本記事は、Pandas の公式ドキュメントのUser Guide - Indexing and Selecting Dataを機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
Pandas公式ドキュメント日本語訳記事一覧
-
 データの取得と選択
データの取得と選択
- マルチインデックス・高度な索引
- mergeとjoinとconcatenateとcompare
- テーブルの整形とピボットテーブル
- テキストデータの操作
- 欠損データの操作
- 重複ラベル
- カテゴリデータ
- Group by - 分割・適用・結合
データの取得と選択
pandasオブジェクトの軸ラベル情報は、多くの目的を果たします:
- 既知のインジケータを使用して、分析・可視化・対話型コンソール表示に重要なデータの識別を可能にします(つまり、metadataを提供します)。
- 自動的かつ明示的なデータの整列を可能にします。
- データセットのサブセットを直感的に取得・設定することができます。
この章では、最後のポイント――pandas オブジェクトのサブセットをどのようにスライス・ダイスおよび一般的に取得・代入するか――に焦点をあてます。この分野で開発が注目されているため、主な焦点は Series と DataFrame になります。
PythonとNumPyのインデックス演算子[]と属性演算子.を利用することで、様々な場面でpandasのデータ構造に素早く簡単にアクセスすることができます。これらは、Pythonの辞書やNumPy配列の扱い方を既に知っているならば新たに学ぶことはほとんどないので、インタラクティブな作業を直感的にできます。とはいえ標準演算子の直接使用は、アクセスする事前にデータの型がわからないため、最適化には限界があります。実用的には、この章で紹介されている最適化されたpandasデータのアクセス方法を利用することをお勧めします。
代入操作において、コピーと参照のどちらが返されるのかは、場合によって異なります。これは連鎖代入chained assignmentと呼ばれ、避けるべきものです。返るのはビューかコピーかを参照してください。
マルチインデックス・高度な索引には、MultiIndexとより高度な索引についてのマニュアルがあります。
より応用的な操作については、cook bookもご覧ください。
さまざまな取得の方法
オブジェクトの選択は、より明確な位置ベースの取得をサポートするために、ユーザーからの要望に応じて多くの機能が存在しています。pandasでは現在3種類の複数軸による取得をサポートしています。
-
.locは基本的にラベルベースですが、真偽値配列を利用することもできます。要素が見つからない場合、.locはKeyErrorを返します。以下を渡すことができます。- 単一のラベル。例:
5,'a'(※5はインデックスのラベルとして解釈されることに注意してください。インデックス配列の位置番号ではありません。)。 - ラベルのリスト・配列。例:
['a', 'b', 'c']。 - ラベルによるスライス。例:
'a':'f'(※通常のPythonのスライスと異なり、インデックスに存在すれば、始点と終点の両方が含まれます!ラベルによるスライスや終点は含まれるを参照してください。)。 - 真偽値の配列(
NAの値はすべてFalseとして扱われます)。 - 引数を一つ(SeriesまたはDataFrame)受け取り、有効なインデクサ(上記のどれか)を返す呼び出し可能関数(
callable)。
より詳しい解説はラベルによる選択を参照してください。
- 単一のラベル。例:
-
.ilocは基本的に位置番号ベース(0からlength-1まで)ですが、真偽値配列を利用することもできます。インデックス配列の範囲を超えた値を指定した場合、.ilocはIndexErrorを返します。ただし、スライスによる指定は、範囲を越えた値を指定できます(この挙動はPythonやNumPyのスライスに準拠しています)。以下を渡すことができます。- 整数。例:
5。 - 整数のリスト・配列。例:
[4, 3, 0]。 - 整数のスライスオブジェクト。例:
1:7。 - 真偽値の配列(
NAの値はすべてFalseとして扱われます)。 - 引数を一つ(SeriesまたはDataFrame)受け取り、有効なインデクサ(上記のどれか)を返す呼び出し可能関数(
callable)。
- 整数。例:
-
.locと.ilocだけでなく、[]による取得もcallableをインデクサとして利用できます。より詳しい解説は呼び出し関数による選択を参照してください。
複数の軸を選択してオブジェクトから値を取得するには、以下の表記法を使用します(.locを例に挙げていますが、.ilocの場合も同様です)。どの軸に対しても Null スライス:が使用可能です。指定されなかった軸は:を指定したと解釈されます。例えば、p.loc['a']はp.loc['a', :]と同じ意味になります。
| オブジェクト | インデクサ |
|---|---|
| Series | s.loc[indexer] |
| DataFrame | df.loc[row_indexer,column_indexer] |
基本
前章でデータ構造を紹介したときに述べたように、[](Python でクラスの振る舞いを実装するのに慣れた人に対して言い換えるなら、__getitem__)によるインデクシングの基本的機能は、より低次元のスライスを選択することです。次の表は、[]を用いて pandas オブジェクトを索引した場合の戻り値の型を示しています。
| オブジェクト | 索引 | 返り値の型 |
|---|---|---|
| Series | series[label] |
スカラー値 |
| DataFrame | frame[colname] |
colname に対応するSeries
|
ここでは、インデックスによる取得の機能を説明するために、簡単な時系列データセットを使用します。
dates = pd.date_range('1/1/2000', periods=8)
df = pd.DataFrame(np.random.randn(8, 4),
index=dates, columns=['A', 'B', 'C', 'D'])
df
# A B C D
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236
# 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
# 2000-01-04 0.721555 -0.706771 -1.039575 0.271860
# 2000-01-05 -0.424972 0.567020 0.276232 -1.087401
# 2000-01-06 -0.673690 0.113648 -1.478427 0.524988
# 2000-01-07 0.404705 0.577046 -1.715002 -1.039268
# 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
特に明記しない限り、インデックス機能は時系列データ固有のものではありません。
したがって、上で述べたように、最も基本的な[]を使った取得を用いることができます。
s = df['A']
s[dates[5]]
# -0.6736897080883706
列のリストを[]に渡すと、列をこの順序で選択できます。列が DataFrame に含まれていない場合は、例外が発生します。この方法で複数の列を代入して設定することもできます。
df
# A B C D
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236
# 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
# 2000-01-04 0.721555 -0.706771 -1.039575 0.271860
# 2000-01-05 -0.424972 0.567020 0.276232 -1.087401
# 2000-01-06 -0.673690 0.113648 -1.478427 0.524988
# 2000-01-07 0.404705 0.577046 -1.715002 -1.039268
# 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
df[['B', 'A']] = df[['A', 'B']]
df
# A B C D
# 2000-01-01 -0.282863 0.469112 -1.509059 -1.135632
# 2000-01-02 -0.173215 1.212112 0.119209 -1.044236
# 2000-01-03 -2.104569 -0.861849 -0.494929 1.071804
# 2000-01-04 -0.706771 0.721555 -1.039575 0.271860
# 2000-01-05 0.567020 -0.424972 0.276232 -1.087401
# 2000-01-06 0.113648 -0.673690 -1.478427 0.524988
# 2000-01-07 0.577046 0.404705 -1.715002 -1.039268
# 2000-01-08 -1.157892 -0.370647 -1.344312 0.844885
これは、列のサブセットに(インプレースに)変換を適用するのに役立ちます。
.locや.ilocからSeriesとDataFrameを設定すると、pandas はすべての軸を整列させます。
列の整列は値の割り当ての前に行われるため、以下の例はdfを変更しません。
df[['A', 'B']]
# A B
# 2000-01-01 -0.282863 0.469112
# 2000-01-02 -0.173215 1.212112
# 2000-01-03 -2.104569 -0.861849
# 2000-01-04 -0.706771 0.721555
# 2000-01-05 0.567020 -0.424972
# 2000-01-06 0.113648 -0.673690
# 2000-01-07 0.577046 0.404705
# 2000-01-08 -1.157892 -0.370647
df.loc[:, ['B', 'A']] = df[['A', 'B']]
df[['A', 'B']]
# A B
# 2000-01-01 -0.282863 0.469112
# 2000-01-02 -0.173215 1.212112
# 2000-01-03 -2.104569 -0.861849
# 2000-01-04 -0.706771 0.721555
# 2000-01-05 0.567020 -0.424972
# 2000-01-06 0.113648 -0.673690
# 2000-01-07 0.577046 0.404705
# 2000-01-08 -1.157892 -0.370647
列の値を交換するには、生の値を使用するのが正しい方法です。
df.loc[:, ['B', 'A']] = df[['A', 'B']].to_numpy()
df[['A', 'B']]
# A B
# 2000-01-01 0.469112 -0.282863
# 2000-01-02 1.212112 -0.173215
# 2000-01-03 -0.861849 -2.104569
# 2000-01-04 0.721555 -0.706771
# 2000-01-05 -0.424972 0.567020
# 2000-01-06 -0.673690 0.113648
# 2000-01-07 0.404705 0.577046
# 2000-01-08 -0.370647 -1.157892
属性アクセス
SeriesのインデックスまたはDataFrameの列には、属性として直接取得することができます。
sa = pd.Series([1, 2, 3], index=list('abc'))
dfa = df.copy()
sa.b
# 2
dfa.A
# 2000-01-01 0.469112
# 2000-01-02 1.212112
# 2000-01-03 -0.861849
# 2000-01-04 0.721555
# 2000-01-05 -0.424972
# 2000-01-06 -0.673690
# 2000-01-07 0.404705
# 2000-01-08 -0.370647
# Freq: D, Name: A, dtype: float64
sa.a = 5
sa
# a 5
# b 2
# c 3
# dtype: int64
dfa.A = list(range(len(dfa.index))) # A列が既に存在している場合はOK
dfa
# A B C D
# 2000-01-01 0 -0.282863 -1.509059 -1.135632
# 2000-01-02 1 -0.173215 0.119209 -1.044236
# 2000-01-03 2 -2.104569 -0.494929 1.071804
# 2000-01-04 3 -0.706771 -1.039575 0.271860
# 2000-01-05 4 0.567020 0.276232 -1.087401
# 2000-01-06 5 0.113648 -1.478427 0.524988
# 2000-01-07 6 0.577046 -1.715002 -1.039268
# 2000-01-08 7 -1.157892 -1.344312 0.844885
dfa['A'] = list(range(len(dfa.index))) # もし新しい列を作る場合はこちら
dfa
# A B C D
# 2000-01-01 0 -0.282863 -1.509059 -1.135632
# 2000-01-02 1 -0.173215 0.119209 -1.044236
# 2000-01-03 2 -2.104569 -0.494929 1.071804
# 2000-01-04 3 -0.706771 -1.039575 0.271860
# 2000-01-05 4 0.567020 0.276232 -1.087401
# 2000-01-06 5 0.113648 -1.478427 0.524988
# 2000-01-07 6 0.577046 -1.715002 -1.039268
# 2000-01-08 7 -1.157892 -1.344312 0.844885
- この取得は、index要素がPythonの識別子として有効である場合にのみ使用できます。例えば、
s.1は使用できません。有効な識別子の説明については、こちらを参照してください。 - この属性は、既存のメソッド名と競合する場合には利用できません。例えば、
s['min']は使用できますが、s.minは使用できません。 - 同様に、次に挙げたもののいずれかと競合する場合、その属性は利用できません。
index,major_axis,minor_axis,items。 - 上記の場合のいずれにおいても、標準的なインデックス取得であれば利用することができます。例えば、
s['1'],s['min'],s['index']は、対応する要素または列にアクセスします。
IPython 環境を使用している場合は、タブ補完を使用してこれらのアクセス可能な属性を確認することもできます。
DataFrameの行に、辞書dictを割り当てることもできます。
x = pd.DataFrame({'a': [1, 2, 3], 'b': [3, 4, 5]})
x.iloc[1] = {'a': 9, 'b': 99}
x
# a b
# 0 1 3
# 1 9 99
# 2 3 5
属性アクセスを使用して、既存のSeriesの要素またはDataFrameの列を変更できます。ただし、新しい列を作成しようとして属性アクセスを使用すると、新しい列ではなく新しい属性が作成されることに注意してください。0.21.0以降ではこのときUserWarningを送出します。
df = pd.DataFrame({'one': [1., 2., 3.]})
df.two = [4, 5, 6]
# UserWarning: Pandas doesn't allow Series to be assigned into nonexistent columns - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute_access
df
# one
# 0 1.0
# 1 2.0
# 2 3.0
範囲スライス
任意の軸に沿って範囲をスライスする最も堅牢で一貫性のある方法は、.ilocメソッドの詳細を説明する位置による選択の節で説明されています。ここでは、[]演算子を使ったスライスの記法を説明します。
Seriesでは、ndarrayの構文とまったく同じように機能し、値とそれに対応するラベルのスライスを返します。
s[:5]
# 2000-01-01 0.469112
# 2000-01-02 1.212112
# 2000-01-03 -0.861849
# 2000-01-04 0.721555
# 2000-01-05 -0.424972
# Freq: D, Name: A, dtype: float64
s[::2]
# 2000-01-01 0.469112
# 2000-01-03 -0.861849
# 2000-01-05 -0.424972
# 2000-01-07 0.404705
# Freq: 2D, Name: A, dtype: float64
s[::-1]
# 2000-01-08 -0.370647
# 2000-01-07 0.404705
# 2000-01-06 -0.673690
# 2000-01-05 -0.424972
# 2000-01-04 0.721555
# 2000-01-03 -0.861849
# 2000-01-02 1.212112
# 2000-01-01 0.469112
# Freq: -1D, Name: A, dtype: float64
また、代入の際も同様に機能します。
s2 = s.copy()
s2[:5] = 0
s2
# 2000-01-01 0.000000
# 2000-01-02 0.000000
# 2000-01-03 0.000000
# 2000-01-04 0.000000
# 2000-01-05 0.000000
# 2000-01-06 -0.673690
# 2000-01-07 0.404705
# 2000-01-08 -0.370647
# Freq: D, Name: A, dtype: float64
DataFrameでは、[]の中の行がスライスされます。これは、このような操作が一般的であることから、利便性のために実装されています。
df[:3]
# A B C D
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236
# 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
df[::-1]
# A B C D
# 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885
# 2000-01-07 0.404705 0.577046 -1.715002 -1.039268
# 2000-01-06 -0.673690 0.113648 -1.478427 0.524988
# 2000-01-05 -0.424972 0.567020 0.276232 -1.087401
# 2000-01-04 0.721555 -0.706771 -1.039575 0.271860
# 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632
ラベルによる選択
代入操作において、コピーと参照のどちらが返されるのかは、場合によって異なります。これは連鎖代入chained assignmentと呼ばれ、避けるべきものです。返るのはビューかコピーかを参照してください。
インデックスの型と互換性のない(あるいは変換不可能な)スライサを用いた場合、
.locは厳密になります。例として、DatetimeIndexに整数を使用してみます。この場合TypeErrorが発生します。
dfl = pd.DataFrame(np.random.randn(5, 4),
columns=list('ABCD'),
index=pd.date_range('20130101', periods=5))
dfl
# A B C D
# 2013-01-01 1.075770 -0.109050 1.643563 -1.469388
# 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
# 2013-01-03 -1.294524 0.413738 0.276662 -0.472035
# 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
# 2013-01-05 0.895717 0.805244 -1.206412 2.565646
dfl.loc[2:3]
# TypeError: cannot do slice indexing on <class 'pandas.tseries.index.DatetimeIndex'> with these indexers [2] of <type 'int'>
文字列ライクな型によるスライスは、インデックスの型に変換することができるため自然にスライスできます。
dfl.loc['20130102':'20130104']
# A B C D
# 2013-01-02 0.357021 -0.674600 -1.776904 -0.968914
# 2013-01-03 -1.294524 0.413738 0.276662 -0.472035
# 2013-01-04 -0.013960 -0.362543 -0.006154 -0.923061
バージョン1.0.0で変更
pandasは、存在しないラベルを含むリストで索引すると、KeyErrorを発生させます。存在しないキーを含むリストによる索引は非推奨をご覧ください。
pandasでは純粋なラベルベースの索引のために一連のメソッドが提供されています。これは厳密な包含ベースのプロトコルです。要求された全てのラベルはインデックスに含まれていなければなりません、そうでなければKeyErrorが送出されます。スライス時に、インデックスに存在する場合は、始点と終点の両方が含まれます。整数はラベルとして有効ですが、位置ではなくラベルを参照します。
.loc属性が基本的なアクセスメソッドです。有効な入力は以下のとおりです。
- 単一のラベル。例:
5,'a'(※5はインデックスのラベルとして解釈されます。インデックス配列の位置番号ではありません。)。 - ラベルのリスト・配列。例:
['a', 'b', 'c']。 - ラベルによるスライス。例:
'a':'f'(※普通の python のスライスと異なり、インデックスに存在すれば、始点と終点の両方が含まれます!ラベルによるスライスを参照してください。)。 - 真偽値の配列。
- 呼び出し可能関数
callable。呼び出し関数による選択を参照してください。
s1 = pd.Series(np.random.randn(6), index=list('abcdef'))
s1
# a 1.431256
# b 1.340309
# c -1.170299
# d -0.226169
# e 0.410835
# f 0.813850
# dtype: float64
s1.loc['c':]
# c -1.170299
# d -0.226169
# e 0.410835
# f 0.813850
# dtype: float64
s1.loc['b']
# 1.3403088497993827
また、代入の際も同様に機能します。
s1.loc['c':] = 0
s1
# a 1.431256
# b 1.340309
# c 0.000000
# d 0.000000
# e 0.000000
# f 0.000000
# dtype: float64
DataFrame の場合。
df1 = pd.DataFrame(np.random.randn(6, 4),
index=list('abcdef'),
columns=list('ABCD'))
df1
# A B C D
# a 0.132003 -0.827317 -0.076467 -1.187678
# b 1.130127 -1.436737 -1.413681 1.607920
# c 1.024180 0.569605 0.875906 -2.211372
# d 0.974466 -2.006747 -0.410001 -0.078638
# e 0.545952 -1.219217 -1.226825 0.769804
# f -1.281247 -0.727707 -0.121306 -0.097883
df1.loc[['a', 'b', 'd'], :]
# A B C D
# a 0.132003 -0.827317 -0.076467 -1.187678
# b 1.130127 -1.436737 -1.413681 1.607920
# d 0.974466 -2.006747 -0.410001 -0.078638
ラベルスライスを介したアクセス。
df1.loc['d':, 'A':'C']
# A B C
# d 0.974466 -2.006747 -0.410001
# e 0.545952 -1.219217 -1.226825
# f -1.281247 -0.727707 -0.121306
ラベルを使用した断面の取得(df.xs('a')に等しい)。
df1.loc['a']
# A 0.132003
# B -0.827317
# C -0.076467
# D -1.187678
# Name: a, dtype: float64
真偽値配列を利用した値の取得。
df1.loc['a'] > 0
# A True
# B False
# C False
# D False
# Name: a, dtype: bool
df1.loc[:, df1.loc['a'] > 0]
# A
# a 0.132003
# b 1.130127
# c 1.024180
# d 0.974466
# e 0.545952
# f -1.281247
真偽値配列のNA値はFalseとして伝播します。
バージョン1.0.2で変更
mask = pd.array([True, False, True, False, pd.NA, False], dtype="boolean")
mask
# <BooleanArray>
# [True, False, True, False, <NA>, False]
# Length: 6, dtype: boolean
df1[mask]
# A B C D
# a 0.132003 -0.827317 -0.076467 -1.187678
# c 1.024180 0.569605 0.875906 -2.211372
明示的に値を取得する場合。
# これは``df1.at['a', 'A']``に等しい
df1.loc['a', 'A']
# 0.13200317033032932
ラベルによるスライス
.locでスライスを用いるときに、始点ラベルと終点ラベルの両方がインデックスに存在する場合、2つのラベルの間に位置している要素(始点終点を含む)が返されます。
s = pd.Series(list('abcde'), index=[0, 3, 2, 5, 4])
s.loc[3:5]
# 3 b
# 2 c
# 5 d
# dtype: object
2つのうちの少なくとも1つが存在しないバアにおいても、インデックスがソートされていて、かつ始点ラベル・終点ラベルと順序が比較できる場合は、2つの間にランク付けされるラベルが選択されて、スライスは期待どおりに機能します。
s.sort_index()
# 0 a
# 2 c
# 3 b
# 4 e
# 5 d
# dtype: object
s.sort_index().loc[1:6]
# 2 c
# 3 b
# 4 e
# 5 d
# dtype: object
ただし、2つのうち少なくとも片方が存在せず、かつインデックスがソートされていない場合は、エラーが発生します(そうしないと計算量が多くなるだけでなく、型が混在したインデックスでは期待される結果が曖昧になる可能性があるため)。例えば上記の例では、s.loc[1:6]はKeyErrorを送出します。
この動作の根拠については、終点は含まれるを参照してください。
s = pd.Series(list('abcdef'), index=[0, 3, 2, 5, 4, 2])
s.loc[3:5]
# 3 b
# 2 c
# 5 d
# dtype: object
また、インデックスに重複するラベルが存在していて、かつ始点ラベルまたは終点ラベルが重複している場合、エラーが発生します。例えば、上記の例では、s.loc[2:5]はKeyErrorを送出します。
ラベルの重複についての詳細は、重複ラベルを参照してください。
位置による選択
代入操作において、コピーと参照のどちらが返されるのかは、場合によって異なります。これは連鎖代入chained assignmentと呼ばれ、避けるべきものです。返るのはビューかコピーかを参照してください。
pandasでは純粋な位置番号ベースの索引のための一連のメソッドが提供されています。その記法はPythonとNumPyのスライスとほぼ同じです。これは0-basedインデックスです。このスライスでは、始点は含まれますが、終点は含まれません。有効なラベルであっても、整数以外を使用しようとするとIndexErrorが発生します。
.iloc属性が基本的なアクセスメソッドです。以下を渡すことができます。
- 整数。例:
5。 - 整数のリスト・配列。例:
[4, 3, 0]。 - 整数のスライスオブジェクト。例:
1:7。 - 真偽値の配列。
- 呼び出し可能関数
callable。呼び出し関数による選択を参照してください。
s1 = pd.Series(np.random.randn(5), index=list(range(0, 10, 2)))
s1
# 0 0.695775
# 2 0.341734
# 4 0.959726
# 6 -1.110336
# 8 -0.619976
# dtype: float64
s1.iloc[:3]
# 0 0.695775
# 2 0.341734
# 4 0.959726
# dtype: float64
s1.iloc[3]
# -1.110336102891167
また、代入の際も同様に機能します。
s1.iloc[:3] = 0
s1
# 0 0.000000
# 2 0.000000
# 4 0.000000
# 6 -1.110336
# 8 -0.619976
# dtype: float64
DataFrame の場合。
df1 = pd.DataFrame(np.random.randn(6, 4),
index=list(range(0, 12, 2)),
columns=list(range(0, 8, 2)))
df1
# 0 2 4 6
# 0 0.149748 -0.732339 0.687738 0.176444
# 2 0.403310 -0.154951 0.301624 -2.179861
# 4 -1.369849 -0.954208 1.462696 -1.743161
# 6 -0.826591 -0.345352 1.314232 0.690579
# 8 0.995761 2.396780 0.014871 3.357427
# 10 -0.317441 -1.236269 0.896171 -0.487602
整数スライスを介した選択。
df1.iloc[:3]
# 0 2 4 6
# 0 0.149748 -0.732339 0.687738 0.176444
# 2 0.403310 -0.154951 0.301624 -2.179861
# 4 -1.369849 -0.954208 1.462696 -1.743161
df1.iloc[1:5, 2:4]
# 4 6
# 2 0.301624 -2.179861
# 4 1.462696 -1.743161
# 6 1.314232 0.690579
# 8 0.014871 3.357427
整数のリストを介した選択。
df1.iloc[[1, 3, 5], [1, 3]]
# 2 6
# 2 -0.154951 -2.179861
# 6 -0.345352 0.690579
# 10 -1.236269 -0.487602
df1.iloc[1:3, :]
# 0 2 4 6
# 2 0.403310 -0.154951 0.301624 -2.179861
# 4 -1.369849 -0.954208 1.462696 -1.743161
df1.iloc[:, 1:3]
# 2 4
# 0 -0.732339 0.687738
# 2 -0.154951 0.301624
# 4 -0.954208 1.462696
# 6 -0.345352 1.314232
# 8 2.396780 0.014871
# 10 -1.236269 0.896171
# これは``df1.iat[1, 1]``に等しい
df1.iloc[1, 1]
# -0.1549507744249032
位置番号による断面の取得(df.xs(1)に等しい)。
df1.iloc[1]
# 0 0.403310
# 2 -0.154951
# 4 0.301624
# 6 -2.179861
# Name: 2, dtype: float64
範囲外のスライスインデックスは、Python/NumPy と同じように適切に処理されます。
# これらはPython/NumPyで使用可能。
x = list('abcdef')
x
# ['a', 'b', 'c', 'd', 'e', 'f']
x[4:10]
# ['e', 'f']
x[8:10]
# []
s = pd.Series(x)
s
# 0 a
# 1 b
# 2 c
# 3 d
# 4 e
# 5 f
# dtype: object
s.iloc[4:10]
# 4 e
# 5 f
# dtype: object
s.iloc[8:10]
# Series([], dtype: object)
範囲外のスライスを使用すると、軸が空になる(たとえば、空のDataFrameが返される)可能性があることに注意してください。
dfl = pd.DataFrame(np.random.randn(5, 2), columns=list('AB'))
dfl
# A B
# 0 -0.082240 -2.182937
# 1 0.380396 0.084844
# 2 0.432390 1.519970
# 3 -0.493662 0.600178
# 4 0.274230 0.132885
dfl.iloc[:, 2:3]
# Empty DataFrame
# Columns: []
# Index: [0, 1, 2, 3, 4]
dfl.iloc[:, 1:3]
# B
# 0 -2.182937
# 1 0.084844
# 2 1.519970
# 3 0.600178
# 4 0.132885
dfl.iloc[4:6]
# A B
# 4 0.27423 0.132885
単一のインデクサが範囲を超えている場合はIndexErrorを送出します。インデクサのリストにおいていずれかの要素が範囲外にある場合はIndexErrorを送出します。
>>> dfl.iloc[[4, 5, 6]]
IndexError: positional indexers are out-of-bounds
>>> dfl.iloc[:, 4]
IndexError: single positional indexer is out-of-bounds
呼び出し関数による選択
.loc,.iloc,[]による索引はcallableをインデクサをして受け取れます。callableは引数を一つ(SeriesまたはDataFrame)とり、有効なインデクサを返す関数でなければなりません。
df1 = pd.DataFrame(np.random.randn(6, 4),
index=list('abcdef'),
columns=list('ABCD'))
df1
# A B C D
# a -0.023688 2.410179 1.450520 0.206053
# b -0.251905 -2.213588 1.063327 1.266143
# c 0.299368 -0.863838 0.408204 -1.048089
# d -0.025747 -0.988387 0.094055 1.262731
# e 1.289997 0.082423 -0.055758 0.536580
# f -0.489682 0.369374 -0.034571 -2.484478
df1.loc[lambda df: df['A'] > 0, :]
# A B C D
# c 0.299368 -0.863838 0.408204 -1.048089
# e 1.289997 0.082423 -0.055758 0.536580
df1.loc[:, lambda df: ['A', 'B']]
# A B
# a -0.023688 2.410179
# b -0.251905 -2.213588
# c 0.299368 -0.863838
# d -0.025747 -0.988387
# e 1.289997 0.082423
# f -0.489682 0.369374
df1.iloc[:, lambda df: [0, 1]]
# A B
# a -0.023688 2.410179
# b -0.251905 -2.213588
# c 0.299368 -0.863838
# d -0.025747 -0.988387
# e 1.289997 0.082423
# f -0.489682 0.369374
df1[lambda df: df.columns[0]]
# a -0.023688
# b -0.251905
# c 0.299368
# d -0.025747
# e 1.289997
# f -0.489682
# Name: A, dtype: float64
Seriesでも使用できます。
df1['A'].loc[lambda s: s > 0]
# c 0.299368
# e 1.289997
# Name: A, dtype: float64
これらのメソッド・インデクサを使用すると、一時変数を使用せずにデータ選択操作を連鎖できます。
bb = pd.read_csv('data/baseball.csv', index_col='id')
(bb.groupby(['year', 'team']).sum(numeric_only=True)
.loc[lambda df: df['r'] > 100])
# stint g ab r h X2b ... so ibb hbp sh sf gidp
# year team ...
# 2007 CIN 6 379 745 101 203 35 ... 127.0 14.0 1.0 1.0 15.0 18.0
# DET 5 301 1062 162 283 54 ... 176.0 3.0 10.0 4.0 8.0 28.0
# HOU 4 311 926 109 218 47 ... 212.0 3.0 9.0 16.0 6.0 17.0
# LAN 11 413 1021 153 293 61 ... 141.0 8.0 9.0 3.0 8.0 29.0
# NYN 13 622 1854 240 509 101 ... 310.0 24.0 23.0 18.0 15.0 48.0
# SFN 5 482 1305 198 337 67 ... 188.0 51.0 8.0 16.0 6.0 41.0
# TEX 2 198 729 115 200 40 ... 140.0 4.0 5.0 2.0 8.0 16.0
# TOR 4 459 1408 187 378 96 ... 265.0 16.0 12.0 4.0 16.0 38.0
# [8 rows x 18 columns]
位置ベースとラベルベースのインデックスの組み合わせ
'A'列のインデックスから0番目と2番目の要素を取得したい場合は、このようにします。
dfd = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]},
index=list('abc'))
dfd
# A B
# a 1 4
# b 2 5
# c 3 6
dfd.loc[dfd.index[[0, 2]], 'A']
# a 1
# c 3
# Name: A, dtype: int64
これは、.ilocを使用して、インデクサ上の位置を明示的に取得し、位置による索引を使用して選択することによっても表現できます。
dfd.iloc[[0, 2], dfd.columns.get_loc('A')]
# a 1
# c 3
# Name: A, dtype: int64
複数のインデクサを取得するには、.get_indexerを使用します。
dfd.iloc[[0, 2], dfd.columns.get_indexer(['A', 'B'])]
# A B
# a 1 4
# c 3 6
存在しないキーを含むリストによる取得は非推奨
バージョン1.0.0で変更
存在しないラベルを1つ以上含むリストを用いた.locまたは[]によるインデックスの再作成はできなくなりました。代わりに.reindexを利用してください。
以前のバージョンでは、.loc[list-of-labels]を使っても、少なくとも1つのキーが見つかる限りは動作していました(そうでない場合はKeyErrorが発生します)。この挙動は変更され、少なくとも1つのラベルが見つからない場合はKeyErrorが発生するようになりました。推奨される代替方法は.reindex()を使用することです。
例。
s = pd.Series([1, 2, 3])
s
# 0 1
# 1 2
# 2 3
# dtype: int64
全てのキーが見つかった場合の挙動は変わりせん。
s.loc[[1, 2]]
# 1 2
# 2 3
# dtype: int64
以前の挙動。
s.loc[[1, 2, 3]]
# 1 2.0
# 2 3.0
# 3 NaN
# dtype: float64
現在の挙動
s.loc[[1, 2, 3]]
# Passing list-likes to .loc with any non-matching elements will raise
# KeyError in the future, you can use .reindex() as an alternative.
#
# See the documentation here:
# https://pandas.pydata.org/pandas-docs/stable/indexing.html#deprecate-loc-reindex-listlike
# 1 2.0
# 2 3.0
# 3 NaN
# dtype: float64
インデックスの再作成
見つからない可能性のある要素を選択するための一般的な方法は、.reindex()を使用することです。インデックスの再作成の節も参照してください。
s.reindex([1, 2, 3])
# 1 2.0
# 2 3.0
# 3 NaN
# dtype: float64
あるいは、有効なキーだけを選択したい場合は、次の方法が慣例的かつ効率的です。選択部分のデータ型が保持されることが保証されています。
labels = [1, 2, 3]
s.loc[s.index.intersection(labels)]
# 1 2
# 2 3
# dtype: int64
インデックスに重複がある場合、.reindex()においてエラーが送出されます。
s = pd.Series(np.arange(4), index=['a', 'a', 'b', 'c'])
labels = ['c', 'd']
s.reindex(labels)
# ValueError: cannot reindex on an axis with duplicate labels
通常、目的のラベルを現在の軸と交差させてから、インデックスを再作成します。
s.loc[s.index.intersection(labels)].reindex(labels)
# c 3.0
# d NaN
# dtype: float64
ただし、結果のインデックスが重複している場合は、この方法でもエラーが発生します。
labels = ['a', 'd']
s.loc[s.index.intersection(labels)].reindex(labels)
# ValueError: cannot reindex on an axis with duplicate labels
ランダムサンプルの選択
sample()メソッドを使用すると Series または DataFrame から行または列をランダムに選択できます。このメソッドはデフォルトでは行をサンプリングし、返される行/列の数あるいは割合を受け取ります。
s = pd.Series([0, 1, 2, 3, 4, 5])
# 引数がない場合、1行が返される
s.sample()
# 4 4
# dtype: int64
# 行数を指定することも可能
s.sample(n=3)
# 0 0
# 4 4
# 1 1
# dtype: int64
# 行数の割合を指定することも可能
s.sample(frac=0.5)
# 5 5
# 3 3
# 1 1
# dtype: int64
デフォルトでは、sampleは各行を最大1回返しますが、replace引数を使用して重複を許可するサンプリングをすることもできます。
s = pd.Series([0, 1, 2, 3, 4, 5])
# replacementなし(デフォルト)
s.sample(n=6, replace=False)
# 0 0
# 1 1
# 5 5
# 3 3
# 2 2
# 4 4
# dtype: int64
# replacementあり:
s.sample(n=6, replace=True)
# 0 0
# 4 4
# 3 3
# 2 2
# 4 4
# 4 4
# dtype: int64
デフォルトでは、各行は選択される確率が同じですが、行に異なる確率を持たせたい場合は、weights引数によって重みをsample関数に渡すことができます。この重みはリスト・NumPy配列・Seriesが使用できますが、それらはサンプリングするオブジェクトと同じ長さでなければなりません。欠損値は重みゼロとして扱われ、またinf値は使用できません。重みの合計が1でない場合は、すべての重みを重みの合計で除算することによって、正規化されます。例えば、
s = pd.Series([0, 1, 2, 3, 4, 5])
example_weights = [0, 0, 0.2, 0.2, 0.2, 0.4]
s.sample(n=3, weights=example_weights)
# 5 5
# 4 4
# 3 3
# dtype: int64
# 重みは自動的に正規化される
example_weights2 = [0.5, 0, 0, 0, 0, 0]
s.sample(n=1, weights=example_weights2)
# 0 0
# dtype: int64
DataFrameに適用する場合、列の名前を文字列として渡すだけで、DataFrameの列をサンプリングの重みとして使用できます(列ではなく、行をサンプリングする場合)。
df2 = pd.DataFrame({'col1': [9, 8, 7, 6],
'weight_column': [0.5, 0.4, 0.1, 0]})
df2.sample(n=3, weights='weight_column')
# col1 weight_column
# 1 8 0.4
# 0 9 0.5
# 2 7 0.1
sampleはまたaxis引数を使用して行ではなく列をサンプリングすることもできます。
df3 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
df3.sample(n=1, axis=1)
# col1
# 0 1
# 1 2
# 2 3
最後に、random_state引数を使用して、sampleの乱数ジェネレータのシードを設定することもできます。これは、整数(シードとして)または NumPy RandomState オブジェクトのいずれかを受け入れます。
df4 = pd.DataFrame({'col1': [1, 2, 3], 'col2': [2, 3, 4]})
# シードを与えると、常に同じ行をサンプリングできる
df4.sample(n=2, random_state=2)
# col1 col2
# 2 3 4
# 1 2 3
df4.sample(n=2, random_state=2)
# col1 col2
# 2 3 4
# 1 2 3
代入による拡張
.loc/[]操作は、その軸に存在しないキーに代入すると、拡張を実行できます。
Seriesの場合、これは事実上要素追加操作です。
se = pd.Series([1, 2, 3])
se
# 0 1
# 1 2
# 2 3
# dtype: int64
se[5] = 5.
se
# 0 1.0
# 1 2.0
# 2 3.0
# 5 5.0
# dtype: float64
DataFrameは、.locを介してどちらの軸でも拡張できます。
dfi = pd.DataFrame(np.arange(6).reshape(3, 2),
columns=['A', 'B'])
dfi
# A B
# 0 0 1
# 1 2 3
# 2 4 5
dfi.loc[:, 'C'] = dfi.loc[:, 'A']
dfi
# A B C
# 0 0 1 0
# 1 2 3 2
# 2 4 5 4
これはDataFrameのappend操作に似ています。
dfi.loc[3] = 5
dfi
# A B C
# 0 0 1 0
# 1 2 3 2
# 2 4 5 4
# 3 5 5 5
高速なスカラー値の取得と代入
[]によるインデックス付けは多くのケース(単一ラベルアクセス、スライス、真偽値による索引など)を処理する必要があり、何が要求されているのかを把握するために少しオーバーヘッドがあります。スカラー値にのみアクセスしたい場合は、すべてのデータ構造に実装されている.atメソッドと.iatメソッドを使用するのが最も早い方法です。
.locと同様に、.atはラベルベースのスカラー検索を提供し、.iatは.ilocと同様に位置番号ベースの検索を提供します。
s.iat[5]
# 5
df.at[dates[5], 'A']
# -0.6736897080883706
df.iat[3, 0]
# 0.7215551622443669
同じインデクサを使って代入することもできます。
df.at[dates[5], 'E'] = 7
df.iat[3, 0] = 7
インデクサが存在しない値の場合、.atは上記のようにオブジェクトをインプレースで拡張することがあります。
df.at[dates[-1] + pd.Timedelta('1 day'), 0] = 7
df
# A B C D E 0
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN
# 2000-01-03 -0.861849 -2.104569 -0.494929 1.071804 NaN NaN
# 2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN
# 2000-01-05 -0.424972 0.567020 0.276232 -1.087401 NaN NaN
# 2000-01-06 -0.673690 0.113648 -1.478427 0.524988 7.0 NaN
# 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaN
# 2000-01-08 -0.370647 -1.157892 -1.344312 0.844885 NaN NaN
# 2000-01-09 NaN NaN NaN NaN NaN 7.0
真偽値による索引
もう 1 つの一般的な操作は、データをフィルタリングするための真偽値ベクトルを用いることです。演算子は以下のとおりです。|はor,&はand,~はnot。デフォルトでは Python はdf['A'] > 2 & df['B'] < 3のような式をdf['A'] > (2 & df['B']) < 3として評価しますが、望ましい評価順序は(df['A'] > 2) & (df['B'] < 3)であるため、これらは括弧を使用してグループ化しなければなりません。
Seriesの索引のための真偽値ベクトルの使用は、NumPy ndarray の場合とまったく同じように機能します。
s = pd.Series(range(-3, 4))
s
# 0 -3
# 1 -2
# 2 -1
# 3 0
# 4 1
# 5 2
# 6 3
# dtype: int64
s[s > 0]
# 4 1
# 5 2
# 6 3
# dtype: int64
s[(s < -1) | (s > 0.5)]
# 0 -3
# 1 -2
# 4 1
# 5 2
# 6 3
# dtype: int64
s[~(s < 0)]
# 3 0
# 4 1
# 5 2
# 6 3
# dtype: int64
DataFrameのインデックスと同じ長さの真偽値ベクトル(例えば、DataFrameの列の1つから派生したもの)を使用して、DataFrameから行を選択できます。
df[df['A'] > 0]
# A B C D E 0
# 2000-01-01 0.469112 -0.282863 -1.509059 -1.135632 NaN NaN
# 2000-01-02 1.212112 -0.173215 0.119209 -1.044236 NaN NaN
# 2000-01-04 7.000000 -0.706771 -1.039575 0.271860 NaN NaN
# 2000-01-07 0.404705 0.577046 -1.715002 -1.039268 NaN NaN
リスト内包表記と Series のmapメソッドを利用して、より複雑な基準を作成することもできます。
df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'three', 'two', 'one', 'six'],
'b': ['x', 'y', 'y', 'x', 'y', 'x', 'x'],
'c': np.random.randn(7)})
# 'two'か'three'だけが必要な場合
criterion = df2['a'].map(lambda x: x.startswith('t'))
df2[criterion]
# a b c
# 2 two y 0.041290
# 3 three x 0.361719
# 4 two y -0.238075
# 同じ結果だが遅い
df2[[x.startswith('t') for x in df2['a']]]
# a b c
# 2 two y 0.041290
# 3 three x 0.361719
# 4 two y -0.238075
# 複数の基準
df2[criterion & (df2['b'] == 'x')]
# a b c
# 3 three x 0.361719
ラベルによる選択・位置による選択・高度な索引では、真偽値ベクトルを他の索引式と組み合わせて使用して、複数の軸から選択することができます。
df2.loc[criterion & (df2['b'] == 'x'), 'b':'c']
# b c
# 3 x 0.361719
ilocは2種類の真偽値インデックスをサポートしています。インデクサーが真偽値型のSeriesの場合、エラーが発生します。例えば以下の例では、df.iloc[s.values, 1]は真偽値インデクサーは配列であるため問題ありませんが、df.iloc[s, 1]ではValueErrorが発生します。
df = pd.DataFrame([[1, 2], [3, 4], [5, 6]],
index=list('abc'),
columns=['A', 'B'])
s = (df['A'] > 2)
s
# a False
# b True
# c True
# Name: A, dtype: bool
df.loc[s, 'B']
# b 4
# c 6
# Name: B, dtype: int64
df.iloc[s.values, 1]
# b 4
# c 6
# Name: B, dtype: int64
isin による索引
Seriesのisin()メソッドを考えてみましょう。このメソッドは、Seriesの要素が渡されたリストの中に存在する場合は真となる、真偽値ベクトルを返します。これにより、1 つ以上の列に必要な値がある行を選択できます。
s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64')
s
# 4 0
# 3 1
# 2 2
# 1 3
# 0 4
# dtype: int64
s.isin([2, 4, 6])
# 4 False
# 3 False
# 2 True
# 1 False
# 0 True
# dtype: bool
s[s.isin([2, 4, 6])]
# 2 2
# 0 4
# dtype: int64
同じ方法がIndexオブジェクトにも利用でき、探しているラベルのどれが実際に存在しているのかわからない場合に役立ちます。
s[s.index.isin([2, 4, 6])]
# 4 0
# 2 2
# dtype: int64
# 次の例と比較する
s.reindex([2, 4, 6])
# 2 2.0
# 4 0.0
# 6 NaN
# dtype: float64
それに加えて、MultiIndexではメンバーシップチェックで使用するために別のレベルを選択することができます。
s_mi = pd.Series(np.arange(6),
index=pd.MultiIndex.from_product([[0, 1], ['a', 'b', 'c']]))
s_mi
# 0 a 0
# b 1
# c 2
# 1 a 3
# b 4
# c 5
# dtype: int64
s_mi.iloc[s_mi.index.isin([(1, 'a'), (2, 'b'), (0, 'c')])]
# 0 c 2
# 1 a 3
# dtype: int64
s_mi.iloc[s_mi.index.isin(['a', 'c', 'e'], level=1)]
# 0 a 0
# c 2
# 1 a 3
# c 5
# dtype: int64
DataFrameにもisin()メソッドがあります。 isinを呼び出すときは、一連の値を配列または辞書として渡します。もし値が配列の場合、isinは元の DataFrame と同じ形状の真偽値の DataFrame を返します。これは要素が値のシーケンス内にある場合は True になります。
df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
'ids2': ['a', 'n', 'c', 'n']})
values = ['a', 'b', 1, 3]
df.isin(values)
# vals ids ids2
# 0 True True True
# 1 False True False
# 2 True False False
# 3 False False False
多くの場合、特定の値を特定の列と一致させる必要があります。キーが列で、値がチェックしたい項目のリストになっている辞書dictを値として渡すだけです。
values = {'ids': ['a', 'b'], 'vals': [1, 3]}
df.isin(values)
# vals ids ids2
# 0 True True False
# 1 False True False
# 2 True False False
# 3 False False False
元のDataFrameにその値がないことを示す真偽値のDataFrameを返すには、~演算子を使用します。
values = {'ids': ['a', 'b'], 'vals': [1, 3]}
~df.isin(values)
# vals ids ids2
# 0 False False True
# 1 True False True
# 2 False True True
# 3 True True True
DataFrame のisinとany()やall()メソッドを組み合わせて、特定の基準を満たすデータのサブセットをすばやく選択できます。各列がそれぞれの基準を満たす行を選択するには、
values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
row_mask = df.isin(values).all(1)
df[row_mask]
# vals ids ids2
# 0 1 a a
where()メソッドとマスク
真偽値ベクトルを使用して Series から値を選択すると、通常、データのサブセットが返されます。出力が元のデータと同じ形状になるようにするためには、SeriesおよびDataFrameのwhereメソッドを使用します。
選択した行だけを返すには、
s[s > 0]
# 3 1
# 2 2
# 1 3
# 0 4
# dtype: int64
オリジナルと同じ形の Series を返すには、
s.where(s > 0)
# 4 NaN
# 3 1.0
# 2 2.0
# 1 3.0
# 0 4.0
# dtype: float64
ブール基準を使用して DataFrame から値を選択すると、入力データの形状も保持されるようになりました。whereは実装として内部で使用されています。以下のコードは、df.where(df < 0)と同等です。
df[df < 0]
# A B C D
# 2000-01-01 -2.104139 -1.309525 NaN NaN
# 2000-01-02 -0.352480 NaN -1.192319 NaN
# 2000-01-03 -0.864883 NaN -0.227870 NaN
# 2000-01-04 NaN -1.222082 NaN -1.233203
# 2000-01-05 NaN -0.605656 -1.169184 NaN
# 2000-01-06 NaN -0.948458 NaN -0.684718
# 2000-01-07 -2.670153 -0.114722 NaN -0.048048
# 2000-01-08 NaN NaN -0.048788 -0.808838
さらに、whereは、返されたコピーにおいて、条件が False の場合に値を置き換えるためのオプション引数otherを受け取ります。
df.where(df < 0, -df)
# A B C D
# 2000-01-01 -2.104139 -1.309525 -0.485855 -0.245166
# 2000-01-02 -0.352480 -0.390389 -1.192319 -1.655824
# 2000-01-03 -0.864883 -0.299674 -0.227870 -0.281059
# 2000-01-04 -0.846958 -1.222082 -0.600705 -1.233203
# 2000-01-05 -0.669692 -0.605656 -1.169184 -0.342416
# 2000-01-06 -0.868584 -0.948458 -2.297780 -0.684718
# 2000-01-07 -2.670153 -0.114722 -0.168904 -0.048048
# 2000-01-08 -0.801196 -1.392071 -0.048788 -0.808838
あなたはあるブール基準に基づいて値を代入したいと思うかもしれません。これは以下のように直感的に行うことができます。
s2 = s.copy()
s2[s2 < 0] = 0
s2
# 4 0
# 3 1
# 2 2
# 1 3
# 0 4
# dtype: int64
df2 = df.copy()
df2[df2 < 0] = 0
df2
# A B C D
# 2000-01-01 0.000000 0.000000 0.485855 0.245166
# 2000-01-02 0.000000 0.390389 0.000000 1.655824
# 2000-01-03 0.000000 0.299674 0.000000 0.281059
# 2000-01-04 0.846958 0.000000 0.600705 0.000000
# 2000-01-05 0.669692 0.000000 0.000000 0.342416
# 2000-01-06 0.868584 0.000000 2.297780 0.000000
# 2000-01-07 0.000000 0.000000 0.168904 0.000000
# 2000-01-08 0.801196 1.392071 0.000000 0.000000
デフォルトでは、whereは変更したデータのコピーを返します。コピーを作成しなくても元のデータを変更できるように、オプションのパラメータinplaceがあります。
df_orig = df.copy()
df_orig.where(df > 0, -df, inplace=True)
df_orig
# A B C D
# 2000-01-01 2.104139 1.309525 0.485855 0.245166
# 2000-01-02 0.352480 0.390389 1.192319 1.655824
# 2000-01-03 0.864883 0.299674 0.227870 0.281059
# 2000-01-04 0.846958 1.222082 0.600705 1.233203
# 2000-01-05 0.669692 0.605656 1.169184 0.342416
# 2000-01-06 0.868584 0.948458 2.297780 0.684718
# 2000-01-07 2.670153 0.114722 0.168904 0.048048
# 2000-01-08 0.801196 1.392071 0.048788 0.808838
where()の書き方は、numpy.where()とは異なります。df1.where(m, df2)は、おおむねnp.where(m, df1, df2)と同等です。
df.where(df < 0, -df) == np.where(df < 0, df, -df)
# A B C D
# 2000-01-01 True True True True
# 2000-01-02 True True True True
# 2000-01-03 True True True True
# 2000-01-04 True True True True
# 2000-01-05 True True True True
# 2000-01-06 True True True True
# 2000-01-07 True True True True
# 2000-01-08 True True True True
整列
また、whereは入力されたブール条件(ndarrayまたはDataFrame)を揃え、特定部分を選択して代入することが可能になります。これは、.locによる部分的な代入に似ています(ただし、軸ラベルではなく内容に対して)。
df2 = df.copy()
df2[df2[1:4] > 0] = 3
df2
# A B C D
# 2000-01-01 -2.104139 -1.309525 0.485855 0.245166
# 2000-01-02 -0.352480 3.000000 -1.192319 3.000000
# 2000-01-03 -0.864883 3.000000 -0.227870 3.000000
# 2000-01-04 3.000000 -1.222082 3.000000 -1.233203
# 2000-01-05 0.669692 -0.605656 -1.169184 0.342416
# 2000-01-06 0.868584 -0.948458 2.297780 -0.684718
# 2000-01-07 -2.670153 -0.114722 0.168904 -0.048048
# 2000-01-08 0.801196 1.392071 -0.048788 -0.808838
whereは、whereを実行するときの入力を調整するためにaxisとlevelのパラメータを受け取ることもできます。
df2 = df.copy()
df2.where(df2 > 0, df2['A'], axis='index')
# A B C D
# 2000-01-01 -2.104139 -2.104139 0.485855 0.245166
# 2000-01-02 -0.352480 0.390389 -0.352480 1.655824
# 2000-01-03 -0.864883 0.299674 -0.864883 0.281059
# 2000-01-04 0.846958 0.846958 0.600705 0.846958
# 2000-01-05 0.669692 0.669692 0.669692 0.342416
# 2000-01-06 0.868584 0.868584 2.297780 0.868584
# 2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
# 2000-01-08 0.801196 1.392071 0.801196 0.801196
これは、次のものと同等(ただし、より速い)です。
df2 = df.copy()
df.apply(lambda x, y: x.where(x > 0, y), y=df['A'])
# A B C D
# 2000-01-01 -2.104139 -2.104139 0.485855 0.245166
# 2000-01-02 -0.352480 0.390389 -0.352480 1.655824
# 2000-01-03 -0.864883 0.299674 -0.864883 0.281059
# 2000-01-04 0.846958 0.846958 0.600705 0.846958
# 2000-01-05 0.669692 0.669692 0.669692 0.342416
# 2000-01-06 0.868584 0.868584 2.297780 0.868584
# 2000-01-07 -2.670153 -2.670153 0.168904 -2.670153
# 2000-01-08 0.801196 1.392071 0.801196 0.801196
whereは、条件やother引数に呼び出し可能関数(callable)を受け取ることができます。関数は 1 つの引数(呼び出し元の Series または DataFrame)を受け取り、条件やother引数として有効な出力を返す必要があります。
df3 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]})
df3.where(lambda x: x > 4, lambda x: x + 10)
# A B C
# 0 11 14 7
# 1 12 5 8
# 2 13 6 9
マスク
mask()はwhereの逆のブール演算です。
s.mask(s >= 0)
# 4 NaN
# 3 NaN
# 2 NaN
# 1 NaN
# 0 NaN
# dtype: float64
df.mask(df >= 0)
# A B C D
# 2000-01-01 -2.104139 -1.309525 NaN NaN
# 2000-01-02 -0.352480 NaN -1.192319 NaN
# 2000-01-03 -0.864883 NaN -0.227870 NaN
# 2000-01-04 NaN -1.222082 NaN -1.233203
# 2000-01-05 NaN -0.605656 -1.169184 NaN
# 2000-01-06 NaN -0.948458 NaN -0.684718
# 2000-01-07 -2.670153 -0.114722 NaN -0.048048
# 2000-01-08 NaN NaN -0.048788 -0.808838
numpyを使って条件付きで拡大して設定する
where()の代わりにnumpy.where()を使うこともできます。新しい列を設定することと組み合わせて、値が条件によって決定されるデータフレームを拡大するために使用することができます。
次のデータフレームでは、2つの選択肢があると考えてください。そして、2つ目のカラムに「Z」があるときに、新しいカラムの色を「green」に設定したいとします。以下のようにすることができます。
df = pd.DataFrame({'col1': list('ABBC'), 'col2': list('ZZXY')})
df['color'] = np.where(df['col2'] == 'Z', 'green', 'red')
df
# col1 col2 color
# 0 A Z green
# 1 B Z green
# 2 B X red
# 3 C Y red
複数の条件がある場合は、numpy.select()を使うことで実現できます。3つの条件に対応して、3つの色の選択肢があり、4つ目の色を予備として使うと、以下のようになります。
conditions = [
(df['col2'] == 'Z') & (df['col1'] == 'A'),
(df['col2'] == 'Z') & (df['col1'] == 'B'),
(df['col1'] == 'B')
]
choices = ['yellow', 'blue', 'purple']
df['color'] = np.select(conditions, choices, default='black')
df
# col1 col2 color
# 0 A Z yellow
# 1 B Z blue
# 2 B X purple
# 3 C Y black
query()メソッド
DataFrameオブジェクトには、式を使って選択できるquery()メソッドがあります。
列bが列aとcの間の値を持つフレームの値を取得できます。例えば、
n = 10
df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
df
# a b c
# 0 0.438921 0.118680 0.863670
# 1 0.138138 0.577363 0.686602
# 2 0.595307 0.564592 0.520630
# 3 0.913052 0.926075 0.616184
# 4 0.078718 0.854477 0.898725
# 5 0.076404 0.523211 0.591538
# 6 0.792342 0.216974 0.564056
# 7 0.397890 0.454131 0.915716
# 8 0.074315 0.437913 0.019794
# 9 0.559209 0.502065 0.026437
# 純粋なpython
df[(df['a'] < df['b']) & (df['b'] < df['c'])]
# a b c
# 1 0.138138 0.577363 0.686602
# 4 0.078718 0.854477 0.898725
# 5 0.076404 0.523211 0.591538
# 7 0.397890 0.454131 0.915716
# query
df.query('(a < b) & (b < c)')
# a b c
# 1 0.138138 0.577363 0.686602
# 4 0.078718 0.854477 0.898725
# 5 0.076404 0.523211 0.591538
# 7 0.397890 0.454131 0.915716
名前がaの列がない場合は、名前付きインデックスまで戻って、同じことを行います。
df = pd.DataFrame(np.random.randint(n / 2, size=(n, 2)), columns=list('bc'))
df.index.name = 'a'
df
# b c
# a
# 0 0 4
# 1 0 1
# 2 3 4
# 3 4 3
# 4 1 4
# 5 0 3
# 6 0 1
# 7 3 4
# 8 2 3
# 9 1 1
df.query('a < b and b < c')
# b c
# a
# 2 3 4
代わりに、インデックスに名前を付けたくない、またはできない場合は、クエリ式に名前indexを使用できます。
df = pd.DataFrame(np.random.randint(n, size=(n, 2)), columns=list('bc'))
df
# b c
# 0 3 1
# 1 3 0
# 2 5 6
# 3 5 2
# 4 7 4
# 5 0 1
# 6 2 5
# 7 0 1
# 8 6 0
# 9 7 9
df.query('index < b < c')
# b c
# 2 5 6
インデックスの名前が列名と重複する場合は、列名が優先されます。例えば、
df = pd.DataFrame({'a': np.random.randint(5, size=5)})
df.index.name = 'a'
df.query('a > 2') # インデックスではなく列aに適用
#
a
a
1 3
3 3
特別な識別子「index」を使用することで、クエリ式でインデックスを使用することができます。
df.query('index > 2')
#
a
a
3 3
4 2
何らかの理由でindexという名前の列がある場合は、ilevel_0とすることでインデックスを参照できますが、この場合は列の名前をあいまいさの少ない名前に変更することを検討してください。
MultiIndex query()シンタックス
DataFrame の列のように、MultiIndexを使用してDataFrameのレベルに対して使用することもできます。
n = 10
colors = np.random.choice(['red', 'green'], size=n)
foods = np.random.choice(['eggs', 'ham'], size=n)
colors
# array(['red', 'red', 'red', 'green', 'green', 'green', 'green', 'green',
# 'green', 'green'], dtype='<U5')
foods
# array(['ham', 'ham', 'eggs', 'eggs', 'eggs', 'ham', 'ham', 'eggs', 'eggs',
# 'eggs'], dtype='<U4')
index = pd.MultiIndex.from_arrays([colors, foods], names=['color', 'food'])
df = pd.DataFrame(np.random.randn(n, 2), index=index)
df
# 0 1
# color food
# red ham 0.194889 -0.381994
# ham 0.318587 2.089075
# eggs -0.728293 -0.090255
# green eggs -0.748199 1.318931
# eggs -2.029766 0.792652
# ham 0.461007 -0.542749
# ham -0.305384 -0.479195
# eggs 0.095031 -0.270099
# eggs -0.707140 -0.773882
# eggs 0.229453 0.304418
df.query('color == "red"')
# 0 1
# color food
# red ham 0.194889 -0.381994
# ham 0.318587 2.089075
# eggs -0.728293 -0.090255
MultiIndexのレベルに名前が付いていない場合は、特別な名前を使用してそれらを参照できます。
df.index.names = [None, None]
df
# 0 1
# red ham 0.194889 -0.381994
# ham 0.318587 2.089075
# eggs -0.728293 -0.090255
# green eggs -0.748199 1.318931
# eggs -2.029766 0.792652
# ham 0.461007 -0.542749
# ham -0.305384 -0.479195
# eggs 0.095031 -0.270099
# eggs -0.707140 -0.773882
# eggs 0.229453 0.304418
df.query('ilevel_0 == "red"')
# 0 1
# red ham 0.194889 -0.381994
# ham 0.318587 2.089075
# eggs -0.728293 -0.090255
規則はilevel_0です。これは、indexの 0 番目のレベル、「index level 0」を意味します。
query()の活用例
query()が活きるのは、共通の列名(またはインデックスのレベル/名前)のサブセットを持つDataFrameオブジェクトのコレクションがある場合です。どちらのフレームにクエリを実行するのかを指定しなくても、両方のフレームに同じクエリを渡すことができます。
df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
df
# a b c
# 0 0.224283 0.736107 0.139168
# 1 0.302827 0.657803 0.713897
# 2 0.611185 0.136624 0.984960
# 3 0.195246 0.123436 0.627712
# 4 0.618673 0.371660 0.047902
# 5 0.480088 0.062993 0.185760
# 6 0.568018 0.483467 0.445289
# 7 0.309040 0.274580 0.587101
# 8 0.258993 0.477769 0.370255
# 9 0.550459 0.840870 0.304611
df2 = pd.DataFrame(np.random.rand(n + 2, 3), columns=df.columns)
df2
# a b c
# 0 0.357579 0.229800 0.596001
# 1 0.309059 0.957923 0.965663
# 2 0.123102 0.336914 0.318616
# 3 0.526506 0.323321 0.860813
# 4 0.518736 0.486514 0.384724
# 5 0.190804 0.505723 0.614533
# 6 0.891939 0.623977 0.676639
# 7 0.480559 0.378528 0.460858
# 8 0.420223 0.136404 0.141295
# 9 0.732206 0.419540 0.604675
# 10 0.604466 0.848974 0.896165
# 11 0.589168 0.920046 0.732716
expr = '0.0 <= a <= c <= 0.5'
map(lambda frame: frame.query(expr), [df, df2])
# <map at 0x7fb06bd71cf8>
query()の Python と Pandas の構文比較
完全な NumPy 式の構文
df = pd.DataFrame(np.random.randint(n, size=(n, 3)), columns=list('abc'))
df
# a b c
# 0 7 8 9
# 1 1 0 7
# 2 2 7 2
# 3 6 2 2
# 4 2 6 3
# 5 3 8 2
# 6 1 7 2
# 7 5 1 5
# 8 9 8 0
# 9 1 5 0
df.query('(a < b) & (b < c)')
# a b c
# 0 7 8 9
df[(df['a'] < df['b']) & (df['b'] < df['c'])]
# a b c
# 0 7 8 9
括弧を削除することで少しすっきりします(比較演算子は&や|より優先されて結合します)。
df.query('a < b & b < c')
# a b c
# 0 7 8 9
記号の代わりに英語を使います。
df.query('a < b and b < c')
# a b c
# 0 7 8 9
紙に書くような文法にかなり近づきました。
df.query('a < b < c')
# a b c
# 0 7 8 9
in演算子とnot in演算子
query()は Python の特殊演算子in,not inもサポートし、SeriesまたはDataFrameのisinメソッドを呼び出す際の簡潔な構文を提供します。
# 列aと列bが重複して持っている値をとる、すべての行を取得する
df = pd.DataFrame({'a': list('aabbccddeeff'), 'b': list('aaaabbbbcccc'),
'c': np.random.randint(5, size=12),
'd': np.random.randint(9, size=12)})
df
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 3 b a 2 1
# 4 c b 3 6
# 5 c b 0 2
# 6 d b 3 3
# 7 d b 2 1
# 8 e c 4 3
# 9 e c 2 0
# 10 f c 0 6
# 11 f c 1 2
df.query('a in b')
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 3 b a 2 1
# 4 c b 3 6
# 5 c b 0 2
# 純粋なpythonではどのように行うか
df[df['a'].isin(df['b'])]
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 3 b a 2 1
# 4 c b 3 6
# 5 c b 0 2
df.query('a not in b')
# a b c d
# 6 d b 3 3
# 7 d b 2 1
# 8 e c 4 3
# 9 e c 2 0
# 10 f c 0 6
# 11 f c 1 2
# 純粋なpython
df[~df['a'].isin(df['b'])]
# a b c d
# 6 d b 3 3
# 7 d b 2 1
# 8 e c 4 3
# 9 e c 2 0
# 10 f c 0 6
# 11 f c 1 2
非常に簡潔なクエリ式で、これを他の式と組み合わせることができます。
# 列aと列bが重複して持っている値をとり、
# かつ列cの値が列dの値より小さい行
df.query('a in b and c < d')
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 4 c b 3 6
# 5 c b 0 2
# 純粋なpython
df[df['b'].isin(df['a']) & (df['c'] < df['d'])]
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 4 c b 3 6
# 5 c b 0 2
# 10 f c 0 6
# 11 f c 1 2
inとnot inは、numexprにはこの演算子に相当するものがないため、Pythonで評価されます。ただし、in/not inの表現自体だけが、純粋なPythonで評価されます。例えば、
df.query('a in b + c + d')
この場合、(b + c + d)がnumexprで評価された後で、in演算子が純粋なPythonで評価されます。基本的には、numexprが使える演算子はすべてそれで評価されます。
listオブジェクトにおける特殊な==演算子の用法
==/!=を使用して値のlistと列を比較すると、in/not inと同じように機能します。
df.query('b == ["a", "b", "c"]')
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 3 b a 2 1
# 4 c b 3 6
# 5 c b 0 2
# 6 d b 3 3
# 7 d b 2 1
# 8 e c 4 3
# 9 e c 2 0
# 10 f c 0 6
# 11 f c 1 2
# 純粋なpython
df[df['b'].isin(["a", "b", "c"])]
# a b c d
# 0 a a 2 6
# 1 a a 4 7
# 2 b a 1 6
# 3 b a 2 1
# 4 c b 3 6
# 5 c b 0 2
# 6 d b 3 3
# 7 d b 2 1
# 8 e c 4 3
# 9 e c 2 0
# 10 f c 0 6
# 11 f c 1 2
df.query('c == [1, 2]')
# a b c d
# 0 a a 2 6
# 2 b a 1 6
# 3 b a 2 1
# 7 d b 2 1
# 9 e c 2 0
# 11 f c 1 2
df.query('c != [1, 2]')
# a b c d
# 1 a a 4 7
# 4 c b 3 6
# 5 c b 0 2
# 6 d b 3 3
# 8 e c 4 3
# 10 f c 0 6
# in/not inを用いて
df.query('[1, 2] in c')
# a b c d
# 0 a a 2 6
# 2 b a 1 6
# 3 b a 2 1
# 7 d b 2 1
# 9 e c 2 0
# 11 f c 1 2
df.query('[1, 2] not in c')
# a b c d
# 1 a a 4 7
# 4 c b 3 6
# 5 c b 0 2
# 6 d b 3 3
# 8 e c 4 3
# 10 f c 0 6
# 純粋なpython
df[df['c'].isin([1, 2])]
# a b c d
# 0 a a 2 6
# 2 b a 1 6
# 3 b a 2 1
# 7 d b 2 1
# 9 e c 2 0
# 11 f c 1 2
ブール演算子
notまたは~演算子を使って真偽値を反転することができます。
df = pd.DataFrame(np.random.rand(n, 3), columns=list('abc'))
df['bools'] = np.random.rand(len(df)) > 0.5
df.query('~bools')
# a b c bools
# 2 0.697753 0.212799 0.329209 False
# 7 0.275396 0.691034 0.826619 False
# 8 0.190649 0.558748 0.262467 False
df.query('not bools')
# a b c bools
# 2 0.697753 0.212799 0.329209 False
# 7 0.275396 0.691034 0.826619 False
# 8 0.190649 0.558748 0.262467 False
df.query('not bools') == df[~df['bools']]
# a b c bools
# 2 True True True True
# 7 True True True True
# 8 True True True True
もちろん、式がどんどん複雑になる可能性もあります。
# 短いクエリ構文
shorter = df.query('a < b < c and (not bools) or bools > 2')
# 純粋なpython式との比較
longer = df[(df['a'] < df['b'])
& (df['b'] < df['c'])
& (~df['bools'])
| (df['bools'] > 2)]
shorter
# a b c bools
# 7 0.275396 0.691034 0.826619 False
longer
# a b c bools
# 7 0.275396 0.691034 0.826619 False
shorter == longer
# a b c bools
# 7 True True True True
query()のパフォーマンス
numexprを使用したDataFrame.query()は、大きなフレームではPythonよりわずかに高速です。
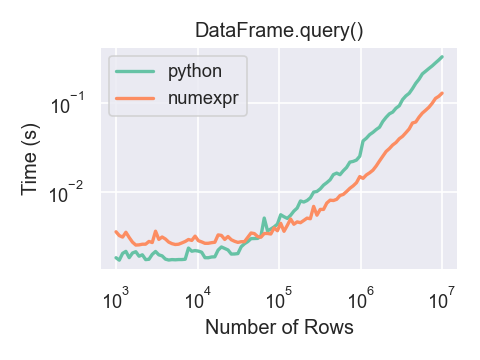
numexprエンジンによるDataFrame.query()のパフォーマンス上の利点が目に見えてくるのは、フレームが約20万行を越えてからです。

このプロットは、numpy.random.randn()を使用して生成した、浮動小数点値を含む3列のDataFrameを使用して作成されました。
重複データ
DataFrame 内の重複する行を識別したり削除したりする場合は、duplicatedとdrop_duplicatesの 2 つの方法が役立ちます。それぞれは、重複行を識別するために使用する列を引数として取ります。
-
duplicatedは、行数が長さとなる、重複行かどうかを示す真偽値ベクトルを返します。 -
drop_duplicatesは重複する行を削除します。
デフォルトでは、重複セットのうち最初に現れた行はユニークであると見なされますが、各メソッドには保持する対象を指定するためのkeepパラメータがあります。
-
keep='first'(デフォルト):最初に現れたものを除いて、重複をマーク/削除します。 -
keep='last':最後に現れたものを除いて、重複をマーク/削除します。 -
keep=False:全ての重複をマーク/削除します。
df2 = pd.DataFrame({'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
'b': ['x', 'y', 'x', 'y', 'x', 'x', 'x'],
'c': np.random.randn(7)})
df2
# a b c
# 0 one x -1.067137
# 1 one y 0.309500
# 2 two x -0.211056
# 3 two y -1.842023
# 4 two x -0.390820
# 5 three x -1.964475
# 6 four x 1.298329
df2.duplicated('a')
# 0 False
# 1 True
# 2 False
# 3 True
# 4 True
# 5 False
# 6 False
# dtype: bool
df2.duplicated('a', keep='last')
# 0 True
# 1 False
# 2 True
# 3 True
# 4 False
# 5 False
# 6 False
# dtype: bool
df2.duplicated('a', keep=False)
# 0 True
# 1 True
# 2 True
# 3 True
# 4 True
# 5 False
# 6 False
# dtype: bool
df2.drop_duplicates('a')
# a b c
# 0 one x -1.067137
# 2 two x -0.211056
# 5 three x -1.964475
# 6 four x 1.298329
df2.drop_duplicates('a', keep='last')
# a b c
# 1 one y 0.309500
# 4 two x -0.390820
# 5 three x -1.964475
# 6 four x 1.298329
df2.drop_duplicates('a', keep=False)
# a b c
# 5 three x -1.964475
# 6 four x 1.298329
また、重複を識別するための列をリストを渡すこともできます。
df2.duplicated(['a', 'b'])
# 0 False
# 1 False
# 2 False
# 3 False
# 4 True
# 5 False
# 6 False
# dtype: bool
df2.drop_duplicates(['a', 'b'])
# a b c
# 0 one x -1.067137
# 1 one y 0.309500
# 2 two x -0.211056
# 3 two y -1.842023
# 5 three x -1.964475
# 6 four x 1.298329
重複をインデックスの値で削除するには、Index.duplicatedを使用してからスライスを実行します。keepパラメーターに同様のオプションを渡すこともできます。
df3 = pd.DataFrame({'a': np.arange(6),
'b': np.random.randn(6)},
index=['a', 'a', 'b', 'c', 'b', 'a'])
df3
# a b
# a 0 1.440455
# a 1 2.456086
# b 2 1.038402
# c 3 -0.894409
# b 4 0.683536
# a 5 3.082764
df3.index.duplicated()
# array([False, True, False, False, True, True])
df3[~df3.index.duplicated()]
# a b
# a 0 1.440455
# b 2 1.038402
# c 3 -0.894409
df3[~df3.index.duplicated(keep='last')]
# a b
# c 3 -0.894409
# b 4 0.683536
# a 5 3.082764
df3[~df3.index.duplicated(keep=False)]
# a b
# c 3 -0.894409
辞書ライクなget()メソッド
SeriesまたはDataFrameにはそれぞれ、デフォルトの値を返すことができるgetメソッドがあります。
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
s.get('a') # s['a']に等しい
# 1
s.get('x', default=-1)
# -1
lookup()メソッド
行ラベルと列ラベルの並びを指定して値のセットを抽出したい場合、pandas.factorizeとNumPyのインデックスを組み合わせて使います。例えば
df = pd.DataFrame({'col': ["A", "A", "B", "B"],
'A': [80, 23, np.nan, 22],
'B': [80, 55, 76, 67]})
df
# col A B
# 0 A 80.0 80
# 1 A 23.0 55
# 2 B NaN 76
# 3 B 22.0 67
idx, cols = pd.factorize(df['col'])
df.reindex(cols, axis=1).to_numpy()[np.arange(len(df)), idx]
# array([80., 23., 76., 67.])
以前は、専用のDataFrame.lookupメソッドでこれを行うことができましたが、バージョン1.2.0で非推奨となりました。
Index オブジェクト
Pandas のIndexクラスとそのサブクラスは、順序付きマルチセットが実装されていると見なすことができます。重複は許可されています。ただし、重複エントリを含むIndexオブジェクトをsetに変換しようとすると、例外が発生します。
また、Indexは、検索・データの整列・インデックスの再作成に必要な構造も提供します。Indexを直接作成する最も簡単な方法は、listまたは他のシーケンスをIndexに渡すことです。
index = pd.Index(['e', 'd', 'a', 'b'])
index
# Index(['e', 'd', 'a', 'b'], dtype='object')
'd' in index
# True
インデックスに付与されるnameを渡すこともできます。
index = pd.Index(['e', 'd', 'a', 'b'], name='something')
index.name
# 'something'
name が設定されている場合は、コンソールディスプレイに表示されます。
index = pd.Index(list(range(5)), name='rows')
columns = pd.Index(['A', 'B', 'C'], name='cols')
df = pd.DataFrame(np.random.randn(5, 3), index=index, columns=columns)
df
# cols A B C
# rows
# 0 1.295989 0.185778 0.436259
# 1 0.678101 0.311369 -0.528378
# 2 -0.674808 -1.103529 -0.656157
# 3 1.889957 2.076651 -1.102192
# 4 -1.211795 -0.791746 0.634724
df['A']
# rows
# 0 1.295989
# 1 0.678101
# 2 -0.674808
# 3 1.889957
# 4 -1.211795
# Name: A, dtype: float64
メタデータの設定
インデックスは「ほぼイミュータブル」ですが、name属性を設定したり変更したりすることは可能です。rename・set_namesを使って直接これらの属性を設定することができ、デフォルトではコピーを返すようになっています。
マルチインデックスの使用法については、高度な索引を参照してください。
ind = pd.Index([1, 2, 3])
ind.rename("apple")
# Int64Index([1, 2, 3], dtype='int64', name='apple')
ind
# Int64Index([1, 2, 3], dtype='int64')
ind.set_names(["apple"], inplace=True)
ind.name = "bob"
ind
# Int64Index([1, 2, 3], dtype='int64', name='bob')
set_names,set_levels,set_codesはオプション引数levelを受け取ります。
index = pd.MultiIndex.from_product([range(3), ['one', 'two']], names=['first', 'second'])
index
# MultiIndex([(0, 'one'),
# (0, 'two'),
# (1, 'one'),
# (1, 'two'),
# (2, 'one'),
# (2, 'two')],
# names=['first', 'second'])
index.levels[1]
# Index(['one', 'two'], dtype='object', name='second')
index.set_levels(["a", "b"], level=1)
# MultiIndex([(0, 'a'),
# (0, 'b'),
# (1, 'a'),
# (1, 'b'),
# (2, 'a'),
# (2, 'b')],
# names=['first', 'second'])
Index オブジェクトに対する集合演算
基本的な演算は、和集合unionと共通部分intersectionの 2 つです。差集合は.difference()メソッドを用います。
a = pd.Index(['c', 'b', 'a'])
b = pd.Index(['c', 'e', 'd'])
a.difference(b)
# Index(['a', 'b'], dtype='object')
対称差symmetric_difference操作も使用できます。これは、idx1またはidx2のいずれか一方に出現するが両方には出現しない要素の集合を返します。これは、idx1.difference(idx2).union(idx2.difference(idx1))によって作成されたインデックスに相当しますが、重複は削除されます。
idx1 = pd.Index([1, 2, 3, 4])
idx2 = pd.Index([2, 3, 4, 5])
idx1.symmetric_difference(idx2)
# Int64Index([1, 5], dtype='int64')
集合演算の結果のインデックスは昇順でソートされます。
異なるdtypeを持つインデックス間でIndex.union()を実行する場合、インデックスは共通のdtypeに変換する必要があります。常にではありませんが、通常これはオブジェクトdtypeです。例外は、整数データと浮動小数点データの結合を実行する場合です。この場合、整数値は浮動小数点に変換されます。
idx1 = pd.Index([0, 1, 2])
idx2 = pd.Index([0.5, 1.5])
idx1.union(idx2)
# Float64Index([0.0, 0.5, 1.0, 1.5, 2.0], dtype='float64')
欠損値
Indexは欠損値(NaN)を保持できますが、予期せぬ動作に至りたくない場合は避けるべきです。たとえば、一部の操作では、欠損値が暗黙的に除外されます。
Index.fillnaは、欠損値を指定されたスカラー値で穴埋めします。
idx1 = pd.Index([1, np.nan, 3, 4])
idx1
# Float64Index([1.0, nan, 3.0, 4.0], dtype='float64')
idx1.fillna(2)
# Float64Index([1.0, 2.0, 3.0, 4.0], dtype='float64')
idx2 = pd.DatetimeIndex([pd.Timestamp('2011-01-01'),
pd.NaT,
pd.Timestamp('2011-01-03')])
idx2
# DatetimeIndex(['2011-01-01', 'NaT', '2011-01-03'], dtype='datetime64[ns]', freq=None)
idx2.fillna(pd.Timestamp('2011-01-02'))
# DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03'], dtype='datetime64[ns]', freq=None)
インデックスの作成・再作成
場合によっては、データセットを DataFrame に既にロードまたは作成した後に、インデックスを追加したいことがあります。いくつかの異なる方法があります。
インデックスの設定
DataFrame には、列名(通常のIndexの場合)または列名のリスト(MultiIndexの場合)を受け取るset_index()メソッドがあります。インデックスを再設定した DataFrame を作成するには、
data
# a b c d
# 0 bar one z 1.0
# 1 bar two y 2.0
# 2 foo one x 3.0
# 3 foo two w 4.0
indexed1 = data.set_index('c')
indexed1
# a b d
# c
# z bar one 1.0
# y bar two 2.0
# x foo one 3.0
# w foo two 4.0
indexed2 = data.set_index(['a', 'b'])
indexed2
# c d
# a b
# bar one z 1.0
# two y 2.0
# foo one x 3.0
# two w 4.0
appendキーワードオプションを使用すると、既存のインデックスを保持し、指定した列をMultiIndexに追加することができます。
frame = data.set_index('c', drop=False)
frame = frame.set_index(['a', 'b'], append=True)
frame
# c d
# c a b
# z bar one z 1.0
# y bar two y 2.0
# x foo one x 3.0
# w foo two w 4.0
set_indexの他のオプションによって、インデックスに設定した列を残したり、インデックスを上書きで(新しいオブジェクトを作成せずに)追加したりすることができます。
data.set_index('c', drop=False)
# a b c d
# c
# z bar one z 1.0
# y bar two y 2.0
# x foo one x 3.0
# w foo two w 4.0
data.set_index(['a', 'b'], inplace=True)
data
# c d
# a b
# bar one z 1.0
# two y 2.0
# foo one x 3.0
# two w 4.0
インデックスのリセット
便宜をはかるため、DataFrame にreset_index()という新しい関数があります。これは、インデックスの値を DataFrame の列に移し、単純な整数インデックスを設定します。これはset_index()の逆の操作です。
data
# c d
# a b
# bar one z 1.0
# two y 2.0
# foo one x 3.0
# two w 4.0
data.reset_index()
# a b c d
# 0 bar one z 1.0
# 1 bar two y 2.0
# 2 foo one x 3.0
# 3 foo two w 4.0
出力は、SQL のテーブルやレコードの配列に似ています。もとインデックスだった列の名前は、names属性に格納されていたものが用いられます。
levelキーワードを使用すると、インデックスの一部だけを削除できます。
frame
# c d
# c a b
# z bar one z 1.0
# y bar two y 2.0
# x foo one x 3.0
# w foo two w 4.0
frame.reset_index(level=1)
# a c d
# c b
# z one bar z 1.0
# y two bar y 2.0
# x one foo x 3.0
# w two foo w 4.0
reset_indexはオプション引数dropを受け取ります。true の場合は、DataFrame の列にインデックス値を入れる代わりに、単にインデックスを破棄します。
アドホックなインデックスの追加
自分でインデックスを作成する場合は、indexフィールドにそれを割り当てることができます。
data.index = index
返るのはビューかコピーか
Pandas オブジェクトに値を代入するときは、連鎖索引chained indexingと呼ばれるものを避けるように注意する必要があります。一例を示します。
dfmi = pd.DataFrame([list('abcd'),
list('efgh'),
list('ijkl'),
list('mnop')],
columns=pd.MultiIndex.from_product([['one', 'two'],
['first', 'second']]))
dfmi
# one two
# first second first second
# 0 a b c d
# 1 e f g h
# 2 i j k l
# 3 m n o p
次の 2 つのアクセス方法を比較してください。
dfmi['one']['second']
# 0 b
# 1 f
# 2 j
# 3 n
# Name: second, dtype: object
dfmi.loc[:, ('one', 'second')]
# 0 b
# 1 f
# 2 j
# 3 n
# Name: (one, second), dtype: object
どちらも同じ結果になりますが、どちらを使用すべきでしょうか?これらの処理順序と、方法 1(chained [])よりも方法 2(.loc)の方が好ましい理由を理解することは有益です。
前者はまずdfmi['one']は列の第一レベルを選択し、単一インデックス付きの DataFrame を返します。それから、別の Python 操作dfmi_with_one['second']によって、「second」でインデックスされた Series を選択します。これは変数dfmi_with_oneで示されます。なぜなら、pandas はこれらの操作を別々のイベントとして見なすためです。例えば__getitem__への呼び出しを分離するので、それらは線形操作として扱わなければなりません、それらは順々に起こります。
これと対照的に、df.loc[:,('one','second')]は、(slice(None),('one','second'))とネストしたタプルを 1 度だけ呼び出した__getitem__に渡します。これにより、pandas はこれを単一のエンティティとして扱うことができます。さらに、この操作の手順はかなり速くなる可能性があり、必要に応じて両方の軸にインデックスを付けることができます。
連鎖索引を使用すると、割り当てが失敗するのはなぜですか?
前項で述べた問題は、パフォーマンスの問題です。警告SettingWithCopyとはなんですか?あなたが数ミリ秒余分にかかるかもしれない何かをするとき、我々は通常警告を投げません!
しかし、連鎖索引の産物へ代入することは本質的に予測不可能な結果をもたらすことがわかりました。これを見るために、Python インタプリタがどのように次のコードを実行するかについて考えてみましょう。
dfmi.loc[:, ('one', 'second')] = value
# こうなる
dfmi.loc.__setitem__((slice(None), ('one', 'second')), value)
しかし、次のコードは異なる方法で処理されます。
dfmi['one']['second'] = value
# こうなる
dfmi.__getitem__('one').__setitem__('second', value)
この__getitem__がわかりますか?単純な場合を除いて、ビューを返すのかコピーを返すのか(これは配列のメモリレイアウトに依存し、Pandas はそれを保証しません)、つまり__setitem__がdfmiを変更するのかそれとも直後にスローされる一時オブジェクトを変更するのか、予測するのは非常に困難です。このことをSettingWithCopyは警告しています。
最初の例でlocプロパティを気にする必要があるかどうか疑問に思うかもしれません。しかし、dfmi.locはインデックス動作が変更されたdfmi自体であることが保証されているので、dfmi.loc.__getitem__/dfmi.loc.__setitem__はdfmiを直接操作します。もちろん、dfmi.loc.__getitem__(idx)はdfmiのビューまたはコピーです。
明白な連鎖索引の作成が行われていないときでも、警告SettingWithCopyが発生することがあります。これらはSettingWithCopyがキャッチするように設計されているバグです!pandas はおそらくあなたが次のようなことをしたことを警告しようとしています。
def do_something(df):
foo = df[['bar', 'baz']] # fooはビューかコピーか?誰にもわからない!
# ... この間数行 ...
# これでdfが変更されるかどうかはわかりません!
foo['quux'] = value
return foo
!?
評価順序に関する事項
連鎖索引を使用する場合、索引操作の順序と種類によって、結果が元のオブジェクトへのスライスなのか、スライスのコピーなのかが部分的に決まる場合があります。
スライスのコピーへの代入は意図的ではないことが多い――これは連鎖索引が原因でスライスが予期されていた場所にコピーが返されることによる誤りです――ため、Pandas にはSettingWithCopyWarningがあります。
Pandas が連鎖索引式への代入について多かれ少なかれ信頼できるようにしたい場合は、オプションmode.chained_assignmentを次のいずれかの値に設定します。
-
'warn'は、デフォルト値で、SettingWithCopyWarningが送出されることを意味します。 -
'raise'は、Pandas があなたが対処しなければならないSettingWithCopyErrorを発生させることを意味します。 -
Noneは、警告を完全に抑制します。
dfb = pd.DataFrame({'a': ['one', 'one', 'two',
'three', 'two', 'one', 'six'],
'c': np.arange(7)})
# これはSettingWithCopyWarningが表示される
# しかしDataFrameの値は代入される
dfb['c'][dfb['a'].str.startswith('o')] = 42
しかし次の例はコピーで動作していて動作しません。
>>> pd.set_option('mode.chained_assignment','warn')
>>> dfb[dfb['a'].str.startswith('o')]['c'] = 42
Traceback (most recent call last)
...
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_index,col_indexer] = value instead
連鎖代入は、dtype が混在したフレームに設定する際にも発生します。
これらの設定規則は、.loc/.ilocのすべてに適用されます。
以下は、.locを使用して複数の要素(maskを使用)にアクセスし、また固定インデックスを使用して単一の要素にアクセスする推奨された方法です。
dfc = pd.DataFrame({'a': ['one', 'one', 'two',
'three', 'two', 'one', 'six'],
'c': np.arange(7)})
dfd = dfc.copy()
# maskを使用して複数の要素に代入
mask = dfd['a'].str.startswith('o')
dfd.loc[mask, 'c'] = 42
dfd
# a c
# 0 one 42
# 1 one 42
# 2 two 2
# 3 three 3
# 4 two 4
# 5 one 42
# 6 six 6
# 単一の要素に代入
dfd = dfc.copy()
dfd.loc[2, 'a'] = 11
dfd
# a c
# 0 one 0
# 1 one 1
# 2 11 2
# 3 three 3
# 4 two 4
# 5 one 5
# 6 six 6
以下が機能する場合もありますが、保証されていないため、避ける必要があります。
dfd = dfc.copy()
dfd['a'][2] = 111
dfd
# a c
# 0 one 0
# 1 one 1
# 2 111 2
# 3 three 3
# 4 two 4
# 5 one 5
# 6 six 6
最後に、これは常に機能しないので、避けるべきです。
>>> pd.set_option('mode.chained_assignment','raise')
>>> dfd.loc[0]['a'] = 1111
Traceback (most recent call last)
...
SettingWithCopyError:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_index,col_indexer] = value instead
連鎖代入の警告・例外は、無効な代入を行った可能性をユーザーに通知することを目的としています。そのため、連鎖代入が誤って伝達され、誤検知がある場合があります。