watsonx.dataのSaaS版にSparkエンジンが追加できるようになりました。今までは外部のIBM Analytics EngineSparkエンジンを使用する形でしたが、内部のSparkも選べるようになりました。
Sparkエンジン追加されていると、WebのGUIからSparkエンジンを使用した取り込みジョブ(CSV,parquetファイルなどのロード)が使えるようになります。
当記事はwatsonx.dataのSaaS版にSparkエンジンを追加する方法について説明します。
2025/05/01 MetastoreAccessロールをMetadataAdminロールに更新
2024/08/13 UI更新
2024/06/11 「5. IAMでMetastoreAccessロールの付与」を追記
0. 前提
- 既にwatsonx.dataのSaaS版のインスタンスが作成済みであること
1. 手順
1. 左側のナビゲーションメニューの「インフラストラクチャー・マネージャー」をクリックして「インフラストラクチャー・マネージャー」を表示

2. 右上の「コンポーネントの追加」をクリック
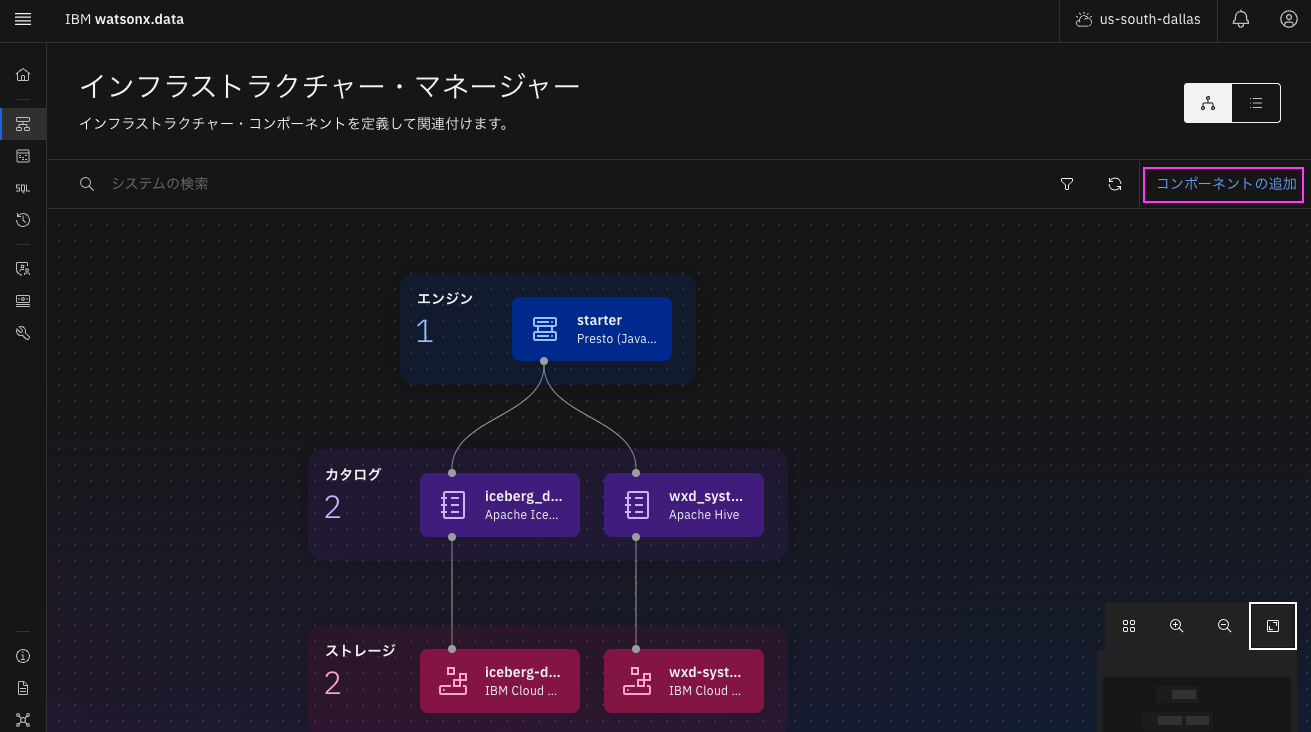
3. Enginsから「IBM Spark」をクリックし、「次へ」をクリック
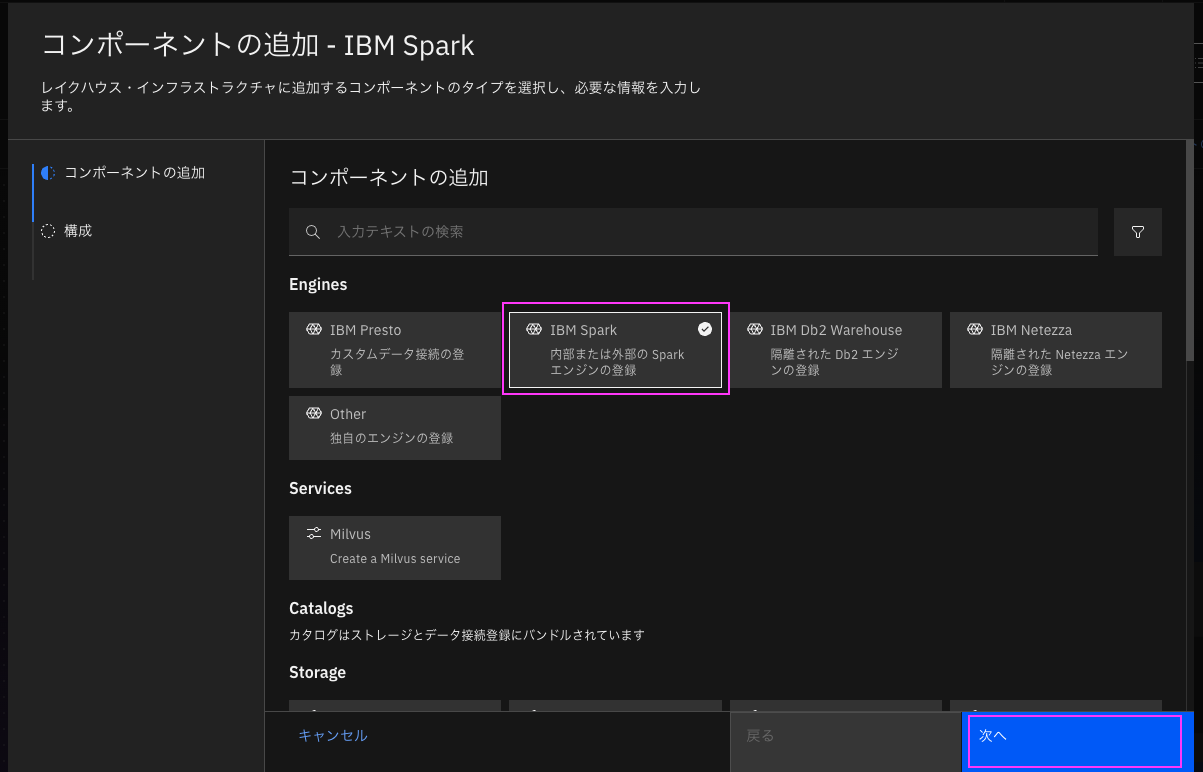
4. 「構成」で必要事項を入力し、「作成」をクリック
- 一般情報
- 表示名
- お好みの名前を記入。ここでは「Spark」としました
- 表示名
- エンジン構成
- 登録モード
- 「新規インスタンスの作成」を選択
- デフォルトの Spark バージョン
- お好みのバージョンを選択
- エンジン・ホーム・バケット
- カスタム・ライブラリー、Spark イベント、Spark ログなどのエンジン関連データのストレージ。ログを直接みるなど中身にアクセスしたい場合は、自分でアクセス可能なバケットを選択
- 容量の予約
- ノード・タイプ
- 必要なリソースを選択、デフォルトは小(Liteプランは小のみ)
- No. of nodes
- ノード数を設定、デフォルトは1(Liteプランは設定不可)
- ノード・タイプ
- 登録モード
- 関連付けられたカタログ(オプション)
- 必要に応じて操作したいテーブルのあるカタログを選択
5. プロビジョン完了まで待つ
プロビジョン中は、色が塗られていない、点線のエンジンが表示されています

3分程度でプロビジョンは完了しました、プロビジョン完了後、青色のエンジンが表示されます。

6. IAMでMetadataAdminロールの付与
使用するユーザーIDにMetadataAdminロールがついていないと、SparkでのIngest Jobが「User is not allowed to process this api」というエラーで失敗しますので付与しておきます。ここではユーザーIDに付与する例です。グループへ付与でも問題ありません。
6.1 IBM Cloudのダッシュボード画面の上部」メニューから、「管理」→「アクセス(IAM)」をクリック

6.2 左のメニューの「ユーザー」をクリックし、権限を付与したいユーザーIDをクリック

6.3 「アクセス」 タブをクリックし、「アクセス・ポリシー」の「アクセス権の割り当て」をクリック

6.4 「アクセス・ポリシー」にチェックし、サービスで「watsonx.data」を検索し、表示された」watsonx.dataをクリックし、チェックを入れる。その後、「次へ」をクリック。

6.5 リソース:
5.5-1 リソース: 全てのwatsonx.dataにセットする場合:
「すべてのリソース」を選択

6.5-1 リソース: 全てのwatsonx.dataにセットする場合:
「すべてのリソース」を選択
6.5-2 リソース: 特定のwatsonx.dataにセットする場合:
「特定のリソース」を選択し、特定のリソースの情報を入力し、「次へ」をクリック
ここではserviceIncetanceにして、権限を付与させるインスタンスのGUIDを入力
GUIDの取得方法は「IBM Cloud: 作成したリソースのCRNおよびGUID(インスタンスID)の取得方法」を参照

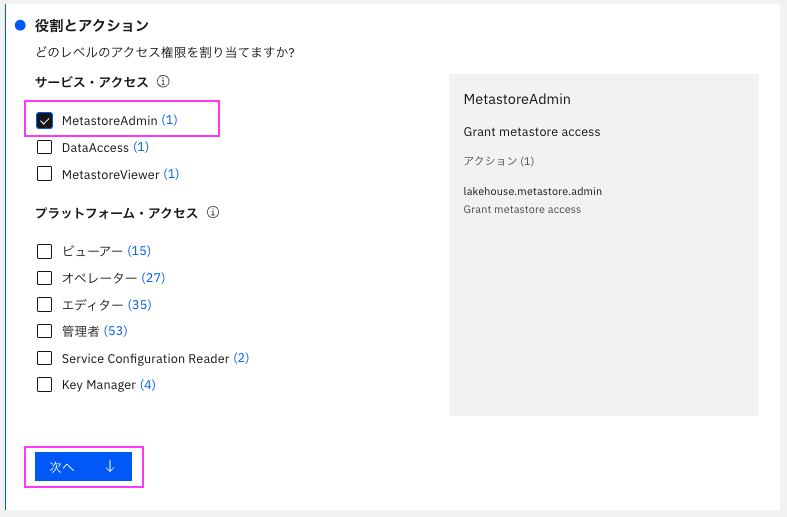
6.6 「役割とアクション」の「サービス・アクセス」の「MetadataAdmin」にチェックを入れ、「次へ」をクリック
6.6 「追加」をクリック
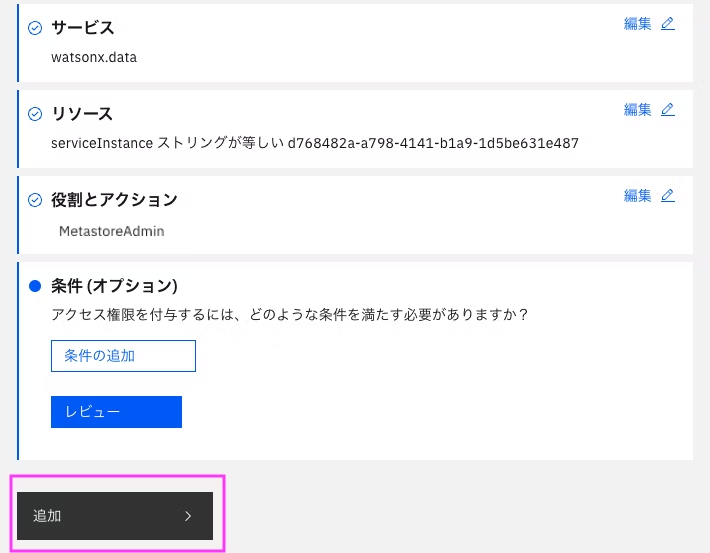
6.7 右側の「アクセス・サマリー」の「割り当て」をクリック
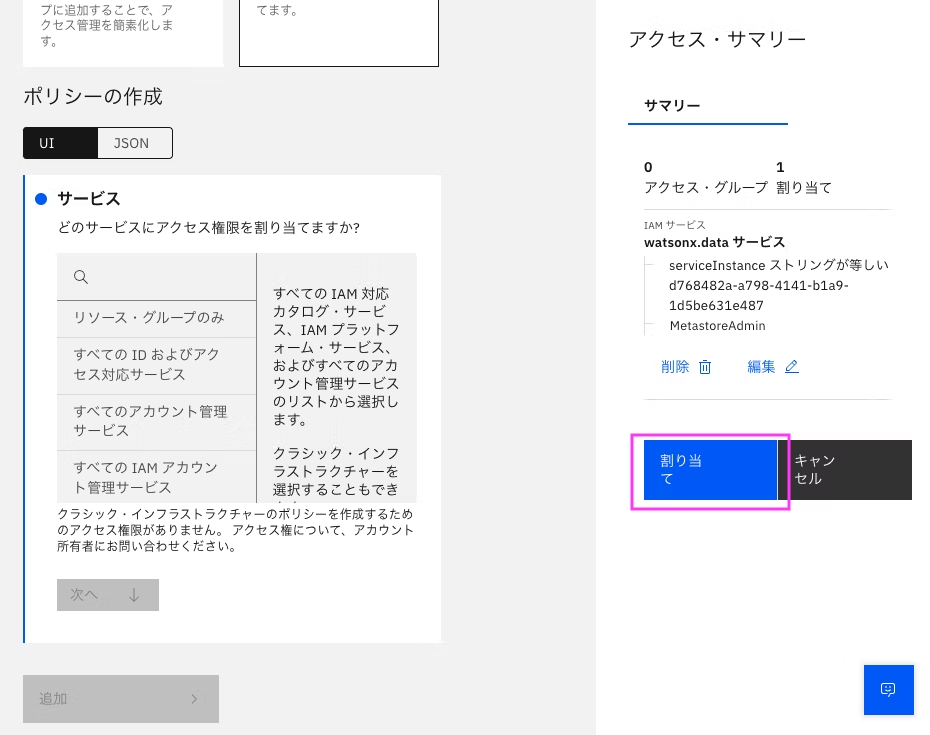
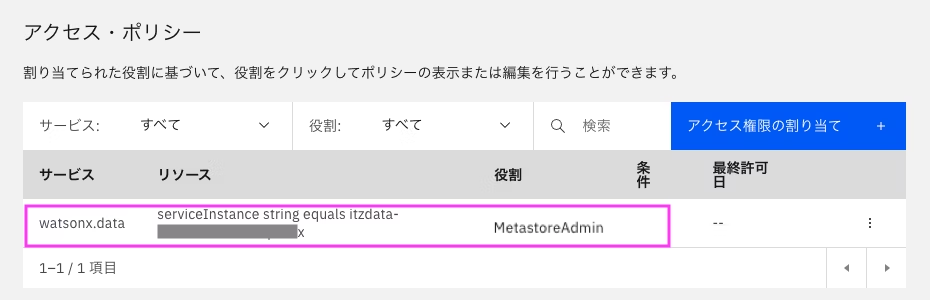
アクセス・ポリシーに登録されれば完了です。
2. 参考ドキュメント
公式ドキュメントの「ネイティブ Spark エンジンの概要」以下を参照してください。
以上です。