DS-STAR(Data Science Agent via Iterative Planning and Verification) は、Google Cloud のチームが発表した素晴らしい論文で、大規模言語モデル(LLM)を活用したデータサイエンスエージェントの新しいアプローチです。従来手法が抱えていた「異種データ形式への対応」と「計画の妥当性検証」という 2 つの課題を解決し、DABStep、KramaBench、DA-Code の 3 つのベンチマークで SOTA を達成したとのことです。
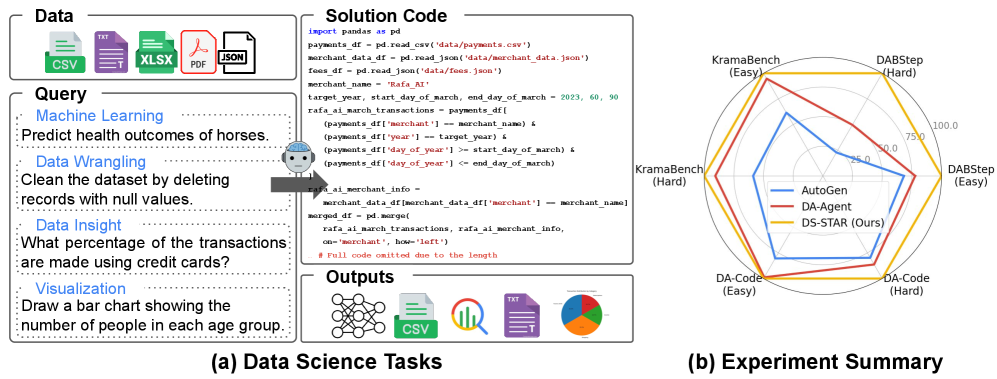
図1は、データサイエンスエージェントが異種形式の複数ファイルを処理して予測や分析を行う仕組みと、DS-STARが難易度の高いタスクにおいて既存手法を大きく上回る精度を示す
AutoGen の精度が低く出てるけど?
論文では AutoGen をどんなアーキテクチャで実装したのか? が記載されておらず、高度な Magentic-One のような反復的計画フローは使用されていないと想定されます。ベースラインとして標準的なマルチエージェント会話フレームワークを使用したのだとしたらなおさらです。
本記事では、勉強がてら DS-STAR のマルチエージェントアーキテクチャの理解と Microsoft Agent Framework を使用して実装までやっちゃいます。
背景と課題
データサイエンスワークフローの複雑な点
データサイエンスは、生データから実用的なインサイトを抽出する重要なプロセスですが、以下のような課題がありました。
- 多様なデータソースの処理: CSV、JSON、Excel、マークダウン、非構造化テキストなど
- 複雑な分析ステップ: データ探索、前処理、統計分析、機械学習、可視化など
- 専門知識の要求: コンピュータサイエンス、統計学、ドメイン知識の融合
既存 LLM エージェントの限界
従来のデータサイエンスエージェント(例:Data Interpreter)には以下の制限がありました。
- 構造化データへの偏重: 主に CSV やリレーショナルデータベースのみをサポート
- 検証メカニズムの欠如: コードの実行成功 ≠ 正しい答え
- 最善ではない計画: 一度に完全な計画を立てるため、柔軟性に欠ける
DS-STAR の 3 つの革新ポイント
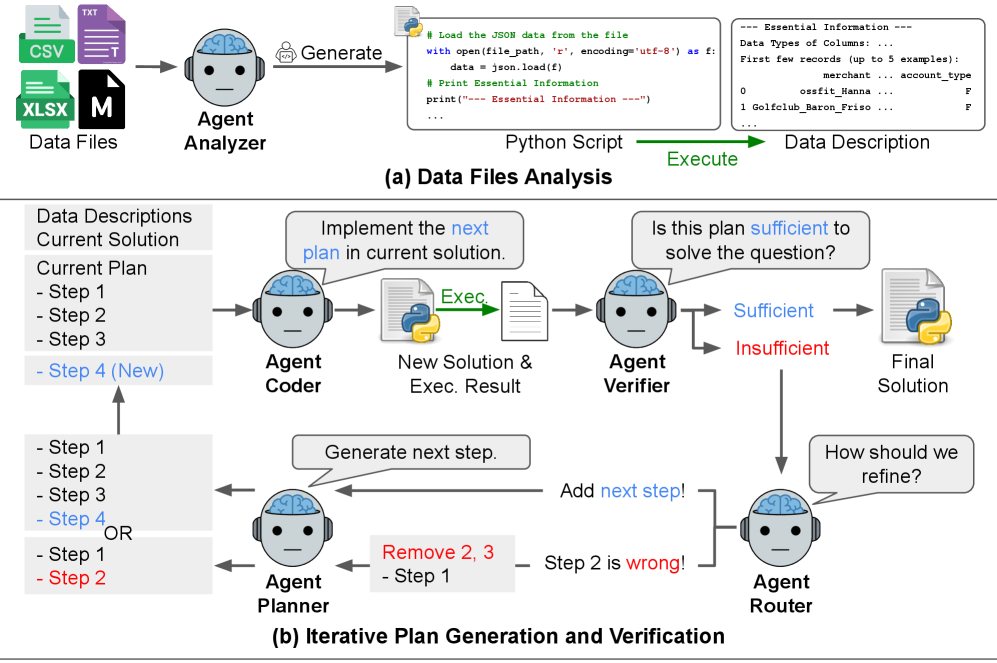
図2: DS-STAR の概要。こーれは単一エージェントじゃ無理やろな…
- DS-STAR は、異種の入力データ ファイルを分析するために不可欠な情報を抽出する Python スクリプトを生成します。
- DS-STAR は、単純な 1 つのステップである初期プランから始めて、プランを実装し、実行して中間結果を取得します。
- 次に、検証エージェントを使用して、DS-STAR は、現在のプランがユーザーのクエリを解決するのに十分かどうかを判断します。十分であれば、現在実装されているコードが最終的なソリューションになります。そうでない場合、DS-STAR のルーター エージェントは、次のステップを追加するか、現在のプランから誤ったステップを削除するかを決定します。
- 最後に、DS-STAR は次のステップを追加し、それを再度実装します。計画、実装、実行、検証のこの反復プロセスは、検証エージェントがプランがユーザーのクエリに十分であると判断するまで、反復の最大回数に達するまで繰り返されます。
1. データファイル分析モジュール(Data File Analysis Module)
現実のデータサイエンスプロジェクトでは、CSV だけでなく、JSON 設定ファイル、Excel レポート、マークダウンドキュメント、テキストログなど、多様な形式のデータが混在します。
Text-to-SQL アプローチ(DIN-SQL、CHASE-SQLなど)は、リレーショナルデータベースに特化しており、非構造化データには対応できません。また、従来のエージェントは「CSV の最初の数行を表示する」程度の単純な方法しか持っていませんでした。
これではマークダウンファイルや JSON 階層構造を理解できず、KramaBench のような複雑なデータレイクタスクで苦戦します(DA-Agentで39.79%)。
解決策:
DS-STAR の Analyzer エージェントは、各ファイル形式に応じた専用の分析スクリプトを動的に生成します。
- CSV: 列名、データ型、統計情報、欠損値
- JSON: 階層構造、キー一覧、ネストレベル
- Excel: シート名、各シートの構造
- テキスト/マークダウン: メタデータ、要約、キーワード抽出
この柔軟なアプローチにより、DS-STAR は KramaBench で 44.69% の精度を達成し、1,500 以上のファイルから関連データを正確に発見・活用できます。
かなり柔軟ですね・・・この部分まで動的に生成しちゃうなんて。もし非構造化ファイルが多い場合は、Azure AI Document Intelligence を使用するように指示するのもよいかもしれません。
2. LLM ベースの検証ステップ(Verification Step)
DS-STARは、単なる実行成功ではなく、「計画がユーザーのクエリに答えるのに十分か」を明示的に評価します。
解決策:
Verifier エージェントは以下を確認します。
- クエリで問われた質問に直接答えているか
- 数値的な結果が具体的に示されているか
- 複数の条件がある場合、すべて満たされているか
この検証ステップにより、DS-STAR は「動くが役に立たないコード」の生成を回避できます。結果として、 Hard-level タスクで 45.24% という他手法の2倍以上の精度を達成しました。
3. 逐次的計画メカニズム(Sequential Planning Mechanism)
複雑なデータサイエンスタスクは、最初から完璧な計画を立てることが困難です。実際のデータサイエンティストは、データを見ながら「次に何をすべきか」を判断し、必要に応じて方向転換します。
多くのエージェントは最初に包括的な計画を立てようとしますが、これには 2 つの問題があります。
- 過度に複雑な計画: 一度にすべてを解決しようとして、実装不可能なコードを生成
- 修正不能な計画: 誤った方向に進んでも、途中で軌道修正できない
その結果、DA-Agent でさえ Hard-level タスクで 22.49% の精度にとどまりました。
解決策:
DS-STAR は人間のデータサイエンティストの思考プロセスを模倣します。(逐次的計画と適応的修正)
- シンプルな第一歩: 「まずデータを読み込もう」のような単純なステップから開始
- 結果を見て次を決定: 各ステップの実行結果を確認してから次の計画を立てる
- 間違いに気づいたら戻る: Router エージェントが誤ったステップを検出し、そこまで巻き戻して再試行
この「計画 → 実装 → 検証 → 改善」のループにより、DS-STAR は平均 5.6 回の反復で Hard-level タスクを解決します。一方、従来手法は 1 回の試行で失敗するか、修正不能な計画に固執します。
AutoGen の Magentic-One アプローチとの類似性
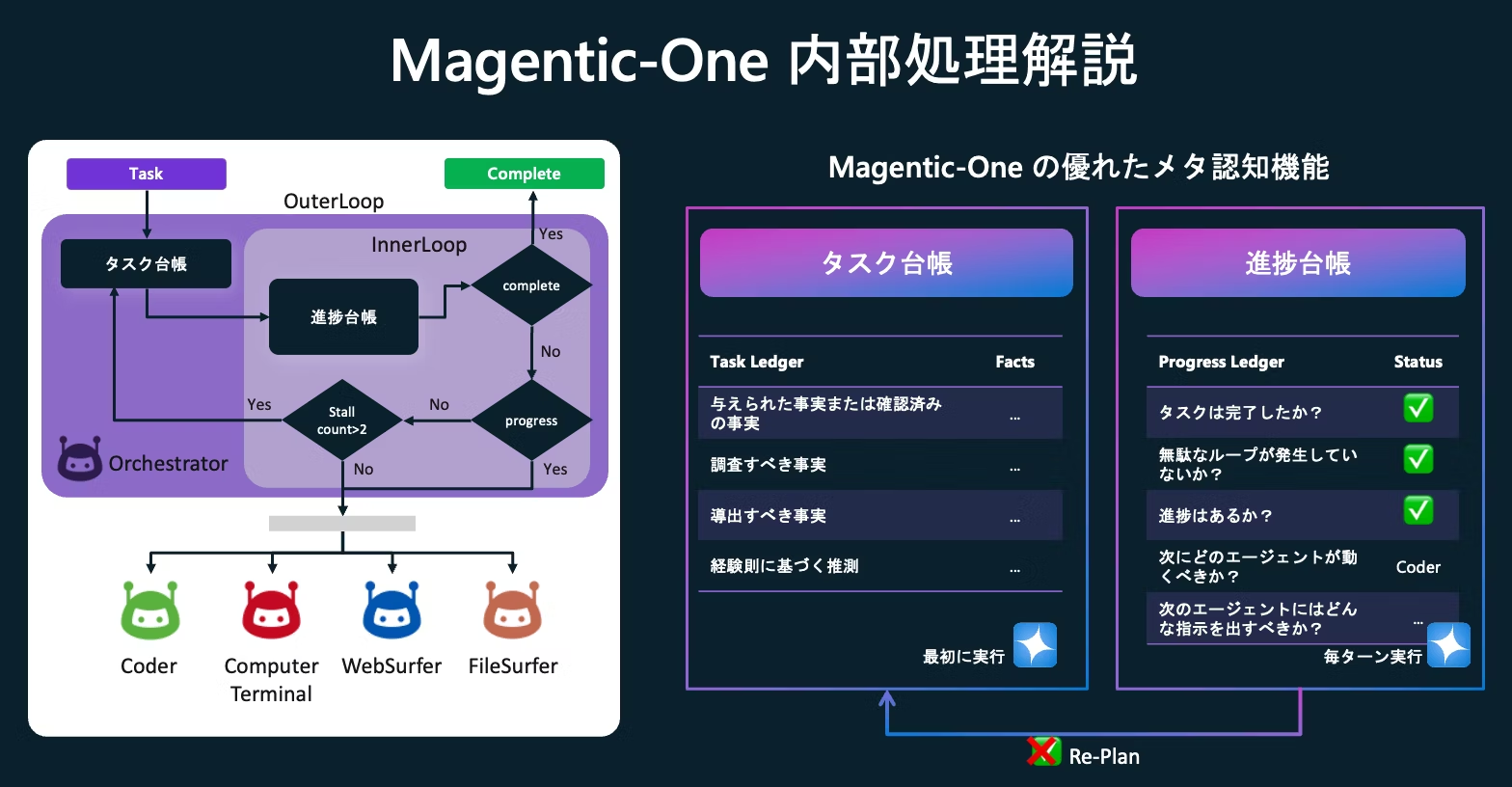
私はこれまで AutoGen の Magentic-One デザインパターンを紹介してきましたが、 Magentic-One には内部ループとしての進捗台帳のトラッキングおよび、外部ループとしての計画修正の機能が実装されており、組み込みの Coder エージェントや Computer Terminal エージェント、FileSurfer エージェントをデフォルトで用いた場合に、DS-STAR のような「計画 → 実装 → 検証 → 改善」のループがある程度実現可能であると考えています。※逐次改善ではないが。
これについては今後同じタスクで精度を比較してみましょう。
Microsoft Agent Frameworkでの実装アプローチ
アーキテクチャ概要
DS-STAR を Microsoft Agent Framework で実装する際、論文で提案されたエージェントを効率的に統合します。そのまま実装するとちょっと複雑になるので、独自にエージェントを統合してシンプル化を図っています。例:Debugger Agent を統合
エージェント構成例
# 1. Analyzer Agent: データファイル分析
analyzer = ChatAgent(
id="analyzer",
name="DataFileAnalyzer",
instructions="""
専門的なデータアナリストとして、与えられたデータファイルを
読み込んで説明するPythonスクリプトを生成してください。
重要な情報を出力し、ダミーの内容を避け、
スクリプトをtry/exceptでラップしないでください。
""",
chat_client=chat_client,
)
# 2. Planner Agent: 計画立案
planner = ChatAgent(
id="planner",
name="SequentialPlanner",
instructions="""
データサイエンス計画者として、初期計画の作成、
および以前の結果に基づく計画の拡張・修復を行います。
シンプルで実行可能な分析計画をステップバイステップで作成してください。
""",
chat_client=chat_client,
)
# 3. Coder Agent: コード実装
coder = ChatAgent(
id="coder",
name="PythonCoder",
instructions="""
データサイエンティストとして、クリーンで正確なPythonコードを生成してください。
重要: 生成するコードには必ずprint()文を含めて、
計算結果や中間結果を標準出力に表示してください。
""",
chat_client=chat_client,
)
# 4. Verifier Agent: 検証
verifier = ChatAgent(
id="verifier",
name="PlanVerifier",
instructions="""
検証の専門家として、分析結果がクエリに十分に答えているかどうかを
評価してください。'Yes'または'No'のみで答えてください。
""",
chat_client=chat_client,
)
# 5. Router Agent: ルーティング判断
router = ChatAgent(
id="router",
name="PlanRouter",
instructions="""
計画の専門家として、分析計画に新しいステップを追加するか、
既存のステップを修正するかを決定してください。
""",
chat_client=chat_client,
)
ワークフロー設計
Microsoft Agent Framework の WorkflowBuilder を使用して、DS-STAR の反復的計画と検証フローを実装します。
from agent_framework import WorkflowBuilder
workflow = (
WorkflowBuilder()
.set_start_executor(initialize)
# Phase 1: File Analysis Loop
.add_edge(initialize, analyze_files, condition=has_unanalyzed_files)
.add_edge(analyze_files, analyzer)
.add_edge(analyzer, process_analysis)
.add_edge(process_analysis, analyze_files, condition=has_unanalyzed_files)
.add_edge(process_analysis, plan, condition=analysis_complete)
# Phase 2: Planning
.add_edge(plan, planner)
.add_edge(planner, process_plan)
# Phase 3: Code Generation & Execution
.add_edge(process_plan, generate_and_execute_code)
.add_edge(generate_and_execute_code, coder)
.add_edge(coder, execute_generated_code)
# Phase 4: Verification
.add_edge(execute_generated_code, verify)
.add_edge(verify, verifier)
.add_edge(verifier, process_verification)
# Conditional: Sufficient or Insufficient
.add_edge(process_verification, prepare_final_answer, condition=is_sufficient)
.add_edge(process_verification, route, condition=is_insufficient)
# Phase 5: Routing & Plan Refinement
.add_edge(route, router)
.add_edge(router, process_routing)
.add_edge(process_routing, plan) # Loop back to planning
# Phase 6: Finalization
.add_edge(prepare_final_answer, finalize)
.build()
)

まずはリファレンス実装としてこのような感じになるかと。ChatAgent だけで繋げられればいいのですが、プロンプトの整形、データの評価や条件分岐処理を含めるとノードが一気に増えてしまいます。
今後のカスタマイズ例として、Coder エージェントの部分を Azure AI Foundry Agent Service に置き換えてマネージド化された Code Interpreter を実装することもできますよね。
Shared States の実装
Microsoft Agent Framework の最新機能 Shared States を使用してフロー内の状態を管理します。
# 共有状態初期化
await ctx.set_shared_state(STATE_KEY_QUERY, query)
await ctx.set_shared_state(STATE_KEY_ITERATION, 0)
await ctx.set_shared_state(STATE_KEY_PLAN_STEPS, [])
await ctx.set_shared_state(STATE_KEY_CURRENT_CODE, "")
await ctx.set_shared_state(STATE_KEY_FILE_DESCS, state.file_descriptions)
await ctx.set_shared_state(STATE_KEY_LAST_RESULT, "")
await ctx.set_shared_state(STATE_KEY_ROUTER_ACTION, None)
await ctx.set_shared_state(STATE_KEY_EXECUTION_PATH, [])
サンプルデータ実験
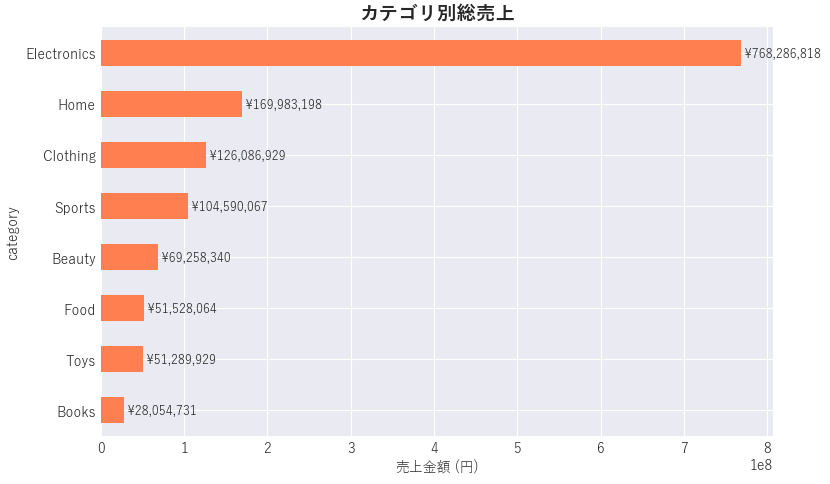
50,000 行の仮想的な小売トランザクションデータを用意して、「各カテゴリの総売上高はいくらですか?また、最も売れているカテゴリを特定してください。」というタスクを解かせてみましょう。
transaction_id,date,store_id,customer_id,category,quantity,unit_price,discount_rate,total_amount,year,month,day_of_week,week,is_weekend
TXN_032358,2022-01-01,Store_09,CUST_04380,Home,4,7412.262230548731,0.0,46252.51631862408,2022,1,5,52,1
TXN_014592,2022-01-01,Store_10,CUST_04516,Clothing,3,5258.014177418107,0.0,24607.50635031674,2022,1,5,52,1
TXN_002420,2022-01-01,Store_06,CUST_01221,Clothing,1,4272.04853594357,0.0,6664.395716071968,2022,1,5,52,1
実行
================================================================================
DS-STAR v5 (Optimized): Iterative Planning and Verification
Query: 各カテゴリの総売上高はいくらですか?また、最も売れているカテゴリを特定してください。
================================================================================
Phase 1: Analyzing data files...
Found 1 files
Analyzing: synthetic_retail_transactions.csv
Generated analysis code for synthetic_retail_transactions.csv:
------------------------------------------------------------
<生成したコード>
✓ Analysis successful
✓ All files analyzed
Phase 2: Creating initial plan...
============================================================
Initial Plan Generated:
============================================================
ステップ1(最初の実行作業):
- data/synthetic_retail_transactions.csv を読み込み、列名・データ型・先頭数行・欠損の有無を確認する。加えてトランザクションごとの売上額を表すカラム(例:sales, revenue)が存在するかを確認し、存在しなければ quantity × unit_price(または price)で新しく作成する。
-
Phase 3: Generating code (Iteration 1)...
============================================================
<生成したコード>
============================================================
✓ Execution Success
============================================================
Output:
Attempting to read file: data\synthetic_retail_transactions.csv
Phase 4: Verification...
============================================================
Verifier Response:
============================================================
Yes
============================================================
Result: ✓ SUFFICIENT (Yes)
============================================================
================================================================================
DS-STAR v5 Analysis Complete
Total iterations: 1
Final answer:
Total sales by category (sorted descending):
Electronics: 768286818.22
Home: 169983198.34
Clothing: 126086929.31
Sports: 104590067.31
Beauty: 69258339.91
Food: 51528063.66
Toys: 51289928.94
Books: 28054730.99
Top category: 'Electronics' with total sales = 768286818.22
Overall total sales (sum over all categories): 1369078076.69
事前に Jupyter Notebook で計算していた正解と同じことが確認できました🎉
実行パス
最終出力に実行されたワークフローのパスを表示するようにしています。最短では以下のような実行パスになるはずです。
================================================================================
EXECUTION PATH TRACE
================================================================================
Total steps executed: 10
Execution sequence:
1. analyze_files
2. process_analysis
3. plan
4. process_plan
5. generate_and_execute_code
6. execute_generated_code
7. verify
8. process_verification
9. prepare_final_answer
10. finalize
NG: Verifier エージェントが INSUFFICIENT と判断した場合
Router エージェントに制御が移り、分析計画に新しいステップを追加するか、既存のステップを修正するかを決定します。
================================================================================
EXECUTION PATH TRACE
================================================================================
Total steps executed: 18
Execution sequence:
1. analyze_files
2. process_analysis
3. plan
4. process_plan
5. generate_and_execute_code
6. execute_generated_code
7. verify
8. process_verification ⭐
9. route ⭐
10. process_routing ⭐
11. plan ⭐
12. process_plan
13. generate_and_execute_code
14. execute_generated_code
15. verify
16. process_verification
17. prepare_final_answer
18. finalize
まずは簡単なデータサイエンスタスクを実行してみましたが、今後はより高度なタスクについても実行していきたいと思います。
GitHub
論文をベースにした参考実装。
参考