1.はじめに
- この記事は知財系 もっともっと Advent Calendar 2021の記事です。
- Google Patents Public Datasetsが特許データの分析に便利!ということを伝えたくて書きました。
2.Google Patents Public Datasetsについて
- どんなデータが入っている?
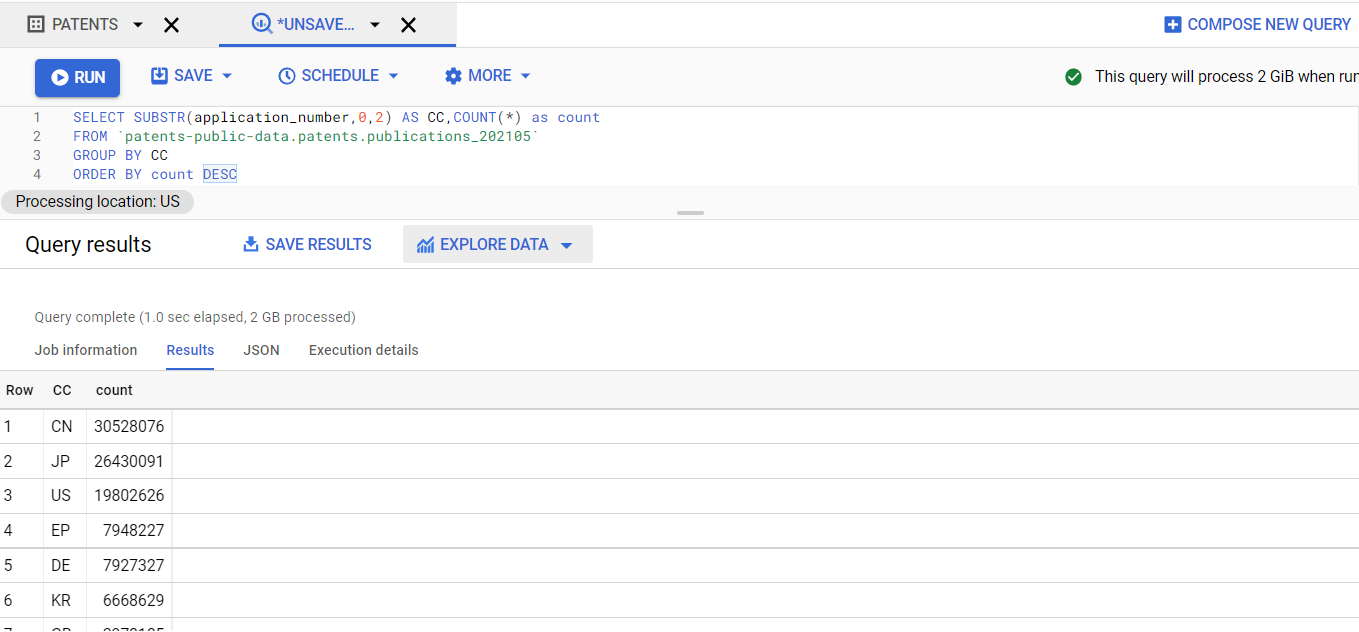
ここを見るとわかるように、US、CNをはじめとして各国の特許データの書誌事項(US公開系はfulltextまで)が入っています。
SQL
SELECT SUBSTR(application_number,0,2) AS CC,COUNT(*) as count
FROM `patents-public-data.patents.publications_202105`
GROUP BY CC
ORDER BY count DESC
結果
- データもとは?
ifiCLAIMSという特許データ提供会社が加工したデータをCreativeCommonsとして提供してBigQueryに格納されています。だいたい半年に1回ほどデータが更新されます。2021年12月13日時点の最新は2021年5月更新分です。

3.どうやって使うのか?
-
BigQueryというGoogleのサービスを使います。メリットなどはリンク先参照ですが、とにかく速いのが特徴。数千万件のレコードでも数秒で処理結果が帰って来ます。
SQLという言語でデータベースからデータを取得&加工します。 -
取得した後はcsvに吐き出した後、pythonなどで可視化します。
ちなみにpandas-bgq等のライブラリを使えばpythonから直接BigQueryを動かすことができるので、大量データの処理はBigqueryにやらせて、処理結果をpythonで受け取ることもできます。
1例:出願人名検索
SELECT publication_number,
STRING_AGG(ipcs.code,",") as IPC,
STRING_AGG(appl,",") AS applicants
FROM `patents-public-data.patents.publications_202105`
,UNNEST(ipc) as ipcs
,UNNEST(assignee) as appl
WHERE appl LIKE '%トヨタ自動車%'
GROUP BY publication_number
1例:IPC検索
SELECT publication_number,
STRING_AGG(ipcs.code,",") as IPC,
STRING_AGG(appl,",") AS applicants
FROM `patents-public-data.patents.publications_202105`
,UNNEST(ipc) as ipcs
,UNNEST(assignee) as appl
WHERE ipcs.code LIKE '%G06Q%'
GROUP BY publication_number
4.メリット/デメリット
(1)メリット
-
大量のデータをさくっと扱える。
下記のデータ収録範囲を見ればわかるように世界各国のデータが入っています。
要約、タイトルまでであればだいたいすべて取れます。 -
(基本的に)無料
⇒自動で30,000円分の利用枠がもらえる上に、無料枠内であればずっと無料です。
私はヘビーに使っていますが、BigQueryの利用料金は月3,000円くらいです。
(2)デメリット(プログラミングになじみのない人)
-
Gogle Clooud Platform(GCP)への登録が抵抗ある人がいるかも(クレカ要登録)
⇒上記のとおりかなりの部分が無料ですが、GCPのエコシステムが使えるので、登録してみてもよいと思います! -
SQLを多少覚える必要あり
SELECT,GROUPBYくらい覚えれば基本的な操作はできますので敬遠せずどうぞ。 -
データ収録の遅さ
早く更新いてくれみたいなrequestが来るくらい遅いときがあります。
5.利用例
(1)技術同士のつながりを可視化する
SQL
with rtable as (
SELECT family_id as rappnum, SUBSTR(ipcs.code,0,4) as rcode
FROM `patents-public-data.patents.publications_202101` ,
UNNEST(ipc) as ipcs
WHERE filing_date >= 20000101
GROUP BY rappnum,rcode
),
ltable as (
SELECT family_id as lappnum, SUBSTR(ipcs.code,0,4) as lcode
FROM `patents-public-data.patents.publications_202101` ,
UNNEST(ipc) as ipcs
WHERE filing_date >= 20000101
GROUP BY lappnum,lcode
),
cotable as (
SELECT lappnum,rappnum,lcode,rcode
FROM ltable
join rtable
ON lappnum = rappnum
)
SELECT lcode,rcode,COUNT(*) as count
FROM cotable
WHERE lcode != rcode
GROUP BY lcode,rcode

(2)世界一被引用回数が多い特許を調べる。
母集団等はこの記事を参照。
SQL
WITH bibtable as (
SELECT
pub.application_number AS appnum,
pub.publication_number AS pubnum,
pub.filing_date as appday,
STRING_AGG(DISTINCT(applicants.name)) AS applicants ,
STRING_AGG(DISTINCT(title.text)) AS texts,
SUBSTR(STRING_AGG(ipcs.code),0,1) AS ipc4,
STRING_AGG(DISTINCT(title.text)) AS title
FROM `patents-public-data.patents.publications_201912` AS pub,
UNNEST(title_localized) AS title,
UNNEST(assignee_harmonized) as applicants,
UNNEST(ipc) as ipcs
GROUP BY appnum,pubnum,appday
)
SELECT
bibtable.pubnum,
SUBSTR(bibtable.pubnum,0,2) AS appcountry,
SUBSTR(STRING_AGG(DISTINCT(CAST(bibtable.appday AS STRING))),0,4) AS appyear,
#STRING_AGG(DISTINCT(cit.application_number)) as appnum,
#STRING_AGG(DISTINCT(cit.type)) AS cit_type,
COUNT(main.application_number) AS total_cit_count,
COUNT(DISTINCT(main.family_id)) AS unique_cit_count,
STRING_AGG(DISTINCT(ipc4)) AS ipcs,
STRING_AGG(DISTINCT(title)) AS titles,
STRING_AGG(DISTINCT(applicants)) AS applicants,
ARRAY_AGG(STRUCT(SUBSTR(ipcs.code,0,1) AS ipc_sec,
SUBSTR(main.publication_number,0,2) AS cc,
SUBSTR(CAST(main.filing_date AS STRING),0,4) AS year,
appls)
) AS fcit,
#STRING_AGG(cit.type),STRING_AGG(DISTINCT(family_id))
FROM
`patents-public-data.patents.publications_201912` as main,
UNNEST(main.citation) AS cit,
UNNEST(main.ipc) AS ipcs,
UNNEST(main.assignee) AS appls
LEFT JOIN bibtable
ON cit.publication_number = bibtable.pubnum
WHERE SUBSTR(main.publication_number,0,2) IN ('US','JP','EP','CN','KR','WO') AND pubnum IS NOT NULL AND ipcs.first = TRUE
GROUP BY appnum,pubnum
ORDER BY total_cit_count DESC,pubnum DESC
| Row | pubnum | appcountry | appyear | total_cit_count | unique_cit_count | ipcs | titles | applicants | IPC_A | IPC_B | IPC_C | IPC_D | IPC_E | IPC_F | IPC_G | IPC_H | US | JP | EP | KR | CN | WO |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | US-4683202-A | US | 1985 | 8996 | 4766 | C | Process for amplifying nucleic acid sequences | CETUS CORP | 1602 | 148 | 6116 | 13 | 1 | 12 | 1083 | 21 | 5542 | 0 | 1701 | 1 | 1 | 1751 |
| 2 | US-4816567-A | US | 1983 | 8668 | 4748 | C | Recombinant immunoglobin preparations | GENENTECH INC | 3319 | 27 | 4354 | 8 | 0 | 3 | 954 | 3 | 4387 | 0 | 1878 | 0 | 1 | 2402 |
| 3 | US-4683195-A | US | 1986 | 7174 | 3763 | C | Process for amplifying, detecting, and/or-cloning nucleic acid sequences | CETUS CORP | 1115 | 154 | 4853 | 1 | 1 | 11 | 1021 | 18 | 4593 | 0 | 1355 | 1 | 1 | 1224 |
| 4 | US-5223409-A | US | 1991 | 4956 | 2523 | C | Directed evolution of novel binding proteins | PROTEIN ENG CORP | 1598 | 17 | 2833 | 10 | 0 | 2 | 493 | 3 | 2629 | 2 | 1092 | 1 | 0 | 1232 |
| 5 | US-5523520-A | US | 1994 | 4759 | 3761 | C | Mutant dwarfism gene of petunia | GOLDSMITH SEEDS INC | 4585 | 1 | 162 | 0 | 2 | 1 | 5 | 3 | 4759 | 0 | 0 | 0 | 0 | 0 |
(3)有価証券報告書と特許データを同時に検索する
⇒Google DataStudio(ダッシュボード作成ツール)と組み合わせれば、簡単に特許データのダッシュボードを作れます。※特許データ側にGoogle Patents Public Datasetsを利用。

6.他の例用例とか
- BigQueryだけで機械学習できる!
- PCAもできる
PCA
CREATE OR REPLACE MODEL PROJECT.DATASET.pcadata
OPTIONS(MODEL_TYPE = 'PCA' ,
NUM_PRINCIPAL_COMPONENTS = 5,
SCALE_FEATURES = FALSE ,
PCA_SOLVER = 'AUTO'
) AS (
SELECT publication_number, emb
FROM `patents-public-data.google_patents_research.publications_202105`,UNNEST(embedding_v1) as emb
);
- 昔ちょっと流行ったBERT for Patentsもこのデータを利用して作成されてます。
- 請求項の広さの推定とか
- GPT-2で、タイトル→要約書、要約書→請求項1を生成するという技術でもこのデータが使われています。日本だとIIPなどありますが、アカデミックなとこでも使われてますね。
- 同じpublic datasetの中に「google_patents_research」という、書誌事項+テキスト情報からembeddしたデータがはいっているDBもあります。1つ1つの公報が100次元くらいのベクトルになっているので、cosine類似度などでサクッと類似文献抽出が可能です。被引用文献リストもとれるので、引用分析の際に便利です。