本記事は、Pandas の公式ドキュメントのUser Guide - Merge, join, and concatenateを機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
mergeとjoin,concatenate,compare
pandasは、SeriesまたはDataFrameを簡単に結合するための、join・merge系操作におけるインデックスおよびリレーショナル代数機能のさまざまな種類の集合演算とさまざまな機能を提供します。
さらに、pandasは2つのSeriesまたはDataFrameを比較し、それらの違いを要約するユーティリティも提供します。
オブジェクトの結合
concat()関数(メインのpandas名前空間に存在します)は、他の軸(もしあれば)のインデックスに任意の集合演算(unionやintersection)を実行しながら、軸に沿って連結操作を実行するという面倒な作業をすべて行います。なお「もしあれば」と書いたのは、Seriesには連結の軸が1つしかないためです。
concatの詳細とそれが何ができるかを詳しく説明する前に、以下に簡単な例を示します。
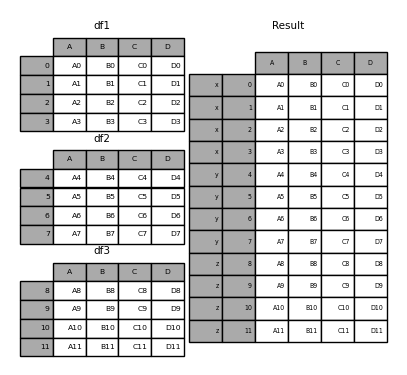
df1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3],
)
df2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7],
)
df3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11],
)
frames = [df1, df2, df3]
result = pd.concat(frames)
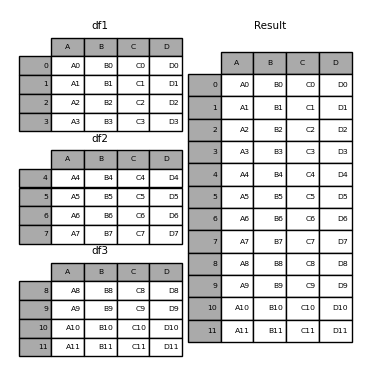
ndarrayにおける兄弟的な関数であるnumpy.concatenateと同様に、pandas.concatは同種のオブジェクトのリストまたは辞書を取り、いくつかの設定可能な「他の軸をどうするか」に関する処理とともに、それらを連結します。
pd.concat(
objs,
axis=0,
join="outer",
ignore_index=False,
keys=None,
levels=None,
names=None,
verify_integrity=False,
copy=True,
)
-
objs:SeriesまたはDataFrameオブジェクトのシーケンスまたはマッピング。辞書が渡された場合、ソートされたキーはkeys引数として使用されます。そうでない場合、値が選択されます(後述)。 Noneオブジェクトは暗黙的に除外されます。全てNoneの場合はValueErrorが発生します。 -
axis:{0, 1, …}、デフォルトは0。連結する軸を指定します。 -
join:{‘inner’, ‘outer’}、デフォルトは‘outer’。他の軸のインデックスを処理する方法。outerは和(union)、innerは共通部分(intersection)。 -
ignore_index:真偽値、デフォルトはFalse。Trueの場合、連結軸におけるインデックスの値を使用しません。結果の軸には 0,…,n - 1 というラベルが付けられます。これは、連結軸に意味のあるインデックス情報がないオブジェクトを連結する場合に便利です。他の軸のインデックスの値は結合で引き続き考慮されることに注意してください。 -
keys:シーケンス、デフォルトはNone。渡されたキーを最も外側のレベルとして使用して、階層的インデックスを構築します。複数のレベルが渡された場合、タプルを含める必要があります。 -
levels:シーケンスのリスト、デフォルトはNone。MultiIndexの構築に使用する特定のレベル(一意の値)。Noneの場合は、keysから推測されます。 -
names:リスト、デフォルトはNone。結果の階層的インデックスのレベルの名前。 -
verify_integrity:真偽値、デフォルトはFalse。新しい連結軸に重複が含まれているかどうかを確認します。これは、実際のデータ連結に比べて非常に高価になる場合があります。 -
copy:ブール値、デフォルトはTrue。Falseの場合、データを不必要にコピーしません。
多少の説明がないと、これらの引数のほとんどはよく意味がわからないかもしれません。上の例をもう一度見てみましょう。特定のキーを、結合前のDataFrameの各部分に関連付けたいとします。keys引数を使用してこれを行うことができます。
result = pd.concat(frames, keys=["x", "y", "z"])
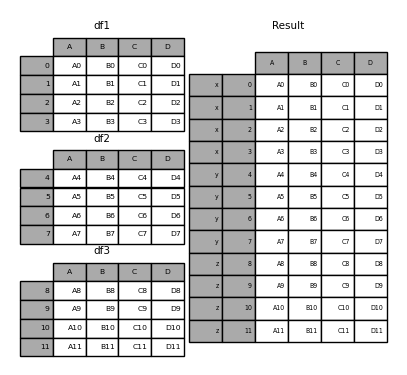
(あなたがドキュメントの残りの部分を読んだなら)これを見てわかるように、結果のオブジェクトのインデックスには階層的インデックスがあります。これは、キーによって各チャンクを選択できることを意味します。
result.loc["y"]
# A B C D
# 4 A4 B4 C4 D4
# 5 A5 B5 C5 D5
# 6 A6 B6 C6 D6
# 7 A7 B7 C7 D7
これがどれほど役立つかを見るのは難しいことではありません。この機能の詳細については、以下をご覧ください。
concat()(したがってappend()も)はデータの完全なコピーを作成し、この関数を絶えず再利用するとパフォーマンスが大幅に低下することに注意してください。複数のデータセットで操作を使用する必要がある場合は、リスト内包表記を使用します。
frames = [ process_your_file(f) for f in files ]
result = pd.concat(frames)
名前(name属性)付き軸を持つデータフレーム同士を連結する場合、pandasは可能な限りこれらのインデックス/カラムの名前を保持しようとします。すべての入力が共通の名前を持つ場合、この名前が結果に割り当てられます。入力の名前がすべて一致しない場合、結果は無名(None)になります。MultiIndexについても同じことが言えますが、この動作はレベルごとに別々に適用されます。
他の軸に対する集合演算
複数のDataFrameを結合する場合、(連結される軸以外の)他の軸の処理方法を選択できます。これは、次の2つの方法で実行できます。
- すべて結合する場合(和,union)は、
join='outer'にします。これは、情報損失がゼロになるため、デフォルトのオプションです。 - 共通部分をとる場合(交差,intersection)は、
join='inner'にします。
これらの各メソッドの例を次に示します。まず、デフォルトのjoin='outer'のときの動作は、
df4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},
index=[2, 3, 6, 7],
)
result = pd.concat([df1, df4], axis=1)
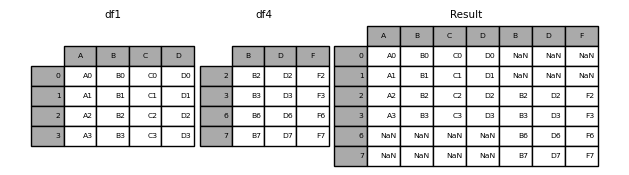
同じことをjoin='inner'で行うと、
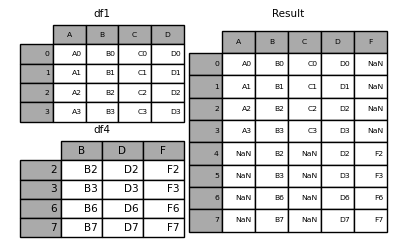
result = pd.concat([df1, df4], axis=1, join="inner")

最後に、元のDataFrameの正確なインデックスを再利用したいとします。
result = pd.concat([df1, df4], axis=1).reindex(df1.index)
同様に、結合する前にインデックスを作成できます。
pd.concat([df1, df4.reindex(df1.index)], axis=1)
# A B C D B D F
# 0 A0 B0 C0 D0 NaN NaN NaN
# 1 A1 B1 C1 D1 NaN NaN NaN
# 2 A2 B2 C2 D2 B2 D2 F2
# 3 A3 B3 C3 D3 B3 D3 F3

連結軸のインデックスを無視する
インデックスが意味を持たないDataFrameオブジェクトの場合、それらを結合するときに、インデックスが重複していたとしても無視してほしいと思うことがあるかもしれません。これを行うには、ignore_index引数を使用します。
result = pd.concat([df1, df4], ignore_index=True, sort=False)
次元数の異なるデータの結合
SeriesオブジェクトとDataFrameオブジェクトを混在させて結合することもできます。Seriesは、その名前(name属性)を列名とするDataFrameに変換されます。
s1 = pd.Series(["X0", "X1", "X2", "X3"], name="X")
result = pd.concat([df1, s1], axis=1)
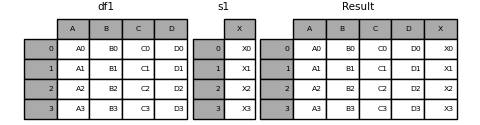
DataFrameにSeriesを結合したので、DataFrame.assign()と同じ結果を得ることができました。任意の数のpandasオブジェクト(DataFrameまたはSeries)を連結するには、concatを使用します。
名前のないSeriesが渡された場合は、連番が列名に付けられます。
s2 = pd.Series(["_0", "_1", "_2", "_3"])
result = pd.concat([df1, s2, s2, s2], axis=1)
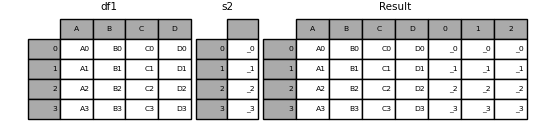
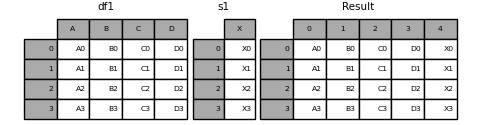
ignore_index=Trueを渡すと、すべての名前参照が削除されます。
result = pd.concat([df1, s1], axis=1, ignore_index=True)
グループキーを用いたさらなる結合
keys引数は、既存のSeriesから新しいDataFrameを作成するときに、列名を新しく上書きするときによく使われます。デフォルトの動作では、もとのSeriesに名前が存在していれば、結果のDataFrameはそれを継承します。
s3 = pd.Series([0, 1, 2, 3], name="foo")
s4 = pd.Series([0, 1, 2, 3])
s5 = pd.Series([0, 1, 4, 5])
pd.concat([s3, s4, s5], axis=1)
# foo 0 1
# 0 0 0 0
# 1 1 1 1
# 2 2 2 4
# 3 3 3 5
keys引数を使用することで、既存の列名を新しく上書きできます。
pd.concat([s3, s4, s5], axis=1, keys=["red", "blue", "yellow"])
# red blue yellow
# 0 0 0 0
# 1 1 1 1
# 2 2 2 4
# 3 3 3 5
一番最初にあげた例のバリエーションを考えてみましょう。
result = pd.concat(frames, keys=["x", "y", "z"])
辞書をconcatに渡すこともできます。このとき、(他にキーが指定されていない場合は)辞書のキーがkeys引数に使用されます。
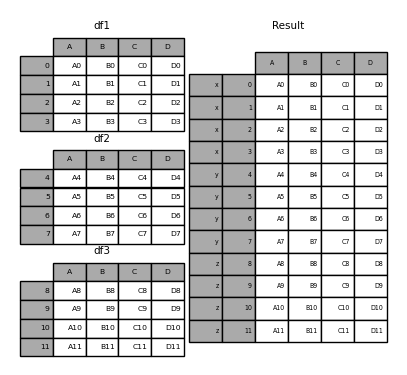
pieces = {"x": df1, "y": df2, "z": df3}
result = pd.concat(pieces)
result = pd.concat(pieces, keys=["z", "y"])
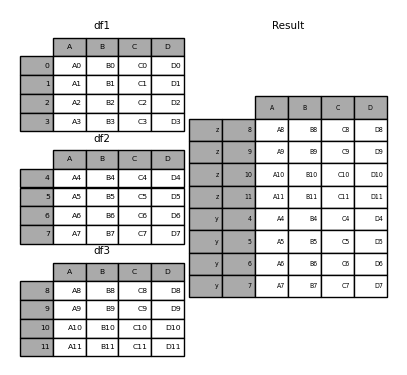
作成されたMultiIndexは、渡されたキーとDataFrameピースのインデックスから構成されるレベルを持ちます。
result.index.levels
# FrozenList([['z', 'y'], [4, 5, 6, 7, 8, 9, 10, 11]])
他のレベルを指定する場合(場合によってはそうすることがあります)、levels引数を使用して指定できます。
result = pd.concat(
pieces, keys=["x", "y", "z"], levels=[["z", "y", "x", "w"]], names=["group_key"]
)
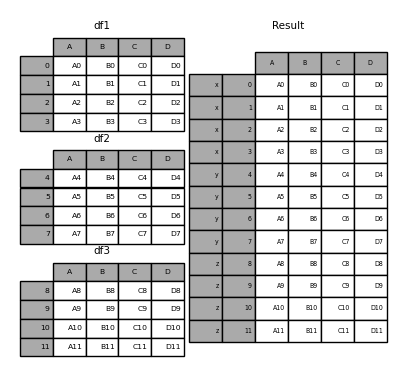
result.index.levels
# FrozenList([['z', 'y', 'x', 'w'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]])
これはかなり難解ですが、実際には、カテゴリ変数の順序が意味のあるGroupByなどの実装に必要です。
DataFrameの行の追加
DataFrameに1行追加したいシリーズがある場合、行をDataFrameに変換して、concatを使用します。
s2 = pd.Series(["X0", "X1", "X2", "X3"], index=["A", "B", "C", "D"])
result = pd.concat([df1, s2.to_frame().T], ignore_index=True)
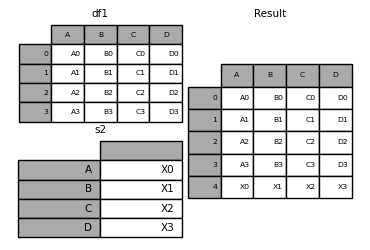
このメソッドで、DataFrameの元のインデックスを破棄したい場合は、ignore_indexを使用してください。インデックスを保持したい場合は、適切にインデックス付けされたDataFrameを構築し、それらのオブジェクトを連結・結合してください。
データベーススタイルのDataFrameまたは名前付きSeriesのjoin/merge
pandasには、SQLなどのリレーショナルデータベースに非常によく似た、フル機能の高性能なメモリ内結合操作があります。これらのメソッドは、他のオープンソース実装(Rのbase::merge.data.frameなど)よりも大幅に優れています(場合によっては1桁以上も優れています)。この理由は、慎重なアルゴリズム設計とDataFrameのデータの内部レイアウトです。
より応用的な操作については、cook bookもご覧ください。
SQLには慣れているが、pandasは初めてだというユーザーは、SQLとの比較が役立つかもしれません。
pandasは、DataFrameまたは名前付きSeriesオブジェクト間のすべての標準データベース結合操作のエントリポイントとして、単一の関数merge()を提供します。
pd.merge(
left,
right,
how="inner",
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=True,
suffixes=("_x", "_y"),
copy=True,
indicator=False,
validate=None,
)
-
left:DataFrameまたは名前付きSeriesオブジェクト。 -
right:別のDataFrameまたは名前付きSeriesオブジェクト。 -
on:結合する列または行レベルの名前。左右のDataFrameまたはSeriesオブジェクトの両方に存在しなければなりません。これを指定せず、left_indexとright_indexがFalseの場合は、DataFrameまたはSeriesの列の共通部分が結合キーであると推測されます。 -
left_on:キーとして使用する左側のDataFrameまたはSeriesの列または行レベル。列名か行レベル名、あるいはDataFrameやSeriesの長さ(len)と等しい長さの配列のいずれかを受け取ることができます。 -
right_on:キーとして使用する左側のDataFrameまたはSeriesの列または行レベル。列名か行レベル名、あるいはDataFrameやSeriesの長さ(len)と等しい長さの配列のいずれかを受け取ることができます。 -
left_index:Trueの場合、左側のDataFrameまたはSeriesのindex(行ラベル)を結合キーとして使用します。MultiIndex(階層)を持つDataFrameまたはSeriesの場合、レベルの数は、右側のDataFrameまたはSeriesからの結合キーの数と一致する必要があります。 -
right_index:右側のDataFrameまたはSeriesに対する、left_indexと同様の指定。 -
how:'left'・'right'・'outer'・'inner'・'cross'のいずれか。デフォルトは'inner'。各方法の詳細については、下で述べます。 -
sort:結果のDataFrameを結合キーで辞書式に並べ替えます。デフォルトはTrueで、Falseに設定すると、多くの場合、パフォーマンスが大幅に向上します。 -
suffixes:重複する列に適用する接頭辞のタプル。デフォルトは('_x', '_y')。 -
copy:(デフォルトのTrueの場合)インデックスの再作成が不要な場合でも、渡されたDataFrameまたは名前付きSeriesオブジェクトから常にデータをコピーします。多くの場合、コピーを回避することはできませんが、パフォーマンス・メモリ使用量が改善される可能性があります。コピーを避けることができるケースは稀ですが、それでもこのオプションは提供されています。 -
indicator:出力DataFrameに、各行のソースに関する情報を記した列を_mergeという名前で追加します。_mergeはCategorical型で、マージキーが'left'のDataFrameまたはSeriesにのみ存在する場合はleft_only、rightのDataFrameまたはSeriesにのみ存在する場合はright_only、両方に存在する場合はbothの値を取ります。 -
validate:文字列、デフォルトはNone。指定されている場合、マージが指定されたタイプであるかどうかを確認します。- “one_to_one”または“1:1”:マージキーが左右のデータセットの両方で一意であるかどうかを確認します。
- “one_to_many”または“1:m”:マージキーが左側のデータセットで一意であるかどうかを確認します。
- “many_to_one”または“m:1”:マージキーが右側のデータセットで一意であるかどうかを確認します。
- “many_to_many”または“m:m”:引数を受け取りますが、確認は行われません。
on・left_on・right_on引数を用いて行レベルを指定するサポートは、バージョン0.23.0で追加されました。名前付きSeriesオブジェクトのmergeのサポートは、バージョン0.24.0で追加されました。
戻り値の型はleftと同じです。leftがDataFrameまたは名前付きSeriesで、rightがDataFrameのサブクラスである場合、戻り値の型は引き続きDataFrameになります。
mergeはpandas名前空間の関数ですが、DataFrameインスタンスメソッドmerge()も使用できます。呼び出し側のDataFrameは、結合の左側のオブジェクトと暗黙的に見なされます。
関連するjoin()メソッドは、index-on-index(デフォルト)およびcolumn-on-index結合に内部的にmergeを使用します。indexのみで結合する場合は、DataFrame.joinを使用して入力を簡略化できます。
merge メソッド(リレーショナル代数)の概略
SQLのようなリレーショナルデータベースの経験が豊富なユーザーは、2つのSQLテーブルのような構造(DataFrameオブジェクト)間の結合操作を説明するための用語に精通しています。いくつかのケースを考慮する必要があり、理解することが非常に重要です。
-
one-to-one 結合:たとえば、(一意の値を含む)インデックスに従って2つの
DataFrameオブジェクトを結合する場合。 - many-to-one 結合:たとえば、インデックス(一意)を異なるDataFrameの1つ以上の列に結合する場合。
- many-to-many 結合:列に列を結合する場合。
(many-to-many 結合のように)列と列を結合する場合、渡されたDataFrameオブジェクトのインデックスは全て破棄されます。
many-to-many 結合の結果を理解するのには時間をかける価値があります。SQLや標準のリレーショナル代数では、キーの組み合わせが両方のテーブルに複数回出現する場合、結果のテーブルには関連データのデカルト積が含まれます。以下は、1つの一意のキーの組み合わせを使用した非常に基本的な例です。
left = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
result = pd.merge(left, right, on="key")
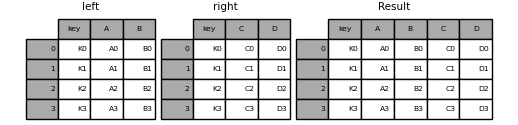
以下は、複数の結合キーを使用したより複雑な例です。既定ではhow='inner'であるため、左右に共通して存在するキーのみが結果に現れます(交差 intersection)。
left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
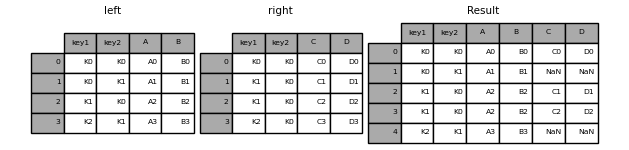
result = pd.merge(left, right, on=["key1", "key2"])

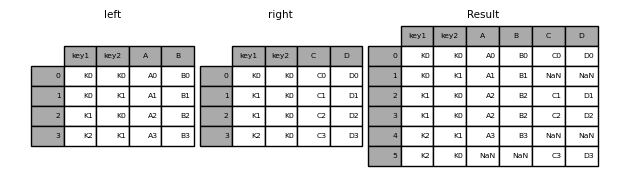
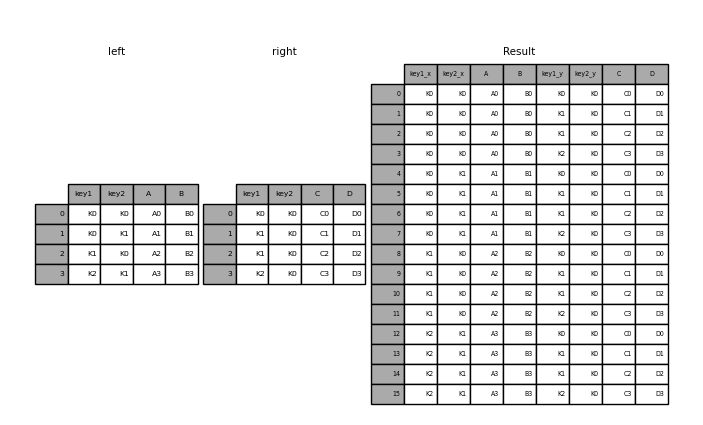
mergeのhow引数は、どのキーを結果のテーブルに含めるかを決定する方法を指定します。キーの組み合わせが左右どちらのテーブルにも存在しない場合、結合されたテーブルの値はNAになります。howオプションとそれに対応するSQLの名前の概要は以下のとおりです。
| merge メソッド | SQL JOIN の名前 | 動作 |
|---|---|---|
left |
LEFT OUTER JOIN |
左側のキーのみを使用 |
right |
RIGHT OUTER JOIN |
右側のキーのみを使用 |
outer |
FULL OUTER JOIN |
両方のキーの和を使用 |
inner |
INNER JOIN |
両方のキーの共通部分を使用 |
cross |
CROSS JOIN |
両フレームの行のデカルト積を作成 |
result = pd.merge(left, right, how="left", on=["key1", "key2"])
result = pd.merge(left, right, how="right", on=["key1", "key2"])

result = pd.merge(left, right, how="outer", on=["key1", "key2"])
result = pd.merge(left, right, how="inner", on=["key1", "key2"])

result = pd.merge(left, right, how="cross")
マルチインデックスの名前(name属性)がDataFrameの列のそれと一致している場合、マルチインデックスのSeriesとDataFrameをマージできます。次の例に示すように、マージする前にSeries.reset_index()を使用してSeriesをDataFrameに変換します。
df = pd.DataFrame({"Let": ["A", "B", "C"], "Num": [1, 2, 3]})
df
# Let Num
# 0 A 1
# 1 B 2
# 2 C 3
ser = pd.Series(
["a", "b", "c", "d", "e", "f"],
index=pd.MultiIndex.from_arrays(
[["A", "B", "C"] * 2, [1, 2, 3, 4, 5, 6]], names=["Let", "Num"]
),
)
ser
# Let Num
# A 1 a
# B 2 b
# C 3 c
# A 4 d
# B 5 e
# C 6 f
# dtype: object
pd.merge(df, ser.reset_index(), on=["Let", "Num"])
# Let Num 0
# 0 A 1 a
# 1 B 2 b
# 2 C 3 c
以下は、DataFrameに重複する結合キーがあるもう一つの例です。
left = pd.DataFrame({"A": [1, 2], "B": [2, 2]})
right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
result = pd.merge(left, right, on="B", how="outer")
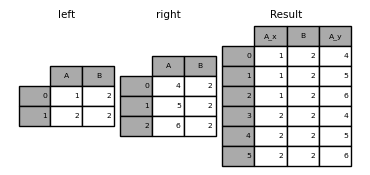
重複したキーによるjoin/mergeは、行の次元の乗算のフレームを返す場合があり、メモリオーバーフローを引き起こす可能性があります。大きなDataFrameをjoinさせる前に、ユーザーはキーの重複を管理しなければなりません。
重複キーの確認
ユーザーはvalidate引数を使用して、マージキーに予期しない重複があるかどうかを自動的に確認できます。キーの一意性は結合操作の前にチェックされるため、メモリオーバーフローを防ぐことでしょう。キーの一意性を確認することも、ユーザーデータ構造が期待どおりであることを確認するための良い方法です。
次の例では、右側のDataFrameのBの値が重複しています。これは、validate引数で指定された one-to-oneのマージではないため、例外が発生します。
left = pd.DataFrame({"A": [1, 2], "B": [1, 2]})
right = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})
result = pd.merge(left, right, on="B", how="outer", validate="one_to_one")
# ...
# MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
右側のDataFrameに重複があることを既に知った上で、左側のDataFrameに重複がないことを確認したい場合は、validate='one_to_many'引数を代わりに使用できます。これは例外を発生させません。
pd.merge(left, right, on="B", how="outer", validate="one_to_many")
# A_x B A_y
# 0 1 1 NaN
# 1 2 2 4.0
# 2 2 2 5.0
# 3 2 2 6.0
mergeのindicator
merge()はindicator引数を受け取ります。Trueの場合、以下のいずれかの値からなる_mergeというCategorical型の列が、出力オブジェクトに追加されます。
| 観測原点 |
_mergeの値 |
|---|---|
結合キーがleftフレームにのみ存在 |
left_only |
結合キーがrightフレームにのみ存在 |
right_only |
| 結合キーが両方のフレームに存在 | both |
df1 = pd.DataFrame({"col1": [0, 1], "col_left": ["a", "b"]})
df2 = pd.DataFrame({"col1": [1, 2, 2], "col_right": [2, 2, 2]})
pd.merge(df1, df2, on="col1", how="outer", indicator=True)
# col1 col_left col_right _merge
# 0 0 a NaN left_only
# 1 1 b 2.0 both
# 2 2 NaN 2.0 right_only
# 3 2 NaN 2.0 right_only
indicator引数は、文字列を受け取ることもできます。この場合、indicator関数は渡された文字列の値をインジケータ列の名前として使用します。
pd.merge(df1, df2, on="col1", how="outer", indicator="indicator_column")
# col1 col_left col_right indicator_column
# 0 0 a NaN left_only
# 1 1 b 2.0 both
# 2 2 NaN 2.0 right_only
# 3 2 NaN 2.0 right_only
merge のデータ型
mergeは、結合キーのデータ型を保持します。
left = pd.DataFrame({"key": [1], "v1": [10]})
left
# key v1
# 0 1 10
right = pd.DataFrame({"key": [1, 2], "v1": [20, 30]})
right
# key v1
# 0 1 20
# 1 2 30
結合キーを保持できます。
pd.merge(left, right, how="outer")
# key v1
# 0 1 10
# 1 1 20
# 2 2 30
pd.merge(left, right, how="outer").dtypes
# key int64
# v1 int64
# dtype: object
もちろん、欠損値がある場合は、結果のデータ型はアップキャストされます。
pd.merge(left, right, how="outer", on="key")
# key v1_x v1_y
# 0 1 10.0 20
# 1 2 NaN 30
pd.merge(left, right, how="outer", on="key").dtypes
# key int64
# v1_x float64
# v1_y int64
# dtype: object
mergeは、元のcategoryデータ型を保持します。カテゴリに関するセクションも参照してください。
左のフレーム。
from pandas.api.types import CategoricalDtype
X = pd.Series(np.random.choice(["foo", "bar"], size=(10,)))
X = X.astype(CategoricalDtype(categories=["foo", "bar"]))
left = pd.DataFrame(
{"X": X, "Y": np.random.choice(["one", "two", "three"], size=(10,))}
)
left
# X Y
# 0 bar one
# 1 foo one
# 2 foo three
# 3 bar three
# 4 foo one
# 5 bar one
# 6 bar three
# 7 bar three
# 8 bar three
# 9 foo three
left.dtypes
# X category
# Y object
# dtype: object
右のフレーム。
right = pd.DataFrame(
{
"X": pd.Series(["foo", "bar"], dtype=CategoricalDtype(["foo", "bar"])),
"Z": [1, 2],
}
)
right
# X Z
# 0 foo 1
# 1 bar 2
right.dtypes
# X category
# Z int64
# dtype: object
結合した結果。
result = pd.merge(left, right, how="outer")
result
# X Y Z
# 0 bar one 2
# 1 bar three 2
# 2 bar one 2
# 3 bar three 2
# 4 bar three 2
# 5 bar three 2
# 6 foo one 1
# 7 foo three 1
# 8 foo one 1
# 9 foo three 1
result.dtypes
# X category
# Y object
# Z int64
# dtype: object
カテゴリ型は、同じカテゴリと順序属性を持ち、完全に同じでなければなりません。それ以外の場合、結果はカテゴリの要素のデータ型に上書きされます。
同じcategoryデータ型の結合は、objectデータ型のマージと比較して非常にパフォーマンスが高い場合があります。
インデックスに従う結合(join)
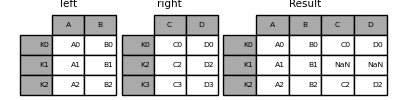
DataFrame.join()は、インデックスが異なる可能性のある2つのDataFrameの列を、一つのDataFrameに結合するための便利なメソッドです。次の例は非常に基本的な例です。
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
)
right = pd.DataFrame(
{"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
)
result = left.join(right)
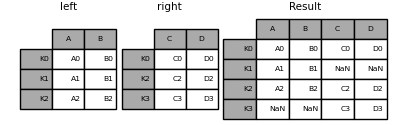
result = left.join(right, how="outer")
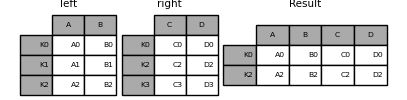
上記と同様にして、how='inner'を使用すると、
result = left.join(right, how="inner")
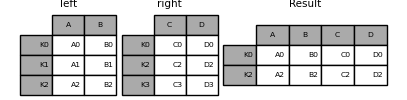
ここでのデータの整列は、インデックス(行ラベル)に基づいています。mergeでこれと同じ動作を実行するには、インデックスを使用するように指示する追加の引数を渡します。
result = pd.merge(left, right, left_index=True, right_index=True, how="outer")
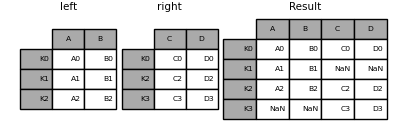
result = pd.merge(left, right, left_index=True, right_index=True, how="inner")
キー列のindexへの結合
join()はオプションのon引数で、列または複数の列名を受け取ります。渡されたDataFrameは、DataFrame内のその列に沿って結合されます。以下の2つの関数呼び出しは完全に同等です。
left.join(right, on=key_or_keys)
pd.merge(
left, right, left_on=key_or_keys, right_index=True, how="left", sort=False
)
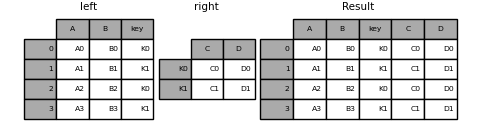
もちろん、ユーザーはより便利な形式を選択できます。many-to-one結合(DataFrameの1つが既に結合キーによってインデックス付けされている場合)では、joinを使用する方が便利でしょう。以下に簡単な例を示します。
left = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"key": ["K0", "K1", "K0", "K1"],
}
)
right = pd.DataFrame({"C": ["C0", "C1"], "D": ["D0", "D1"]}, index=["K0", "K1"])
result = left.join(right, on="key")
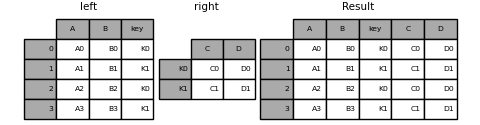
result = pd.merge(
left, right, left_on="key", right_index=True, how="left", sort=False
)
複数のキーで結合するには、渡されたDataFrameにMultiIndexが必要です。
left = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
}
)
index = pd.MultiIndex.from_tuples(
[("K0", "K0"), ("K1", "K0"), ("K2", "K0"), ("K2", "K1")]
)
right = pd.DataFrame(
{"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=index
)
これは、2つのキー列名を渡すことで結合できます。
result = left.join(right, on=["key1", "key2"])
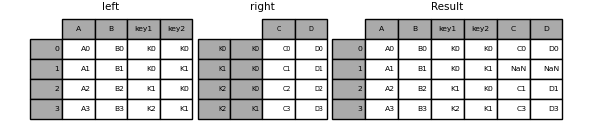
DataFrame.joinのデフォルトは、呼び出し側のDataFrameで見つかったキーのみを使用する左結合(簡潔に言えばExcelユーザーにとっての「VLOOKUP」操作)を実行することです。他の結合タイプ、たとえば内部結合も同様に簡単に実行できます。
result = left.join(right, on=["key1", "key2"], how="inner")
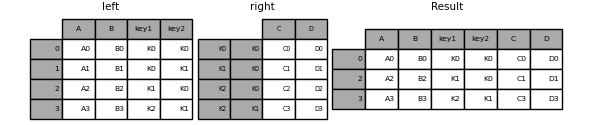
上のように、これは一致しなかった行は削除されます。
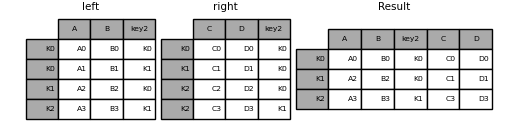
単一インデックスのマルチインデックスへの結合
単一インデックスのDataFrameをMultiIndexをもつDataFrameのレベルに結合できます。MultiIndexを持つフレームのレベル名において、レベルは単一インデックスのフレームのインデックスの名前と一致します。
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]},
index=pd.Index(["K0", "K1", "K2"], name="key"),
)
index = pd.MultiIndex.from_tuples(
[("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")],
names=["key", "Y"],
)
right = pd.DataFrame(
{"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]},
index=index,
)
result = left.join(right, how="inner")
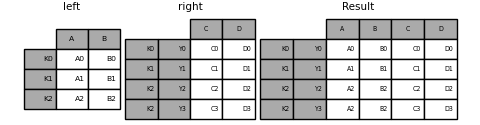
次の例は同等ですが、冗長性が低く、これよりもメモリ効率が良く高速です。
result = pd.merge(
left.reset_index(), right.reset_index(), on=["key"], how="inner"
).set_index(["key","Y"])
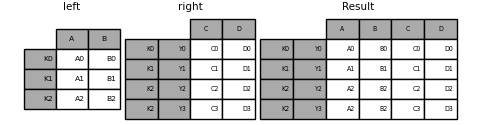
2つのマルチインデックスの結合
この方法が使えるのは、次の例のように、右引数のインデックスが結合で完全に使用され、左引数のインデックスのサブセットである場合のみです。
leftindex = pd.MultiIndex.from_product(
[list("abc"), list("xy"), [1, 2]], names=["abc", "xy", "num"]
)
left = pd.DataFrame({"v1": range(12)}, index=leftindex)
left
# v1
# abc xy num
# a x 1 0
# 2 1
# y 1 2
# 2 3
# b x 1 4
# 2 5
# y 1 6
# 2 7
# c x 1 8
# 2 9
# y 1 10
# 2 11
rightindex = pd.MultiIndex.from_product(
[list("abc"), list("xy")], names=["abc", "xy"]
)
right = pd.DataFrame({"v2": [100 * i for i in range(1, 7)]}, index=rightindex)
right
# v2
# abc xy
# a x 100
# y 200
# b x 300
# y 400
# c x 500
# y 600
left.join(right, on=["abc", "xy"], how="inner")
# v1 v2
# abc xy num
# a x 1 0 100
# 2 1 100
# y 1 2 200
# 2 3 200
# b x 1 4 300
# 2 5 300
# y 1 6 400
# 2 7 400
# c x 1 8 500
# 2 9 500
# y 1 10 600
# 2 11 600
その条件が満たされない場合は、次のコードを使用して2つのマルチインデックスの結合を実行できます。
leftindex = pd.MultiIndex.from_tuples(
[("K0", "X0"), ("K0", "X1"), ("K1", "X2")], names=["key", "X"]
)
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=leftindex
)
rightindex = pd.MultiIndex.from_tuples(
[("K0", "Y0"), ("K1", "Y1"), ("K2", "Y2"), ("K2", "Y3")], names=["key", "Y"]
)
right = pd.DataFrame(
{"C": ["C0", "C1", "C2", "C3"], "D": ["D0", "D1", "D2", "D3"]}, index=rightindex
)
result = pd.merge(
left.reset_index(), right.reset_index(), on=["key"], how="inner"
).set_index(["key", "X", "Y"])
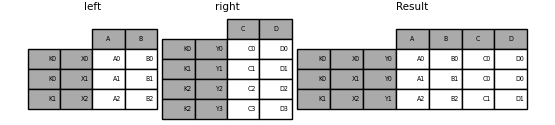
列とインデックスレベルの組み合わせでのマージ
on・left_on・right_onパラメータとして渡される文字列は、列名またはインデックスレベル名のいずれかを参照できます。これにより、インデックスをリセットせずに、インデックスレベルと列の組み合わせでDataFrameインスタンスをマージできます。
left_index = pd.Index(["K0", "K0", "K1", "K2"], name="key1")
left = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"key2": ["K0", "K1", "K0", "K1"],
},
index=left_index,
)
right_index = pd.Index(["K0", "K1", "K2", "K2"], name="key1")
right = pd.DataFrame(
{
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
"key2": ["K0", "K0", "K0", "K1"],
},
index=right_index,
)
result = left.merge(right, on=["key1", "key2"])
両方のフレームのインデックスレベルに一致する文字列でデータフレームをマージすると、インデックスレベルは結果のデータフレームのインデックスレベルとして保持されます。
MultiIndexの一部のレベルのみを使用してデータフレームをマージすると、マージ結果からは余分なレベルが削除されます。これらのレベルを保持するには、マージを実行する前に、それらのレベル名でreset_indexを使用してそれらのレベルを列に移動します。
文字列が列名とインデックスレベル名の両方に一致する場合、警告が送出され、列が優先されます。これは将来のバージョンであいまいなエラーが発生するかもしれません。
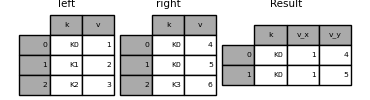
値が重複する列
mergeのsuffixes引数は、結果の列を明確にするために、入力DataFrameの重複する列名に追加する文字列のタプルを受け取ります。
left = pd.DataFrame({"k": ["K0", "K1", "K2"], "v": [1, 2, 3]})
right = pd.DataFrame({"k": ["K0", "K0", "K3"], "v": [4, 5, 6]})
result = pd.merge(left, right, on="k")
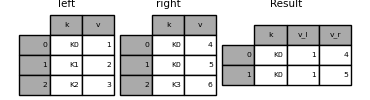
result = pd.merge(left, right, on="k", suffixes=("_l", "_r"))
DataFrame.join()には、同様に動作するlsuffixおよびrsuffix引数があります。
left = left.set_index("k")
right = right.set_index("k")
result = left.join(right, lsuffix="_l", rsuffix="_r")
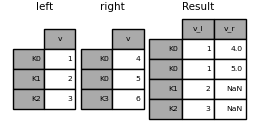
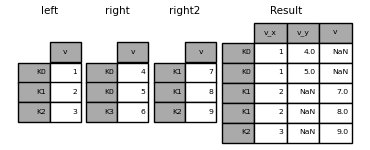
複数のデータフレームの結合
DataFrameのリストまたはタプルをjoin()に渡して、インデックスでそれらを結合することもできます。
right2 = pd.DataFrame({"v": [7, 8, 9]}, index=["K1", "K1", "K2"])
result = left.join([right, right2])
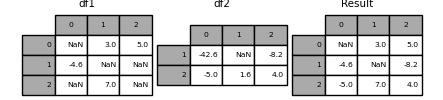
SeriesまたはDataFrameの列内の値を結合する
もう1つのかなり一般的な状況は、2つの同様にインデックス付けされた(または同様にインデックス付けされた)SeriesまたはDataFrameオブジェクトを持ち、一方のオブジェクトの値を他方のインデックスと一致する値から「穴埋め(patch)」したい場合です。以下に例を示します。
df1 = pd.DataFrame(
[[np.nan, 3.0, 5.0], [-4.6, np.nan, np.nan], [np.nan, 7.0, np.nan]]
)
df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5.0, 1.6, 4]], index=[1, 2])
これには、combine_first()メソッドを使用します。
result = df1.combine_first(df2)
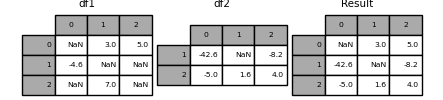
このメソッドは、左側のDataFrameに値がない場合にのみ、右側のDataFrameから値を取得することに注意してください。関連するメソッドupdate()は、 NA 以外の値を変更します。
df1.update(df2)
時系列データのための結合
順序があるデータの結合
merge_ordered()関数を使用すると、時系列と他の順序付けられたデータを組み合わせることができます。欠落データを埋める・補間するオプションのfill_method引数があるのが特徴です。
left = pd.DataFrame(
{"k": ["K0", "K1", "K1", "K2"], "lv": [1, 2, 3, 4], "s": ["a", "b", "c", "d"]}
)
right = pd.DataFrame({"k": ["K1", "K2", "K4"], "rv": [1, 2, 3]})
pd.merge_ordered(left, right, fill_method="ffill", left_by="s")
# k lv s rv
# 0 K0 1.0 a NaN
# 1 K1 1.0 a 1.0
# 2 K2 1.0 a 2.0
# 3 K4 1.0 a 3.0
# 4 K1 2.0 b 1.0
# 5 K2 2.0 b 2.0
# 6 K4 2.0 b 3.0
# 7 K1 3.0 c 1.0
# 8 K2 3.0 c 2.0
# 9 K4 3.0 c 3.0
# 10 K1 NaN d 1.0
# 11 K2 4.0 d 2.0
# 12 K4 4.0 d 3.0
asofマージ
merge_asof()は、順序付けられた左結合に似ていますが、等しいキーではなく最も近いキーで一致させます。left DataFrameの各行に対して、onキーが左側のキーよりも小さいright DataFrameの最後の行を選択します。両方のデータフレームはキーでソートされている必要があります。
オプションで、asofマージはグループ単位のマージを実行できます。これは、onキーに対して近似一致し、加えてbyキーで完全一致させます。
例えば、tradesとquotesがあるとき、それらをマージします。
trades = pd.DataFrame(
{
"time": pd.to_datetime(
[
"20160525 13:30:00.023",
"20160525 13:30:00.038",
"20160525 13:30:00.048",
"20160525 13:30:00.048",
"20160525 13:30:00.048",
]
),
"ticker": ["MSFT", "MSFT", "GOOG", "GOOG", "AAPL"],
"price": [51.95, 51.95, 720.77, 720.92, 98.00],
"quantity": [75, 155, 100, 100, 100],
},
columns=["time", "ticker", "price", "quantity"],
)
quotes = pd.DataFrame(
{
"time": pd.to_datetime(
[
"20160525 13:30:00.023",
"20160525 13:30:00.023",
"20160525 13:30:00.030",
"20160525 13:30:00.041",
"20160525 13:30:00.048",
"20160525 13:30:00.049",
"20160525 13:30:00.072",
"20160525 13:30:00.075",
]
),
"ticker": ["GOOG", "MSFT", "MSFT", "MSFT", "GOOG", "AAPL", "GOOG", "MSFT"],
"bid": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],
"ask": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03],
},
columns=["time", "ticker", "bid", "ask"],
)
trades
# time ticker price quantity
# 0 2016-05-25 13:30:00.023 MSFT 51.95 75
# 1 2016-05-25 13:30:00.038 MSFT 51.95 155
# 2 2016-05-25 13:30:00.048 GOOG 720.77 100
# 3 2016-05-25 13:30:00.048 GOOG 720.92 100
# 4 2016-05-25 13:30:00.048 AAPL 98.00 100
quotes
# time ticker bid ask
# 0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
# 1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
# 2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
# 3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
# 4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
# 5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
# 6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
# 7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
デフォルトとして、quotesのasofを適用します。
pd.merge_asof(trades, quotes, on="time", by="ticker")
# time ticker price quantity bid ask
# 0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
# 1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
# 2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
# 3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
# 4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
quote時刻とtrade時刻の間の時間を2ms以内にします。
pd.merge_asof(trades, quotes, on="time", by="ticker", tolerance=pd.Timedelta("2ms"))
# time ticker price quantity bid ask
# 0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
# 1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
# 2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
# 3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
# 4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
quote時刻とtrade時刻の間の時間を10ms以内にし、時間通りの完全一致は除外します。(quotesの)完全一致は除外しますが、以前のquotesはその時点まで伝播することに注意してください。
pd.merge_asof(
trades,
quotes,
on="time",
by="ticker",
tolerance=pd.Timedelta("10ms"),
allow_exact_matches=False,
)
# time ticker price quantity bid ask
# 0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
# 1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
# 2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
# 3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
# 4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
オブジェクトのcompare
compare()メソッドとcompare()メソッドを使用すると、2つのデータフレームまたはシリーズをそれぞれ比較し、その差分をまとめることができます。
この機能はV1.1.0から追加されました。
たとえば、2つのデータフレームを比較して、それらの違いを並べてスタックすることができます。
df = pd.DataFrame(
{
"col1": ["a", "a", "b", "b", "a"],
"col2": [1.0, 2.0, 3.0, np.nan, 5.0],
"col3": [1.0, 2.0, 3.0, 4.0, 5.0],
},
columns=["col1", "col2", "col3"],
)
df
# col1 col2 col3
# 0 a 1.0 1.0
# 1 a 2.0 2.0
# 2 b 3.0 3.0
# 3 b NaN 4.0
# 4 a 5.0 5.0
df2 = df.copy()
df2.loc[0, "col1"] = "c"
df2.loc[2, "col3"] = 4.0
df2
# col1 col2 col3
# 0 c 1.0 1.0
# 1 a 2.0 2.0
# 2 b 3.0 4.0
# 3 b NaN 4.0
# 4 a 5.0 5.0
df.compare(df2)
# col1 col3
# self other self other
# 0 a c NaN NaN
# 2 NaN NaN 3.0 4.0
デフォルトでは、2つの対応する値が等しい場合、それらはNaNとして表示されます。さらに、ある行・列全体の値が等しい場合、その行・列は結果から省略されます。残りの差分は列ごとに配置されます。
必要に応じて、差分を行方向に積み重ねることもできます。
df.compare(df2, align_axis=0)
# col1 col3
# 0 self a NaN
# other c NaN
# 2 self NaN 3.0
# other NaN 4.0
元の行と列をすべて保持する場合は、keep_shape引数をTrueに設定します。
df.compare(df2, keep_shape=True)
# col1 col2 col3
# self other self other self other
# 0 a c NaN NaN NaN NaN
# 1 NaN NaN NaN NaN NaN NaN
# 2 NaN NaN NaN NaN 3.0 4.0
# 3 NaN NaN NaN NaN NaN NaN
# 4 NaN NaN NaN NaN NaN NaN
また、元の値がすべて同じであっても、それらすべてを保持することもできます。
df.compare(df2, keep_shape=True, keep_equal=True)
# col1 col2 col3
# self other self other self other
# 0 a c 1.0 1.0 1.0 1.0
# 1 a a 2.0 2.0 2.0 2.0
# 2 b b 3.0 3.0 3.0 4.0
# 3 b b NaN NaN 4.0 4.0
# 4 a a 5.0 5.0 5.0 5.0