IBMのAutoAIのチュートリアルIBM Watson Studio AutoAI: Modeling for the rest of usの日本語解説 #2です。
このページでは
- Create an AutoAI model for regression
をカバーします。
それ以前と以後は以下を参照してください:
-
- Tutorial
- Creating a project
- Add a Watson Machine Learning service to the project
- Creating an AutoAI model for binary classification
-
- Accessing a model through a notebook
- Summary
0. 事前準備
が完了していることが前提です。
4. Create an AutoAI model for regression: 回帰用のAutoAIモデルの作成
前のタスクでは、AutoAIを使用して2値分類モデルを作成する方法を確認しました。 このセクションでは、同様のプロセスを実行しますが、今回は回帰モデルを作成します。
回帰モデルは、連続値のスコアリングを提供します。 私たちの場合、1970年代のボストン周辺の住宅価格に関するデータを使用します。 kaggleサイトでこのデータの詳細を確認できます。
データ属性は次のとおりです。
| Name | Description |
|---|---|
| CRIM | 町ごとの一人当たり犯罪率 |
| ZN | 25,000平方フィートを超える区画に区画化された住宅地の割合 |
| INDUS | 町ごとの非小売業の土地の割合 |
| CHAS | チャールズリバーのダミー変数(=河川の境界線の場合は1、それ以外の場合は0) |
| NOX | 一酸化窒素濃度(1000万分の1) |
| RM | 住居あたりの平均部屋数 |
| AGE | 1940年以前に建設された持ち主自身が住んでいるユニットの割合 |
| DIS | 5つのボストンの雇用センターへの加重距離 |
| RAD | 放射状高速道路へのアクセシビリティのインデックス |
| TAX | 10,000ドルごとの固定資産税率 |
| PTRATIO | 町ごとの生徒と教師の比率 |
| B | 1000(Bk-0.63)^ 2、Bkは町ごとの黒人の割合です |
| LSTAT | 人口の低い割合 |
| MEDV | $の1000年代の持家住宅の中央値 |
予測する値はMEDVです。
1. ボストンの住宅価格データを追加して、モデルをトレーニングします。
データファイルboston_house_prices.csvはここにあります。 ファイルをワークステーションにダウンロードします。
プロジェクトの右側のデータウィンドウは、データをロードする準備ができています。 ウィンドウにboston_house_prices.csvファイルをドロップするか、browseオプションを使用してマシン上のファイルを見つけます。
ウィンドウが開いていない場合は、画面の右上にある次のアイコンをクリックしてください。

2. 画面の右上にあるプロジェクトに追加をクリックします。

3. AutoAI experimentをクリックします。
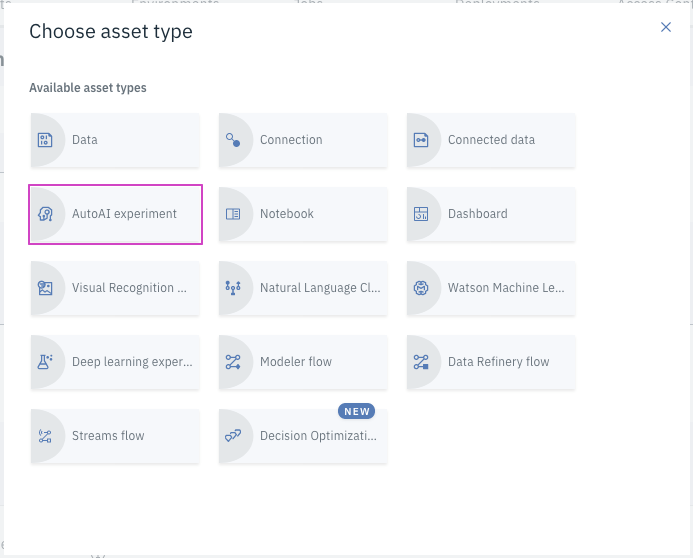
モデルにHouse Prices Analysisという名前を付けます。
機械学習サービスが選択されていることを確認してください。
Createをクリックします。
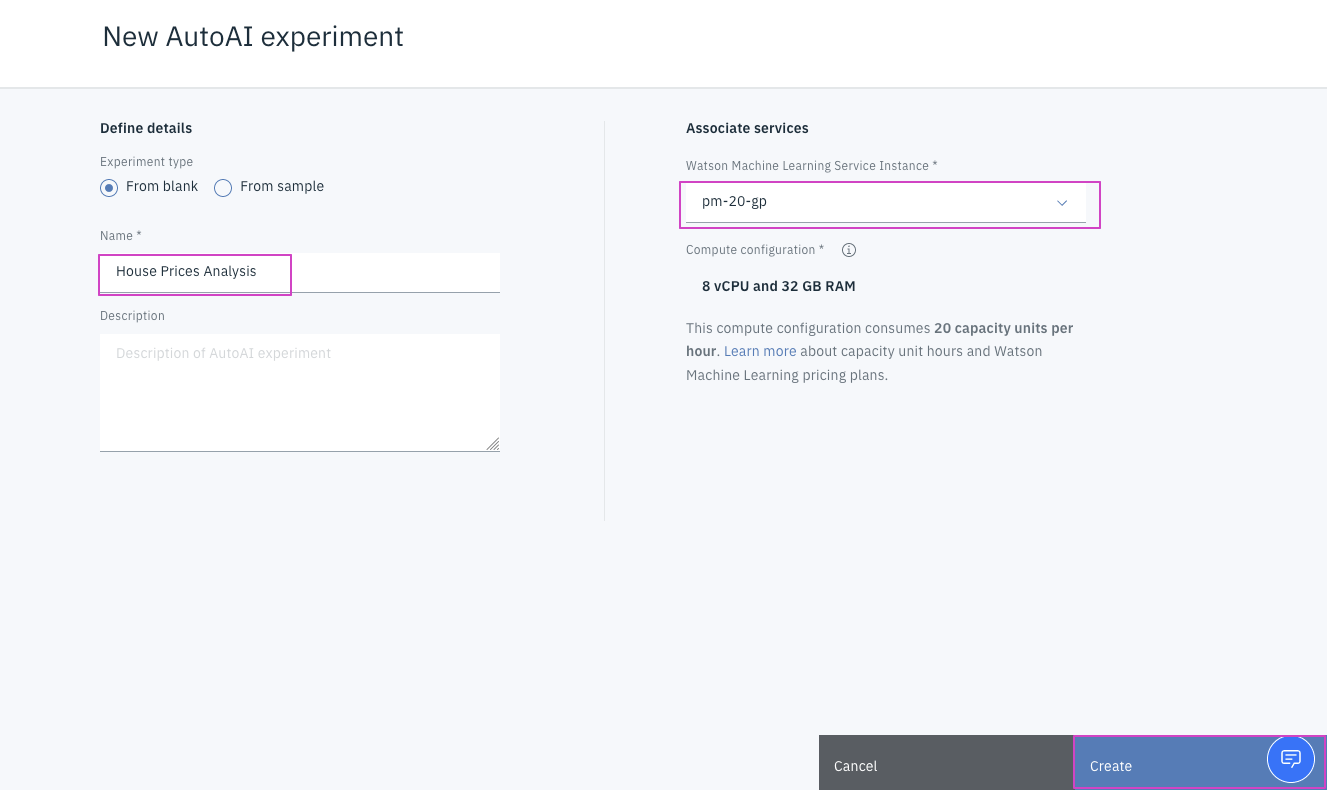
4. 入力データの選択
-
Select from projectをクリックします。 -
boston_house_prices.csvをクリックします。 -
Select assetをクリックします。
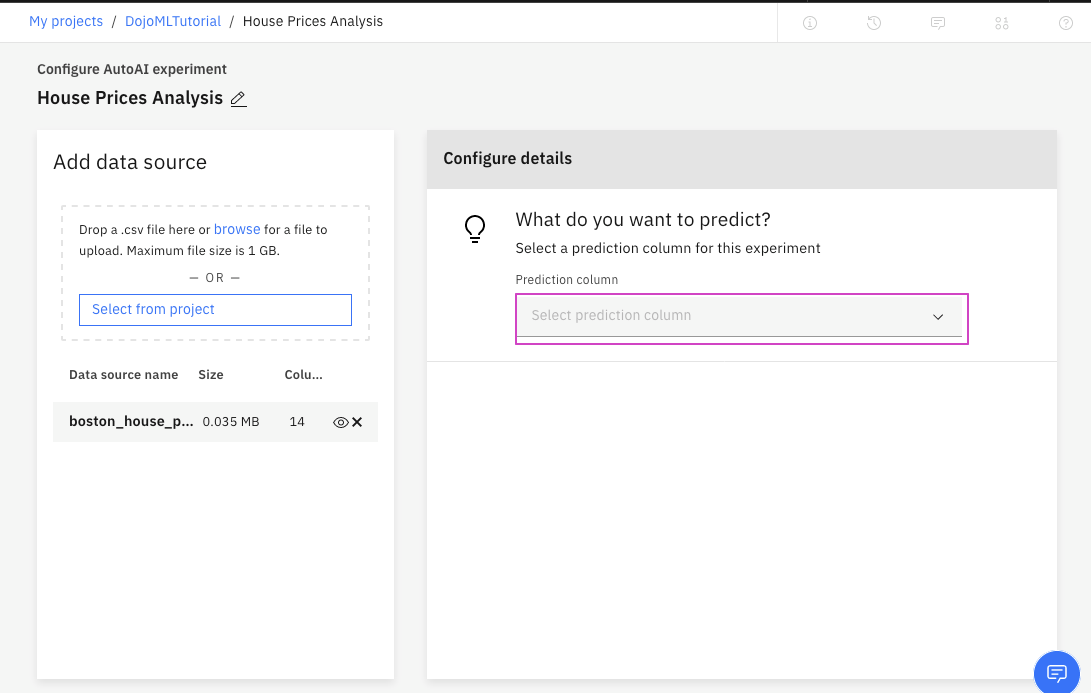
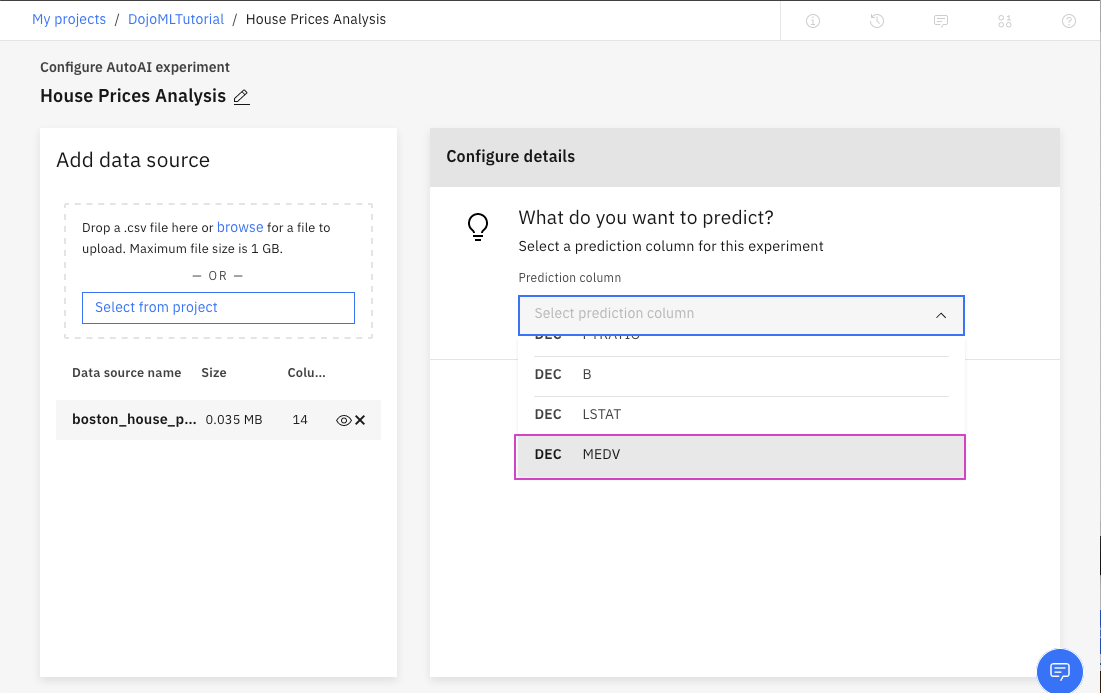
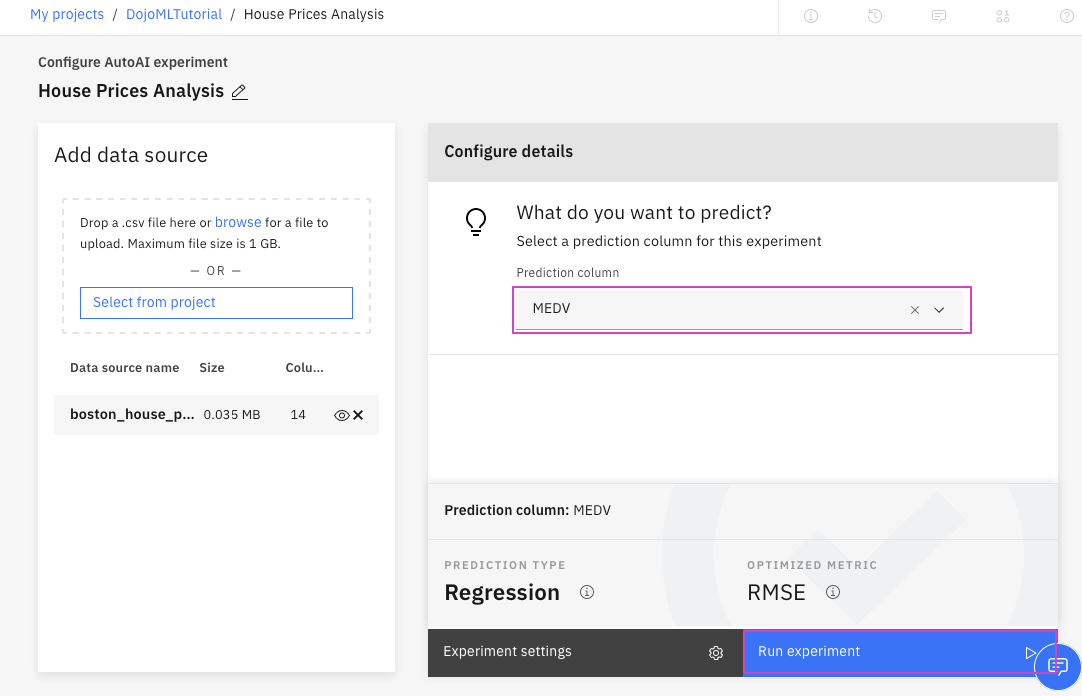
5. 予測する列を選択して、作成プロセスを開始します。
- 「Prediction column」から列名
MEDVをクリックします。 - AutoAIは、連続値を含む10進値であることを検出し、回帰(Regression)モデルを選択することに注意してください。
-
Run experimentをクリックします。
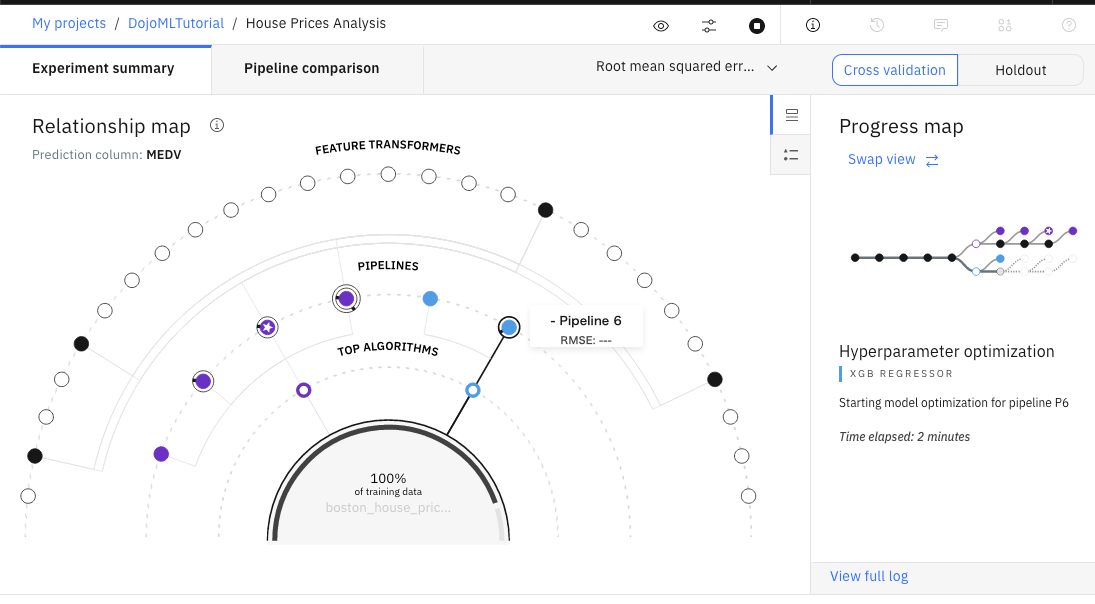
実行は複数のステップを経て、8つのモデルを生成します。 このプロセスには3〜5分かかります。
6. 最上位のモデルの特性を調べます。
番号1のパイプラインをクリックします。
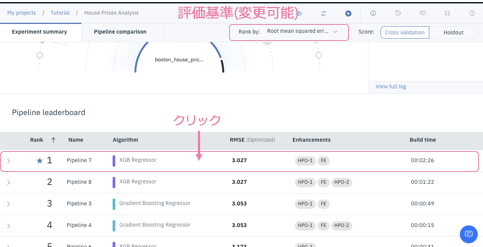
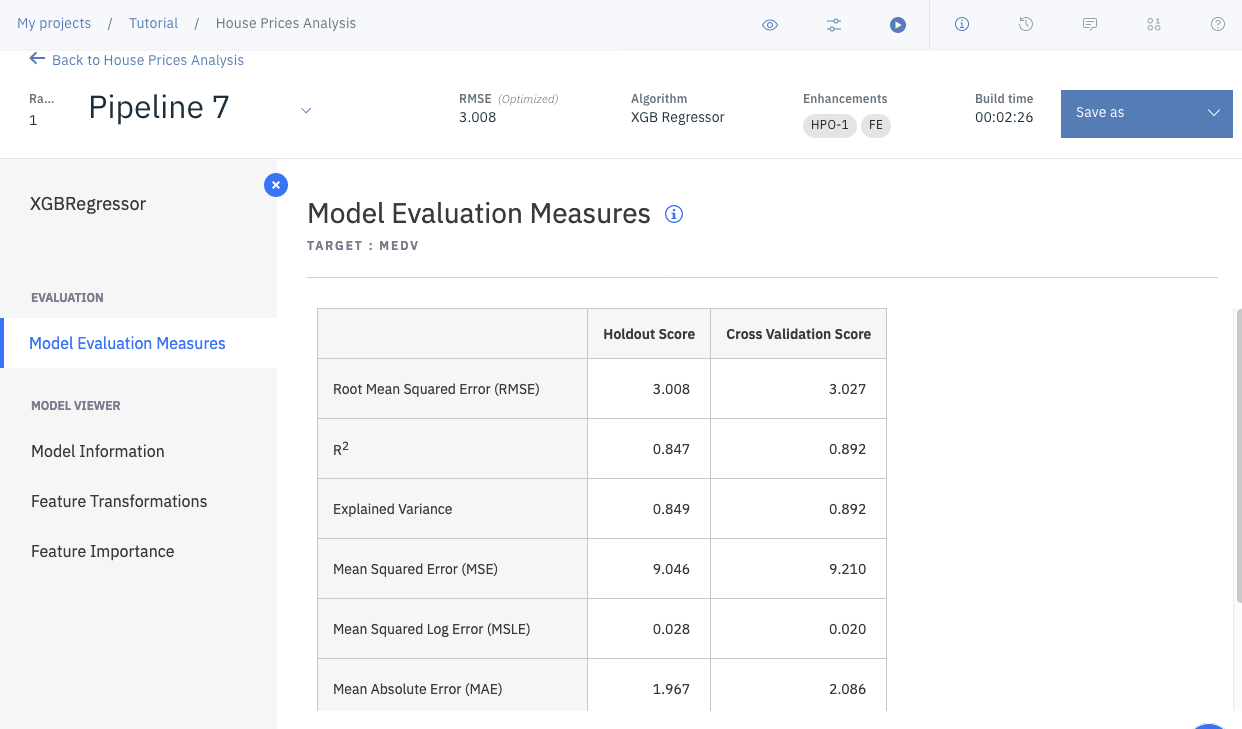
さまざまなメトリックを確認できます。
回帰モデルの場合、含まれる情報はモデル評価指標とモデル情報です。
確認後、画⾯の左上にあるBack to House Prices Analysisをクリックします。
7. ⼀番評価の⾼いモデルを保存します。
-
⼀番上のモデルの⾏にマウスカーソルを合わせると
Save asと
いうボタンが表⽰されるので、それをクリックします。
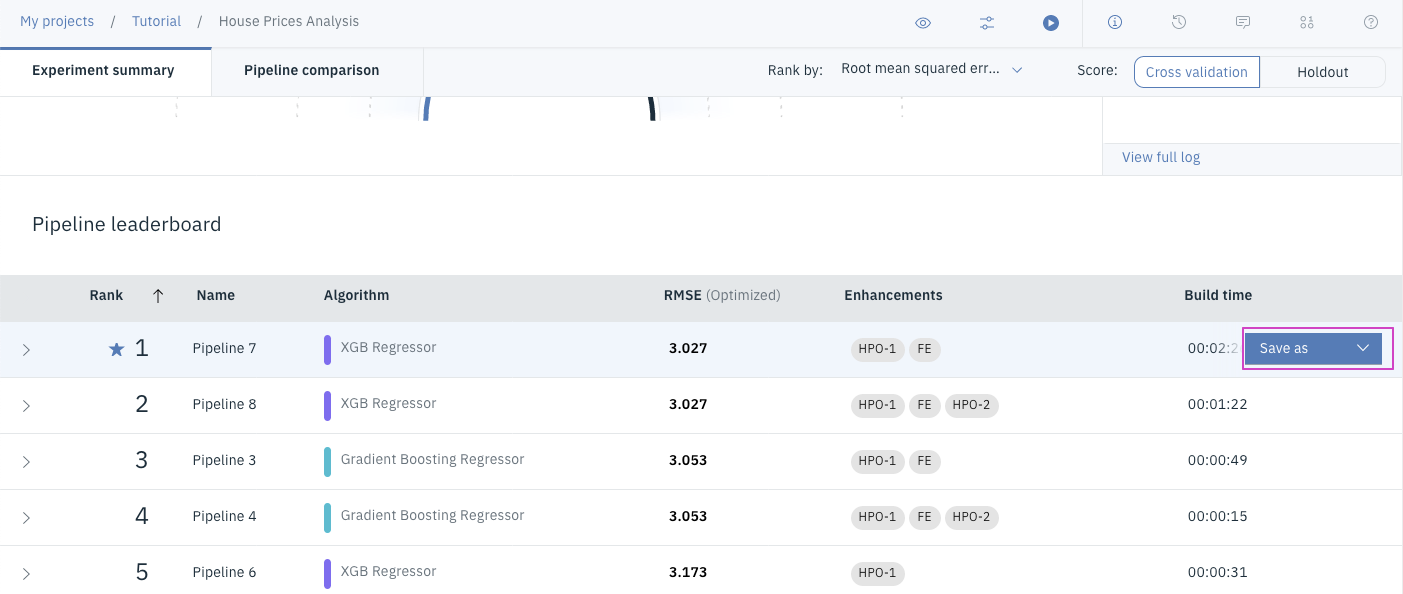
-
ドロップダウンに表示された
Modelをクリックします。
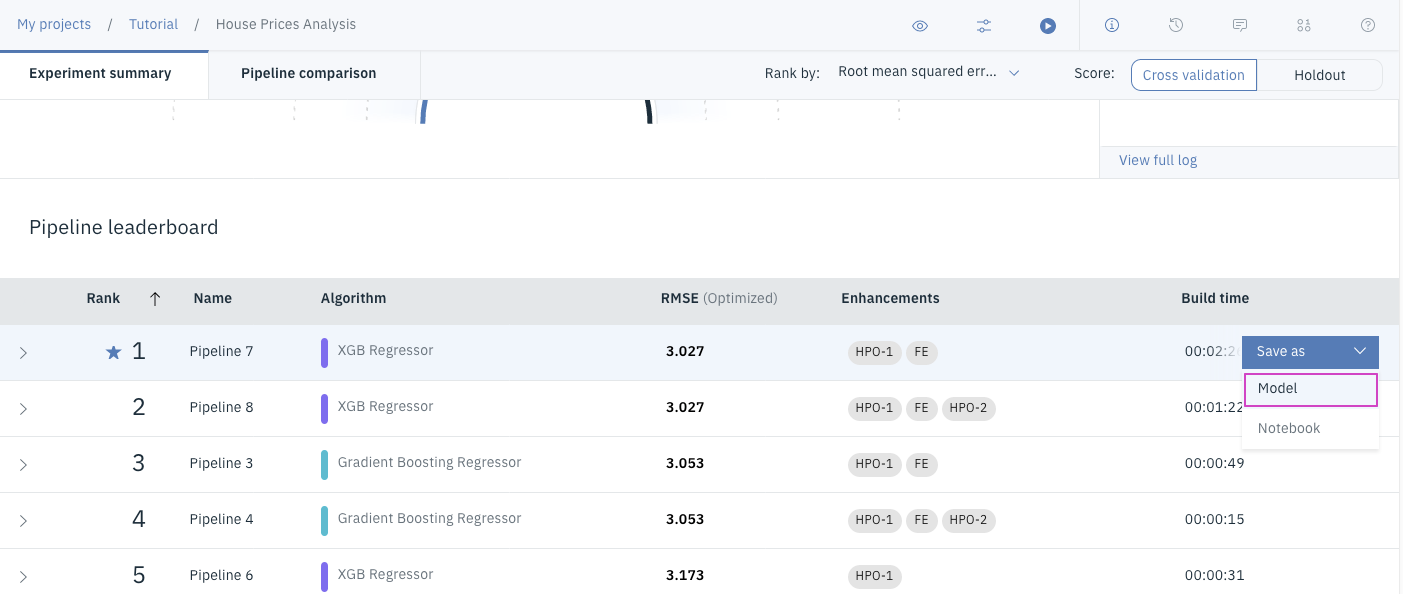
-
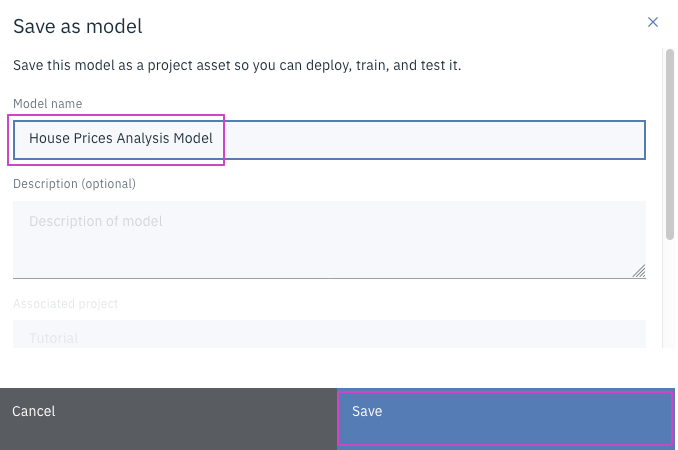
Model Nameを
House Prices Analysis Modelに変更します。
オプションで、Descriptionを入力します。 -
Saveをクリックします。
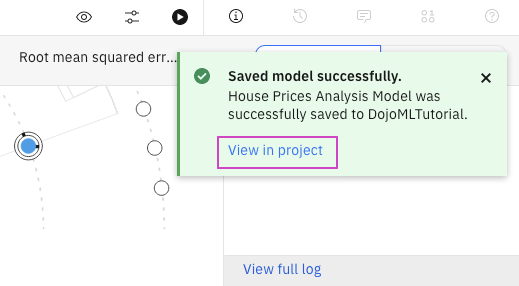
- 画面の右上にある'View in project'をクリックします。
8. モデルのDeploy
-
Deploymentsタブをクリックします。
-
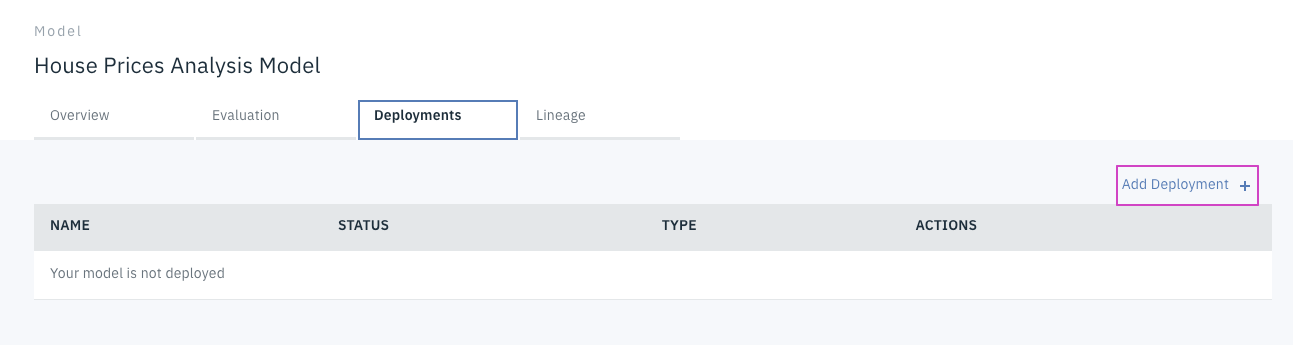
右側の
Add Deploymentをクリックします。
-
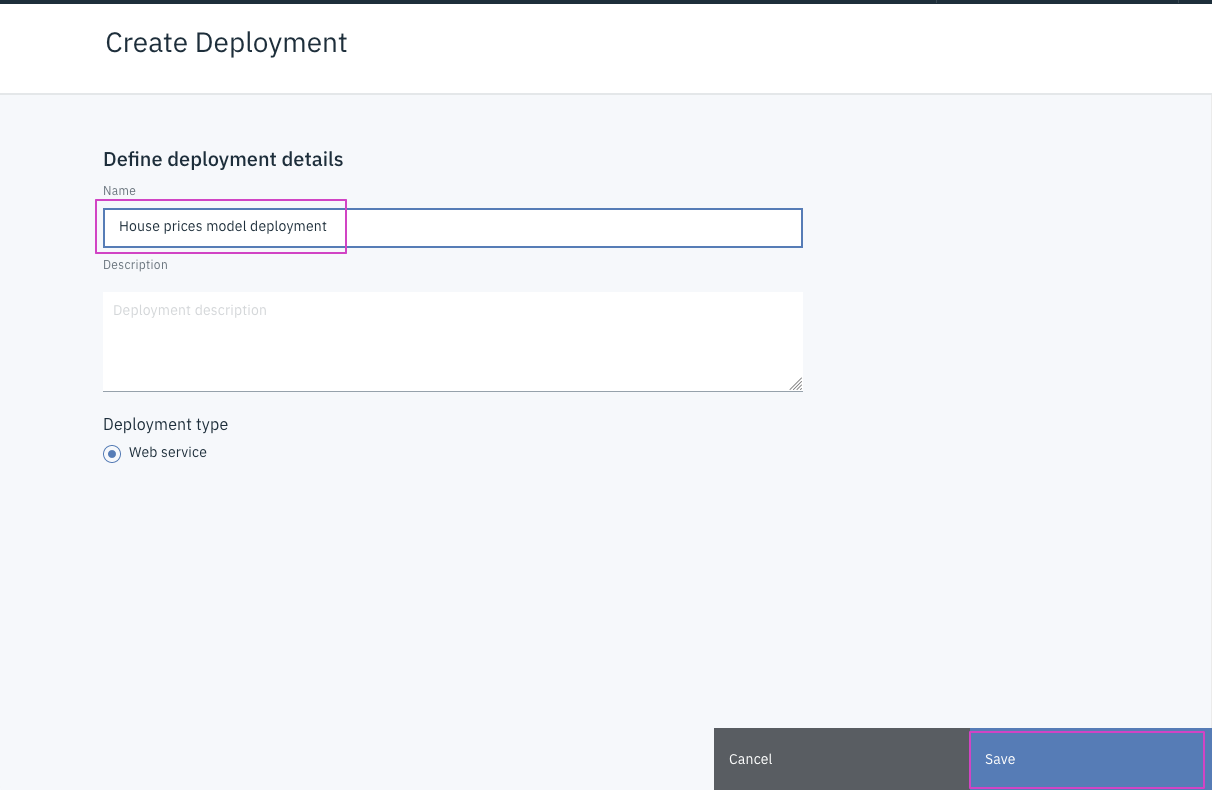
Nameに
House prices model deploymentと⼊⼒後、Saveボタンをクリックします。
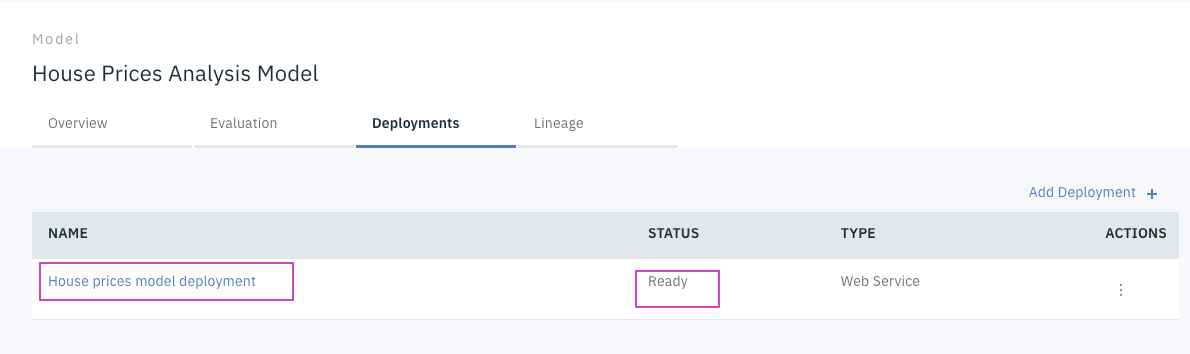
Deploymentタブに⾃動で戻ります。STATUSはInitializingからreadyに変わります。
1分待っても変わらない場合はリロードしてみてください。
9. JSONレコードでモデルをテスト
-
House prices model deploymentをクリックします。
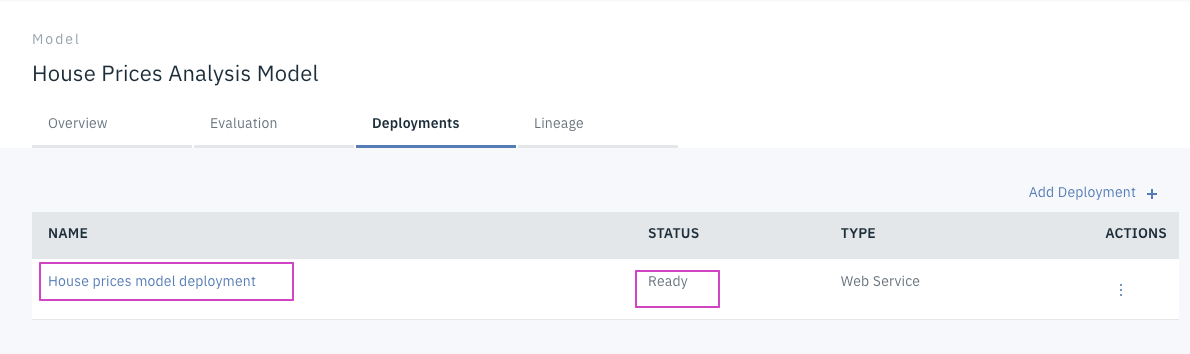
OverviewタブでDeploymentの詳細を確認できます。
Implementationタブをクリックします。そのタブの下に、スコアリングエンドポイントが表⽰され、Java、JavaScript、Pythonなどの5つの⾔語のコードスニペットも提供されます。
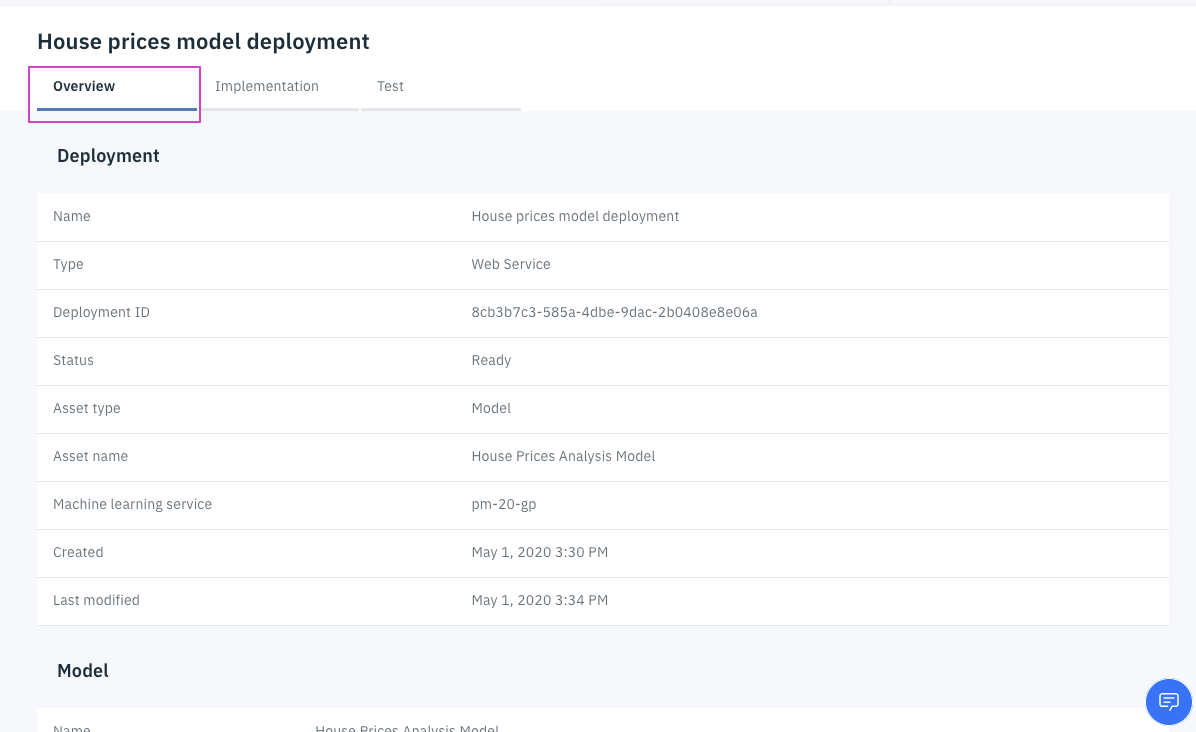
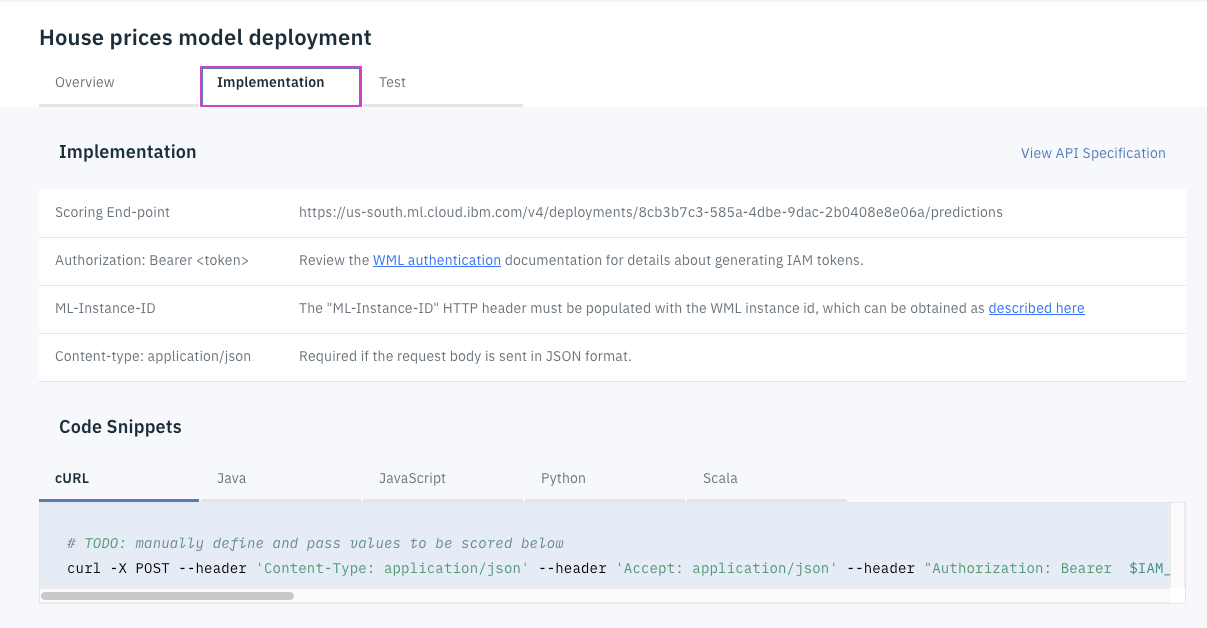
-
Testタブをクリックします。そのままフォームでデータを⼊れてもできますが、今回はJSON inputアイコンをクリックして、JSONで⼊⼒します。
-
以下のデータを⼊⼒エリアにコピー&ペーストしてください。
(日本語訳注:boston_house_prices.csvの1行目の値です)
{"input_data":
[{
"fields": [ "CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM",
"AGE", "DIS", "RAD", "TAX", "PTRATIO",
"B", "LSAT"
],
"values": [[ 0.00632, 18, 2.31, 0, 0.538, 6.575,
65.2, 4.09, 1, 296, 15.3,
396.9, 4.98
]]
}]
}
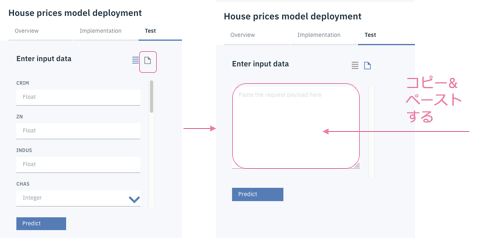
-
Predictボタンをクリックします。
右側に予測結果が表⽰されます。
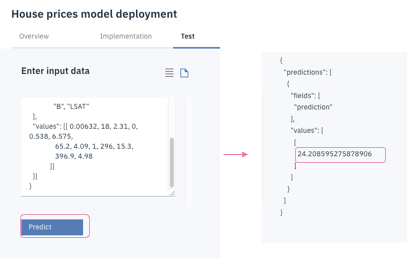
そのレコードの値は24で、予測値は24.209です。
{
"predictions": [
{
"fields": [
"prediction"
],
"values": [
[
24.208595275878906
]
]
}
]
}
- 画面の左上にある名前をクリックすると、チュートリアルプロジェクトに戻ることができます。

Next Step
IBM Watson Studio AutoAI: Modeling for the rest of us 日本語解説 #3に続きます。