Powered by DLHacks
はじめまして、マンボウです。普段は信号処理や画像解析をやっています。
唐突ですが、PythonからピンポイントにCUDAの機能を利用できるCuPyのElementwiseKernelを紹介します。
CUDAと言っても恐れることはなく、「C++の記法をなんとなく理解している」レベルの人でも簡単に利用できます。
はじめに
Pythonは書きやすく読みやすいので私は好きです。
しかし、膨大な信号や大量の画像をPythonで扱っていると、どうしても速度が気になりだします。
かといって、全てをC++やCUDAで書き直すのも骨が折れます。
特に、データ解析で1回しか使わないようなコードを頑張ってC++やCUDAで仕上げるのは辛いです。
「『この部分だけ』で良いんや!折角GPU積んでるんだから『この部分だけ』CUDAで書かせてくれ!」 と思うことが多々あるのです。
CuPyのElementwiseKernelはそんな時に大活躍してくれます。
本記事では、まずCuPyのElementwiseKernelの基本的な機能を紹介します。
そして、次にドキュメントのチュートリアルに載っていないようなちょっと突っ込んだ(?)使用例も紹介します。
CuPyとは
CuPyはPreferred Networks社が開発しているオープンソースの高速な行列計算ライブラリです。
DeepLearningフレームワークChainerのバックエンドにも使われているそうです。
中身はNumPyのGPU版みたいなやつで、npをcpにするだけでGPUに最適化された演算をしてくれます(雑)。
CuPyのページを見ればだいたい分かるので、このあたりは本記事では説明しません。
本記事では、npをcpにする以上のことができるElementwiseKernelを紹介します。
ElementwiseKernelとは
ElementwiseKernelはCuPyの機能のひとつで、一言で説明するなら (簡略化された)CUDAカーネルを記述してPythonから実行できるようにするやつ です。
npをcpにするのは「CPUに最適化された実装からGPUに最適化された実装への変化」に対応しますが、
ElementwiseKernelは 「NumPy化が難しく(=CPUに最適化するのが難しく)PythonのForループになっていた遅い部分をGPUで実行する」 みたいなことも可能になります。
例えるなら、前者は「マンボウ界のウサイン・ボルトからそこそこ速いイルカへの進化」でしたが、
後者は 「冴えないマンボウから普通のイルカへの進化」 みたいなことが起こります。
冴えないアイツが驚異的な速度で動き出す様には水槽のお友達もドン引きです。
さらに、ElementwiseKernelは、CUDAカーネルの中身だけを記述するので、機能の実装に専念することができます。
CuPyがCUDAのラッパーになってくれているので、通常のCUDAプログラミングで必要な並列化の実行計画(ブロック数・スレッド数などの調整やメモリ管理みたいなこと)をあまり気にせずに楽に使えます。
このように、楽で速い というのがElementwiseKernelの良いところです。
これから、ElementwiseKernelの使いどころ、使い方を見ていきます。
ちょっとその前に… Pythonで手軽にできる高速化
Pythonで書いたコードが遅いとき、Forループがボトルネックになっていることが多々あります。
そのようなPythonのForループ部分をC/C++の実装に置き換えることで手軽に速くするには以下のような手段があるかと思います(Cythonみたいなのは話がややこしくなりそうなので無視します)。
- できるだけNumPyを使う(行列演算全般)
- OpenCVを使う(例えば、filter2Dは自分で定義したフィルター処理を速く実行できます。エッジ抽出、鮮鋭化、DeepLearningのConvolutionのような処理ができます。)
- scikit-imageを使う(例えば、block_reduceはDeepLearningのPoolingのような処理を速く実行できます。)
これらがうまくハマる部分は、無理にCUDAにしなくてもそこそこ速く動いてくれるのではないかと思います。
ElementwiseKernelの使いどころ
上記の手軽にできる高速化に当てはまらない、かつ、並列化できそうな処理に使える場合が多いです。
例えば、以下のような場合です。
- 配列(行列・テンソル)の要素ごとに同じような処理をしたい
- バッチで入力した画像全部に同じような処理をしたい
「同じような」とか「並列化できそうな」が曖昧で難しいところですが、あまり深入りはしないことにします。
もう少し具体的にユースケースを挙げると、以下のような感じになります。
- Pythonで画素を走査するようなforループを書いた時
-
Kaggleなどで、大量の画像すべてに簡単な前処理をしたい時
- (画像サイズはある程度そろっている想定)
このような時、全てをC++やCUDAで書き直さなくても、ボトルネックになっている部分だけ高速化できるのがElementwiseKernelです。
ElementwiseKernelの基本
CUDAのおさらい
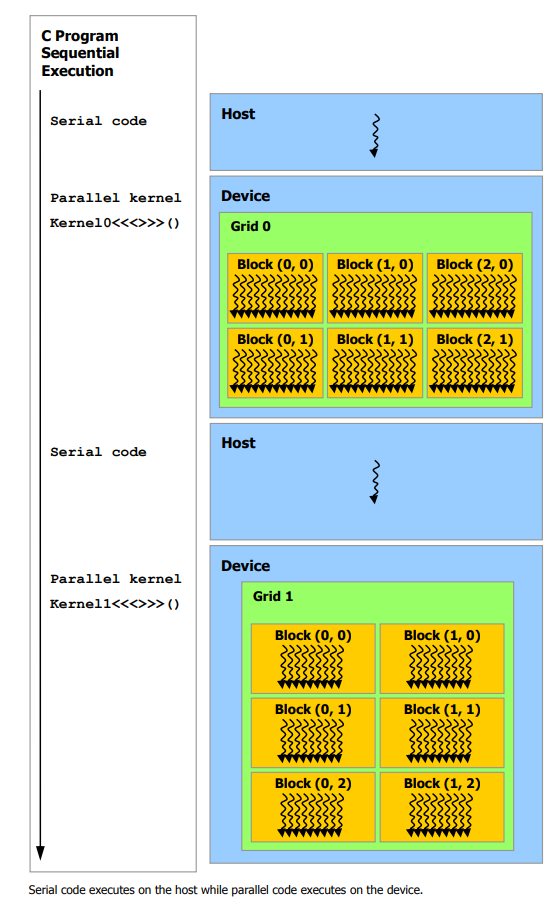
通常のCUDAプログラミングでは、CPU上で動くmain関数をC/C++で記述していき、GPUで実行したい部分はCUDAカーネルという関数を呼び出すことでCPUとGPUを協調させます。
下の概要図はHostがCPU、DeviceがGPUに対応していて、Kernel0<<<>>>()やKernel1<<<>>>()といったCUDAカーネルが呼ばれるとGPUに処理が移り並列計算が行われる様子を表しています。
(引用: CUDAのプログラミングガイド)
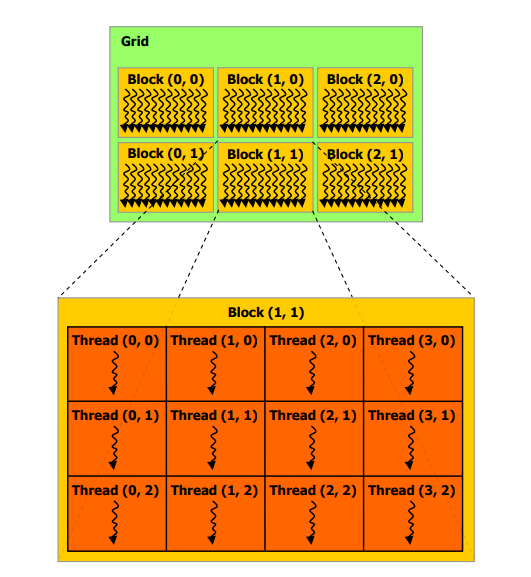
CUDAには色々な並列化の粒度があり、下図ではGridとBlockとThreadが表されています。
CUDAカーネルが呼ばれるとGridが作られ、その中に多くのBlockが、さらにその中に多くのThreadが作られます。
CUDAカーネルを記述する際に主に気にしなければならないのは、二次元的(一次元や三次元的でもOK)に配置されたBlockとThreadです。
(引用: CUDAのプログラミングガイド)
以下の例は、正方行列Aと正方行列Bの足し算をして、結果を正方行列Cに格納するシンプルなCUDAのコードです。
// Kernel definition
__device__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x; // 自身のindexを取得
int j = blockIdx.y * blockDim.y + threadIdx.y; // 自身のindexを取得
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j]; // 足し算
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
(引用: CUDAのプログラミングガイド)
色々見慣れない書き方が有るかもしれませんが、MatAddカーネルの中身だけ説明します。
(それ以外はCuPyがうまく隠してくれるため、今後登場しません。)
CUDAでは、「(並列化の最小単位である)Threadごとに行いたい処理」をCUDAカーネル内に記述します。
このコードでは、「自身のindex(このThreadが配列の何行何列目を扱っているのか)を取得」して「足し算」しているだけです。とても簡単。
blockIdx、blockDim、threadIdxという謎の変数が登場しますが、これらはユーザが定義した変数ではなく、CUDAであらかじめ予約されているビルトイン変数です。
これらには、上の図で二次元的に配置されていたBlockやThreadの位置などが格納されており、
これらによって、並列化されたThread内での添え字アクセスが可能になっています。
(が、これらもCuPyがうまく隠してくれるため、今後登場しません。)
前置きが非常に長くなりましたが、これ以降は、CUDAカーネルをPythonから利用できるElementwiseKernelの使い方を説明していきます。
環境
- Windows 10
- CPU: Intel Core i7-8700K
- GPU: GeForce GTX 1080 Ti
- Python 3.5
- cupy 4.3.0
- numpy 1.15.0
- opencv-python 3.4.2
全要素に対する演算
上でCUDAのコードをお見せした正方行列の足し算をElementwiseKernelで書いてみます。
このような簡単な演算なら、cupy.addや+で済むのですが、練習のためElementwiseKernelを使います。
import cupy as cp
if __name__ == '__main__':
X = cp.arange(9).reshape(3, 3).astype(cp.float32)
Y = cp.arange(9).reshape(3, 3).astype(cp.float32)
# カーネル関数を定義、生成
mat_add_kernel = cp.ElementwiseKernel(
in_params='float32 x, float32 y',
out_params='float32 z',
operation=\
'''
z = x + y;
''',
name='mat_add_kernel')
# カーネル関数の呼び出し
Z = mat_add_kernel(X, Y)
print(X)
print(Y)
print('X + Y = \n', Z)
ElementwiseKernelでは、入力と出力をin_paramsとout_paramsに、処理の内容をoperationに書いて渡します。
上のMatAdd と比較すると、カーネルの中身がシンプルに記述できることがわかります。
結果は以下のようになります。
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
X + Y =
[[ 0. 2. 4.]
[ 6. 8. 10.]
[12. 14. 16.]]
ブロードキャスト
NumPyのようにブロードキャストもいい感じにやってくれます(雑)。
以下では、__main__の中だけを記述します。
X = cp.arange(9).reshape(3, 3).astype(cp.float32)
Y = cp.arange(3).astype(cp.float32)
mat_add_kernel = cp.ElementwiseKernel(
in_params='float32 x, float32 y',
out_params='float32 z',
operation=\
'''
z = x + y;
''',
name='mat_add_kernel')
Z = mat_add_kernel(X, Y)
print(X)
print(Y)
print('X + Y = \n', Z)
結果は以下のようになります。
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
[0. 1. 2.]
X + Y =
[[ 0. 2. 4.]
[ 3. 5. 7.]
[ 6. 8. 10.]]
indexing(現在処理している要素の添え字を取得)
添え字アクセスしたい変数(入力でも出力でもOK)にrawをつけることで添え字アクセスが可能になります。
この時、あらかじめ予約されたiという添え字によってアクセスできます。
また、_ind.size()でiの最大値が取得できます。
CUDAでは、blockIdx、blockDim、threadIdxみたいな変数が出てきましたが、これらをうまく隠してくれているのが分かります。
indexingの例として、配列の要素を1つ左にずらすnp.rollみたいなカーネルを実装してみます(np.rollは右にずらします)。
X = cp.random.randint(low=0, high=10, size=15).astype(cp.int16)
Z = cp.zeros_like(X)
roll_kernel = cp.ElementwiseKernel(
in_params='raw int16 x',
out_params='int16 z',
operation=\
'''
int idx = (i + 1) % _ind.size(); // ひとつ右のindex(溢れたら0に戻る)
z = x[idx];
''',
name='roll_kernel')
roll_kernel(X, Z)
print(X)
print(Z)
ここでは、出力であるZもカーネルの引数として渡している点が前の例と異なります。
ElementwiseKernelは、引数としてraw無しのものが一つでも渡されると、入出力のshapeを自動で推定してくれるそうです(私は仕組みがよく分かっていないのでドキュメントのこの部分を信じることにします)。
上のコードでは入力がrawのため、rawでない出力を渡してあげることでshapeを自動で推定してくれます。
入力も出力もrawが付く場合は、後ほど扱います。
結果は以下のようになります。
[9 0 2 6 2 6 1 2 0 3 8 8 9 9 3]
[0 2 6 2 6 1 2 0 3 8 8 9 9 3 9]
二次元配列のindexing
多次元の変数であってもiによるindexingが可能です。
しかし、「何次元を扱っているか」はユーザが管理しなければなりません。
以下の例を見ると分かりやすいかもしれません。
X = cp.zeros((4, 4)).astype(cp.int16)
Z = cp.zeros_like(X)
ind_size = cp.zeros(1).astype(cp.int16)
get_index_kernel = cp.ElementwiseKernel(
in_params='raw int16 x',
out_params='int16 z, int16 ind_size',
operation=\
'''
z = i;
ind_size = _ind.size();
''',
name='get_index_kernel')
get_index_kernel(X, Z, ind_size)
print(Z)
print('ind_size:', ind_size)
Zにそのままiを格納し、ついでに_ind.size()も受け取ってみます(このように、出力が複数でもOKです)。
すると、結果は以下のようになります。
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
ind_size: [16]
iは一次元的に(?)並んでおり、ind_sizeが全要素の数を表していることがわかります。
(x, y)でアクセスしたい場合は、以下のようにします。
NumPyは表示のためだけにインポートしています。
import numpy as np
X = cp.zeros((4, 4)).astype(cp.int16)
Z = cp.zeros_like(X)
get_index_kernel_2d = cp.ElementwiseKernel(
in_params='raw int16 x, int16 width',
out_params='int16 z',
operation=\
'''
int x_idx = i%width;
int y_idx = i/width;
z = y_idx * 10 + x_idx;
''',
name='get_index_kernel_2d')
get_index_kernel_2d(X, X.shape[1], Z)
# 表示のためにnumpyに変換
Z_numpy = cp.asnumpy(Z)
np.set_printoptions(formatter={'int': '{:02d}'.format})
print(Z_numpy)
結果は以下のようになります。
Zの各要素はy座標を十の位に、x座標を一の位にそれぞれ持つ二桁の数字になっています。
[[00 01 02 03]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]]
channelも考慮したindexing(入力も出力もrawにして、3chの画像にpixel-wiseなアクセスを行う)
3chの画像などをそのまま入力すると、スレッドには「ある画素における、あるchannel」が割り当てられます。
つまり、iの数(=_ind.size())が、画像の幅×画像の高さ×channel数になってしまいます。
「ある画素における、あるchannelごとに」何か処理をしたいならこれでいいのですが、「ある画素ごとに」何か処理をしたい場合はこれでは困ります。
つまり、pixel-wiseなアクセスを行いたいのです。
そのような場合には、以下のように入出力をどちらもrawにして、カーネル呼び出しにsizeパラメータを渡します。
これにより、_ind.size()をユーザが決定することができます。
X = cp.arange(27).reshape(3, 3, 3).astype(cp.int16)
X = cp.transpose(X, axes=(1, 2, 0))
Z = cp.zeros((3, 3, 2)).astype(cp.int16)
ind_size = cp.zeros(1).astype(cp.int16)
get_index_kernel_2d = cp.ElementwiseKernel(
in_params='raw int16 x, int16 width, int16 height',
out_params='raw int16 z',
operation=\
'''
int x_idx = i%width; // 画像のx座標
int y_idx = i/width; // 画像のy座標
z[i*2] = x[i*3] + x[i*3+1];// zの0ch = xの0ch + xの1ch
z[i*2+1] = x[i*3+1] + x[i*3+2]; // zの1ch = xの1ch + xの2ch
''',
name='get_index_kernel_2d')
get_index_kernel_2d(X, X.shape[1], X.shape[0], Z, size=(X.shape[0] * X.shape[1]))
# 表示のためにnumpyに変換
Z_numpy = cp.asnumpy(Z)
np.set_printoptions(formatter={'int': '{:02d}'.format})
print('xの0ch\n', X[:, :, 0])
print('xの1ch\n', X[:, :, 1])
print('xの2ch\n', X[:, :, 2])
print('zの0ch(= xの0ch + xの1ch)\n', Z_numpy[:, :, 0])
print('zの1ch(= xの1ch + xの2ch)\n', Z_numpy[:, :, 1])
この例では、3chの画像Xを入力し、2chの画像Zを出力しています。
入出力がどちらもrawになっています。
Zの0chには、Xの0chとXの1chの和、
Zの0chには、Xの1chとXの2chの和、
が格納されます。
コード内では初期化だけして使っていませんが、x_idx、y_idxがx座標、y座標に対応します。
このようにiとx_idxやy_idxを変換することで、pixel-wiseなアクセスとchannelへのアクセスの両方が可能になります。
結果は以下のようになります。
xの0ch
[[00 01 02]
[03 04 05]
[06 07 08]]
xの1ch
[[09 10 11]
[12 13 14]
[15 16 17]]
xの2ch
[[18 19 20]
[21 22 23]
[24 25 26]]
zの0ch(= xの0ch + xの1ch)
[[09 11 13]
[15 17 19]
[21 23 25]]
zの1ch(= xの1ch + xの2ch)
[[27 29 31]
[33 35 37]
[39 41 43]]
カーネル内で使う関数
カーネル内で使いたい関数はpreambleという引数に渡すことで呼び出せるようになります。
CuPyはoperationなどに渡した文字列をCUDAのコードに変換しているのですが、preambleというところに書いたものはカーネル関数の外に置かれるそうです。
2d_indexing_xy.pyのindexを変換する部分を関数にすると以下のようになります(冗長になっただけですが…)。
get_index_kernel_2d = cp.ElementwiseKernel(
in_params='raw int16 x, int16 width',
out_params='int16 z',
preamble=\
'''
__device__ int get_x_idx(int i, int width) {
return i%width;
}
__device__ int get_y_idx(int i, int width) {
return i/width;
}
''',
operation=\
'''
int x_idx = get_x_idx(i, width);
int y_idx = get_y_idx(i, width);
z = y_idx * 10 + x_idx;
''',
name='get_index_kernel_2d')
関数の頭についている__device__というのはGPU上で動くコードから呼び出したい関数につけるものです(CUDAの決まり事です)。
スレッドの同期
スレッドの同期とは、「自身のスレッドの処理がここまで到達したら、他のスレッドも同じところに到達するまで待つ」みたいな処理です。
結論から言うと、一つのカーネル内で行うのは無理です。
同期させたい場合は、同期させたい部分でカーネルを分離して、カーネルを2回適用させる形になるのではないかと思います。この図のように。
※厳密には「一つのBlock内のThreadは__syncthreads()関数で同期できますが、BlockをまたいだThreadの同期ができない」となるかと思います。ElementwiseKernelではBlockやThreadを自身で制御する術がないので、結果的に「スレッドの同期は無理」ということになります。
試しに、以下のようなことをすると、実行のたびに結果が変わる危ないコードになります。
X = cp.ones((200, 200)).astype(cp.float32)
Z = cp.zeros_like(X)
ind_size = cp.zeros(1).astype(cp.float32)
get_index_kernel_2d = cp.ElementwiseKernel(
in_params='raw float32 input, int16 width, int16 height',
out_params='float32 output',
preamble=\
'''
__device__ int get_x_idx(int i, int width) {
return i%width;
}
__device__ int get_y_idx(int i, int width) {
return i/width;
}
__device__ float calc_local_mean(int x_idx, int y_idx,
int width, int height,
CArray<float, 2> &input) {
// 近傍8pixelを走査して平均値を求める
float mean = 0;
int count = 0;
for (int dy = -1; dy <= 1; dy++) {
for (int dx = -1; dx <= 1; dx++) {
int x = x_idx + dx;
int y = y_idx + dy;
if (x < 0 || x >= width || y < 0 || y >= height) continue;
int idx[] = {y, x};
mean += input[idx];
count += 1;
}
}
return mean / count;
}
''',
operation=\
'''
int x_idx = get_x_idx(i, width);
int y_idx = get_y_idx(i, width);
output = calc_local_mean(x_idx, y_idx, width, height, input);
__syncthreads(); // 意味ない
input[y_idx, x_idx] += 10; // アブナイ。入力をいじる
''',
name='get_index_kernel_2d')
get_index_kernel_2d(X, X.shape[1], X.shape[0], Z)
cp.testing.assert_allclose(Z, cp.ones((200, 200)).astype(cp.float32))
このコードでは、cp.ones((200, 200))で初期化した二次元配列(画像)の全画素について、
「周辺8画素の平均をとる」という操作を行います。
当然結果はcp.ones((200, 200))になるはずです。
しかし、operationの最後の行で、input[y_idx, x_idx] += 10;によって入力をいじっています。
これにより、スレッドが実行される順番によって入力が変化することになり、結果がおかしくなります。
カーネル内コードのコンパイルエラーへの対処
例えば、上のコードのoperationの最後の行にあるinputをinpotにタイポしてみます。すると、以下のようなコンパイルエラーが出ます。
(略)
C:\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cu(35): here
C:\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cu(42): error: identifier "inpot" is undefined
C:\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cu(42): warning: expression has no effect
1 error detected in the compilation of "C:\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cu".
\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cuというCUDAのコードが生成され、
その42行目にタイポがあるのが分かります。
実際にエディタなどで\Users\INTEL_~1\AppData\Local\Temp\tmpyi9gv4_r\kern.cuを開くと、生成されたコードを見ることができます。
pythonのコードにおける行数は分からないのでひと手間増えますが、私は大体これで解決しています。
(コンパイルエラーではなく正常に終了した時に、生成されたCUDAコードのpathを知る方法はあるのでしょうか…?詳しい人がいたら教えてほしいです。)
ElementwiseKernelの使用例:画像同士の対応付け(パッチのマッチング)
画像Aと画像Bがあり、画像Aのある画素(x, y) が画像Bのどの画素(x, y)と近いのか全探索で調べます。
このとき「近い = 画素を中心とするパッチ(今回は3×3)同士の二乗誤差が小さい」とします。
すべての探索が終わると、画像Aの全画素(パッチ)について、画像Bの最近傍画素(パッチ)が求まることになります。
画像Aのそれぞれの画素ごとに、画像Bの最近傍画素の座標(x, y)をならべたものをNearest-Neighbor Field (NNF) といい、このNNFを求めるのが最終的な目標です。
NNFの幅と高さは画像Aと同じになります(各画素には画素値ではなく画像Bの座標が格納される)。
実は、これには近似解を高速に計算するPatchMatchという手法があるのですが、今回は簡単のため全探索して厳密解を求めてみます。
使用する画像は以下の2枚です。
画像A:amidadake_resized.jpg (200×134pixelの画像) ©すしぱく

画像B:yakedake_resized.jpg (同じく200×134pixelの画像) ©クマキチ

実装
まずmain関数です。読み込んで、マッチングして、画像Aを画像Bのパッチだけで再構築(後述)しています。
use_gpuにより、NumPyバージョンの関数を呼ぶかCuPyバージョンの関数を呼ぶかを分岐させています。
import cv2
import time
from exact_patch_match import ExactPatchMatch
if __name__ == '__main__':
use_gpu = True
patch_size = 3 # original: 7
# 読み込む
img_amida = cv2.imread('./amidadake_resized.jpg')
img_yake = cv2.imread('./yakedake_resized.jpg')
start = time.time()
patch_match = ExactPatchMatch(patch_size, img_amida, img_yake)
if use_gpu:
patch_match.get_nnf_cupy() # CuPyバージョンでのマッチング
else:
patch_match.get_nnf() # NumPyバージョンでのマッチング
print('elapsed time [s] :', time.time() - start)
# 再構築して保存
if use_gpu:
cv2.imwrite('./amidadake_resized_reconst_cupy.jpg', patch_match.reconstruct())
else:
cv2.imwrite('./amidadake_resized_reconst_numpy.jpg', patch_match.reconstruct())
次に、マッチングを行うクラス(NumPyバージョン)です。
画素を中心にパッチを構築するときに、パッチが画像からはみ出てしまうところは「一番近い画素の値をコピー」することにしました(コードの中に出てくるoffsetはその処理のためです)。
import numpy as np
import cupy as cp
class ExactPatchMatch(object):
def __init__(self, patch_size, imgA, imgB):
super(ExactPatchMatch, self).__init__()
self.patch_radius = patch_size//2
self.imgA = imgA
self.imgB = imgB
self.imgA_offset = self.__get_offset_img(imgA)
self.imgB_offset = self.__get_offset_img(imgB)
self.imgB_stacked = self.__get_stacked_patches('B')
self.nnf = None
# パッチを取得するときに、画像からはみ出る部分を取得しやすいように、大きな画像を作っておく
# はみ出る部分にはあらかじめ画素値を割り当てておく
def __get_offset_img(self, img):
pr = self.patch_radius
offset_img = np.zeros((img.shape[0]+pr*2 , img.shape[1]+pr*2, img.shape[2]))
for iy in range(offset_img.shape[0]):
for ix in range(offset_img.shape[1]):
x = ix - pr
y = iy - pr
x = max(0, min(img.shape[1] - 1, x))
y = max(0, min(img.shape[0] - 1, y))
offset_img[iy, ix] = img[y, x]
return offset_img
# あらかじめ画像Bのパッチを全て積み上げておく(メモリを犠牲に高速化)
def __get_stacked_patches(self, target='B'):
pr = self.patch_radius
ps = pr * 2 + 1 # patch size (diameter)
img = self.imgA if target is 'A' else self.imgB
width, height, channel = (img.shape[1], img.shape[0], img.shape[2])
pixel_num = width * height
stacked_img = np.zeros((pixel_num, ps, ps, channel))
for y in range(height):
for x in range(width):
stacked_img[y*width + x, :, :] = self.__get_patch_at((x, y), target)
return stacked_img
def __inter_patch_MSE_stacked(self, patch, stacked_patchs):
square_error = (patch.astype(np.float32) - stacked_patchs.astype(np.float32))**2
dim = stacked_patchs.ndim
reduce_axis = tuple(range(dim)[1:]) if dim > 1 else None
return np.mean(square_error, axis=reduce_axis)
def __get_patch_at(self, location, target='A'):
pr = self.patch_radius # patch radius
center_x = location[0] + pr
center_y = location[1] + pr
offset_img = self.imgA_offset if target is 'A' else self.imgB_offset
patch = offset_img[center_y-pr:center_y+pr+1, center_x-pr:center_x+pr+1]
return patch
def __update_nnf_at(self, location):
patchA = self.__get_patch_at(location, 'A')
width, height = (self.imgB.shape[1], self.imgB.shape[0])
inter_patch_MSE = self.__inter_patch_MSE_stacked(patchA, self.imgB_stacked)
min_MSE_index = np.argmin(inter_patch_MSE) # 最近傍パッチを計算
x, y = (min_MSE_index%width, min_MSE_index//width) # 最近傍パッチの座標(nearest neighbor point)
self.nnf[location[1], location[0], :] = np.array([x, y])
def get_nnf(self):
"""
imgA の全画素について、 imgB における最も距離が近い画素を計算し、
最も距離が近い画素の座標を格納する。
距離 = 対象画素を中心としたパッチ同士のMSE
Args:
patch_size (int): パッチの直径
imgA (numpy.ndarray): imgB への nnf を計算したい画像
imgB (numpy.ndarray): imgA からの nnf を計算したい画像
Updates:
nnf (numpy.ndarray): imgA から imgB への Nearest Neighbor Field
width と height は imgA に等しい
0chにx座標 1chにy座標
"""
self.nnf = np.zeros((self.imgA.shape[0], self.imgA.shape[1], 2)).astype(np.int)
for y in range(self.imgA.shape[0]):
for x in range(self.imgA.shape[1]):
self.__update_nnf_at((x, y))
# 後ほど使用する(NNFの算出には関係ない)
def reconstruct(self):
"""
あらかじめ計算した nnf を用いて、 imgA を imgB のパッチだけで再構成。
全画素の位置に nnf による参照先のパッチを貼り合わせて、重なる部分は平均をとる。
"""
reconst_img_offset = np.zeros_like(self.imgA_offset).astype(np.int)
count_map = np.zeros_like(self.imgA_offset).astype(np.int)
pr = self.patch_radius
for iy in range(self.imgA.shape[0]):
for ix in range(self.imgA.shape[1]):
x = ix + pr
y = iy + pr
patch_location = self.nnf[iy, ix]
patch = self.__get_patch_at((patch_location[0], patch_location[1]), 'B')
reconst_img_offset[y-pr:y+pr+1, x-pr:x+pr+1, :] += patch.astype(np.int)
count_map[y-pr:y+pr+1, x-pr:x+pr+1, :] += np.ones(patch.shape).astype(np.int)
reconst_img_offset = reconst_img_offset / count_map
reconst_img = reconst_img_offset[pr:-pr, pr:-pr]
return reconst_img
できるだけ遅くならないように工夫したつもりです。
主に工夫したところは、以下の2つです。
- パッチが画像からはみ出る時の処理を、パッチを取得するたびにやっていては遅いため、
self.imgA_offsetとself.imgB_offsetという大きめの画像を用意しておき、はみ出る部分にあらかじめ画素値を割り当てておきました。 - 画像Bにおける最近傍パッチを検索するとき、Forループだと遅いため、あらかじめパッチを積み上げた
self.imgB_stackedを用意しておいて、np.argminで距離が最小となるパッチの座標を取得しています。メモリは余計に食いますが、この方が速くなります。
NumPy力(ぢから)が強い人はもっと速く書けるかもしれません。
次にCuPyバージョン。上のExactPatchMatchクラスに以下のメソッドを加えます。
NumPyバージョンに比べても、それほど行数が増加していません。
def get_nnf_cupy(self):
get_nnf_kernel = cp.ElementwiseKernel(
in_params='raw float32 imgA, raw float32 imgB,\
uint16 widthA, uint16 heightA,\
uint16 widthB, uint16 heightB,\
uint16 pr',
out_params='raw uint16 nnf',
preamble=\
'''
__device__ int get_x_idx(int i, int width) {
return i%width;
}
__device__ int get_y_idx(int i, int width) {
return i/width;
}
__device__ float inter_patch_MSE(int widthA, int heightA,
int widthB, int heightB,
int x_A, int y_A,
int x_B, int y_B,
CArray<float, 3> &imgA,
CArray<float, 3> &imgB, int pr) {
int ix_A;
int iy_A;
int ix_B;
int iy_B;
int i_A;
int i_B;
float MSE = 0;
for (int dy = pr*(-1); dy <= pr; dy++){
for (int dx = pr*(-1); dx <= pr; dx++){
ix_A = x_A + dx;
iy_A = y_A + dy;
ix_B = x_B + dx;
iy_B = y_B + dy;
ix_A = max(0, min(widthA - 1, ix_A)); // offsetに相当
iy_A = max(0, min(heightA - 1, iy_A));
ix_B = max(0, min(widthB - 1, ix_B));
iy_B = max(0, min(heightB - 1, iy_B));
i_A = ix_A + widthA * iy_A;
i_B = ix_B + widthB * iy_B;
// 3channel分の誤差を足す
MSE += powf(imgA[i_A*3] - imgB[i_B*3], 2);
MSE += powf(imgA[i_A*3+1] - imgB[i_B*3+1], 2);
MSE += powf(imgA[i_A*3+2] - imgB[i_B*3+2], 2);
}
}
MSE = MSE / ((pr*2+1) * 3);
return MSE;
}
''',
operation=\
'''
int x_A = get_x_idx(i, widthA);
int y_A = get_y_idx(i, widthA);
float min_MSE = 1e6;
float MSE;
int nnp[2]; // nearest neighbor point
for (int y_B = 0; y_B < heightB; y_B++) {
for (int x_B = 0; x_B < widthB; x_B++) {
MSE = inter_patch_MSE(widthA, heightA,
widthB, heightB,
x_A, y_A, x_B, y_B,
imgA, imgB, pr);
if (MSE < min_MSE) {
min_MSE = MSE;
nnp[0] = x_B;
nnp[1] = y_B;
}
}
}
nnf[i*2] = nnp[0]; // 0chにx座標
nnf[i*2+1] = nnp[1]; // 1chにy座標
''',
name='get_nnf_kernel')
imgA_cu = cp.asarray(self.imgA).astype(cp.float32)
imgB_cu = cp.asarray(self.imgB).astype(cp.float32)
widthA, heightA = (self.imgA.shape[1], self.imgA.shape[0])
widthB, heightB = (self.imgB.shape[1], self.imgB.shape[0])
nnf_cu = cp.zeros((heightA, widthA, 2)).astype(cp.uint16)
get_nnf_kernel(imgA_cu, imgB_cu,\
widthA, heightA,\
widthB, heightB,\
self.patch_radius, nnf_cu, size=widthA*heightA)
self.nnf = cp.asnumpy(nnf_cu)
結果
マッチングが終わると、画像Aの全画素(パッチ)について、画像Bの最も近い画素(パッチ)が求められたことになります。
よって、画像Bの画素(パッチ)を切り貼りして、画像Aに近い画像を再構築することができます。
その結果が以下です。

本物↓

パッチの切り貼りで、本物に近い画像が再構築できているのが分かります。
もちろん、厳密解を求めているのでNumPyバージョンとCuPyバージョンの出力は全く同じになります。
速度比較
NumPyバージョンがこちら
elapsed time [s] : 91.27937078475952
CuPyバージョンがこちら
elapsed time [s] : 3.4458518028259277
約26倍の高速化になりました。イルカの速度はマンボウの速度の約19倍らしいので、
冴えないマンボウが進化してイルカを超越したことになります。
すごい。
単純計算ですが、同じ処理を200回やろうとすると、NumPyバージョンは 約5時間 かかり、CuPyバージョンは 約11分 で済みます。
終わりに
PythonからCUDAの機能を利用して、手軽に高速化ができるElementwiseKernelを紹介しました。
実行速度を手軽に速くできるのは素晴らしいですね。
みなさんも、著しく遅いForループに遭遇したら、ぜひElementwiseKernelで高速化してあげて下さい。
さらなる情報
いま(2018/08/27)のところ、情報があまり多くないのが事実です。
Qiitaの記事も少ない…
公式ドキュメントの他に、公式のexampleが上がっているので、それを参考にするとよいかと思います。
exampleでは、自身でblockIdx、blockDim、threadIdxなどを操作できる(CUDAカーネルを自前で用意する)RawKernelを使った例も上がっています。