本記事は、Pandas の公式ドキュメントのUser Guide - Working with missing dataを機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
欠損データの操作
このセクションでは、pandasの欠損値(NA)について説明します。
内部的にNaNを使用して欠落データを示すことを選択したのは、主に単純さとパフォーマンス上の理由によるものでした。pandas 1.0 以降、一部のオプションのデータ型は、マスクベースのアプローチを使用してネイティブNAスカラーを試行し始めます。詳細はこちらをご覧ください。
「欠損」とみなされる値
データはさまざまな形や形式で存在するため、pandasは欠落データの処理に関して柔軟であることを目指しています。NaNは計算速度と利便性の理由からデフォルトの欠損値マーカーですが、浮動小数点、整数、真偽値、および一般オブジェクトのさまざまなタイプのデータ型でこの値を簡単に検出できる必要があります。またしかし、多くの場合、PythonのNoneも見られ、「欠落」または「利用不可」または「NA」も考慮する必要があります。
計算でinfと-infを「NA」と見なしたい場合は、pandas.options.mode.use_inf_as_na = Trueによって設定できます。
df = pd.DataFrame(
np.random.randn(5, 3),
index=["a", "c", "e", "f", "h"],
columns=["one", "two", "three"],
)
df["four"] = "bar"
df["five"] = df["one"] > 0
df
# one two three four five
# a 0.469112 -0.282863 -1.509059 bar True
# c -1.135632 1.212112 -0.173215 bar False
# e 0.119209 -1.044236 -0.861849 bar True
# f -2.104569 -0.494929 1.071804 bar False
# h 0.721555 -0.706771 -1.039575 bar True
df2 = df.reindex(["a", "b", "c", "d", "e", "f", "g", "h"])
df2
# one two three four five
# a 0.469112 -0.282863 -1.509059 bar True
# b NaN NaN NaN NaN NaN
# c -1.135632 1.212112 -0.173215 bar False
# d NaN NaN NaN NaN NaN
# e 0.119209 -1.044236 -0.861849 bar True
# f -2.104569 -0.494929 1.071804 bar False
# g NaN NaN NaN NaN NaN
# h 0.721555 -0.706771 -1.039575 bar True
(ときには異なるデータ型の配列を通して)欠損値の検出を容易にするために、pandasはisna()およびnotna()関数を用意しています。これらは、Series および DataFrame オブジェクトのメソッドでもあります。
df2["one"]
# a 0.469112
# b NaN
# c -1.135632
# d NaN
# e 0.119209
# f -2.104569
# g NaN
# h 0.721555
# Name: one, dtype: float64
pd.isna(df2["one"])
# a False
# b True
# c False
# d True
# e False
# f False
# g True
# h False
# Name: one, dtype: bool
df2["four"].notna()
# a True
# b False
# c True
# d False
# e True
# f True
# g False
# h True
# Name: four, dtype: bool
df2.isna()
# one two three four five
# a False False False False False
# b True True True True True
# c False False False False False
# d True True True True True
# e False False False False False
# f False False False False False
# g True True True True True
# h False False False False False
Python(およびNumPy)では、nanは同等ではなく、Noneは同等であることに注意する必要があります。pandas/NumPyはnp.nan != np.nanという事実を使用しながら、np.nanのようにNoneを扱うことに注意してください。
None == None # noqa: E711
# True
np.nan == np.nan
# False
したがって、上記と比較して、None/np.nanに対するスカラー等値比較は有用な情報を提供しません。
df2["one"] == np.nan
# a False
# b False
# c False
# d False
# e False
# f False
# g False
# h False
# Name: one, dtype: bool
整数データ型と欠損データ
NaNは浮動小数点数であるため、欠損値が1つでもある整数の列は、浮動小数点数データ型に変換されます(詳細については、整数NAのサポートを参照してください)。pandasは、欠損値を含むことができる整数配列を提供します。これは、データ型を明示的に指定することで使用できます。
pd.Series([1, 2, np.nan, 4], dtype=pd.Int64Dtype())
# 0 1
# 1 2
# 2 <NA>
# 3 4
# dtype: Int64
文字列エイリアスdtype='Int64'(大文字の"I"に注意)を指定することでも使用可能です。
詳しくは欠損可能整数データ型を参照してください。
時系列データ(datetime)
datetime64[ns] 型の場合、NaTが欠損値を表します。これは、NumPyの単一のデータ型( datetime64[ns] )で表すことができる擬似ネイティブのセンチネル値です。pandasオブジェクトは、NaTとNaNの間の互換性を提供します。
df2 = df.copy()
df2["timestamp"] = pd.Timestamp("20120101")
df2
# one two three four five timestamp
# a 0.469112 -0.282863 -1.509059 bar True 2012-01-01
# c -1.135632 1.212112 -0.173215 bar False 2012-01-01
# e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
# f -2.104569 -0.494929 1.071804 bar False 2012-01-01
# h 0.721555 -0.706771 -1.039575 bar True 2012-01-01
df2.loc[["a", "c", "h"], ["one", "timestamp"]] = np.nan
df2
# one two three four five timestamp
# a NaN -0.282863 -1.509059 bar True NaT
# c NaN 1.212112 -0.173215 bar False NaT
# e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
# f -2.104569 -0.494929 1.071804 bar False 2012-01-01
# h NaN -0.706771 -1.039575 bar True NaT
df2.dtypes.value_counts()
# float64 3
# object 1
# bool 1
# datetime64[ns] 1
# dtype: int64
欠損データの挿入
コンテナに割り当てるだけで、欠損値を挿入できます。使用される実際の欠損値は、データ型に基づいて選択されます。
たとえば、与えられた欠損値の型に関係なく、数値コンテナは常にNaNを使用します。
s = pd.Series([1, 2, 3])
s.loc[0] = None
s
# 0 NaN
# 1 2.0
# 2 3.0
# dtype: float64
同様に、時系列コンテナは常にNaTを使用します。
オブジェクトコンテナの場合、pandasは与えられた値を使用します。
s = pd.Series(["a", "b", "c"])
s.loc[0] = None
s.loc[1] = np.nan
s
# 0 None
# 1 NaN
# 2 c
# dtype: object
欠損データに対する計算
欠損値は、pandasオブジェクト間の算術演算を通じて自然に伝播します。
a
# one two
# a NaN -0.282863
# c NaN 1.212112
# e 0.119209 -1.044236
# f -2.104569 -0.494929
# h -2.104569 -0.706771
b
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e 0.119209 -1.044236 -0.861849
# f -2.104569 -0.494929 1.071804
# h NaN -0.706771 -1.039575
a + b
# one three two
# a NaN NaN -0.565727
# c NaN NaN 2.424224
# e 0.238417 NaN -2.088472
# f -4.209138 NaN -0.989859
# h NaN NaN -1.413542
データ構造の概要(およびこちらとこちらのリスト)で説明されている記述統計と計算方法はすべて、欠損データを説明するために書かれています。例えば:
- データを合計するとき、NA(欠損)値はゼロとして扱われます。
- データがすべてNAの場合、結果は0になります。
-
cumsum()やcumprod()などの累積メソッドは、デフォルトではNA値を無視しますが、結果の配列には保持します。この動作をオーバーライドしてNA値を含めるには、skipna=Falseを使用します。
df
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e 0.119209 -1.044236 -0.861849
# f -2.104569 -0.494929 1.071804
# h NaN -0.706771 -1.039575
df["one"].sum()
# -1.9853605075978744
df.mean(1)
# a -0.895961
# c 0.519449
# e -0.595625
# f -0.509232
# h -0.873173
# dtype: float64
df.cumsum()
# one two three
# a NaN -0.282863 -1.509059
# c NaN 0.929249 -1.682273
# e 0.119209 -0.114987 -2.544122
# f -1.985361 -0.609917 -1.472318
# h NaN -1.316688 -2.511893
df.cumsum(skipna=False)
# one two three
# a NaN -0.282863 -1.509059
# c NaN 0.929249 -1.682273
# e NaN -0.114987 -2.544122
# f NaN -0.609917 -1.472318
# h NaN -1.316688 -2.511893
空・欠損データにおける総和・総乗
この動作はバージョン0.22.0現在の標準であり、numpyのデフォルトと一致しています。以前は、全てNAまたは空のシリーズ・データフレームに対する総和・総乗はNaNを返していました。詳細については、v0.22.0 whatsnewを参照してください。
空あるいは全てがNAのSeriesまたはDataFrameの列の総和は0です。
pd.Series([np.nan]).sum()
# 0.0
pd.Series([], dtype="float64").sum()
# 0.0
空あるいは全てがNAのSeriesまたはDataFrameの列の総乗は1です。
pd.Series([np.nan]).prod()
# 1.0
pd.Series([], dtype="float64").prod()
# 1.0
GroupBy における欠損値
GroupByではNAグループは自動的に除外されます。この動作は、Rと一致しています。例えば、
df
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e 0.119209 -1.044236 -0.861849
# f -2.104569 -0.494929 1.071804
# h NaN -0.706771 -1.039575
df.groupby("one").mean()
# two three
# one
# -2.104569 -0.494929 1.071804
# 0.119209 -1.044236 -0.861849
詳細については、こちらのgroupbyセクションをご覧ください。
欠損データの除外・穴埋め
pandasオブジェクトには、欠損データを処理するためのさまざまなデータ操作メソッドが装備されています。
欠損値の穴埋め――fillna
fillna()は、欠損値を非欠損データで「穴埋め」することができます。
欠損値をスカラー値に置換
df2
# one two three four five timestamp
# a NaN -0.282863 -1.509059 bar True NaT
# c NaN 1.212112 -0.173215 bar False NaT
# e 0.119209 -1.044236 -0.861849 bar True 2012-01-01
# f -2.104569 -0.494929 1.071804 bar False 2012-01-01
# h NaN -0.706771 -1.039575 bar True NaT
df2.fillna(0)
# one two three four five timestamp
# a 0.000000 -0.282863 -1.509059 bar True 0
# c 0.000000 1.212112 -0.173215 bar False 0
# e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 00:00:00
# f -2.104569 -0.494929 1.071804 bar False 2012-01-01 00:00:00
# h 0.000000 -0.706771 -1.039575 bar True 0
df2["one"].fillna("missing")
# a missing
# c missing
# e 0.119209
# f -2.104569
# h missing
# Name: one, dtype: object
前方または後方のデータによる穴埋め
リインデックスと同様の穴埋めパラメータを使用して、非欠損値を前方または後方に伝播させることができます。
df
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e 0.119209 -1.044236 -0.861849
# f -2.104569 -0.494929 1.071804
# h NaN -0.706771 -1.039575
df.fillna(method="pad")
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e 0.119209 -1.044236 -0.861849
# f -2.104569 -0.494929 1.071804
# h -2.104569 -0.706771 -1.039575
穴埋め量の制限
連続したギャップを一定のデータポイントまで埋めるだけの場合は、limitキーワードを使用できます。
df
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e NaN NaN NaN
# f NaN NaN NaN
# h NaN -0.706771 -1.039575
df.fillna(method="pad", limit=1)
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e NaN 1.212112 -0.173215
# f NaN NaN NaN
# h NaN -0.706771 -1.039575
利用可能な穴埋め方法は以下のとおりです。
| メソッド | 動作 |
|---|---|
| pad / ffill | 前方へ穴埋め |
| bfill / backfill | 後方へ穴埋め |
時系列データでは、pad/ffillの使用は非常に一般的であるため、「最後の既知の値」がすべての時点で利用できるようになっています。
ffill()はfillna(method='ffill')と同等であり、bfill()はfillna(method='bfill')と同等です。
pandas オブジェクトによる穴埋め
整列可能な辞書またはシリーズを使用して穴埋めすることもできます。辞書のキーあるいはシリーズのインデックスは、穴埋めしたいフレームの列名と一致する必要があります。以下の例は、データフレームにその列の平均を入力しています。
dff = pd.DataFrame(np.random.randn(10, 3), columns=list("ABC"))
dff.iloc[3:5, 0] = np.nan
dff.iloc[4:6, 1] = np.nan
dff.iloc[5:8, 2] = np.nan
dff
# A B C
# 0 0.271860 -0.424972 0.567020
# 1 0.276232 -1.087401 -0.673690
# 2 0.113648 -1.478427 0.524988
# 3 NaN 0.577046 -1.715002
# 4 NaN NaN -1.157892
# 5 -1.344312 NaN NaN
# 6 -0.109050 1.643563 NaN
# 7 0.357021 -0.674600 NaN
# 8 -0.968914 -1.294524 0.413738
# 9 0.276662 -0.472035 -0.013960
dff.fillna(dff.mean())
# A B C
# 0 0.271860 -0.424972 0.567020
# 1 0.276232 -1.087401 -0.673690
# 2 0.113648 -1.478427 0.524988
# 3 -0.140857 0.577046 -1.715002
# 4 -0.140857 -0.401419 -1.157892
# 5 -1.344312 -0.401419 -0.293543
# 6 -0.109050 1.643563 -0.293543
# 7 0.357021 -0.674600 -0.293543
# 8 -0.968914 -1.294524 0.413738
# 9 0.276662 -0.472035 -0.013960
dff.fillna(dff.mean()["B":"C"])
# A B C
# 0 0.271860 -0.424972 0.567020
# 1 0.276232 -1.087401 -0.673690
# 2 0.113648 -1.478427 0.524988
# 3 NaN 0.577046 -1.715002
# 4 NaN -0.401419 -1.157892
# 5 -1.344312 -0.401419 -0.293543
# 6 -0.109050 1.643563 -0.293543
# 7 0.357021 -0.674600 -0.293543
# 8 -0.968914 -1.294524 0.413738
# 9 0.276662 -0.472035 -0.013960
上記と同じ結果ですが、以下の場合はシリーズである「穴埋め」の値を揃えています。
dff.where(pd.notna(dff), dff.mean(), axis="columns")
# A B C
# 0 0.271860 -0.424972 0.567020
# 1 0.276232 -1.087401 -0.673690
# 2 0.113648 -1.478427 0.524988
# 3 -0.140857 0.577046 -1.715002
# 4 -0.140857 -0.401419 -1.157892
# 5 -1.344312 -0.401419 -0.293543
# 6 -0.109050 1.643563 -0.293543
# 7 0.357021 -0.674600 -0.293543
# 8 -0.968914 -1.294524 0.413738
# 9 0.276662 -0.472035 -0.013960
データが欠損している軸ラベルの削除――dropna
単純に、欠損データを参照しているラベルをデータセットから除外したい場合もあるでしょう。これを行うには、dropna()を使用します。
df
# one two three
# a NaN -0.282863 -1.509059
# c NaN 1.212112 -0.173215
# e NaN 0.000000 0.000000
# f NaN 0.000000 0.000000
# h NaN -0.706771 -1.039575
df.dropna(axis=0)
# Empty DataFrame
# Columns: [one, two, three]
# Index: []
df.dropna(axis=1)
# two three
# a -0.282863 -1.509059
# c 1.212112 -0.173215
# e 0.000000 0.000000
# f 0.000000 0.000000
# h -0.706771 -1.039575
df["one"].dropna()
# Series([], Name: one, dtype: float64)
シリーズにも同等のdropna()が用意されています。DataFrame.dropna には Series.dropna よりもかなり多くのオプションがあり、APIで調べることができます。
補間
シリーズオブジェクトとデータフレームオブジェクトの両方にinterpolate()があり、デフォルトでは、欠落しているデータポイントで線形補間を実行します。
ts
# 2000-01-31 0.469112
# 2000-02-29 NaN
# 2000-03-31 NaN
# 2000-04-28 NaN
# 2000-05-31 NaN
# ...
# 2007-12-31 -6.950267
# 2008-01-31 -7.904475
# 2008-02-29 -6.441779
# 2008-03-31 -8.184940
# 2008-04-30 -9.011531
# Freq: BM, Length: 100, dtype: float64
ts.count()
# 66
ts.plot()
# <AxesSubplot:>
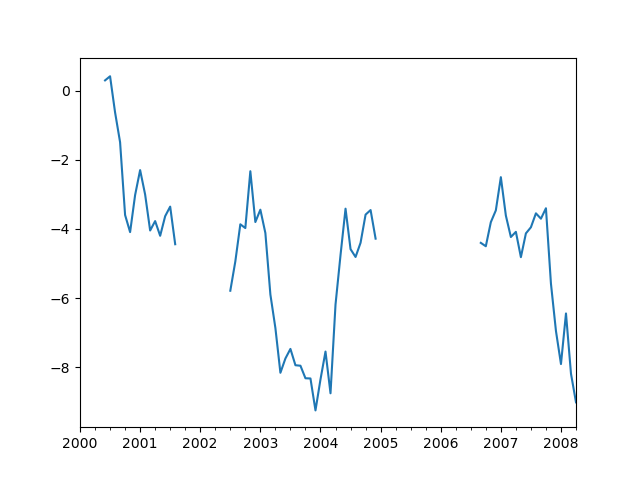
ts.interpolate()
# 2000-01-31 0.469112
# 2000-02-29 0.434469
# 2000-03-31 0.399826
# 2000-04-28 0.365184
# 2000-05-31 0.330541
# ...
# 2007-12-31 -6.950267
# 2008-01-31 -7.904475
# 2008-02-29 -6.441779
# 2008-03-31 -8.184940
# 2008-04-30 -9.011531
# Freq: BM, Length: 100, dtype: float64
ts.interpolate().count()
# 100
ts.interpolate().plot()
# <AxesSubplot:>
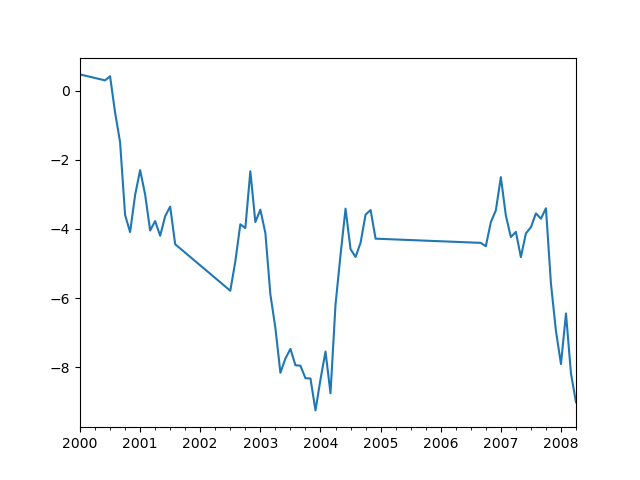
methodキーワードを用いることで、インデックスに基づいた補間を実行できます。
ts2
# 2000-01-31 0.469112
# 2000-02-29 NaN
# 2002-07-31 -5.785037
# 2005-01-31 NaN
# 2008-04-30 -9.011531
# dtype: float64
ts2.interpolate()
# 2000-01-31 0.469112
# 2000-02-29 -2.657962
# 2002-07-31 -5.785037
# 2005-01-31 -7.398284
# 2008-04-30 -9.011531
# dtype: float64
ts2.interpolate(method="time")
# 2000-01-31 0.469112
# 2000-02-29 0.270241
# 2002-07-31 -5.785037
# 2005-01-31 -7.190866
# 2008-04-30 -9.011531
# dtype: float64
浮動小数点インデックスの場合、method='values'を使用します。
ser
# 0.0 0.0
# 1.0 NaN
# 10.0 10.0
# dtype: float64
ser.interpolate()
# 0.0 0.0
# 1.0 5.0
# 10.0 10.0
# dtype: float64
ser.interpolate(method="values")
# 0.0 0.0
# 1.0 1.0
# 10.0 10.0
# dtype: float64
同様に、データフレームを補間することができます。
df = pd.DataFrame(
{
"A": [1, 2.1, np.nan, 4.7, 5.6, 6.8],
"B": [0.25, np.nan, np.nan, 4, 12.2, 14.4],
}
)
df
# A B
# 0 1.0 0.25
# 1 2.1 NaN
# 2 NaN NaN
# 3 4.7 4.00
# 4 5.6 12.20
# 5 6.8 14.40
df.interpolate()
# A B
# 0 1.0 0.25
# 1 2.1 1.50
# 2 3.4 2.75
# 3 4.7 4.00
# 4 5.6 12.20
# 5 6.8 14.40
method引数を用いることで、より高度な補間を実行することができます。scipyがインストールされている場合は、一次元補間ルーチンの名前をmethodに渡すことができます。詳細については、scipyの補間に関するドキュメントやリファレンスガイドを参照してください。適切な補間方法は、扱うデータの種類によって異なります。
- 増加率の高い時系列を扱う場合は、
method='quadratic'が適切かもしれません。 - 累積分布関数に近似した値の場合は、
method='pchip'がうまく機能するはずです。 - スムーズなプロットを目指して欠損値を埋めるには、
method='akima'を検討してください。
これらのメソッドにはscipyが必要です。
df.interpolate(method="barycentric")
# A B
# 0 1.00 0.250
# 1 2.10 -7.660
# 2 3.53 -4.515
# 3 4.70 4.000
# 4 5.60 12.200
# 5 6.80 14.400
df.interpolate(method="pchip")
# A B
# 0 1.00000 0.250000
# 1 2.10000 0.672808
# 2 3.43454 1.928950
# 3 4.70000 4.000000
# 4 5.60000 12.200000
# 5 6.80000 14.400000
df.interpolate(method="akima")
# A B
# 0 1.000000 0.250000
# 1 2.100000 -0.873316
# 2 3.406667 0.320034
# 3 4.700000 4.000000
# 4 5.600000 12.200000
# 5 6.800000 14.400000
多項式またはスプライン近似で補間する場合は、近似の次数も指定する必要があります。
df.interpolate(method="spline", order=2)
# A B
# 0 1.000000 0.250000
# 1 2.100000 -0.428598
# 2 3.404545 1.206900
# 3 4.700000 4.000000
# 4 5.600000 12.200000
# 5 6.800000 14.400000
df.interpolate(method="polynomial", order=2)
# A B
# 0 1.000000 0.250000
# 1 2.100000 -2.703846
# 2 3.451351 -1.453846
# 3 4.700000 4.000000
# 4 5.600000 12.200000
# 5 6.800000 14.400000
いくつかの方法を比較してみましょう。
np.random.seed(2)
ser = pd.Series(np.arange(1, 10.1, 0.25) ** 2 + np.random.randn(37))
missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
ser[missing] = np.nan
methods = ["linear", "quadratic", "cubic"]
df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
df.plot()
# <AxesSubplot:>
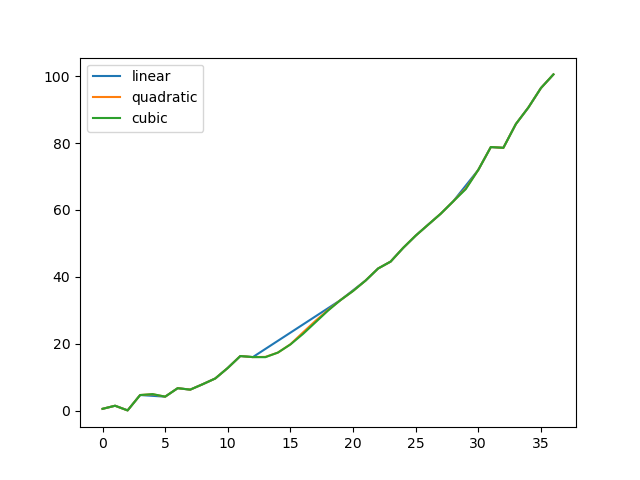
もうひとつの使用例は、新しい値での補間です。ある分布から100個の観測値があるとします。そして、中央付近で何が起こっているかに特に興味があるとしましょう。pandasのreindexとinterpolateメソッドを組み合わせることで、新しい値で補間することができます。
ser = pd.Series(np.sort(np.random.uniform(size=100)))
# 新しいインデックスに対する補間
new_index = ser.index.union(pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]))
interp_s = ser.reindex(new_index).interpolate(method="pchip")
interp_s[49:51]
# 49.00 0.471410
# 49.25 0.476841
# 49.50 0.481780
# 49.75 0.485998
# 50.00 0.489266
# 50.25 0.491814
# 50.50 0.493995
# 50.75 0.495763
# 51.00 0.497074
# dtype: float64
補間の制限
pandasの他の穴埋めメソッドと同様に、interpolate()はキーワード引数limitを受け取ります。この引数を使用して、最後の有効な観測以降に入力された連続したNaN値の数を制限できます。
ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, np.nan, 13, np.nan, np.nan])
ser
# 0 NaN
# 1 NaN
# 2 5.0
# 3 NaN
# 4 NaN
# 5 NaN
# 6 13.0
# 7 NaN
# 8 NaN
# dtype: float64
# 前方へ連続するすべての値を埋める
ser.interpolate()
# 0 NaN
# 1 NaN
# 2 5.0
# 3 7.0
# 4 9.0
# 5 11.0
# 6 13.0
# 7 13.0
# 8 13.0
# dtype: float64
# 前方へ1つだけ値を埋める
ser.interpolate(limit=1)
# 0 NaN
# 1 NaN
# 2 5.0
# 3 7.0
# 4 NaN
# 5 NaN
# 6 13.0
# 7 13.0
# 8 NaN
# dtype: float64
デフォルトでは、NaN値は順方向に穴埋めされます。後方または両方向から穴埋めするには、limit_directionパラメータを使用します。
# 後方へ1つ穴埋め
ser.interpolate(limit=1, limit_direction="backward")
# 0 NaN
# 1 5.0
# 2 5.0
# 3 NaN
# 4 NaN
# 5 11.0
# 6 13.0
# 7 NaN
# 8 NaN
# dtype: float64
# 両方向へ1つ穴埋め
ser.interpolate(limit=1, limit_direction="both")
# 0 NaN
# 1 5.0
# 2 5.0
# 3 7.0
# 4 NaN
# 5 11.0
# 6 13.0
# 7 13.0
# 8 NaN
# dtype: float64
# 両方向に連続するすべての値を埋める
ser.interpolate(limit_direction="both")
# 0 5.0
# 1 5.0
# 2 5.0
# 3 7.0
# 4 9.0
# 5 11.0
# 6 13.0
# 7 13.0
# 8 13.0
# dtype: float64
デフォルトでは、NaN値は、既存の有効な値の内側(囲まれている)でも、既存の有効な値の外側でも穴埋めされます。v0.23で導入されたlimit_areaパラメータは、内部または外部の値への入力を制限します。
# 両方向に1つの連続する内側の値を埋める
ser.interpolate(limit_direction="both", limit_area="inside", limit=1)
# 0 NaN
# 1 NaN
# 2 5.0
# 3 7.0
# 4 NaN
# 5 11.0
# 6 13.0
# 7 NaN
# 8 NaN
# dtype: float64
# 連続するすべての外側の値を逆方向に埋める
ser.interpolate(limit_direction="backward", limit_area="outside")
# 0 5.0
# 1 5.0
# 2 5.0
# 3 NaN
# 4 NaN
# 5 NaN
# 6 13.0
# 7 NaN
# 8 NaN
# dtype: float64
# 両方向に連続するすべての外側の値を埋める
ser.interpolate(limit_direction="both", limit_area="outside")
# 0 5.0
# 1 5.0
# 2 5.0
# 3 NaN
# 4 NaN
# 5 NaN
# 6 13.0
# 7 13.0
# 8 13.0
# dtype: float64
一般的な値の置換
任意の値を他の値に置き換えたいと思うことはよくあります。
シリーズのreplace()およびデータフレームのreplace()によって、そのような置換を効率的かつ柔軟に実行できます。
シリーズの場合、単一の値または値のリストを別の値で置き換えることができます。
ser = pd.Series([0.0, 1.0, 2.0, 3.0, 4.0])
ser.replace(0, 5)
# 0 5.0
# 1 1.0
# 2 2.0
# 3 3.0
# 4 4.0
# dtype: float64
値のリストを他の値のリストで置き換えることができます。
ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0])
# 0 4.0
# 1 3.0
# 2 2.0
# 3 1.0
# 4 0.0
# dtype: float64
マッピング辞書を指定することもできます。
ser.replace({0: 10, 1: 100})
# 0 10.0
# 1 100.0
# 2 2.0
# 3 3.0
# 4 4.0
# dtype: float64
データフレームの場合、列ごとに個別の値を指定できます。
df = pd.DataFrame({"a": [0, 1, 2, 3, 4], "b": [5, 6, 7, 8, 9]})
df.replace({"a": 0, "b": 5}, 100)
# a b
# 0 100 100
# 1 1 6
# 2 2 7
# 3 3 8
# 4 4 9
指定された値で置き換える代わりに、指定されたすべての値を欠損値として扱い、それらを補間することができます。
ser.replace([1, 2, 3], method="pad")
# 0 0.0
# 1 0.0
# 2 0.0
# 3 0.0
# 4 4.0
# dtype: float64
文字列・正規表現の置換
r'hello world'のようにrが前に付いたPython文字列は、いわゆる「生の(raw)」文字列です。これらは、接頭辞のない文字列とは異なるバックスラッシュに関するセマンティクスを持っています。生の文字列内のバックスラッシュは、エスケープされたバックスラッシュとして解釈されます(例:r'\' == '\\')。このことがよくわかっていない場合は、このことについて読む必要があります。
「.」をNaNに置き換えます(文字列→文字列)。
d = {"a": list(range(4)), "b": list("ab.."), "c": ["a", "b", np.nan, "d"]}
df = pd.DataFrame(d)
df.replace(".", np.nan)
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
次に、正規表現で周囲の空白を削除します(正規表現→正規表現)。
df.replace(r"\s*\.\s*", np.nan, regex=True)
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
いくつかの異なる値を置き換えます(リスト→リスト)。
df.replace(["a", "."], ["b", np.nan])
# a b c
# 0 0 b b
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
正規表現のリスト→正規表現のリスト。
df.replace([r"\.", r"(a)"], ["dot", r"\1stuff"], regex=True)
# a b c
# 0 0 astuff astuff
# 1 1 b b
# 2 2 dot NaN
# 3 3 dot d
列'b'のみを検索(辞書→辞書)。
df.replace({"b": "."}, {"b": np.nan})
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
前の例と同じですが、代わりに検索に正規表現を使用します(正規表現の辞書→辞書)。
df.replace({"b": r"\s*\.\s*"}, {"b": np.nan}, regex=True)
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
regex=Trueを使用して正規表現のネストされた辞書を渡すことができます。
df.replace({"b": {"b": r""}}, regex=True)
# a b c
# 0 0 a a
# 1 1 b
# 2 2 . NaN
# 3 3 . d
または、ネストされた辞書を次のように渡すこともできます。
df.replace(regex={"b": {r"\s*\.\s*": np.nan}})
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 NaN NaN
# 3 3 NaN d
正規表現一致のグループを使用して置換することもできます(正規表現の辞書→正規表現の辞書)。これはリストでも機能します。
df.replace({"b": r"\s*(\.)\s*"}, {"b": r"\1ty"}, regex=True)
# a b c
# 0 0 a a
# 1 1 b b
# 2 2 .ty NaN
# 3 3 .ty d
正規表現のリストを渡すことができ、一致するものはスカラーに置き換えられます(正規表現のリスト→正規表現)。
df.replace([r"\s*\.\s*", r"a|b"], np.nan, regex=True)
# a b c
# 0 0 NaN NaN
# 1 1 NaN NaN
# 2 2 NaN NaN
# 3 3 NaN d
正規表現の例はすべて、to_replace引数をregex引数として渡すこともできます。この場合、value引数は明示的に名前で渡されるか、regexはネストされた辞書である必要があります。この場合の前の例は、次のようになります。
df.replace(regex=[r"\s*\.\s*", r"a|b"], value=np.nan)
# a b c
# 0 0 NaN NaN
# 1 1 NaN NaN
# 2 2 NaN NaN
# 3 3 NaN d
これは、正規表現を使用するたびにregex=Trueを渡したくない場合に便利です。
上記のreplaceの例において、正規表現を渡すことができる場面はすべて、コンパイルされた正規表現を渡しても同様に有効です。
数値の置換
df = pd.DataFrame(np.random.randn(10, 2))
df[np.random.rand(df.shape[0]) > 0.5] = 1.5
df.replace(1.5, np.nan)
# 0 1
# 0 -0.844214 -1.021415
# 1 0.432396 -0.323580
# 2 0.423825 0.799180
# 3 1.262614 0.751965
# 4 NaN NaN
# 5 NaN NaN
# 6 -0.498174 -1.060799
# 7 0.591667 -0.183257
# 8 1.019855 -1.482465
# 9 NaN NaN
リストを渡すことで、複数の値を置き換えることができます。
df00 = df.iloc[0, 0]
df.replace([1.5, df00], [np.nan, "a"])
# 0 1
# 0 a -1.021415
# 1 0.432396 -0.323580
# 2 0.423825 0.799180
# 3 1.262614 0.751965
# 4 NaN NaN
# 5 NaN NaN
# 6 -0.498174 -1.060799
# 7 0.591667 -0.183257
# 8 1.019855 -1.482465
# 9 NaN NaN
df[1].dtype
# dtype('float64')
データフレームをインプレース処理することもできます。
df.replace(1.5, np.nan, inplace=True)
欠損データのキャストルールとインデクシング
pandasは整数型とブール型の配列の格納をサポートしていますが、これらの型は欠損データを格納することができません。NumPyでネイティブNA型の使用に切り替えられるまでは、いくつかの「キャストルール」を確立しています。再インデックス化操作で欠損データが発生した場合、以下の表で紹介したルールに従ってシリーズがキャストされます。
| データ型 | キャスト先 |
|---|---|
| 整数 | 浮動小数 |
| 真偽値 | オブジェクト |
| 浮動小数 | キャストしない |
| オブジェクト | キャストしない |
例えば、
s = pd.Series(np.random.randn(5), index=[0, 2, 4, 6, 7])
s > 0
# 0 True
# 2 True
# 4 True
# 6 True
# 7 True
# dtype: bool
(s > 0).dtype
# dtype('bool')
crit = (s > 0).reindex(list(range(8)))
crit
# 0 True
# 1 NaN
# 2 True
# 3 NaN
# 4 True
# 5 NaN
# 6 True
# 7 True
# dtype: object
crit.dtype
# dtype('O')
通常、NumPyは、真偽値配列の代わりにオブジェクト配列を使用してndarrayから値を取得または設定しようとすると(たとえば、いくつかの基準に基づいて値を選択する)、文句を言います。真偽値ベクトルにNAが含まれている場合、例外が発生します。
reindexed = s.reindex(list(range(8))).fillna(0)
reindexed[crit]
# ---------------------------------------------------------------------------
# ValueError Traceback (most recent call last)
# Input In [136], in <module>
# ----> 1 reindexed[crit]
#
# File /pandas/pandas/core/series.py:979, in Series.__getitem__(self, key)
# 976 if is_iterator(key):
# 977 key = list(key)
# --> 979 if com.is_bool_indexer(key):
# 980 key = check_bool_indexer(self.index, key)
# 981 key = np.asarray(key, dtype=bool)
#
# File /pandas/pandas/core/common.py:144, in is_bool_indexer(key)
# 140 na_msg = "Cannot mask with non-boolean array containing NA / NaN values"
# 141 if lib.infer_dtype(key) == "boolean" and isna(key).any():
# 142 # Don't raise on e.g. ["A", "B", np.nan], see
# 143 # test_loc_getitem_list_of_labels_categoricalindex_with_na
# --> 144 raise ValueError(na_msg)
# 145 return False
# 146 return True
#
# ValueError: Cannot mask with non-boolean array containing NA / NaN values
ただし、これらはfillna()を使用して穴埋めすれば正常に動作します。
reindexed[crit.fillna(False)]
# 0 0.126504
# 2 0.696198
# 4 0.697416
# 6 0.601516
# 7 0.003659
# dtype: float64
reindexed[crit.fillna(True)]
# 0 0.126504
# 1 0.000000
# 2 0.696198
# 3 0.000000
# 4 0.697416
# 5 0.000000
# 6 0.601516
# 7 0.003659
# dtype: float64
pandasは欠損値を持つことができる整数データ型を提供していますが、シリーズや列を作成する際に明示的に指定する必要があります。dtype="Int64"で大文字の「I」を使用していることに注意してください。
s = pd.Series([0, 1, np.nan, 3, 4], dtype="Int64")
s
# 0 0
# 1 1
# 2 <NA>
# 3 3
# 4 4
# dtype: Int64
詳しくは欠損可能整数データ型を参照してください。
欠損値を示すための試験的なNAスカラー
試験運用:pd.NAの動作は警告なしに変更される可能性があります。
バージョン1.0.0で追加
pandas 1.0 から、スカラー欠損値を表現するための試験的な値pd.NA(シングルトン)が利用可能になりました。現時点では、nullable integer、boolean、および専用の文字列データ型で、欠損値インジケータとして使用されています。
pandas 1.0 から、実験的なpd.NA値(シングルトン)を使用して、スカラー欠損値を表すことができます。現時点では、欠損可能整数、ブーリアン、および専用の文字列データ型で欠損値インジケーターとして使用されています。
pd.NAの目的は、(データタイプに応じたnp.nan・None・pd.NaTの代わりに)データ型間で一貫して使用できる「欠損」値を提供することです。
たとえば、欠損可能整数データ型のシリーズに欠損値がある場合、pd.NAが使用されます。
s = pd.Series([1, 2, None], dtype="Int64")
s
# 0 1
# 1 2
# 2 <NA>
# dtype: Int64
s[2]
# <NA>
s[2] is pd.NA
# True
現在のところ、(データフレームやシリーズを作成するときやデータを読み込むとき)pandasはこれらのデータ型をまだデフォルトでは使用していませんので、明示的にデータ型を指定する必要があります。これらのデータ型に変換する簡単な方法をここで説明しています。
算術演算および比較演算での伝播
一般的に、pd.NAを含む演算では、欠損値が伝播します。オペランドの1つが不明な場合、演算の結果も不明です。
例えば、pd.NAはnp.nanと同様に算術演算で伝搬します。
pd.NA + 1
# <NA>
"a" * pd.NA
# <NA>
オペランドの片方がNAであっても、結果がわかっている場合には、いくつかの特殊なケースがあります。
pd.NA ** 0
# 1
1 ** pd.NA
# 1
等値演算と比較演算では、pd.NAも伝播します。これは、比較結果が常にFalseとなるnp.nanの挙動とは異なります。
pd.NA == 1
# <NA>
pd.NA == pd.NA
# <NA>
pd.NA < 2.5
# <NA>
値がpd.NAと等しいかどうかを調べるには、isna()関数を使用します。
pd.isna(pd.NA)
# True
この基本的な伝播ルールの例外は、(平均や最小値のような)削減で、pandasはデフォルトで欠損値をスキップします。詳細は上記を参照してください。
論理演算
論理演算については、pd.NAは3値論理(クリーネの論理とも呼び、R・SQL・Juliaと同様の挙動)のルールに従います。この論理は、論理的に必要な場合にのみ欠落した値を伝播することを意味します。
例えば、論理演算「or」(|)の場合、オペランドの片方がTrueであれば、他の値に関係なく(つまり欠損値がTrueであってもFalseであっても)、結果はTrueになることがすでにわかっています。この場合、pd.NAは伝播しません。
True | False
# True
True | pd.NA
# True
pd.NA | True
# True
一方、オペランドの片方がFalseの場合、結果は他方のオペランドの値に依存します。したがって、この場合は、pd.NAが伝播します。
False | True
# True
False | False
# False
False | pd.NA
# <NA>
論理演算「and」(&)の動作も、同様のロジックを使用して導出することができます(この場合、オペランドの1つが既にFalseである場合には、pd.NAは伝搬しません)。
False & True
# False
False & False
# False
False & pd.NA
# False
True & True
# True
True & False
# False
True & pd.NA
# <NA>
ブーリアンコンテキストでのNA
欠損値は実際の値が不明なので、欠損値をブール値に変換することはできません。以下はエラーになります。
bool(pd.NA)
# ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# Input In [165], in <module>
# ----> 1 bool(pd.NA)
#
# File /pandas/pandas/_libs/missing.pyx:382, in pandas._libs.missing.NAType.__bool__()
#
# TypeError: boolean value of NA is ambiguous
これはまた、pd.NAがブール値で評価されるコンテキスト、例えばif condition: ...においてconditionがpd.NAになる可能性がある場合には、pd.NAは使用できないことを意味します。このような場合にはisna()を使用してpd.NAをチェックしたり、条件がpd.NAであることを避けるために、例えば欠落している値を事前に埋めておくことができます。
同様の状況は、if文でシリーズやデータフレームオブジェクトを使用する場合にも発生します。pandasでif/Truth文を使うを参照してください。
NumPy ufunc
pandas.NAはNumPyの__array_ufunc__プロトコルを実装しています。ほとんどのufuncはNAに対して動作し、一般的にはNAを返します。
np.log(pd.NA)
# <NA>
np.add(pd.NA, 1)
# <NA>
現在のところ、ndarrayとNAを含むufuncは欠損値で埋められたオブジェクトデータ型を返します。
a = np.array([1, 2, 3])
np.greater(a, pd.NA)
# array([<NA>, <NA>, <NA>], dtype=object)
ここでの戻り値の型は、将来的には別の配列型を返すように変更される可能性があります。
ufuncの詳細については、DataFrameとNumPy関数の相互運用性を参照してください。
変換
伝統的な型を使用しているデータフレームやシリーズがあり、np.nanを使用して表現されていないデータがある場合、シリーズにはconvert_dtypes()が、データフレームにはconvert_dtypes()があり、ここにリストされている整数、文字列、ブーリアンの新しいデータ型を使用するようにデータを変換することができます。これは、データセットを読み込んだ後にread_csv()やread_excel()などのリーダーにデフォルトのデータ型を推測させる場合に特に便利です。
この例では、すべての列のデータ型が変更されていますが、最初の10列の結果を示しています。
bb = pd.read_csv("data/baseball.csv", index_col="id")
bb[bb.columns[:10]].dtypes
# player object
# year int64
# stint int64
# team object
# lg object
# g int64
# ab int64
# r int64
# h int64
# X2b int64
# dtype: object
bbn = bb.convert_dtypes()
bbn[bbn.columns[:10]].dtypes
# player string
# year Int64
# stint Int64
# team string
# lg string
# g Int64
# ab Int64
# r Int64
# h Int64
# X2b Int64
# dtype: object