できたもの(途中経過)
F-ZEROのコースをsegmentationする深層学習モデルをJetson Nano上で動かしています.480x288,30FPSで処理できています.
Realtime "F-ZERO" course segmentation model is running on Jetson Nano. It is part of "gaming AI making challenge" as my personal work.#jetson #nvidia pic.twitter.com/AYCqE75JbG
— nobu_e753 (@nobu_e753) September 27, 2019
キャプチャしたものはこちら(キャプチャの過程で負荷がかかり,レートが落ちています)
Realtime "F-ZERO" course segmentation model is running on Jetson Nano (captured movie)#jetson #nvidia pic.twitter.com/gnn79ys9Oa
— nobu_e753 (@nobu_e753) October 1, 2019
はじめに
強化学習と聞くと真っ先にイメージするのがゲームの自動プレイです.ちょっと試してみたいな..と思い論文や既存の実装を見るも,どうも馴染みのないゲームが題材にされていることが多いようでした.ROM入手にかかわることが大きいのでしょう.
そこで,どうせ勉強を兼ねて試すなら"自分が遊んだ・好きなゲームで試してみたいよね"ということで,そういったシステムをどう構築するか?から取り組んでみました.
この記事はその前編で,システムの構築までを取り扱います.
1. ゲームの選定
以前から格闘ゲームのハックはしてきたので今回もと思ったのですが,キャラクターが2人いたり動きに自由度があり,難易度高そうな感ぷんぷんでした.初トライで高難度は勘弁...ということで,
- レース or シューティング(一方方向にしか動かないゲームが解析しやすいと聞いたので)
- 背景がシンプルで,数値等の読み取りがしやすい
- 自分が遊んだことがある**(モチベーション維持のため最重要!)**
という条件をもとに考えた結果**,F-ZERO**(初代,1990年,スーパーファミコン)にしました.ロケットスタートとか,ジャンプ台でのショートカットとか,それなりに遊んでいた記憶があります.
なお,強化学習 x F-ZEROについてはいくつも先行事例があり,タイトルに"F-ZERO"とはいった論文(Racing F-Zero with Imitation Learning, 2017)や,まんまなチュートリアル動画"FZERO AI - PPO2 and A2C - OpenAI and Stable-baslines"は見ているだけでも面白いです.
2. 全体構成
**"自分の好きなゲームで強化学習をしたい"**というのが今回のコンセプトなので,ゲーム機実機を組み込んだ構成としました.またどうせやるなら,ということで計算機にはJetson Nanoを充ててみました.学習はともかく推論ができれば,"Jetson Nano限定AIゲーム大会"なんてのも夢ではないかもしれません(是非やりたいです).なおソニックは大会があったみたいですね.
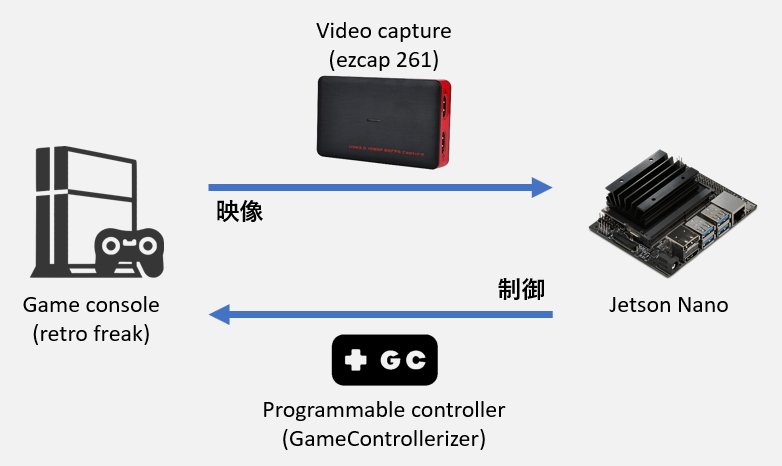
使用した機材
- Jetson Nano (ML computer)
- Retro freak (Game console)
- ezcap 261 (Video capture)
- GameControllerizer (Game controll)
ML computerについては,当初Edge TPUを使う予定でしたが,量子化手順がめんどくさすぎるのでパスしました.Video captureについてはezcap 261を選択.この機種はUVC(USB Video Class)&Linuxに対応していることが明記されており,かつ安価であることから選びました.
キャプチャユニットをJetson Nanoに接続しcv2.VideoCapture()をたたくだけで,だらだらとゲーム画面がやってきます.
import cv2
cap = cv2.VideoCapture(-1) # 0はカメラのデバイス番号
cap.set(cv2.CAP_PROP_FPS, 30) # カメラFPSを30FPSに設定
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280) # カメラ画像の横幅を1280に設定
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720) # カメラ画像の縦幅を720に設定
ret, frame = cap.read() # 画像を取得
ゲーム機実機を使った場合「学習が一生終わらない」なんてことになるかもしれませんが,そうなったらその時に考えることにします.
3. 情報の抽出
とっかかりはゲーム画面からの情報の抽出です.ゲーム強化学習で一般的なフレームワークGym retroと異なり,システムをゼロから組んだ場合はこれが第一の壁になります.必要な情報としては
- Power
- Speed
- Time (option)
- Course (option)
位と考えました.
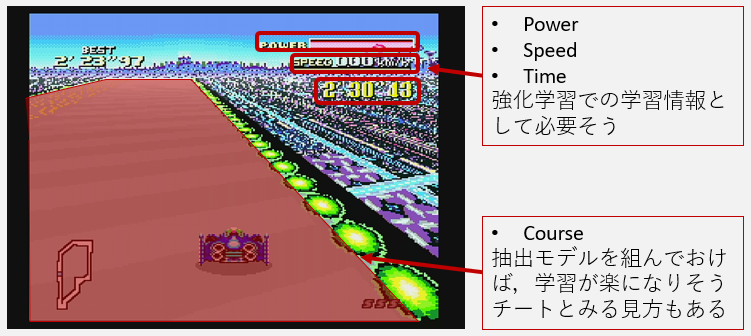
まず初めに各情報の位置をメモしておき,それぞれ取り掛かることにしました.

3.1 Power
最初は「赤色部分の長さ」で判別しようとしましたが,Powerゲージが25%を切ると点滅し赤⇔グレーを繰り返すのでうまくいきませんでした.そののち,ゲージ部分を観察し右側に黒線があることに気づいたので,X方向で輝度最低のPixel位置を求めるような判定ルーチンを組みました.
3.2 Speed
これも最初は適当にテンプレートマッチング(SSD,SAD)すればいけるんじゃね?と思ってやったもののダメでした.数字が微妙に透過しているせいで背景の影響を受け精度が散々でした.
仕方ないので小型のCNNで判別することにしました.28x24サイズで10クラスなのでMNISTとほぼ同等です.
DIGIT_SIZE = [24, 28, 1]
def __build_model(lr=1e-3):
# functional
i = k.layers.Input(DIGIT_SIZE, name="input_0")
x = k.layers.Conv2D(8, (3,3), activation="relu", padding="valid")(i)
x = k.layers.MaxPool2D()(x)
x = k.layers.Flatten()(x)
x = k.layers.Dense(10, activation="softmax", name="output")(x)
model = k.models.Model(inputs=i, outputs=x)
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=k.optimizers.Adam(lr=lr, decay=1e-5),
metrics=['accuracy'])
return model
学習データはゲーム画面からクロップして仕訳けました.計685枚.
 )
)
学習部はtf.kerasのお作法そのままです.1点だけ,収集した事例数が結構偏っていたので,この差を緩和するためにlabels_weightで事例重みを渡してやっています.問題が簡単なせいか,すぐにAccuracy = 1.0に.
# Found 685 images belonging to 10 classes.
# Counter({0: 154, 3: 99, 1: 76, 2: 67, 6: 55, 5: 53, 7: 51, 4: 48, 8: 45, 9: 37})
model = __build_model()
model.fit_generator(
batch_generator,
epochs=10,
class_weight=labels_weight,
verbose=1)
両者の結果をOverlayで表示したものが以下です.Jetson Nano上でもリアルタイムで楽々動きます.
Speed & power value extraction from F-ZERO screen. The image processing program is running on JetsonNano. For speed value extraction, very small CNN model is used.#jetson #nvidia pic.twitter.com/wVJtNCy3th
— nobu_e753 (@nobu_e753) October 1, 2019
3.3 Time (option)
ひとしきり考えた末,スキップすることにしました.
[より短いTime] := [高いSpeed] かつ [Powerが減っていない]
と読み替えていいのではと.サボりですw
3.4 Course (option)
シンプルな強化学習であればコース情報は強化学習中に自動で獲得してゆくものでしょう.ただ,**あらかじめコースを抽出できるモデルを組んでおけば,学習時間を短縮できるのでは?という思いからトライしてみました.またJetson Nano上でSegmentationタスクを動かしたとき,どのくらいのパフォーマンスを出せそうなのか?**ということにも興味がありました.
モデル検討
とにかく早いモデルにしておこう,ということで,Segmentationデータセットとして有名なCityscapeのベンチマークで最速のモデルを探してきました.
- Fast-SCNN: Fast Semantic Segmentation Network, 2019
- https://arxiv.org/abs/1902.04502
1024 x 512 処理時に285 FPSとのことなので期待が持てます(実際はさらにchannel数を半分に切りつめ,入力画像サイズ480 x 288で利用しました).ありがたいことにFast-SCNNのTensorflowでの解説付き実装も公開されていました.
学習データ
こればっかりはどうしよもないので気合で対応,1面(Mute city),2面(Big blue)からそれぞれ75 frameずつ,計150 frameに対して,アノテーション(コース,磁力帯)を作成しました.作成には,ブラウザ上で動くフリーの教師作成ツールAnnoFabを使いました.作成時間は1時間強でした.
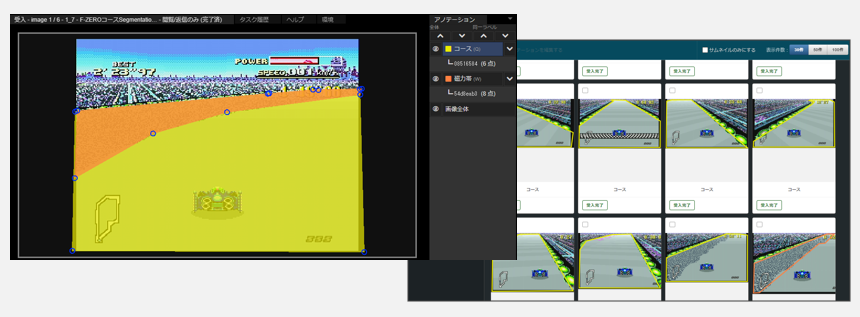
学習&推論
磁力帯を無視し,ひとまずコースだけをsegmentationする学習フローを構築.学習は5000ステップ(適当),RTX 2080i上で18分かかりました.静止画に対する適用結果を確認すると,えいやで作ったモデルのわりに推論結果もまあまあです.
唯一,自車がコース端に激突しエフェクトが走るとsegmentation結果が甘くなりますが,これは学習データ追加でカバーできるでしょう.

速度がでない!
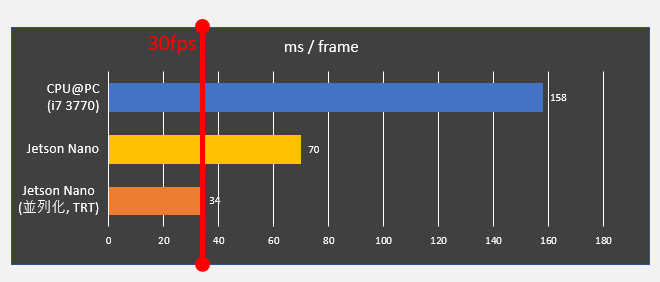
モデルが出来あがりウキウキでJetson Nanoにマッピング,動画を処理してみるも速度が出ません!カクカクです!! 調べてみると
オーバーレイなどの事前事後処理が遅い
でした.segmentation部分を視覚化するためにマスクを作ったりオーバーレイをしたりという事後処理をOpenCV+numpyで書いていたのですが,この処理だけで50-60msかかっていました.逆にCNNの部分は30msec以下でした.
Edge deviceの場合,CNNについてはGPUというアクセラレータがついているのに対して,CPUは貧弱なのでこういう結果を生んだと考えられます.本件に限らずEdge deviceを利用する場合は注意が必要そうです.
高速化(並列化,TF-TRT)
このままでは学習に影響が出そうですし,なにより悔しいので高速化してみました.
並列化
Pythonのmultiprocessing.Processを使って,処理を
- 前処理(キャプチャ,縮小)
- Segmentation
- 後処理(オーバーレイ,表示)
の3つに分割,パイプラインで実行できるようにしました.
Jetson上でGPUの使用率を確認するツールjtopで状況を確認してみると,使用率が如実に改善されていました.
TF-TRT(TensorFlow with TensorRT optimization)
割と使えそうなのがこちらです.Jetson Nano上でCNNモデルを動作させる場合,
- Tensorflowモデルのまま,Tensorflow runtime上で動かす
- TensorRTで最適化したモデルを,TensorRT runtime上で動かす
があります.もちろん2のほうが高効率ですがモデル内にTensorRTサポート外オペレーションを含んでいると最適化ができません.例えば今回のモデルにはResizeBilinearオペレーションが含まれており,これがTensorRT(5.X)非サポートでした.
しかしドキュメントをよく読むと,これ以外に第3の選択肢があり**「TensorRTで対応しているオペレーションだけ最適化を行いこれはTensorRT runtime上で動かす.その他はTensorflowモデルのままTensorflow runtime上で動かす」**ハイブリッドな方法が存在します(公式ページ)
導入方法も簡単で,Tensorflowの推論グラフ(.pb)を読み込んだ後に,数行付け加えるだけです.導入後に推論部のみの速度を計測したところ 24ms → 15ms と大きな改善がみられました.
# TF-TRT導入に必要
from tensorflow.python.compiler.tensorrt import trt_convert as trt
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction = 0.65)
...
graph = tf.Graph()
with graph.as_default():
model_file = open(pb, 'rb')
graph_def = tf.GraphDef()
graph_def.ParseFromString(model_file.read())
#############################################
# TF-TRTむけの追加部分
converter = trt.TrtGraphConverter(
input_graph_def=graph_def,
# precision_mode="FP16", # 演算モードも選べる
nodes_blacklist=[OUTPUT_NODE])
graph_def = converter.convert()
#############################################
tf.import_graph_def(graph_def, name="")
最適化前後のsegmentation速度です.なんとか30 fps達成です.これで冒頭のようなリアルタイムsegmentation画面を表示することができました.
まとめ
"自分の好きなゲームで強化学習をしたい"というコンセプトをもとに,これを可能にするシステムを構築してみました.あわせて,計算機部分にEdge device(Jetson Nano)を試用してみたことで,その特性を知ることができました.
特にJetson Nano上でリアルタイム処理を実現しようとする場合,
- GPUと比較してCPUが貧弱なので,CNN以外の処理負荷にも注意
- TensorRTが適用できない場合にも,TF-TRTがある
の2点は大変よい知見となりました.
足回りができたので,いよいよ本題の強化学習です.自動プレイでMute cityを1周出来るのがいつになるかはわかりませんが,本業の合間にのんびりやっていきます.
挑戦者待ってます!