th>\n<th>TOTAL</th>\n</tr>\n<tr>\n<td>1 TB</td>\n<td>Cloud service</td>\n<td>99.99</td>\n<td>99.99</td>\n</tr>\n<tr>\n<td>1TB</td>\n<td> 0 12345 67890 5</td>\n<td>10.00</td>\n<td>10.00</td>\n</tr>\n<tr>\n<td></td>\n<td></td>\n<td></td>\n<td></td>\n</tr>\n<tr>\n<td></td>\n<td></td>\n<td></td>\n<td></td>\n</tr>\n<tr>\n<td></td>\n<td></td>\n<td></td>\n<td></td>\n</tr>\n<tr>\n<td></td>\n<td></td>\n<td></td>\n<td></td>\n</tr>\n</table>\n\n\n<table>\n<tr>\n<td>Subtotal</td>\n<td>109.99</td>\n</tr>\n<tr>\n<td>Sales tax</td>\n<td>4.99</td>\n</tr>\n<tr>\n<td>Shipping and handling</td>\n<td>0.00</td>\n</tr>\n<tr>\n<td>TOTAL DUE</td>\n<td>114.98</td>\n</tr>\n</table>\n',
'fields': {'CommentsORSpecialInstructions': {'type': 'string',
'valueString': 'Due upon receipt',
'spans': [{'offset': 402, 'length': 16}],
'confidence': 0.997,
'source': 'D(1,0.8182,4.2651,1.8641,4.2651,1.8641,4.4233,0.8182,4.4233)'},
'InvoiceNo': {'type': 'string',
'valueString': '100',
'spans': [{'offset': 184, 'length': 3}],
'confidence': 0.981,
'source': 'D(1,5.0367,1.742,5.2572,1.742,5.2572,1.8767,5.0367,1.8767)'}
...
'pages': [{'pageNumber': 1,
'lines': [{'content': 'INVOICE',
'paragraphs': [{'role': 'title',
'sections': [{'span': {'offset': 0, 'length': 1130},
'tables': [{'rowCount': 7,
非構造化ファイルの例②

このようなファイルに対して、以下のようにスキーマ定義します。
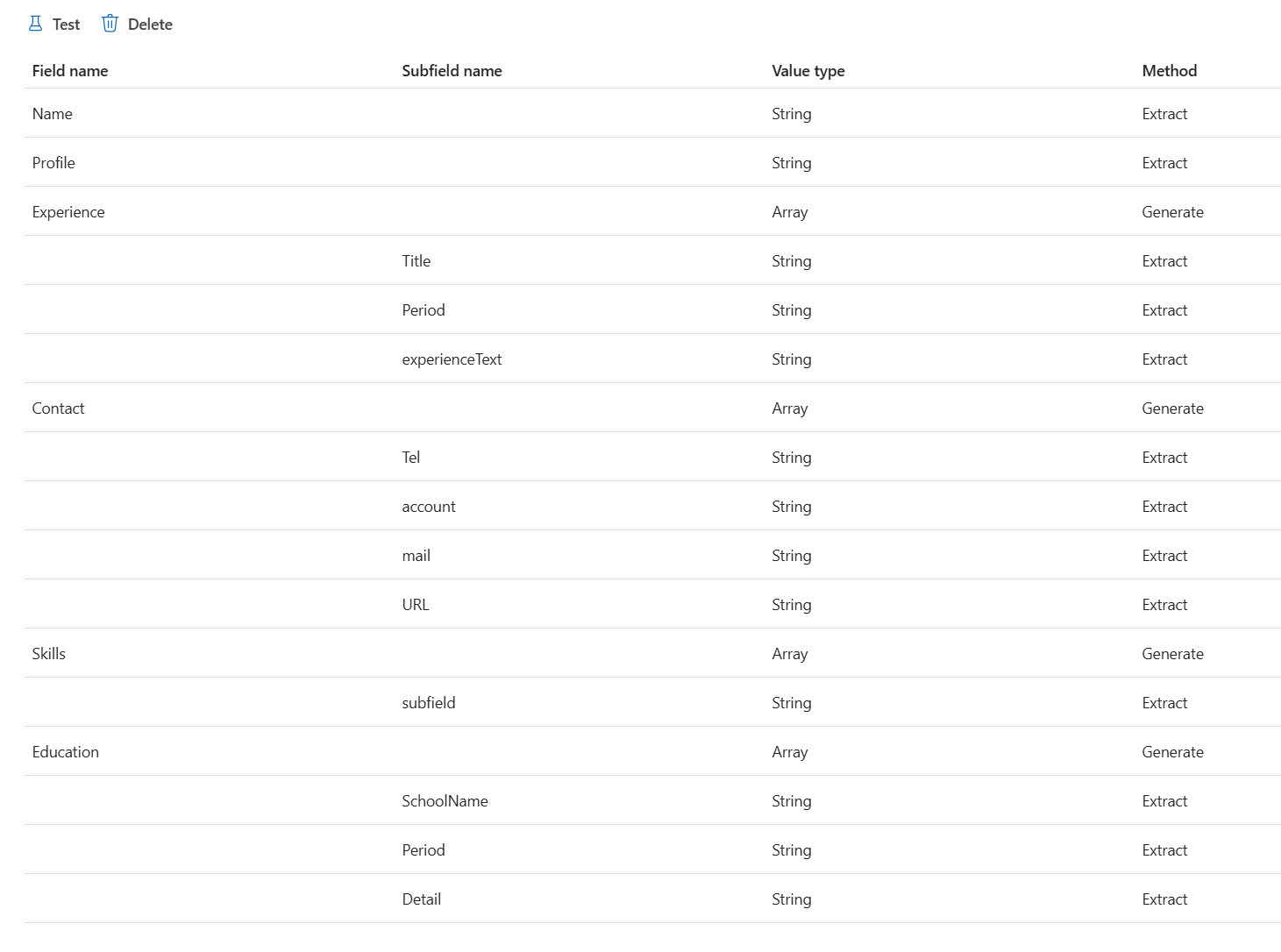
Key の無い人名を抽出
これは面白い。生成 AI の力を借りないと難しいですよね。

Key の無い Table として
それぞれのフォーマットからマッピング

List 構造
Header の無い List として抽出

繰り返し項目を Table として認識

非構造化ファイルの例③
適当に作ったパワーポイントを画像にしても OK です。まだ日本語には対応していませんが、生成 AI の力を借りているからか、英語でスキーマ定義してもうまく抽出できてますね。日本語のサポートが待ち遠しいです。
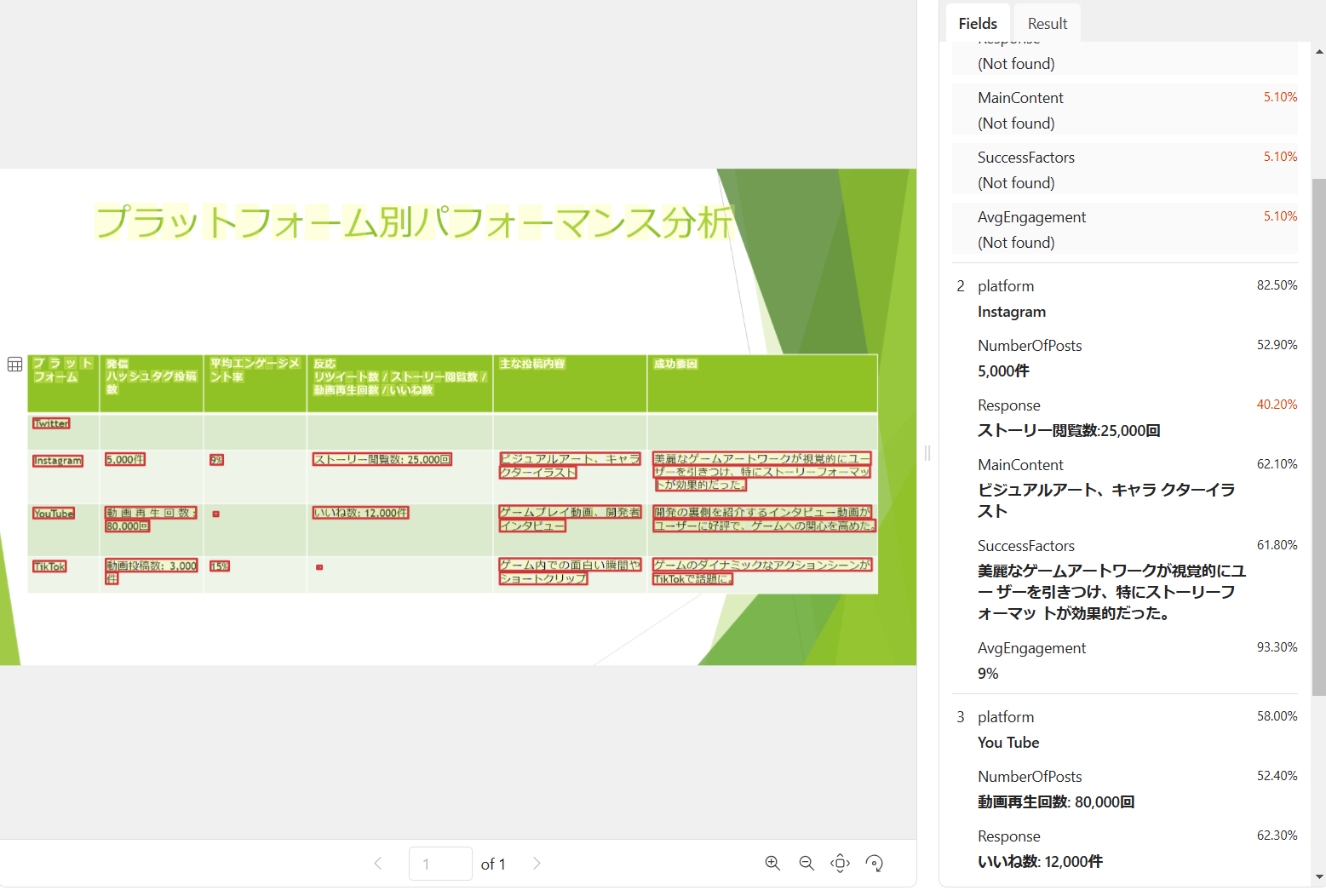
画像ファイルの場合のテンプレート

- Document analysis
- Image analysis: 画像を分析し、構造化されたフィールドを抽出
- Defect detection: 提供された金属板の画像内に潜む欠陥を識別
- Retail inventory management: 棚にある製品を監視するための小売在庫管理
Microsoft がこれまで開発してきた機械学習モデルもこちらに統合しているということですね。
Audio

- 音声文字起こし: オーディオ記録を文字起こし
- 会話の概要作成: 会話を文字起こしし、概要を抽出
- 通話後の分析: コール センターの会話を分析して、トランスクリプト、概要、センチメントなどを抽出
音声からの構造化データ抽出例
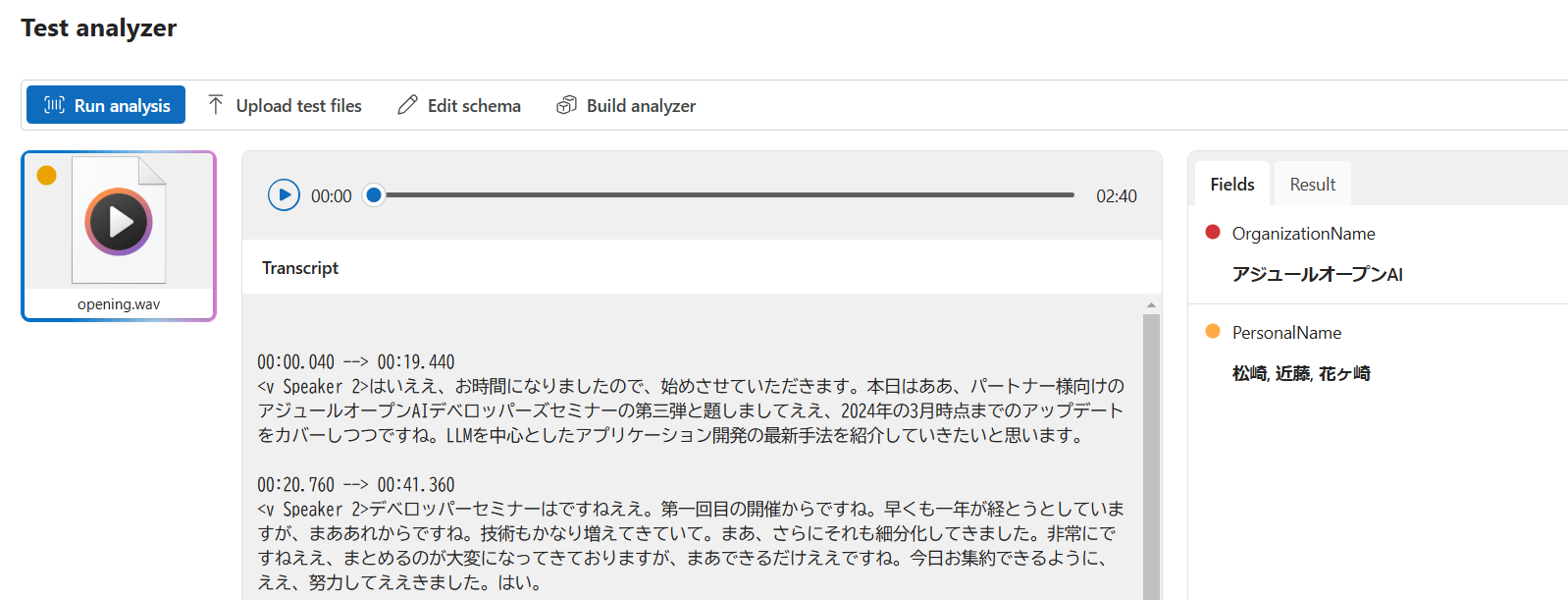
音声ファイルに対してもフィールドを定義することができます。試しに以下のように定義して分析すると、上記のようなデータが抽出できるというわけです。

Video
- ビデオ ショット分析: ビデオを分析して、各ショットのトランスクリプトと構造化フィールドを抽出
- メディア資産管理: マーケティング ビデオ、ニュース コンテンツ、放送メディア、テレビ番組、映画アーカイブから構造化情報を抽出
- 広告: 広告の分析とモデレーション
メディア資産管理
以下のデフォルトのスキーマに新製品の名前のフィールド NewProductName を追加しています。


ビデオのトランスクリプト(WEBVTT)と共に、スキーマ定義した 5 つのフィールドにセグメントの情報が入ります。動画内の背景に映る文字の説明、何を説明しているシーンかの説明、ビデオカテゴリー、言及された NewProductName もしっかり抽出されました。
広告
広告テンプレートのほうがデフォルトスキーマの数が豊富です。自分でフィールドを追加しなくても Brand というフィールドが用意されていました。

ブランド名や感情分類もよく抽出されていて広告戦略やパフォーマンス分析に利用できそうです。

BrandIntroduction
このセグメントでは、繰り返し作業を減らすという役割を強調しながら、Copilot Actions に関する発表を締めくくります。
Description
このセグメントでは、Copilot Actions に関するプレゼンテーションの続きが紹介され、スピーカーは「aka.ms/CopilotActions」と書かれたシンプルでクリーンな背景の前で説明を行っています。製品の利点に焦点を当てたわかりやすい内容となっています。
さいごに

非構造化ファイルをスキーマに従って構造化してくれるというのは、さながらマルチモーダルにおける Structured Outputs とでも言いましょうか。マルチモーダル RAG のデータ加工パイプラインの重要な要素となりそうですね。