watsonx.data では、以下のユースケースを実現するために IBM Analytics Engine Spark を使用することが推奨されています。
- 大量のデータのwatsonx.dataテーブルへの取り込み(取り込み前にデータをクレンジングして変換可能)
- watsonx.data テーブルのパフォーマンス向上のためのテーブルのメンテナンス操作
- クエリとして表現するのが難しい複雑な分析ワークロード
「IBM Analytics Engine Sparkからwatsonx.data を操作」ではpythonを使ってwatsonx.dataのテーブルをIBM Analytics Engine instance(Spark)でアクセスする方法について説明します。環境はIBM Cloudです。
IBM Analytics Engine Sparkからwatsonx.data を操作
以下の順序で説明します。この記事は「2. IBM Analytics Engine Spark の構成」です。
1. IBM Analytics Engine Spark インスタンスの作成
2. IBM Analytics Engine Spark の構成
3. Sparkによる処理
下の図が全体像です。この記事は①が②にアクセスするための設定を行います。
[図1: 全体像]

尚、この内容は公式ドキュメントConfiguring Analytics Engine instanceに書かれている内容を環境に合わせる部分を追加して説明しているものです。
0. 前提
- IBM watsonx.dataのインスタンスがあること
- IBM Analytics Engineのインスタンス があること
- ない場合は「1. IBM Analytics Engine Spark インスタンスの作成」を参考に作成してください。
- オブジェクトストレージ(バケット)が1つ以上カタログ・タイプ「Apache Iceberg」でIBM watsonx.dataに登録済みであること(図1の②があること)
1. [前準備1] HiveメタストアURL(HMS URL)とカタログ名の取得
参考: Retrieving Hive metastore(HMS) credentials
-
watsonx.data コンソールにログインします。
-
ナビゲーションメニューから、インフラストラクチャーマネージャーを選択します。
-
Sparkから操作したいwatsonx.data上のバケットと紐づくカタログをクリックします。
尚、カタログ・タイプは「Apache Iceberg」のものを選んでください。
(Apache Hiveは後の「Sparkによる処理」がいろいろソースを変更してもうまくいきませんでした。もしかしたらやり方があるかもしれませんが、判明しませんでしたのて当シリーズは「Apache Iceberg」に限定します。)
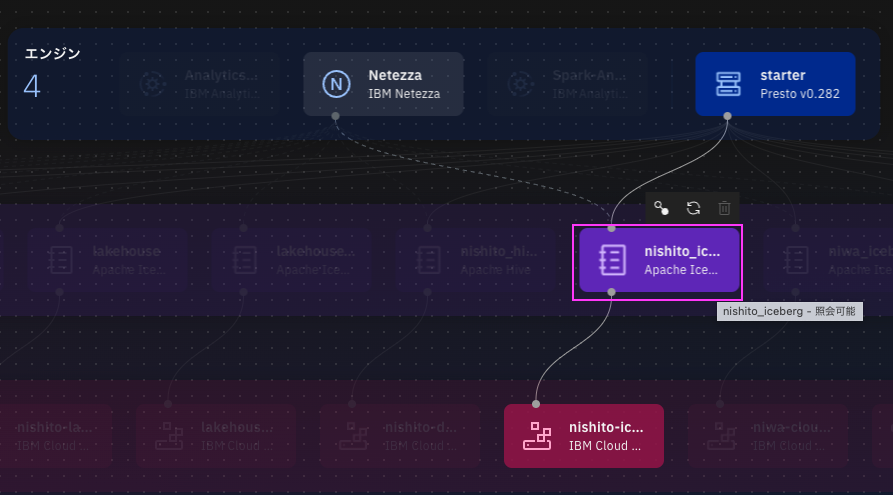
-
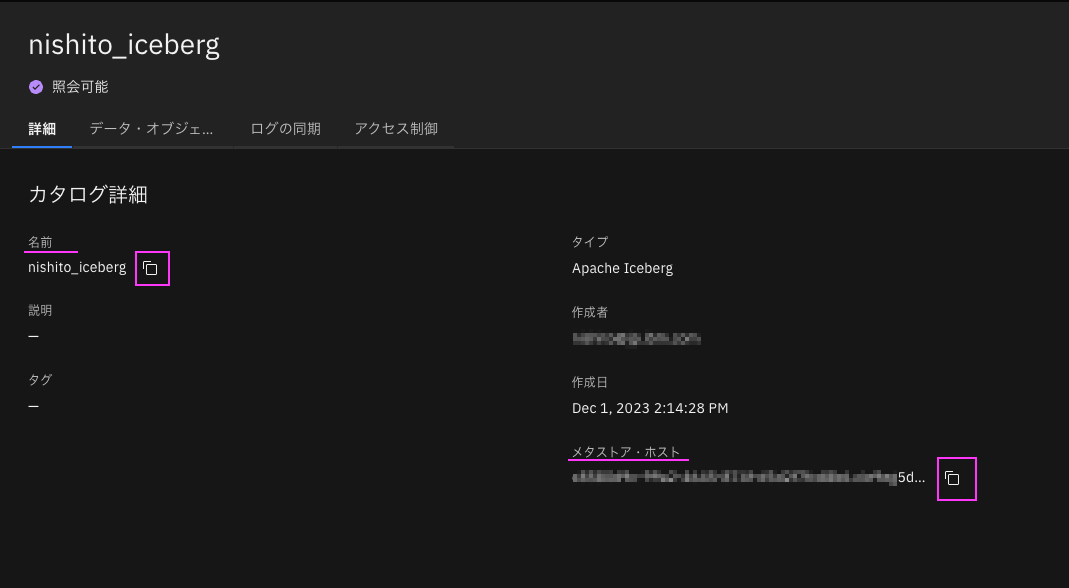
メタストア・ホストと名前ををコピーし、どこかに貼っておきます。
「メタストア・ホスト」が「HMS URL(thrift url)」です。
「名前」が「カタログ名」です。
2. [前準備2] watsonx.data API KEYの取得
以下の方法でAPIKEYを取得してください
3. Analytics Engineインスタンスの設定
1. IBM Cloudにログインし,リソースリストを表示します。
https://cloud.ibm.com/resources
(ログインしていない場合はログイン画面の後、リソースリスト画面になります)
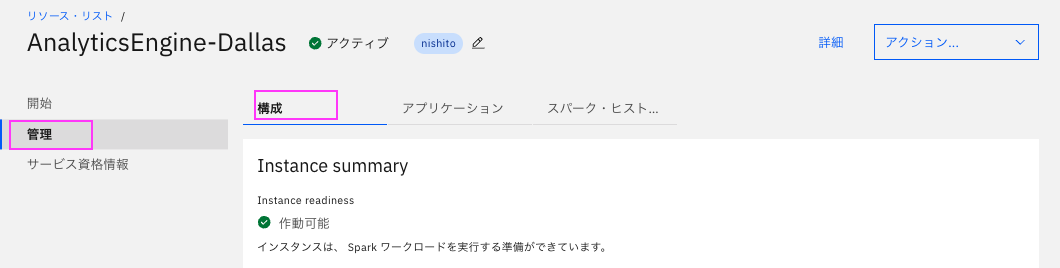
2. 「分析」セクションにあるAnalytics Engineインスタンスの名前をクリックして詳細を表示します。

3. 「管理」 > 「構成」タブ をクリックして構成を表示します。
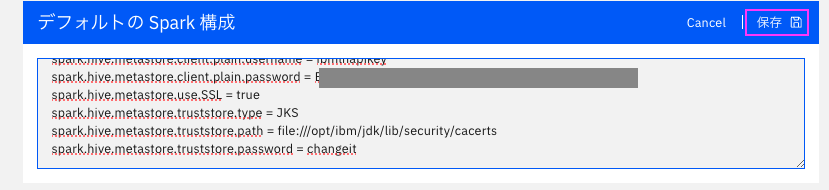
4. スクロールして一番下にある「デフォルトの Spark 構成」セクションで、[Edit] をクリックします。

5. 次の構成をDefault Spark構成セクションに追加します。
以下のパラメータは自分のに情報に変更します。
- Hms-thrift-endpoint-from-watsonx.Data: 前準備1で取得したHMS URL, 先頭に
thrift://を付加 - Hms-user-from-watsonx.Data: APIKEYを使用するので
ibmlhapikey固定値 - Hms-password-from-watsonx.Data: 前準備2で取得したAPIKEY
- <カタログ名>は前準備1で取得したカタログ名に変更します(3カ所)
-
spark.sql.catalog.<カタログ名>
-
spark.sql.catalog.<カタログ名>.type
-
spark.sql.catalog.<カタログ名>.uri
-
例: カタログ名が
nishito_icebergの場合- spark.sql.catalog.nishito_iceberg = org.apache.iceberg.spark.SparkCatalog
- spark.sql.catalog.nishito_iceberg.type = hive
- spark.sql.catalog.nishito_iceberg.uri = thrift://xxx.xxx.xxx.xxx:nnnn
-
尚、もし使用したいカタログが複数ある場合は複数記載しても問題ありません。
-
カタログ名が
xxxx_icebergとyyyy_icebergの場合:- spark.sql.catalog.xxxx_iceberg = org.apache.iceberg.spark.SparkCatalog
- spark.sql.catalog.xxxx_iceberg.type = hive
- spark.sql.catalog.xxxx_iceberg.uri = thrift://xxx.xxx.xxx.xxx:nnnn
- spark.sql.catalog.yyyy_iceberg = org.apache.iceberg.spark.SparkCatalog
- spark.sql.catalog.yyyy_iceberg.type = hive
- spark.sql.catalog.yyyy_iceberg.uri = thrift://xxx.xxx.xxx.xxx:nnnn
-
spark.sql.catalogImplementation = hive
spark.driver.extraClassPath = /opt/ibm/connectors/iceberg-lakehouse/iceberg-3.3.2-1.2.1-hms-4.0.0-shaded.jar
spark.sql.extensions = org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
spark.sql.iceberg.vectorization.enabled = false
spark.sql.catalog.<カタログ名> = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.<カタログ名>.type = hive
spark.sql.catalog.<カタログ名>.uri = <前準備1で取得したHMS URL, 先頭に`thrift://`を付加> 例: thrift://81823aaf-8a88-4bee-a0a1-6e76a42dc833.cfjag3sf0s5o87astjo0.databases.appdomain.cloud:32683
spark.hive.metastore.client.auth.mode = PLAIN
spark.hive.metastore.client.plain.username = ibmlhapikey
spark.hive.metastore.client.plain.password = <前準備2で取得したAPIKEY>
spark.hive.metastore.use.SSL = true
spark.hive.metastore.truststore.type = JKS
spark.hive.metastore.truststore.path = file:///opt/ibm/jdk/lib/security/cacerts
spark.hive.metastore.truststore.password = changeit
セットしたら、「保存」をクリック
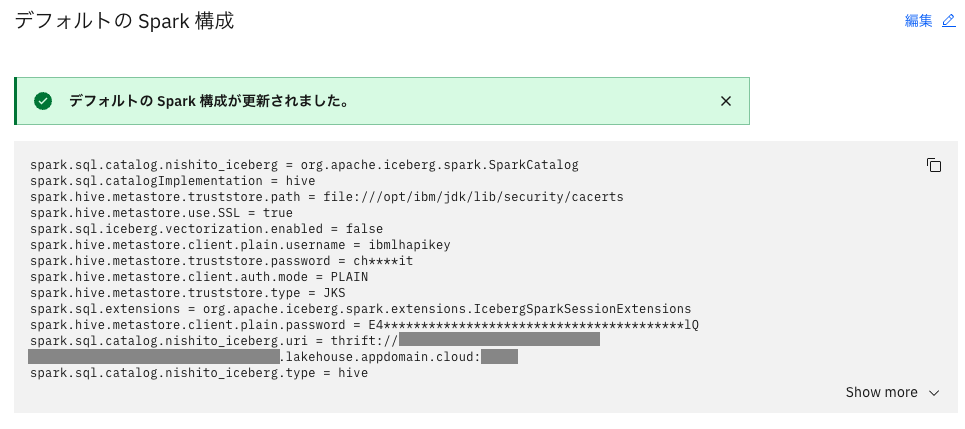
これでIBM Analytics Engine Spark の構成が完了しました!
NEXT
「3. Sparkによる処理」に進みましょう!