2025年5月1日: 結構GUI等変わっていたので全面的に更新しました!
Spark labは、watsonx.dataと連携したSparkエンジン上で動作するSparkクラスタ上でSparkアプリケーションをVisual Studio Code(以下VSCode)を使ってインタラクティブにプログラム、デバッグ、サブミット、テストできるSparkベースの開発環境です。
VSCodeの拡張機能として提供されており、ローカルシステムにインストールすることで、VSCodeを使用してSpark IDEにアクセスできます。
IBM Analytics Engine Sparkからwatsonx.data を操作: 「3. Sparkによる処理」 を書いたときはデバッグが難しすぎて困りましたが、Spark labを使えばVSCodeでお手軽に動作確認できます。
Spark labs - Development environmentにドキュメントがありますが、試行錯誤が必要でした。
2025年5月1日頃確認したら、GUIが改善されていて、試行錯誤なしでいけそうでした!
当記事は試行錯誤なしで使えるように、SaaS版 watsonx.dataのNative Sparkを使用したVSCodeの設定方法と使い方について説明します。
1. 前提
-
Native sparkエンジンが追加済み かつ MetadataAdminロールの付与済み
- 追加していない場合は「watsonx.data: Sparkエンジンの追加」の方法で追加してください
- 「5. IAMでMetadataAdminロールの付与 」は必須ですので必ず設定してください
- 追加していない場合は「watsonx.data: Sparkエンジンの追加」の方法で追加してください
-
APIKEY取得済み
-
取得していない場合は以下のどちらかの方法で取得してください
-
-
MetadataAdmin ロールの付与をお願いします
-
VSCode導入済み
2. watsonx.data extensionとRemote SSHのVSCodeへの導入
watsonx.data extensionをVSCodeに導入します。
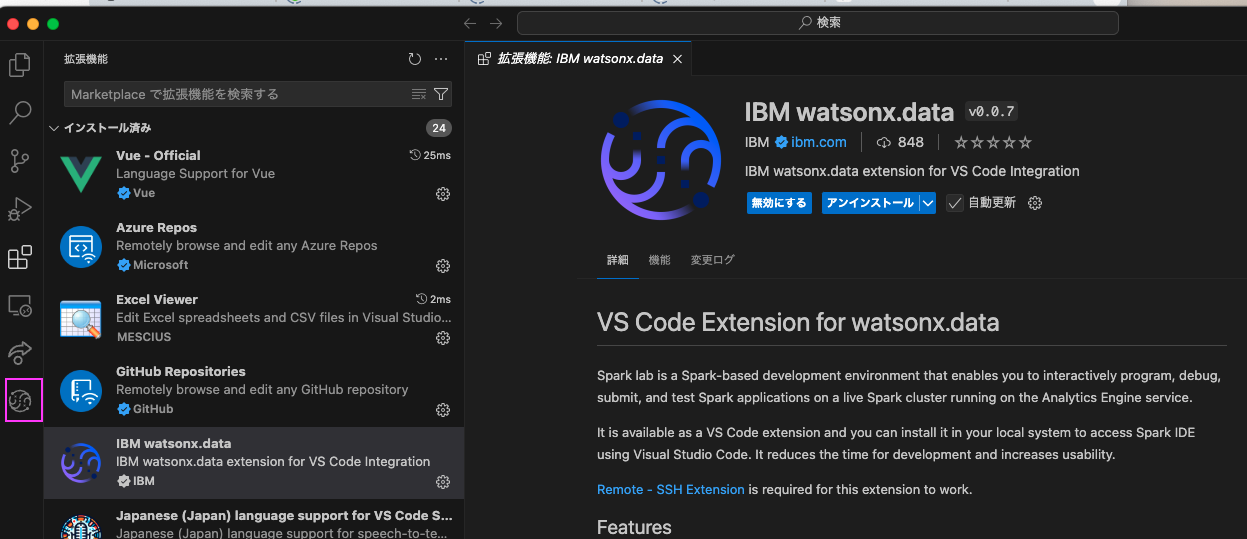
2.1: 左側のアクティビティバーから「拡張機能」のアイコンをクリックし、表示された検索窓にwatsonx.dataと入力
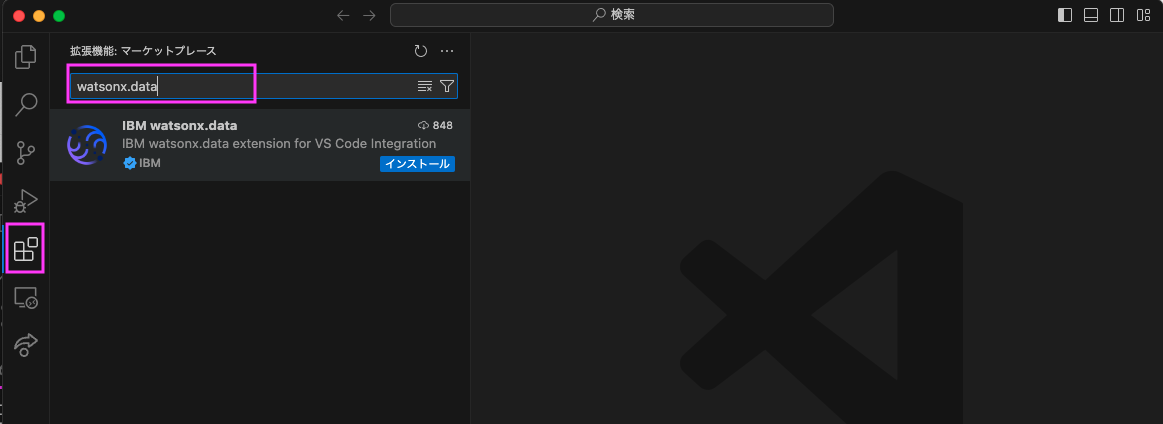
2.2: 表示された「IBM watsonx.data」をクリックし、「インストール」をクリックします
watsonx.data extensionが導入されます
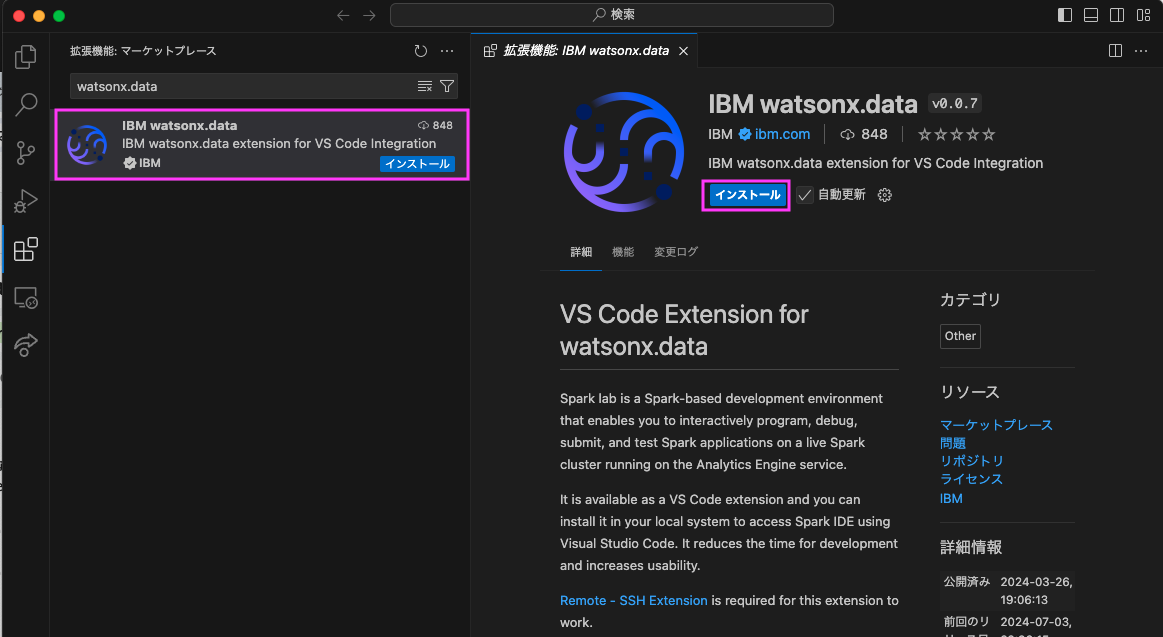
導入が完了すると 左側のアクティビティバーにwatsonx.dataのアイコンが表示されます

2.3: Remote - SSH Extension をVSCodeへ導入します
「Remote - SSH Extension is required for this extension to work.」と書いてありますので、この拡張機能も導入します。
検索窓にRemote - SSHと入力し、表示された「Remote - SSH」をクリックします。

「インストール」をクリックします
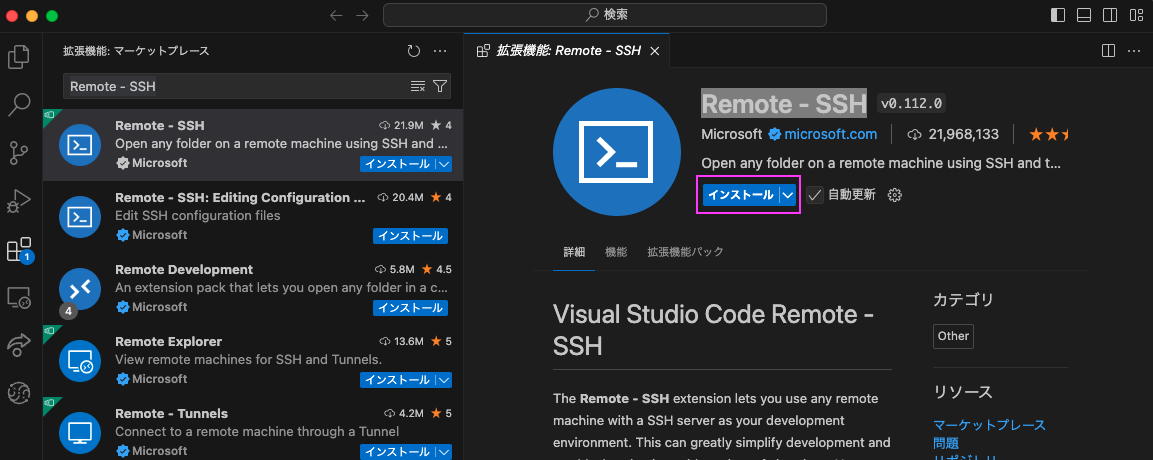
これでRemote - SSHは導入完了です。
3. SSH公開鍵・秘密鍵の作成
既に使用可能なSSH公開鍵・秘密鍵を自分のPC(Mac?)上に作成済みであればそれが使用可能ですので、ここはskipして先に進んでください。
Macでしかやってないので、Macでの方法を記載します。
Windowsの場合も「ssh公開鍵作成 windows」 でググれば方法は出てきますので、その方法でやってみてください。あるいは英語であれば「IBM watsonx.data」拡張機能の説明に書いてあります。
参考: 「IBM watsonx.data」拡張機能の説明の出し方
左側のアクティビティバーから「拡張機能」のアイコンをクリック → インストール済みに表示された「IBM watsonx.data」をクリック → 「拡張機能 IBM watsonx.data」タブが表示される(スクロールするとSet up SSH on your machineという記載あり)
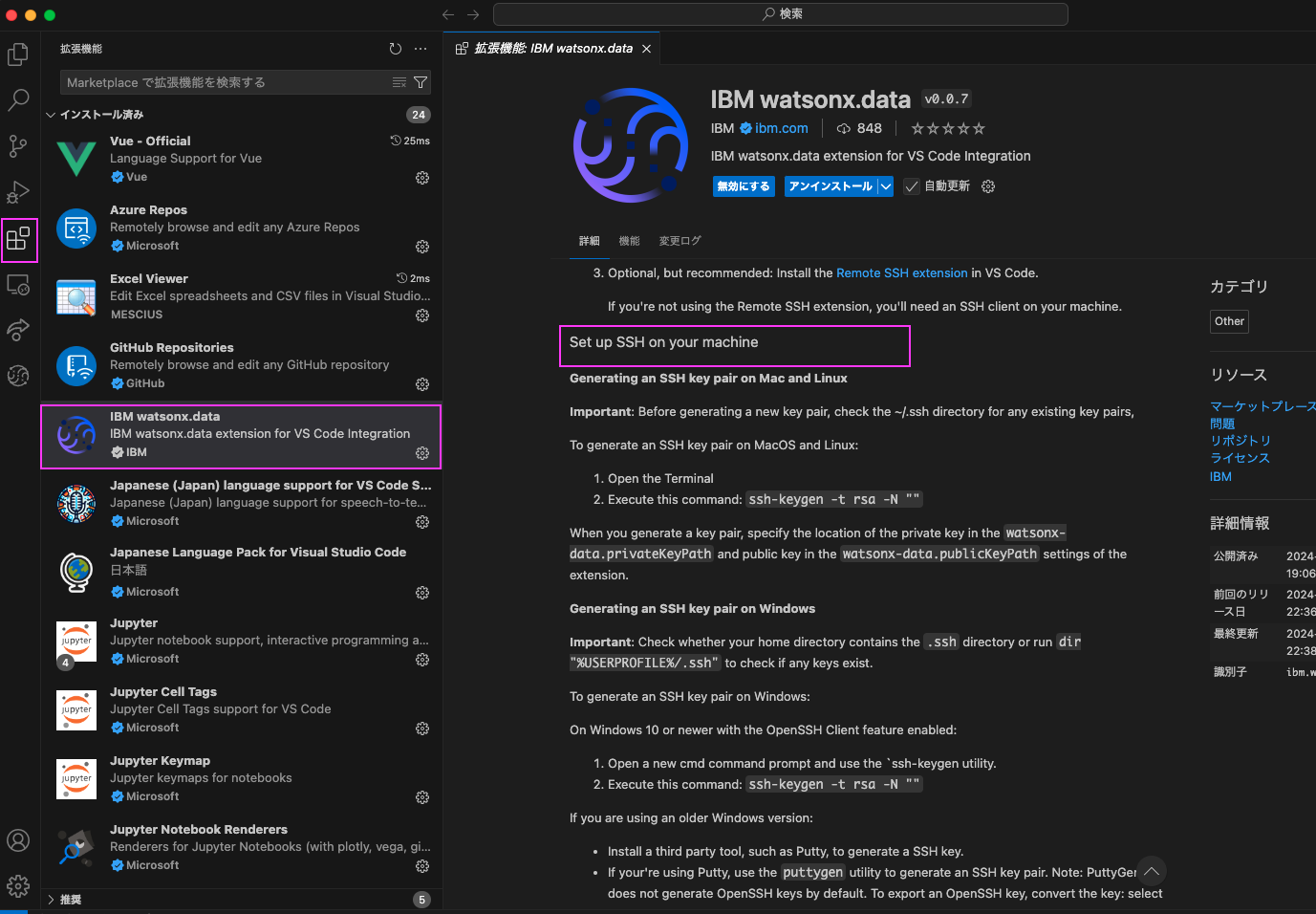
Macのターミナルを開いて、以下のコマンドを入力
ssh-keygen -t rsa -N ""
File名を聞かれますが、デフォルトでよければそのままEnterキーを押下してください
Enter file in which to save the key (/Users/<自分のid>/.ssh/id_rsa):
コマンドが完了すると、ファイル名をデフォルトにした場合は以下の2つのファイルができます。
- 秘密鍵:
~/.ssh/id_rsa - 公開鍵:
~/.ssh/id_rsa.pub
この2つのファイルパスはオプションで後の設定に入力します。
4. watsonx.data extensionを設定
4.1: Manage Connectionを設定
左側のアクティビティバーのwatsonx.dataのアイコンをクリック
最初は以下のようなメッセージが表示されます。
「Manage Connection」(または日本語で「接続の管理」)をクリックします。

以下のような画面が表示されるので、APIキーと接続JSON(取得方法はこのイメージの次に記載)を入力します。

接続JSONの取得方法:
watsonx.dataの「インフラストラクチャー・マネージャー」の画面で、使用するSparkエンジンをクリックします。

VS コードの接続設定の「ビュー構成」をクリックします

表示されたJSONが接続JSONなので、コピーして接続JSONの値に入れます

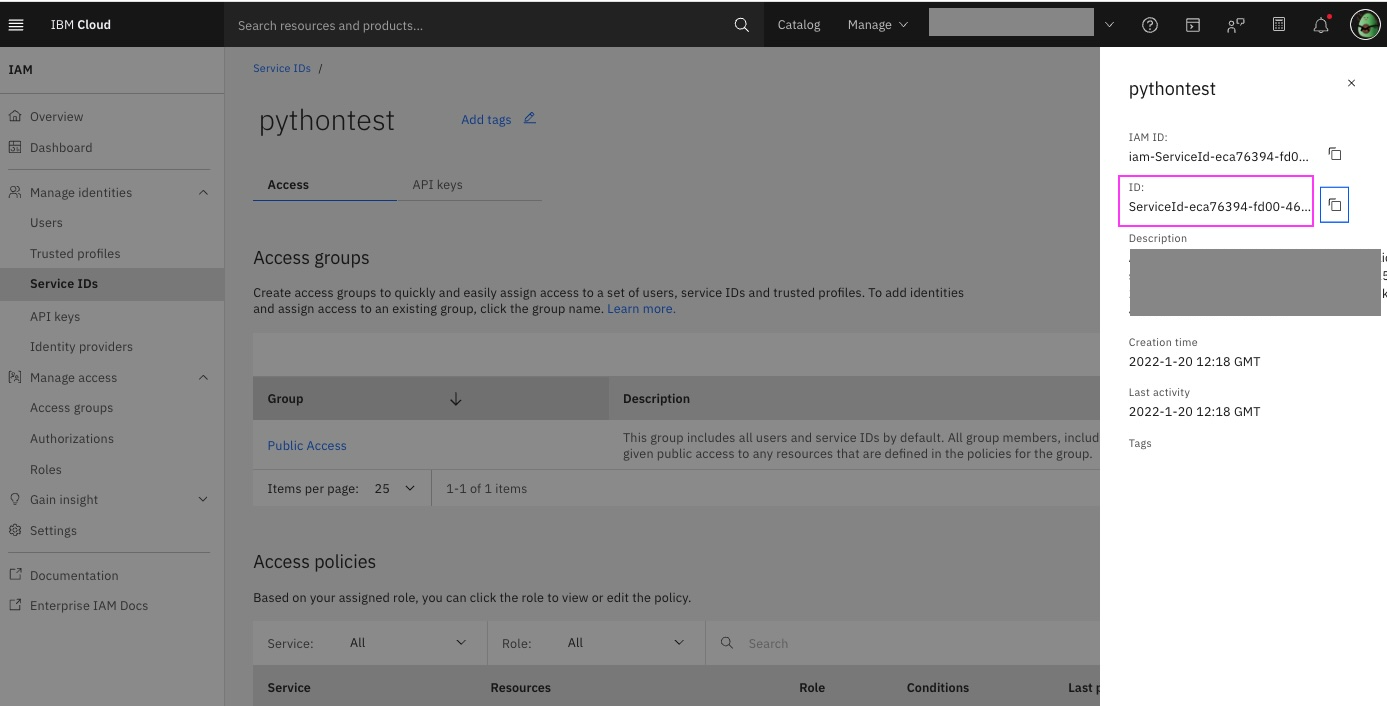
Service IDで接続する場合は、"user_name"の値をIAMの画面で取得できるService IDのID(GUID)に置き換えてください
APIキーと接続JSONを入力したら、[+ テスト&セーブ]をクリックしてください。
エラーが出なければOKです。
SSH系のエラーが出る場合は次の「4.2 IBM:watsonx.ⅾataの設定(オプション)」で3で作成したSSH公開鍵・秘密鍵ファイルの情報を入れてみてください。
4.2 IBM:watsonx.ⅾataの設定(オプション)
この設定はオプションです:
で作成したSSH公開鍵・秘密鍵ファイルの情報を設定します。
歯車アイコンをクリックします

「設定」タブが開きます

SSH公開鍵・秘密鍵を入力します。
Watsonx-data: Private Key Path
3で作成した秘密鍵のファイルのPATHを入れます

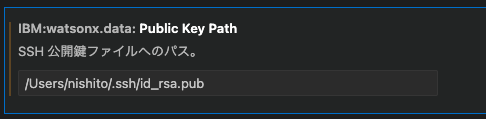
Watsonx-data: Public Key Path
3で作成した公開鍵のファイルのPATHを入れます
5. Spark labの作成
1: + アイコン クリック
Spark - Spark running のあたりにマウスをあてると、+ アイコンが表示されますので、それをクリックします。 作成Spark Labというタブが開きます。


必須で値を入れるのは名前のみです。
あとはお好みで設定してください。
2: 「+作成」 ボタンをクリック
右下の 「+作成」 ボタンをクリックします。
右下に`Creating spark cluster...`というメッセージが表示されるのでしばし待ちます

完了するとSpark - Spark running の下に作成されたSpark Labが表示されます。

6. 作成したSpark Labを起動
作成したSpark Labをクリックします

新規にウィンドウが開いてSpark Lab(=watsonx.data上のSpark)に接続に行くのでしばし待ちます

左下のメッセージがリモートを開いていますからSSH 127.0.0.1:xxxx(xxxxは数字)となったら接続完了です。

7. Spark Labに拡張機能をインストール
ここからはわかりやすくするためと動作確認用に、あらかじめ準備してあるspark_test.ipynbというjupyter notebookのファイルとspark_test.pyというpythonのファイルを使用します。
以下からダウンロードしておいてください:
-
spark_test.ipynb: https://github.com/kyokonishito/watsonx_spark/blob/main/spark_test.ipynb -
spark_test.py: https://github.com/kyokonishito/watsonx_spark/blob/main/spark_test.py
7.1 ダウンロードしたspark_test.ipynbをSpark Labの左側のエクスプローラーにドラッグアンドドロップでアップロードします。

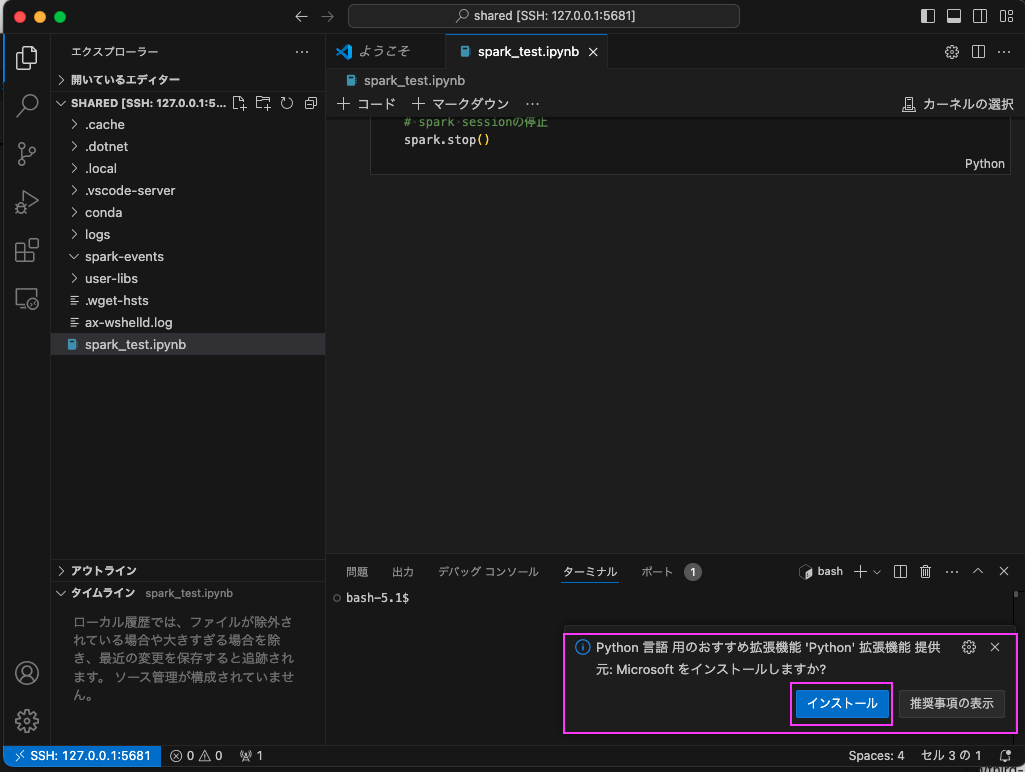
7.2 アップロードしたspark_test.ipynbをダブルクリックして開き、'Python' 拡張機能 をインストール
spark_test.ipynbを開くとPython 言語 用のおすすめ拡張機能 'Python' 拡張機能 提供元: Microsoft をインストールしますか?というメッセージが右下に表示されますで、「インストール」をクリックしてインストールします。
左側の拡張機能のエクスプローラー部分に「i」マークが表示されるまで待ちます

7.3 spark_test.ipynb タブをクリックしてspark_test.ipynbを再度表示し、 右上の「カーネルの選択」をクリックし、拡張機能を導入
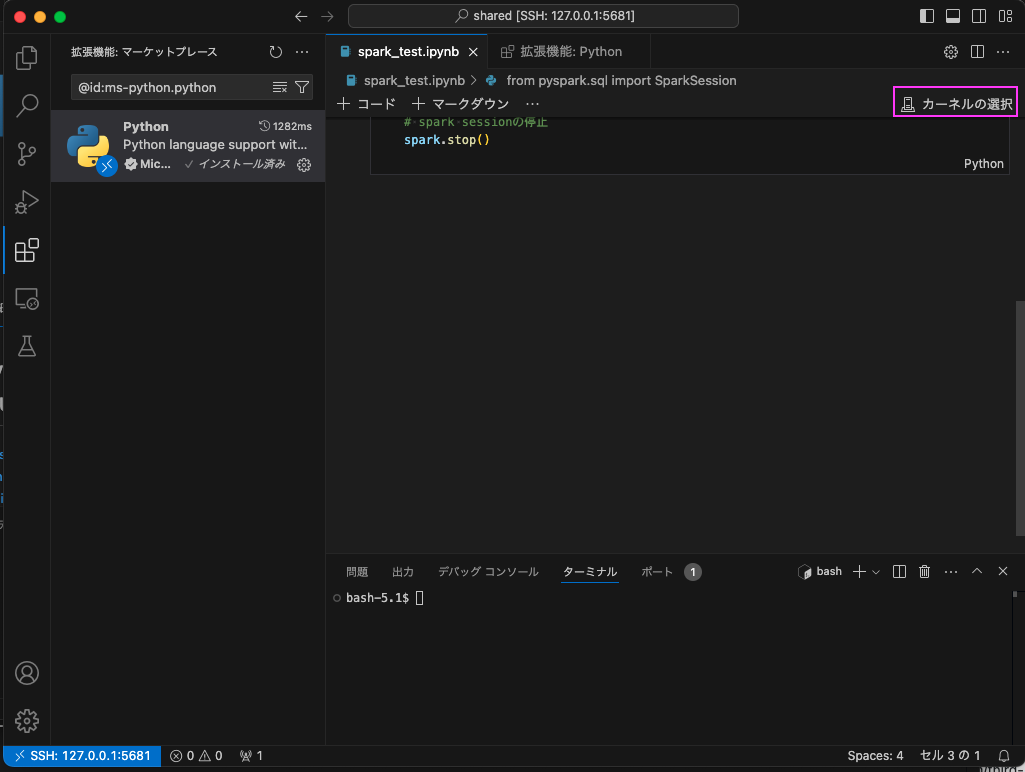
しばし待つと拡張機能の候補をインストールまたは有効にする Python + Jupyterというドロップダウンが、上部の「カーネルの選択」の下に表示されますので、そこをクリックします。
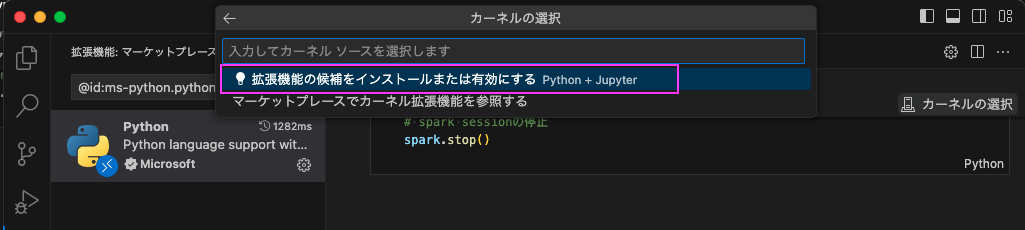
しばし待つと「base」がセットされます。
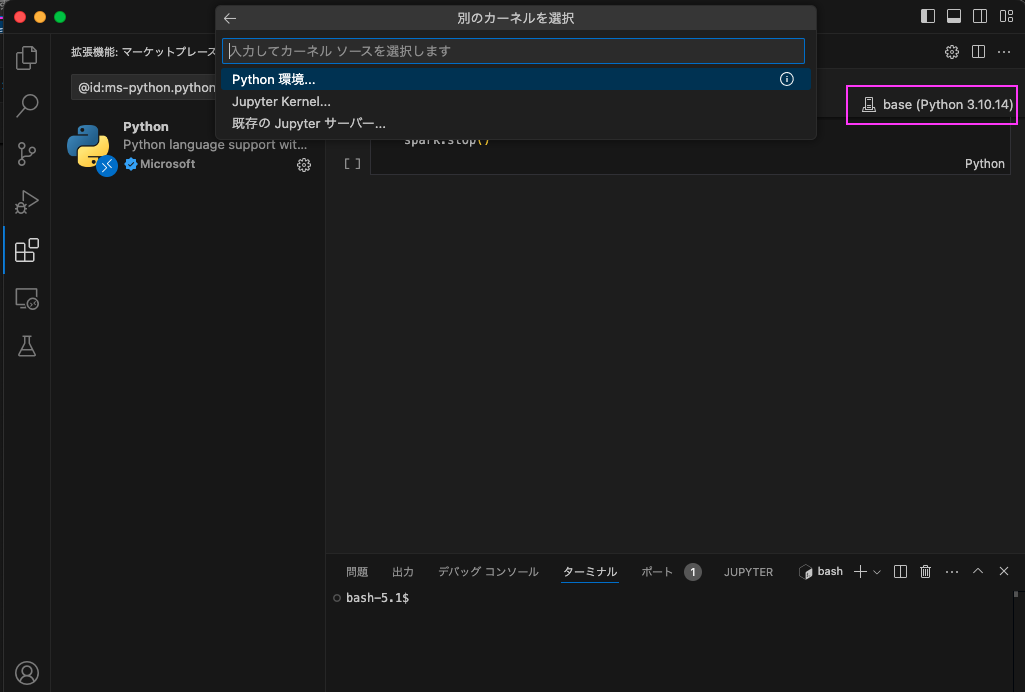
もしセットされない場合は、Python環境をクリックして、baseとついてるものを選択してください。

これでJupyter Notebookが実行できるようになりました!
8. Jupyter Notebookを実行
試しにspark_test.ipynb を実行してみます。
「全てを実行」をクリックして実行してみます。
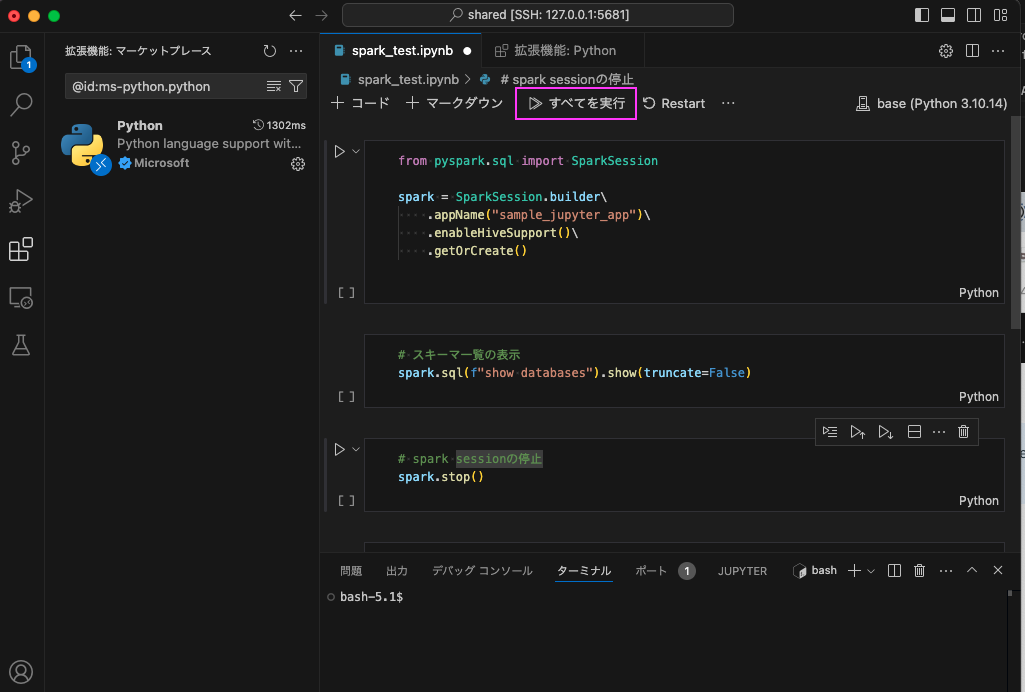
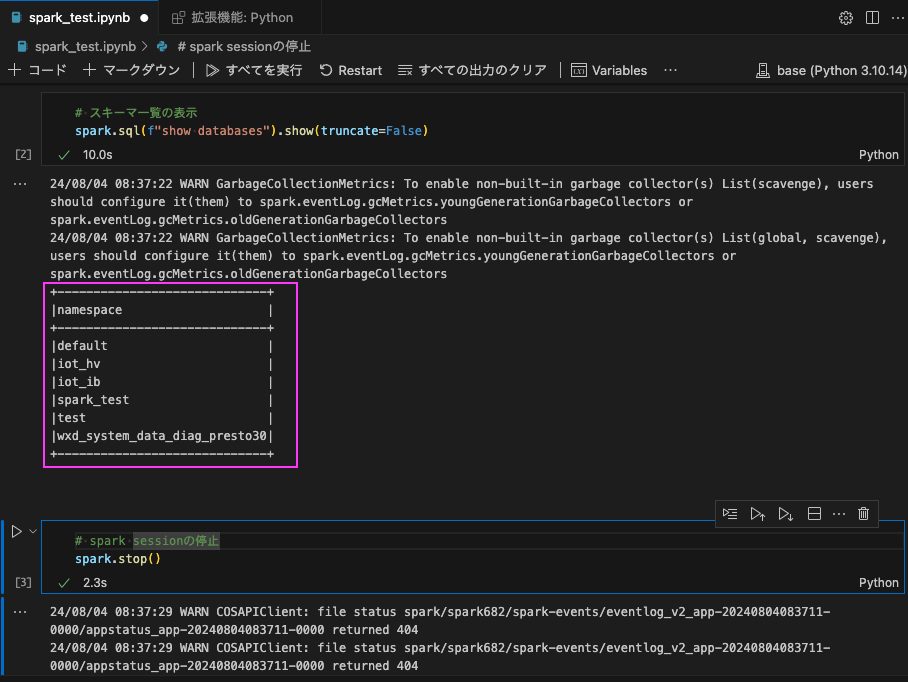
2番目のセルでは、スキーマ一覧を表示しています。
あとは新規に.ipynbの拡張子でファイル作成するか、同じようにnotebookのファイルをドラッグアンドドロップでアップロードして自分のコードを実行してみてください。
9. Python fileを実行
9.1 ダウンロードしたspark_test.pyをSpark Labの左側のエクスプローラーにドラッグアンドドロップでアップロードします
9.2 アップロードしたspark_test.pyをダブルクリックして開きます
9.3 右上の実行アイコンをクリックして実行します

これもスキーマ一覧を表示するコードです。結果はターミナルに表示されます。
いろいろWARNINGは出ますが、最終的にnotebookを実行した時と同じスキーマ一覧が表示されていると思います。

あとは新規に.pyの拡張子でファイル作成するか、同じようにpythonのファイルをドラッグアンドドロップでアップロードして自分のコードを実行してみてください。
10. 作成したファイルのローカルへの保存
環境が消えてしまうとファイルも消えてしまうので、終わる前に必ず残したいファイルはローカルにダウンロードしてください。
エクスプローラー画面から、保存したいファイルを右クリック、「ダウンロード」でダウンロード可能です

11. Spark ラボからの Spark UI へのアクセス
ローカルで「Spark ラボからの Spark UI へのアクセス」 を確認できることがドキュメントには記載されています。
ドキュメントに従って設定すると、Spark UI へのアクセスが可能です。
ドキュメントに書かれているポート4040はプログラム実行中のみ、データが表示されます。
ポート4040と同様に、ポート8080を「ポートの転送」設定するとSpark history serverの表示も可能です。
サーバー側での確認も可能です:
以下のドキュメントを参照の上、Spark history serverのUIで確認してみてください。
Accessing the Spark history server

12. 接続の切断
必要なファイルをローカルに保存したら、セッションを切断します。尚セッションを切断のみならファイルは通常は消えませんが、うまく復活できなかったことがあったので、念の為のローカル保存をお勧めします(長時間使ってない場合は消えるような気がしてます)。
また、切断前にすべてのファイルは閉じておいてください。
右下の青い「SSH: 127.0.0.1:xxxx」をクリックします

上部にドロップダウンが表示されますので、「リモート接続を終了する」をクリックします

接続が切断されるとVSCodeの初期画面になります。
13. 2回目以降のSpark Labの起動
左側のアクティビティバーのwatsonx.dataのアイコンをクリックすると、Spark Labのメニューが表示されるので、そこから起動して下さい。
作成済みのものはクリックすると以前と同じ設定、拡張機能もファイルもそのままで起動します。
が、復活しないこともあったので、何度やってもうまくいかない場合は、削除して作り直してください。
マウスカーソルをあてるとゴミ箱アイコンが表示されるので、クリックすると削除できます。

5.Spark Labの作成からやり直してください。
14. その他
デフォルト Spark 構成はサーバー側のSparkの詳細を表示すると表示可能です。これらの構成は設定済みでコード側で設定不要です。

15. 参考情報
pyspark は以下を参照してください:
https://spark.apache.org/docs/3.3.4/api/python/getting_started/index.html
watsonx.dataでのコードは以下を参考にして下さい:
Enhancing Spark application submission using Spark access control extension
Spark lab公式ドキュメントはこちら:
Spark labs - Development environment
以上です。