IBMのAutoAIのチュートリアルIBM Watson Studio AutoAI: Modeling for the rest of usの日本語解説 #1です。
(2020年6月17日更新)
このページでは
- Tutorial
- Creating a project
- Add a Watson Machine Learning service to the project
- Creating an AutoAI model for binary classification
までをカバーします。
それ以後は以下を参照してください:
-
- Create an AutoAI model for regression
-
- Accessing a model through a notebook
- Summary
0. 事前準備
IBM Watson Studio AutoAI: Modeling for the rest of usには書いてありませんが、Watson Studio サービスの作成が必要です。
Watson Studio サービスとProjectの作成のを実施の上、Watson Studio サービスとProjectを作成してください。
尚、3.3で作成するProjectの名前はチュートリアル上、Tutorialとなっていますので、チュートリアル通りに作りたい方はこの名前でなるべく作成してください(違う名前でもOKです)。
Tutorial: チュートリアル
モデルを手動で作成することは困難です。 特定のケースに最適な候補アルゴリズムを見つけることから始まります。 適切なアルゴリズムをすべて知っていますか? 次に、数値以外のフィールドを数値に変換してデータを準備する必要があります。 追加の特徴量最適化を行う必要がありますか? 選択した各アルゴリズムのすべてのハイパーパラメーターをどのように調整しますか?
AutoAIはこれらすべてのステップを処理し、ランク付けされた一連のモデルから選択します。 すべての詳細が提供されるため、最適なモデルの選択が容易になり、ビジネスソリューションの実装を進めることができます。
このチュートリアルでは、次の主要な機能について探っていきます:
- 多くのアルゴリズムがビジネス上の問題に適合する可能性があります
- モデルの作成には、追加の特徴量最適化が必要になる場合があります
- モデルの作成にはハイパーパラメーターの調整が必要です
- AutoAIはモデル作成の複雑さを取り除きます
1. Create a new project: プロジェクトの作成
0. 事前準備 で作成済みなので、ここは完了です。
2. Add a Watson Machine Learning service to the project: Watson Machine LearningサービスのProjectへの追加
AutoAIを使用する前に、プロジェクトにWatson Machine Learningサービスが必要です。
複数のプランが利用可能です。このラボでは、必要な機能を無料で提供するライトプランを使用します。
1. プロジェクト画面の上部にある設定タブを選択します。
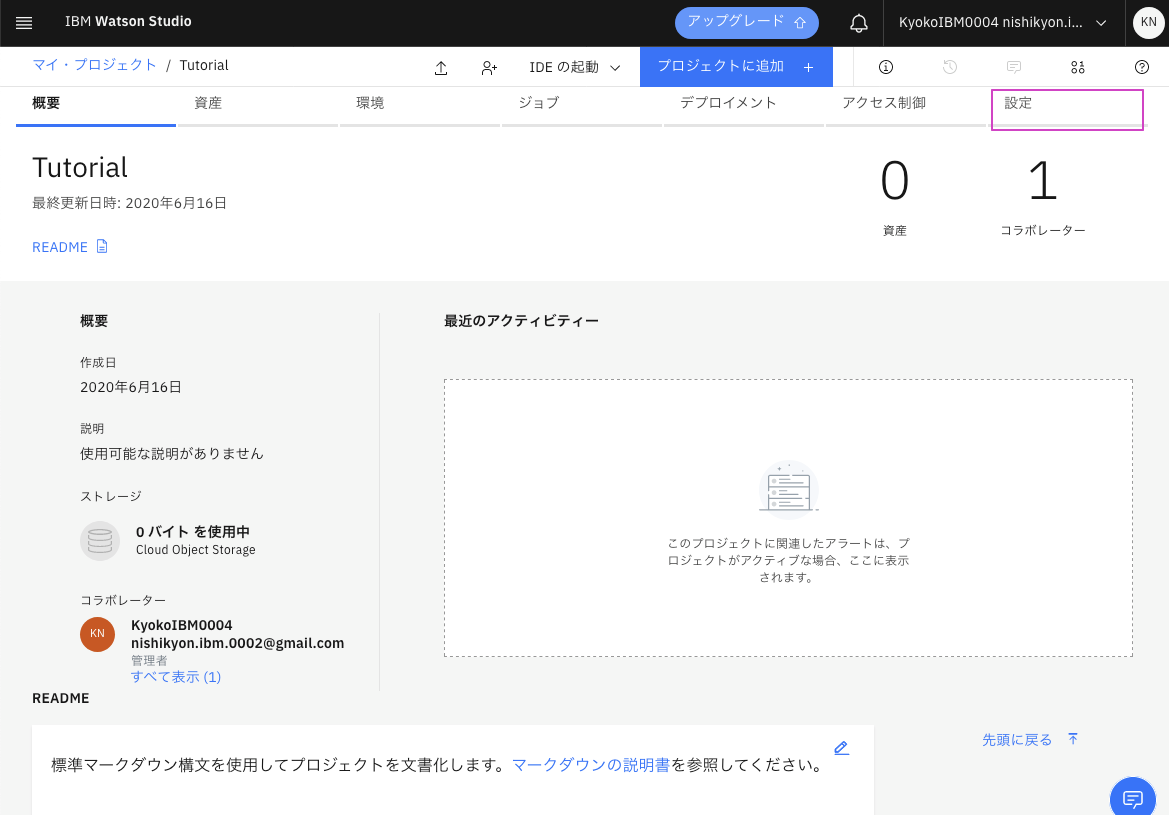
2. 関連サービス セクションまでスクロールします。
3. Machine Learningサービスがない場合は、サービスの追加をクリックし、Watsonを選択してから、Machine Learningの「Add」をクリックします。
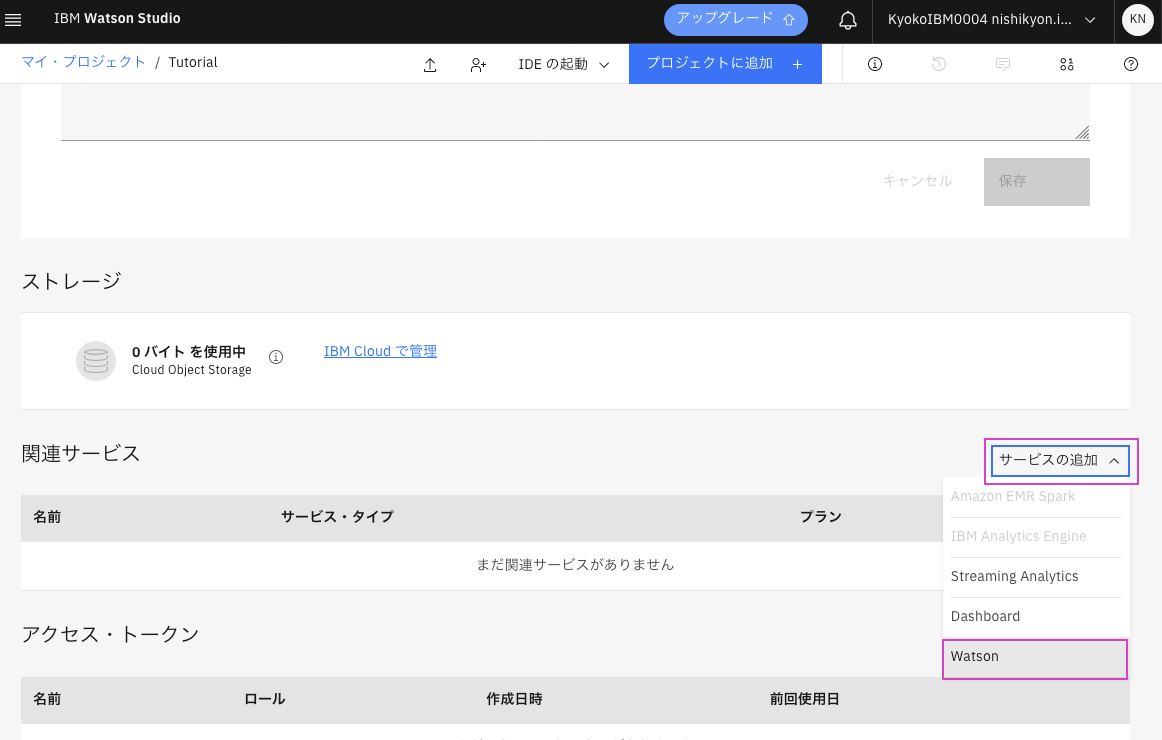
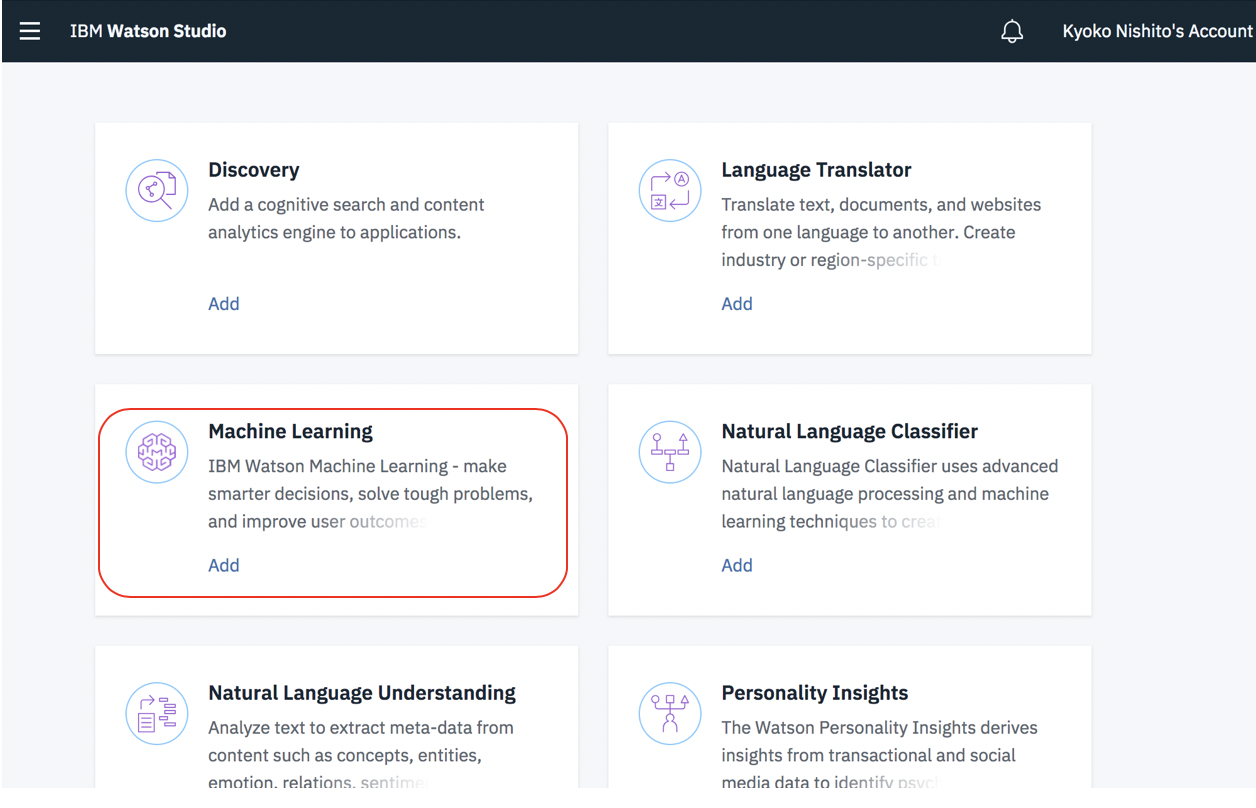
4A: [New]のタブが選択された画面が表示された場合
- スクロールしてPLANでLiteが選択されていることを確認して一番下の[Create]をクリック 。

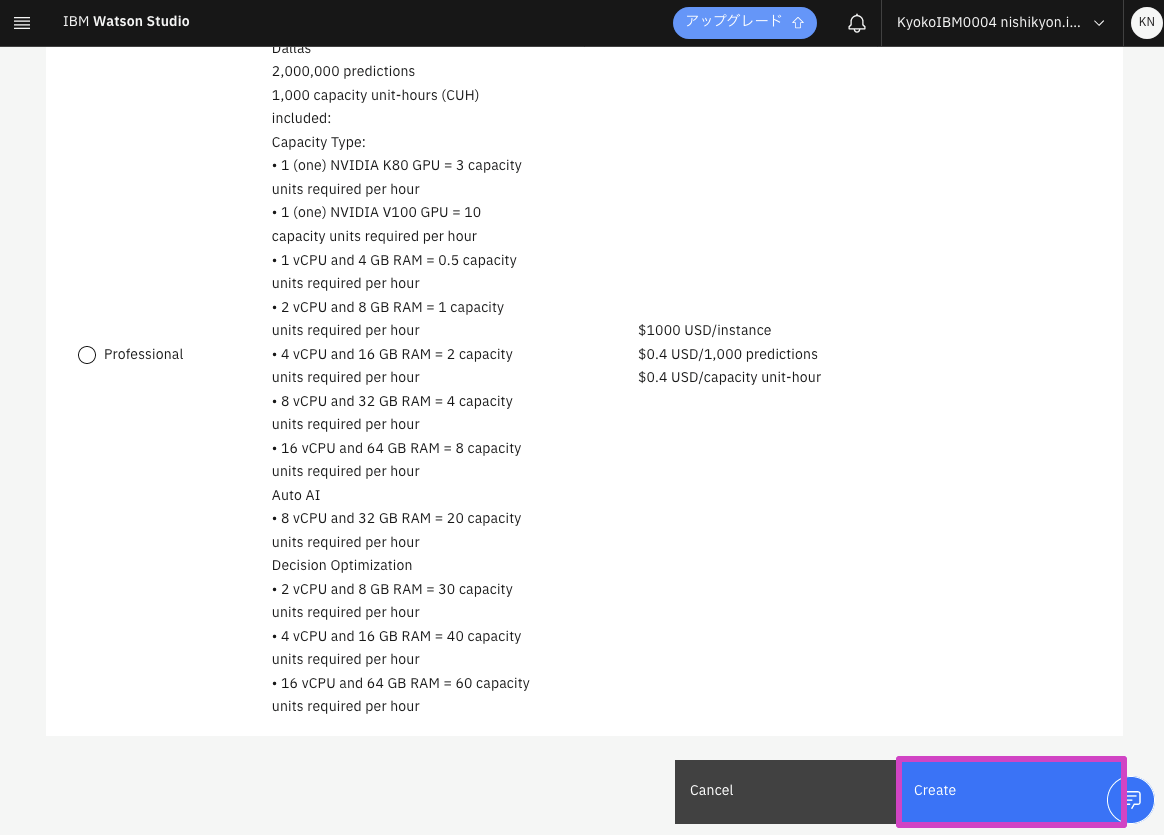
- Confirmの画面でRegionがDallasになっていることを確認して[Confirm]をクリック
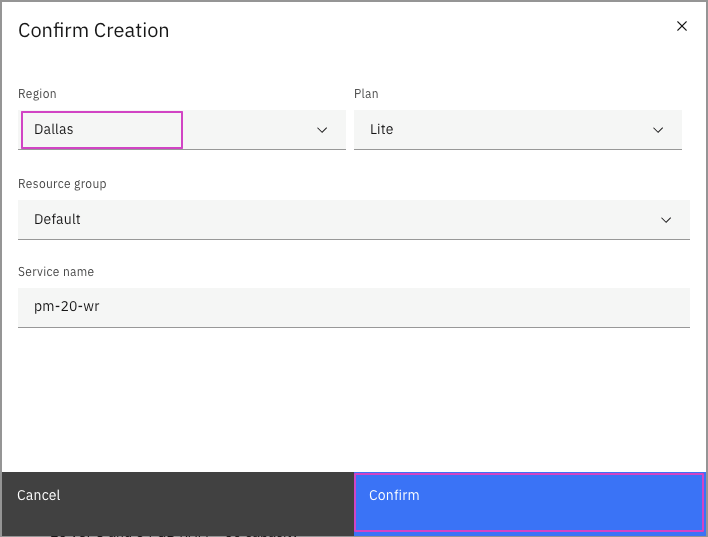
4B: [Existing]のタブが選択された画面が表示された場合
Existing Service Instance のドロップダウンから、使用するMachine Learningのサービスを選択して[Select]をクリック 。
5. 設定 の画面に戻ります。
関連サービスに追加したサービスのインスタンスが追加されていることを確認します。

モデルの作成を開始する準備が整いました。
3. Creating an AutoAI model for binary classification: 2値分類用のAutoAIモデルの作成
このセクションでは、AutoAIを使用して2値分類モードを作成します。
このために、架空の電話会社の顧客記録を使用します。
AutoAIを使用して最適なモデルを生成します。 次に、IBM Watson Studio環境を使用してモデルでデータをを予測(評価)しようとする前に、モデルを保存してデプロイします。
1. 解約データを追加して、モデルをトレーニングします。
データファイルcustomer_churn.csvはここにあります。 ファイルをワークステーションにダウンロードします。
プロジェクトの右側のデータウィンドウは、データをロードする準備ができています。 ウィンドウにcustomer_churn.csvファイルをドロップするか、参照オプションを使用してマシン上のファイルを見つけます。
ウィンドウが開いていない場合は、画面の右上にある次のアイコンをクリックしてください。

2. 画面の右上にあるプロジェクトに追加をクリックします。

3. AutoAI 実験をクリックします。
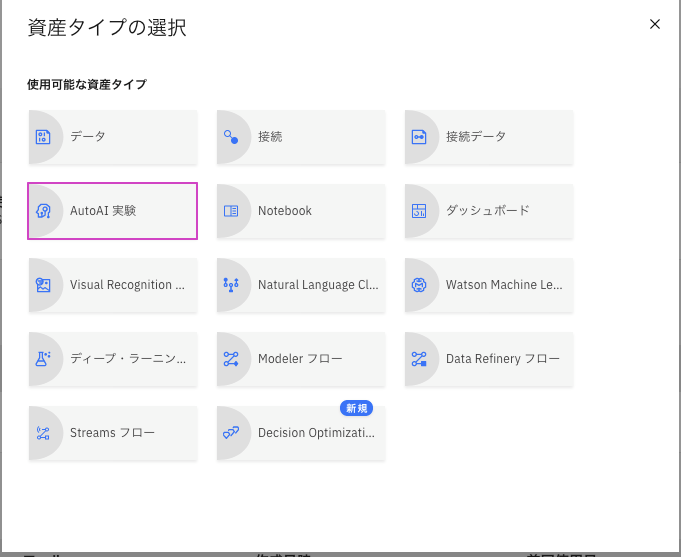
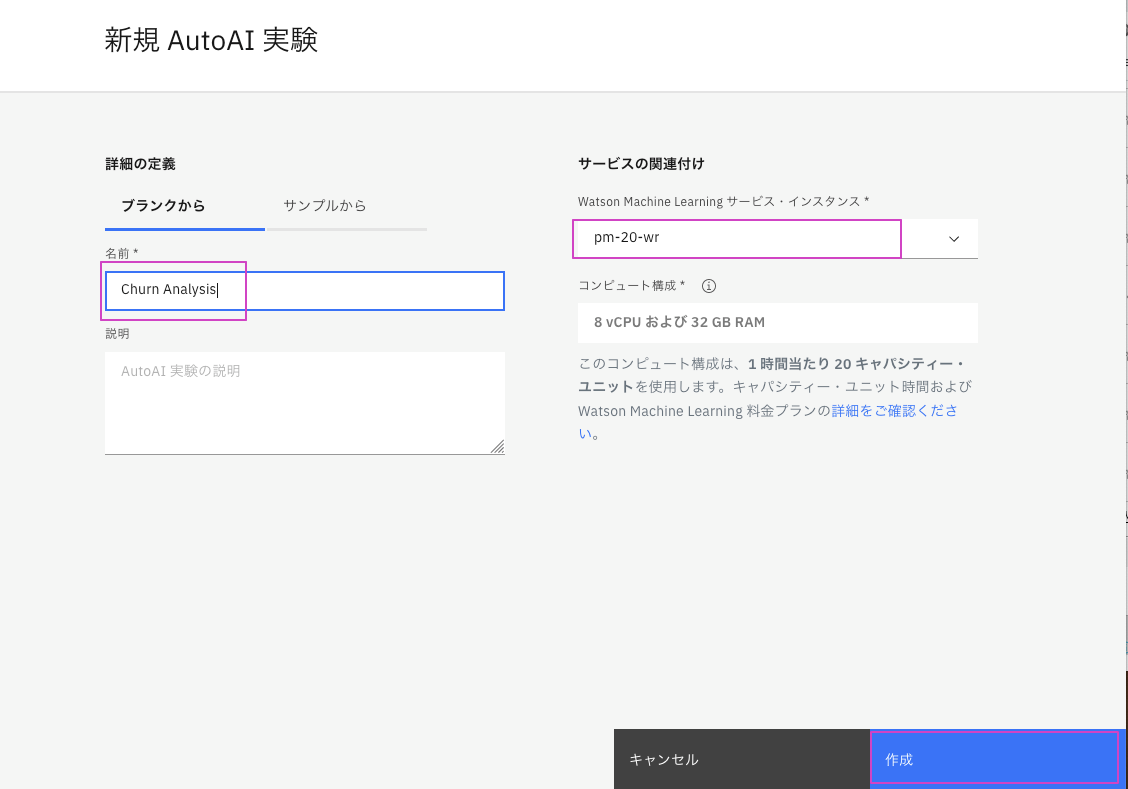
モデルにChurn Analysisという名前を付けます。
機械学習サービスが選択されていることを確認してください。
[作成]をクリックします。
4. 入力データの選択
-
プロジェクトから選択をクリックします。 -
customer_churn.csvにチェックします。 -
資産の選択をクリックします。
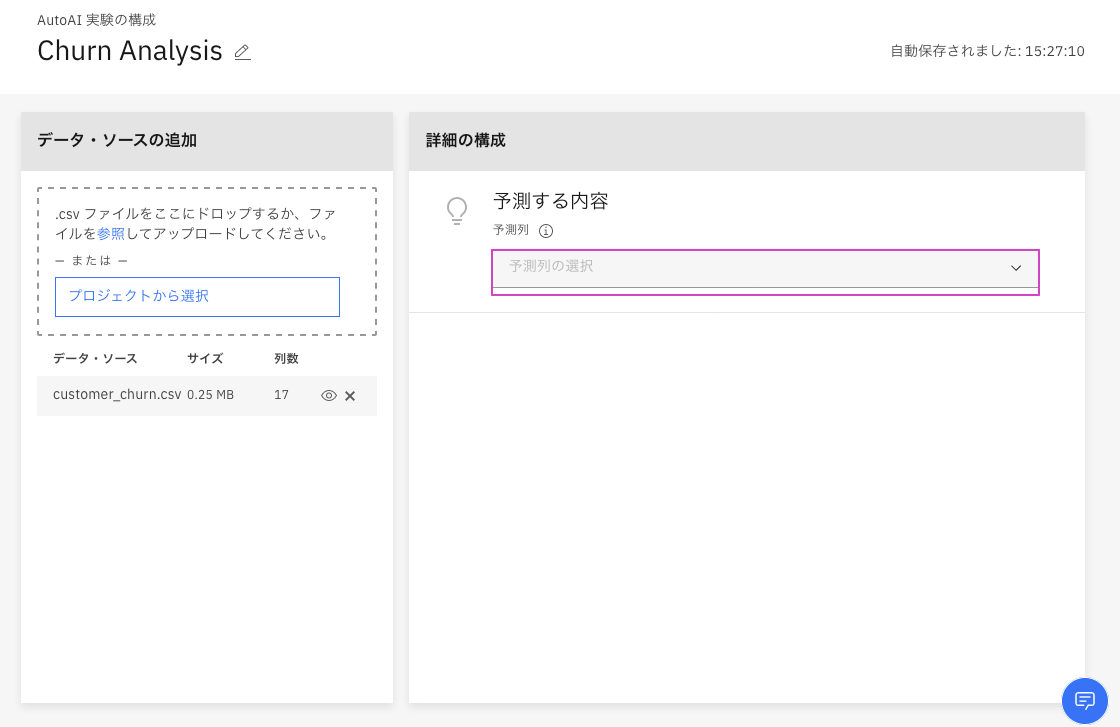
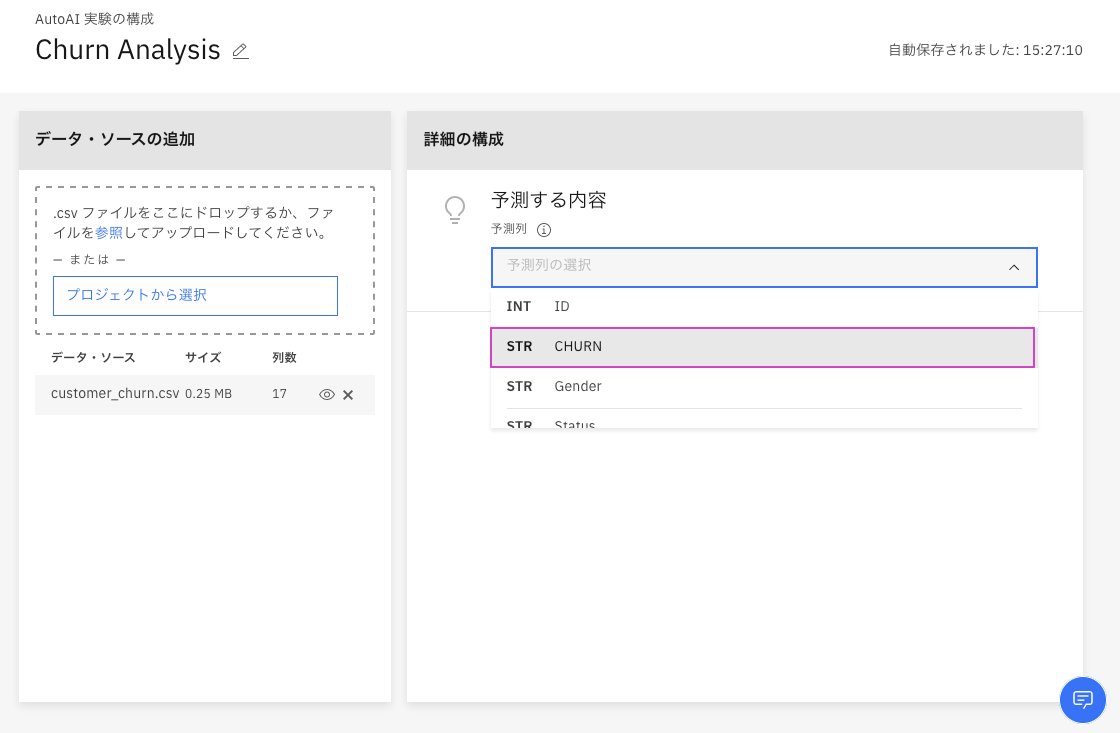
5. 予測する列を選択して、作成プロセスを開始します。
- 「予測列の選択」から列名
CHURNをクリックします。
-
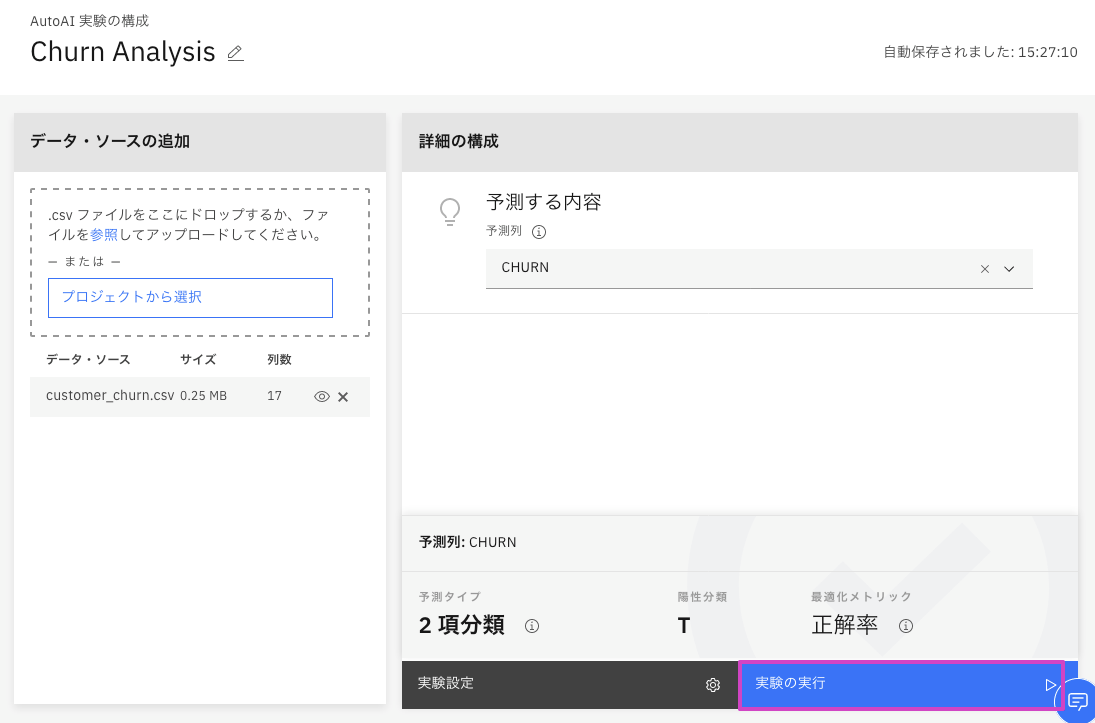
実験の実行をクリックします。
実行は複数のステップを経て、8つのモデルを生成します。 このプロセスには8〜10分かかります。
6. 最上位のモデルの特性を調べます。
番号1のパイプラインをクリックします。
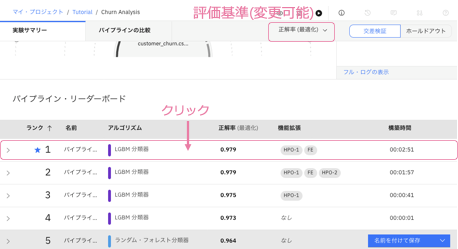
モデル評価、混同⾏列、PR曲線、モデル情報、特徴量の重要度など、
さまざまなメトリックを確認できます。
確認後、画⾯の左上にあるChurn Analysisに戻るをクリックします。
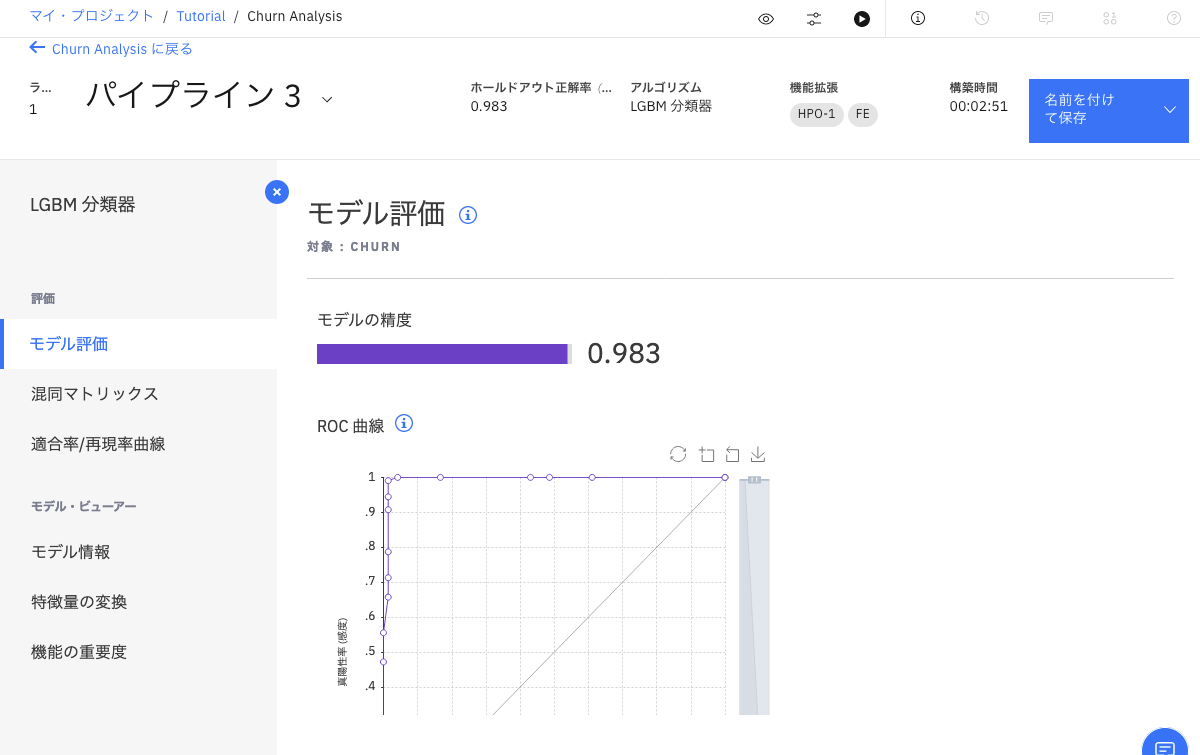
(機能の重要度=特徴量の重要度)
7. ⼀番評価の⾼いモデルを保存します。
-
⼀番上のモデルの⾏にマウスカーソルを合わせると
名前を付けて保存と
いうボタンが表⽰されるので、それをクリックします。
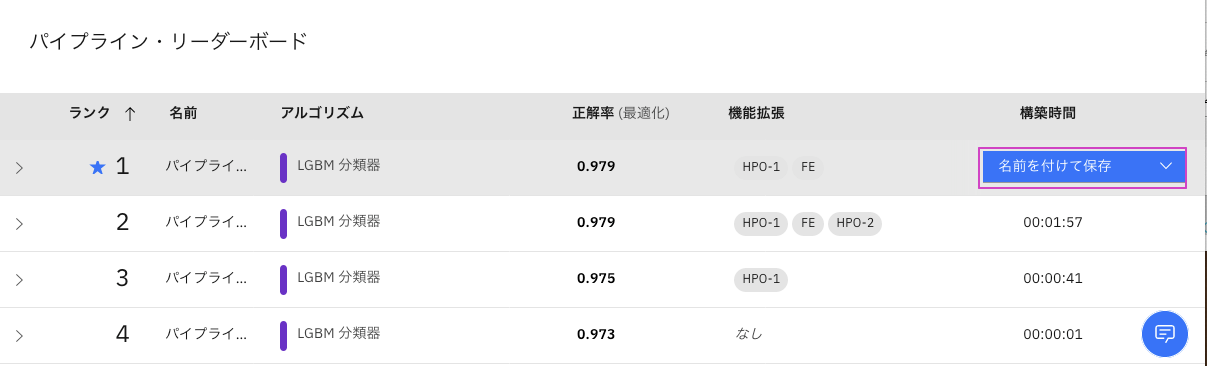
-
ドロップダウンに表示された
モデルをクリックします。
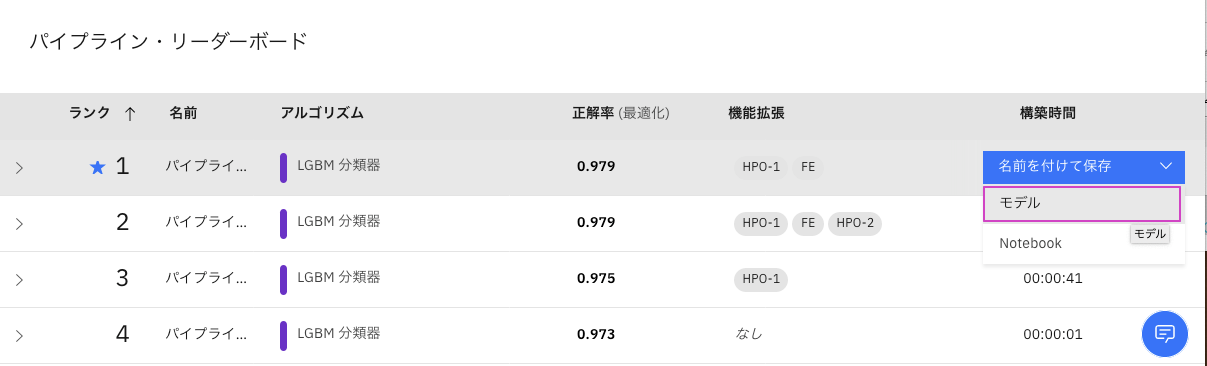
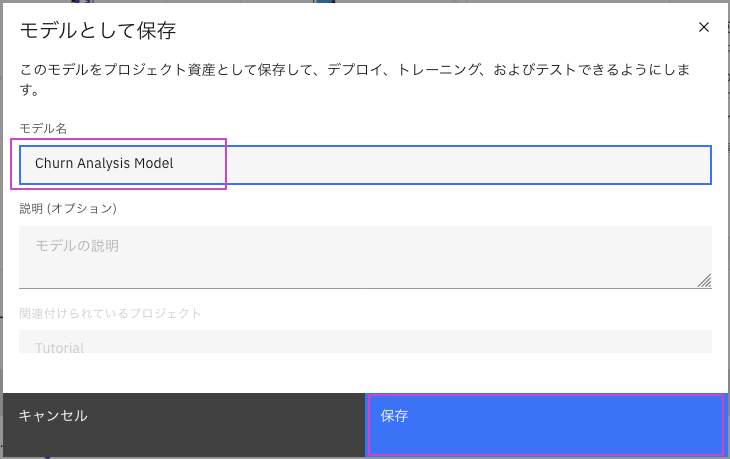
-
モデル名を
Churn Analysis Modelに変更します。
オプション説明を入力します。 -
保存をクリックします。
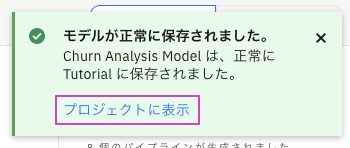
- 画面の右上にある'プロジェクトに表示'をクリックします。
8. モデルのDeploy
-
デプロイメントタブをクリックします。
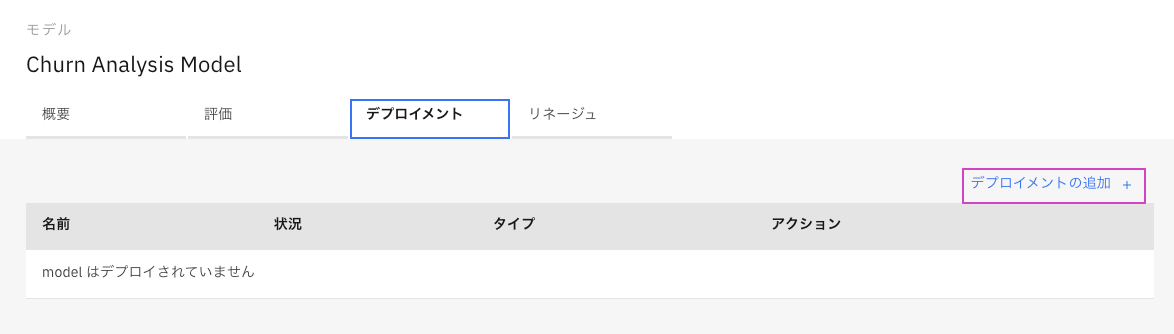
-
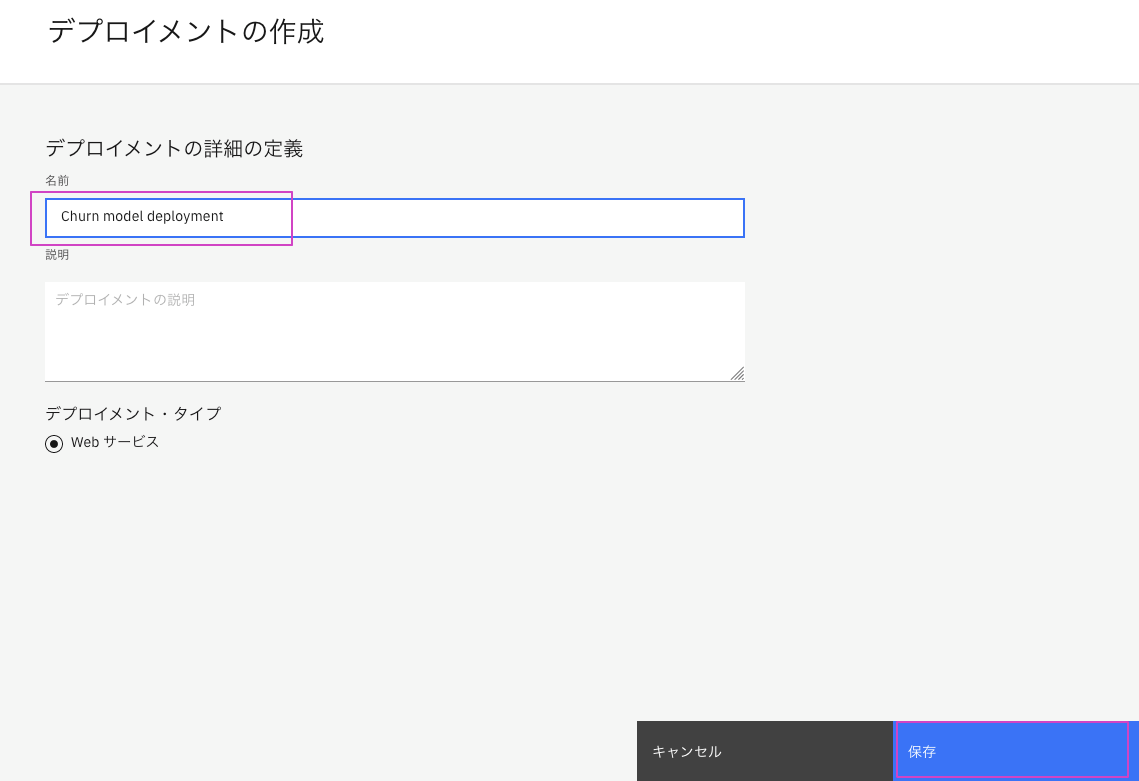
右側の`デプロイメントの追加'をクリックします。
-
名前に
Churn model deploymentと⼊⼒後、保存ボタンをクリックします。
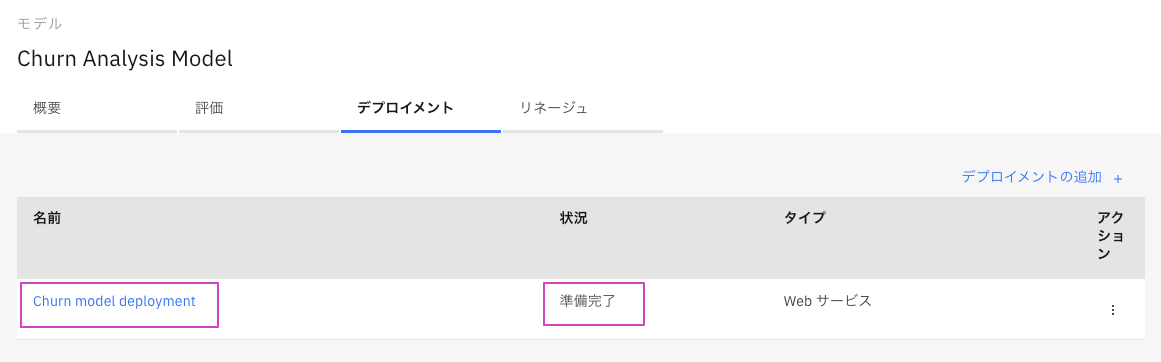
デプロイメントタブに⾃動で戻ります。状況は初期化中から準備完了に変わります。
1分待っても変わらない場合はリロードしてみてください。
9. JSONレコードでモデルをテスト
-
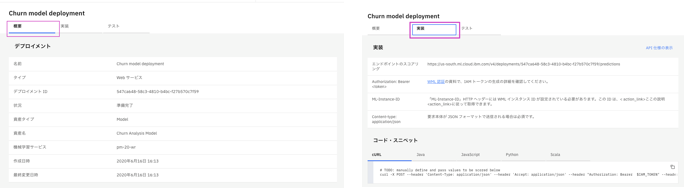
Churn model deploymentをクリックします。
概要タブでデプロイメントの詳細を確認できます。
実装タブをクリックします。そのタブの下に、スコアリングエンドポイントが表⽰され、Java、JavaScript、Pythonなどの5つの⾔語のコードスニペットも提供されます。
-
テストタブをクリックします。そのままフォームでデータを⼊れてもできますが、今回はJSON inputアイコンをクリックして、JSONで⼊⼒します。
-
以下のデータを⼊⼒エリアにコピー&ペーストしてください。
(日本語訳注:customer_churn.csvの2行目の値です)
{"input_data":
[{
"fields": [ "ID", "Gender", "Status", "Children", "Est Income", "Car Owner",
"Age", "LongDistance", "International", "Local", "Dropped",
"Paymethod", "LocalBilltype", "LongDistanceBilltype",
"Usage", "RatePlan"
],
"values": [[ 6, "M", "M", 2, 29616, "N",
49.42, 29.78, 0, 45.5, 0,
"CH", "FreeLocal", "Standard",
75.29, 2
]]
}]
}
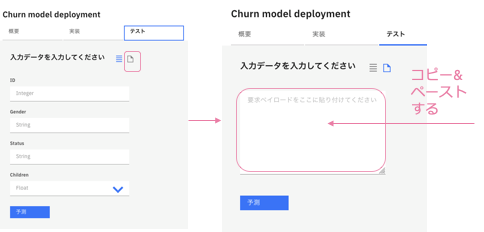
-
予測ボタンをクリックします。
右側に予測結果が表⽰されます。
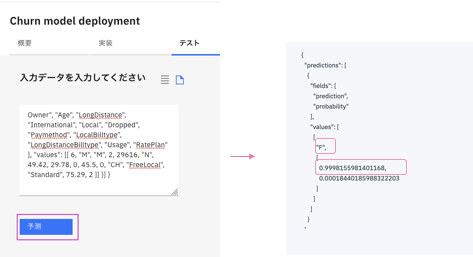
{
"fields": [
"prediction",
"probability"
],
"values": [
[
"F",
[
0.9999555620264015,
0.00004443797359858176
]
]
]
}
]
}
画面の左上にあるプロジェクト名をクリックすると、チュートリアルプロジェクトに戻ることができます。

Next Step
IBM Watson Studio AutoAI: Modeling for the rest of us 日本語解説 #2に続きます。