1. はじめに
この記事は、前回公開した 「【第1回】ミニPCにKubernetes環境を構築するまで ~概要編~」 の続編です。
前回の記事では、Kubernetesの主要な機能やコンポーネントについて整理しました。
今回はそれを踏まえ、実際にミニPCに Kubernetes クラスターを構築していきます。
📘 まだご覧になっていない方は、こちらから:
👉 【第1回】ミニPCにKubernetes環境を構築するまで ~概要編~
2. 構成概要・事前準備
この章では、今回構築する Kubernetes クラスターの構成イメージと、事前に行っておくべき準備について紹介します。
🔧 2.1 構築する環境の概要
今回構築する Kubernetes クラスターは、以下のようなミニマルな構成を採用しています。
| 項目 | 内容 |
|---|---|
| ノード数 | 1台構成(単一のミニPCでコントロールプレーン兼ワーカー) |
| OS | Ubuntu 22.04 LTS |
| Kubernetesのインストール方法 | kubeadm |
| CNIプラグイン | Calico |
| コンテナランタイム | containerd |
1台構成の Kubernetes クラスターのイメージ図は以下になります。
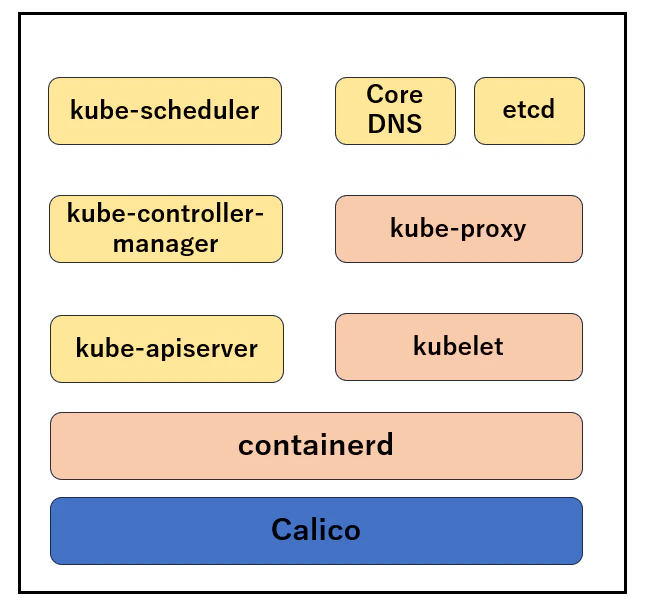
この図では、各コンポーネントを役割ごとに色分けしています。
- 🟨 黄色:コントロールプレーン(制御プレーン)に属するコンポーネント
- 🟥 赤色:全ノード共通のコンポーネント
- 🟦 青色:CNI プラグイン(Calico)
本来、コントロールプレーンとワーカーノードは複数のマシンに分かれて構成されるのが一般的ですが、今回は学習目的のため、1 台のミニPCに両方の役割を担わせています。
このような最小構成でも Kubernetes の仕組みを十分に体験・学習することができます。
まずはこの構成で動作を確認し、慣れてきたら複数ノード構成への拡張を検討するのも良いかと思います!
🖥 2.2 使用するミニPCについて
構築に使用するのは、以下のようなスペックのミニPCです(筆者環境)。
- 製品名: Beelink MINI-S12 Pro
- CPU: 4コア
- メモリ: 16GB
- ストレージ: 512GB SSD
- OS: Ubuntu 22.04 LTS
このようなスペックがあれば、Kubernetes のシングルノード構築や簡単なアプリケーションのデプロイにも十分対応可能です。
📥 2.3 事前に行った準備(Ubuntu インストール)
OSとして使用する Ubuntu 22.04 LTS は、あらかじめミニPCにインストールしておきました。
インストール手順や初期設定(SSH 有効化など)については、以下の記事で詳しく紹介しています。
💻 Ubuntuインストール手順はこちら
👉 ミニPCにUbuntu 22.04をインストール
まだ OS の準備ができていない方は、先に上記記事をご参照ください。
📦 2.4 今回使用するソフトウェアとバージョン
| ソフトウェア | バージョン | 備考 |
|---|---|---|
| Ubuntu | 22.04 LTS | 事前にミニPCにインストールしておく |
| Kubernetes | 1.30.11 | kubeadm で構築。最新の安定版を使用(執筆時点) |
| containerd | 1.7.27 | Kubernetes のコンテナランタイム |
| kubeadm / kubelet / kubectl | 1.30.11 | Kubernetes コンポーネント |
| Calico (CNI Plugin) | 3.27.0 | Pod 間通信のための CNI プラグインとして使用 |
バージョンは執筆時点のものですので、今後の変更に合わせて適宜読み替えてください。
🔑 2.5 作業前の前提
このあと構築作業に入りますが、以下の前提条件を満たしていることを確認してください。
- Ubuntu がインストールされ、SSH 接続が可能である
- sudo 権限のあるユーザーで作業する
- インターネットに接続できる状態である
次章では、いよいよ Kubernetes のインストールに取りかかっていきます!
3. Kubernetes インストール手順
3.1 Ubuntu のパッケージを最新化
まずは、システムのパッケージを最新の状態にしておきます。
古いパッケージはセキュリティ面での脆弱性がある可能性があるため、パッケージを最新化することは大切です。
sudo apt update && sudo apt upgrade -y
3.2 SWAP無効化
下記の Kubernetes 公式ドキュメントにも記載されている通り、SWAP が有効化されていると kubelet が正常に動作しない可能性があります。
👉 https://kubernetes.io/ja/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
そのため、Kubernetes を構築する際は SWAP を必ず無効化する必要があります。
また、SWAP 領域はディスク上に存在するため、物理メモリに比べて非常に低速です。
SWAP が使用されるとディスク I/O が増加し、システム全体のパフォーマンス低下の原因となる可能性もあります。
以下のコマンドで SWAP を無効化できます。
-
swapoff -aコマンドで SWAP 領域を無効化します -
/etc/fstabに定義された SWAP の自動マウント設定をコメントアウトし、再起動後も有効化されないようにします
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
3.3 カーネル設定
Kubernetes ではネットワーク通信を正しく行うために、以下のカーネルモジュールやネットワーク設定が必要です。
特に、br_netfilter モジュールとカーネルパラメーターの設定により、ブリッジ接続されたインターフェース間の通信(Pod 間の通信など)に対しても iptables のルールが適用されるようになります。
Kubernetes はネットワーク制御に iptables を活用しているため、これらの設定が欠けていると、Pod 間通信が正しく機能しなくなる可能性があります。
3.3.1 必要なカーネルモジュールのロード
以下のコマンドで、overlay および br_netfilter モジュールを読み込みます。
sudo modprobe overlay
sudo modprobe br_netfilter
起動時に自動でロードされるよう、設定ファイルを作成します。
sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
3.3.2 カーネルパラメーターの設定
次の設定を行うことで、ブリッジ接続を経由するトラフィックにも iptables のルールが適用され、また IP 転送(ルーティング)も有効になります。
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
設定を反映します。
sudo sysctl --system
3.4 containerd インストール
次に、コンテナランタイムである containerd のインストールを行います。
3.4.1 依存パッケージのインストール
以下のコマンドを実行し、containerd のインストールに必要なパッケージを準備します。
sudo apt install -y curl gnupg2 software-properties-common apt-transport-https ca-certificates
3.4.2 Docker リポジトリの登録
containerd は Docker の APT リポジトリで提供されています。
- Ubuntu 22.04(コードネーム: jammy)の containerd.io パッケージは以下に存在します。
https://download.docker.com/linux/ubuntu/dists/jammy/pool/stable/amd64/
以下のコマンドを実行し、Docker のリポジトリを登録します。
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/docker.gpg
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
3.4.3 containerd のインストール
パッケージリストを更新し、containerd パッケージをインストールします。
sudo apt update
sudo apt install -y containerd.io
3.4.4 containerd の設定変更
Kubernetes では、CPU・メモリなどのリソース制御に Linux の cgroup を使用します。
Ubuntu のように init システムが systemd の場合は、cgroup の制御方式(cgroup ドライバー)にも systemd を使うことが推奨されています。
そのため、containerd 側でも以下のように SystemdCgroup = true に設定変更を行います。
containerd config default | sudo tee /etc/containerd/config.toml >/dev/null 2>&1
sudo sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/g' /etc/containerd/config.toml
containerd デーモンを再起動し、設定変更を反映します。
また、containerd デーモンを自動起動する設定を行います。
sudo systemctl restart containerd
sudo systemctl enable containerd
cgroup とは
cgroup(Control Group) は、プロセス単位で CPU・メモリなどのリソースを制御する Linux の機能です。
Kubernetes のノードでは、以下2種類の cgroup ドライバーのどちらかを使ってリソース管理を行います。
cgroupfssystemd
Ubuntu などの systemd ベースのシステムでは、systemd が cgroup マネージャーとして動作します。
この環境において、cgroupfs を使うと、2つの cgroup マネージャーが動作することになり、これがノードを動かすうえでよろしくない場合があります。
例えば、kubelet やコンテナランタイムで cgroupfs を、残りのプロセスに systemd を使用するようにノードが設定されていると、高負荷時に不安定になることがあります。
Kubernetes 公式ドキュメントでも、systemd が init システムとして動作している場合は SystemdCgroup = true に設定することが推奨されています。
参考:
https://kubernetes.io/ja/docs/setup/production-environment/container-runtimes/#containerd-systemd
3.5 Kubernetes APT リポジトリの追加
Ubuntu 22.04 には、デフォルトで Kubernetes 関連の APT パッケージ(kubeadm・kubelet・kubectl など)を提供するリポジトリが登録されていません。
そのため、以下のコマンドを実行して Kubernetes 公式の APT リポジトリを追加します。
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
補足:リポジトリの仕様変更について
以前は apt.kubernetes.io から配布されていましたが、2024年3月以降は 新しいリポジトリ pkgs.k8s.io に移行されています。
3.6 kubelet、kubectl、kubeadm のインストール
先ほど追加した APT リポジトリを使って、以下の Kubernetes パッケージをインストールします。
-
kubelet: Kubernetes クラスターのコンポーネントの 1 つで、各ノードで Pod の起動・管理を行うエージェント -
kubeadm: クラスターの構築・初期化・アップグレードなどを行うツール -
kubectl: Kubernetes を操作するための CLI
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
# 自動アップグレードされないようにバージョンを固定
sudo apt-mark hold kubelet kubeadm kubectl
補足:kubeadm とは?
kubeadm は Kubernetes クラスターの構築や初期化、アップグレードを簡単に行うための公式ツールです。
個別にコンポーネントを設定・起動するよりもはるかに手軽に、標準的なクラスター構成を立ち上げることができます。
補足:kubectl とは?
kubectl は Kubernetes クラスターと対話するためのコマンドラインツールです。
Pod の作成・削除・ログ取得・設定変更など、あらゆる操作を Kubernetes API 経由で行うことができます。
3.7 Kubernetes の初期化
これまでの作業を経て、Kubernetes を構築する準備ができました。
kubeadm コマンドを使って、Kubernetes クラスターの初期化を行います。
これにより、下図の赤枠部分が構築されます。
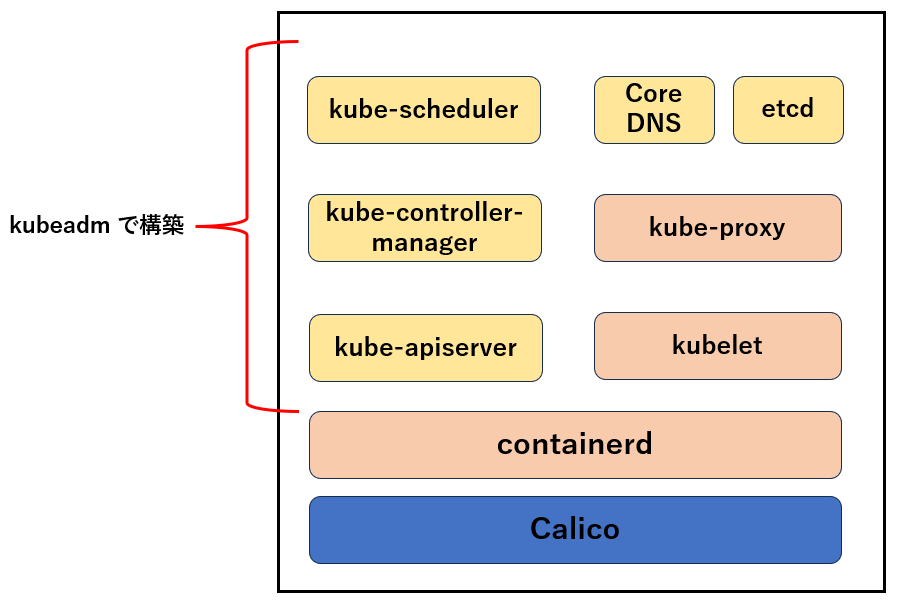
3.7.1 kubeadm による Kubernetes クラスターの初期化
以下のコマンドを実行し、Kubernetes クラスターの初期化を行います。
sudo kubeadm init
以下は上記コマンドの実行ログです。
kube-apiserver や kube-controller-manager 等のコントロールプレーンのコンポーネントが動く Pod マニフェストが作成されたり、CoreDNS や kube-proxy が作成されていることが分かります。
user1@kubenode:~$ sudo kubeadm init
I0418 23:07:58.068217 2397 version.go:256] remote version is much newer: v1.32.3; falling back to: stable-1.30
[init] Using Kubernetes version: v1.30.11
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
W0418 23:07:58.650321 2397 checks.go:844] detected that the sandbox image "registry.k8s.io/pause:3.8" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry.k8s.io/pause:3.9" as the CRI sandbox image.
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubenode kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.3.17]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [kubenode localhost] and IPs [192.168.3.17 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [kubenode localhost] and IPs [192.168.3.17 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 502.208458ms
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 6.002051973s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kubenode as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node kubenode as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: m3i4yj.yvlwrvpq5o4jpdll
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.3.17:6443 --token m3i4yj.yvlwrvpq5o4jpdll \
--discovery-token-ca-cert-hash sha256:e97391516c8f47e94867cfeee0329f8986a5b03a507cfbd4cf7046f7ef5887be
user1@kubenode:
↑のメッセージにも記載されていますが、初期化完了後、一般ユーザーで以下のコマンドを実行する必要があります。
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl では、コマンドを実行する際、$HOME/.kube/config ファイルを参照し、その情報を使って Kubernetes の API サーバーと通信します。
また、管理者権限で実行するのに必要な config ファイルは以下です。
/etc/kubernetes/admin.conf
コントロールプレーンにおいて、現在利用している OS ユーザーで管理者権限で kubectl を実行できるようにするために、以下のコマンドを実行します。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubeconfig ファイルとは?
Kubernetes API にアクセスするための認証・接続情報を記述した設定ファイルです。
デフォルトでは $HOME/.kube/config に配置することで、kubectl コマンドが自動で使用します。
3.7.2 ノードステータスの確認
Kubernetes クラスター初期化後、以下のコマンドでノードの状態を確認します。
kubectl get nodes
この時点では、ノードのステータスが「NotReady」となっているはずです。
これは、Pod 間通信を担うネットワーク機能(CNI)がまだ有効化されていないためです。

3.8 CNI プラグインのインストール
Kubernetes では、Pod 同士の通信を行うために、CNI(Container Network Interface)プラグインが必要です。
今回は、代表的な CNI プラグインの 1 つである Calico を使用します。
以下のコマンドを実行し、Calico をインストールします。
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/calico.yaml
インストールが完了すると、Calico によって Pod 間のネットワークが構成され、ノードのステータスが「Ready」に変わります。
kubectl get nodes
ノードが「Ready」となっていれば、Kubernetes クラスターの基盤が正常に稼働し始めたことを意味します。

補足:CNI プラグインとは
CNI(Container Network Interface)は、コンテナにネットワーク機能を付与するための仕様です。
Calico の他に Flannel、Cilium など複数の実装がありますが、いずれも Pod に IP アドレスを割り当て、ネットワーク通信を可能にします。
3.9 コントロールプレーンノードの Taints 削除
コントロールプレーンノードは、デフォルトでは Pod(コントロールプレーンのコンポーネントの Pod を除く) をスケジューリングできないようになっています。
これは、コントロールプレーンノードはあくまで Kubernetes クラスター全体を管理する役割を担っており、本来ワークロード Pod を動かすのはワーカーノードの役割だからです。
今回の Kubernetes クラスターは 1 台構成であり、このノードはコントロールプレーン兼ワーカーノードとなり、このノードにワークロード Pod を配置するので、以下のコマンドを実行して、ノードにこれらの Pod を配置できるようにします。
ノードから node-role.kubernetes.io/control-plane Taints を削除します。
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
補足:Taints/Tolerations とは
Taints (汚染) とは Kubernetes の機能の 1 つであり、特定のノードに特定の Pod を配置できないようにするための仕組みです。
例えば、このノードには本番環境用の Pod 以外は配置しない、といった制御をこの機能で行うことができます。
一方、Tolerations(許容)とは、Pod 側に設定するプロパティで、「この Pod は特定の Taints を持ったノードにもスケジュールされてよい」と明示的に許可するためのものです。
つまり、Taints があるノードに Pod をスケジュールするには、Pod 側に対応する Tolerations が設定されている必要があります。
たとえば、コントロールプレーンノードには node-role.kubernetes.io/control-plane:NoSchedule という Taints がデフォルトで付与されており、通常の Pod はこれに Tolerations を持たないため、そのノードにスケジュールされません。
これは、重要なコントロールプレーンノードに誤ってワークロードを配置し、リソースを圧迫してしまうことを防ぐために、こうした仕組みを設けていると考えられます。
補足:node-role.kubernetes.io/control-plane とは
kubeadm がコントロールプレーンノードに適用する Taints で、Pod の配置を制限し、特定の Pod のみにスケジュールを許可します。
この Taints が適用されていることで、コントロールプレーンノードではクリティカルなワークロードの Pod のみがスケジュールされるようになります( kube-apiserver や kube-scheduler 等の Pod )。
補足:なぜコントロールプレーンノードでは kube-apiserver 等のコントロールプレーンを構成するコンポーネントの Pod を起動できるのか?
コントロールプレーンノードでは、上記の Taints が設定されているため、この Taints に対応する Tolerations を Pod に設定しない限り、このノードでは Pod を起動することはできません。
一方で、コントロールプレーンノードでは kube-apiserver 等のコントロールプレーンを構成するコンポーネントの Pod がいくつか起動しています。
これらの Pod の YAML には Tolerations が設定されておらず、Taints の仕組みだけを考えると、本来は起動できないのでは?と疑問に思う方もいるかもしれません。
これはどういうことかというと、これらの Pod は Static Pod だからです。
Static Pod は、kube-scheduler を介さず kubelet が直接管理・起動するため、Kubernetes API によるスケジューリング制御(Taints/Tolerations を含む)を受けない特殊な Pod です。
Taints はあくまでスケジューリング時に考慮されるものであり、Static Pod は kube-scheduler を経由せず、kubelet 自身が起動するので、Taints/Tolerations の仕組みの影響を受けません。
これらの Pod の YAML は以下のディレクトリに存在しますが、kubelet ではこのパスにある Pod を Static Pod として起動させます。
/etc/kubernetes/manifests
ちなみに、コントロールプレーンノード上の kubelet の構成設定ファイルは以下になります。
/var/lib/kubelet/config.yaml
このファイル内の staticPodPath が Static Pod の YAML 配置先ディレクトリを指しており、コントロールプレーンで起動する kubelet では /etc/kubernetes/manifests が指定されています。
この設定により、上記ディレクトリにある Pod はすべて Static Pod として自動的に起動されます。
staticPodPath: /etc/kubernetes/manifests
4. サンプル Pod の起動
Kubernetes の構築はこれで完了です。
試しに、Nginx コンテナを Pod として起動し、クラスターが正しく動作しているか確認してみます。
kubectl run nginx --image=nginx --port=80
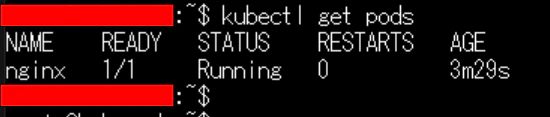
Pod が正常に作成されたかどうか、以下のコマンドでステータスを確認します。
kubectl get pods
Pod のステータスが「Running」となっていれば、Kubernetes クラスターは正常に動作しています 🎉
5. おわりに
ミニPCで Kubernetes を構築することで、手元で自由に試せる学習環境が手に入りました。
今後はこの環境を使って、アプリケーションのデプロイや監視、CI/CD の検証などにも挑戦していきます!
参考資料