Db2 Warehouse on CloudのREST APIを使用したデータロード (Python & curl)という記事を以前書いたのですが、既にDb2 Warehouse on Cloudは名前が変わって「Db2 Warehouse SaaS」そしてアーキテクチャーがGen2(第二世代)からGen3(第3世代)になりました。今Db2 Warehouse SaaSを作ると全てGen3になります。
以前書いたものはREST APIのバージョンがv4でした。Gen3からはv5が推奨ということでv5+Gen3で動かしてみました。そして今回はさらにAPI Documentの説明が少なすぎてもはや推理状態のAWS S3からのデータロードの方法について書きます。
こちらで使用しているPythonのコードはnotebookとして以下でダウンロード可能です:
https://github.com/kyokonishito/Db2onCloud_RESTAPI/blob/main/notebooks/Db2_Warehouse_on_Cloud_API_v5_Load_from_S3.ipynb
0. 以前との違い
0-1. Gen2(第二世代)とGen3(第3世代)のRESTAPIの違い
これはv4とv5ではなく、 Gen2(第二世代)とGen3(第3世代)のRESTAPIの違いです。正直v4とv5で 「同じMethodの」パラメータはほぼ同じです。ただパラメータが減った(なくなった)ものもあるようなので、仕様をよく確認するようお願いします。
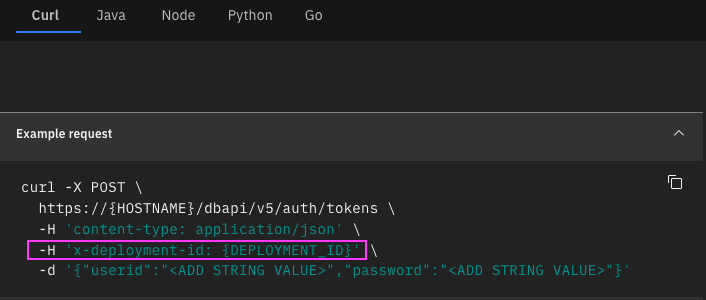
Gen3(第3世代)にはHeaderにx-deployment-idのセットが必要です。x-deployment-idはCRNの値をセットします。
例:
0-2. v4とv5のRESTAPIの違い
Method数がv5で大幅に増加しています。できることが増えました!
v4とv5のMethod数比較:
| v4 | v5 |
|---|---|
 |
 |
1. 前準備
REST APIで使用するREST API host nameとCRNをあらかじめ取得しておきます。
S3にロードするファイルをアップロードしておきます。
1.1 REST API host name情報の取得
まずはREST API host name情報を取得します。
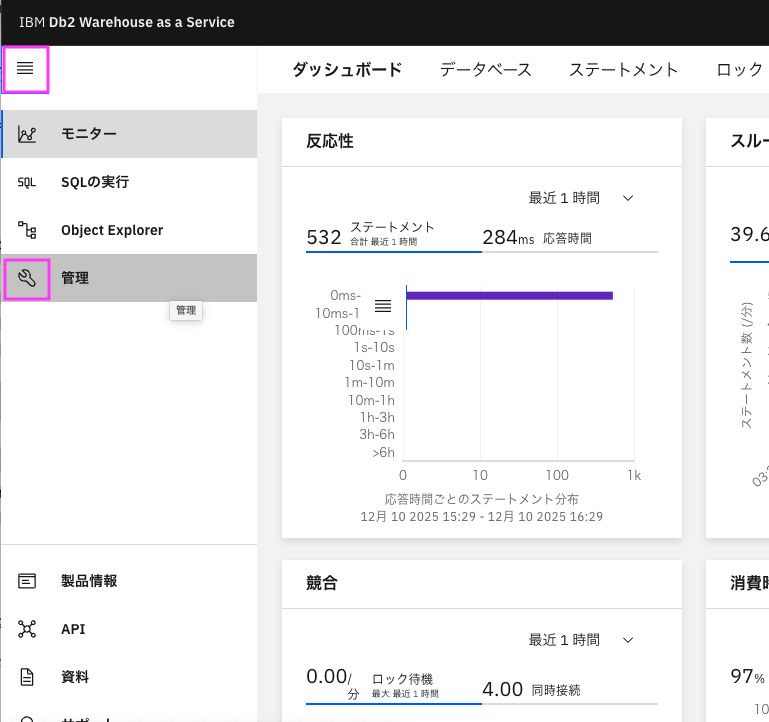
1.1.1. Db2 Warehouse as a Serviceコンソールを開いて、左側のメニューからスパナのアイコン「管理」をクリックします・
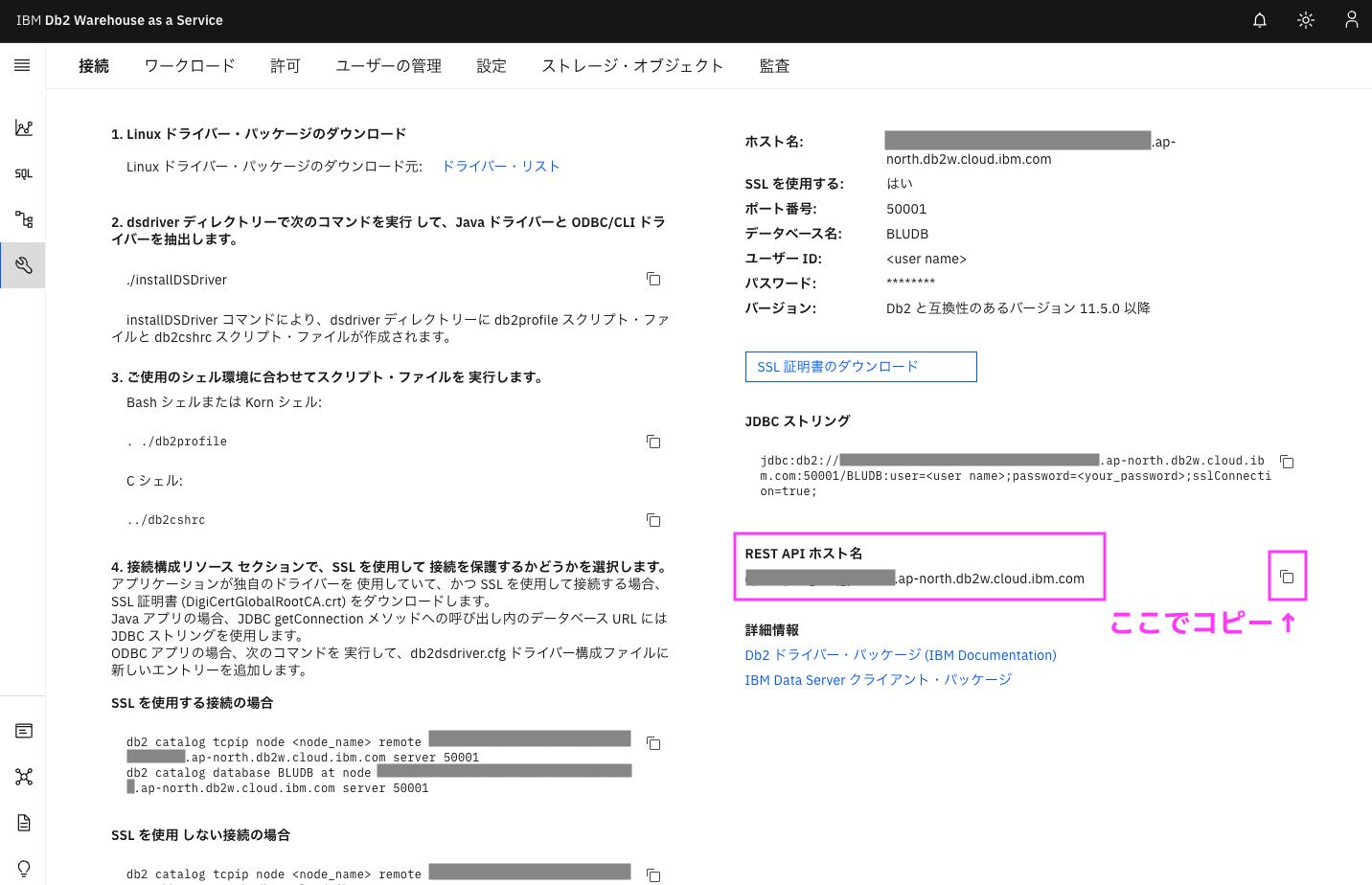
1.1.2. 「接続」タブのREST API ホスト名 からREST API URL情報を取得する
デフォルトで「接続」タブが開きます。「接続」タブでない場合は、「接続」タブをクリックしてください。
ここで取得したホスト名がAPIのhost nameになります。
1.2. CRN情報の取得
CRN情報はいくつかの場所から取得できますが、ここではリソースリストから取得する方法を説明します。
1.2.1. IBM Cloudのダッシュボードの右上のメニューから「リソース・リスト」を選択
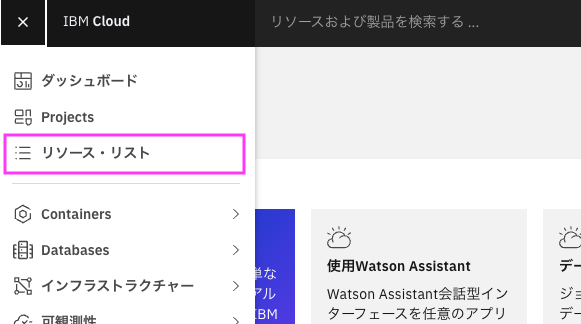
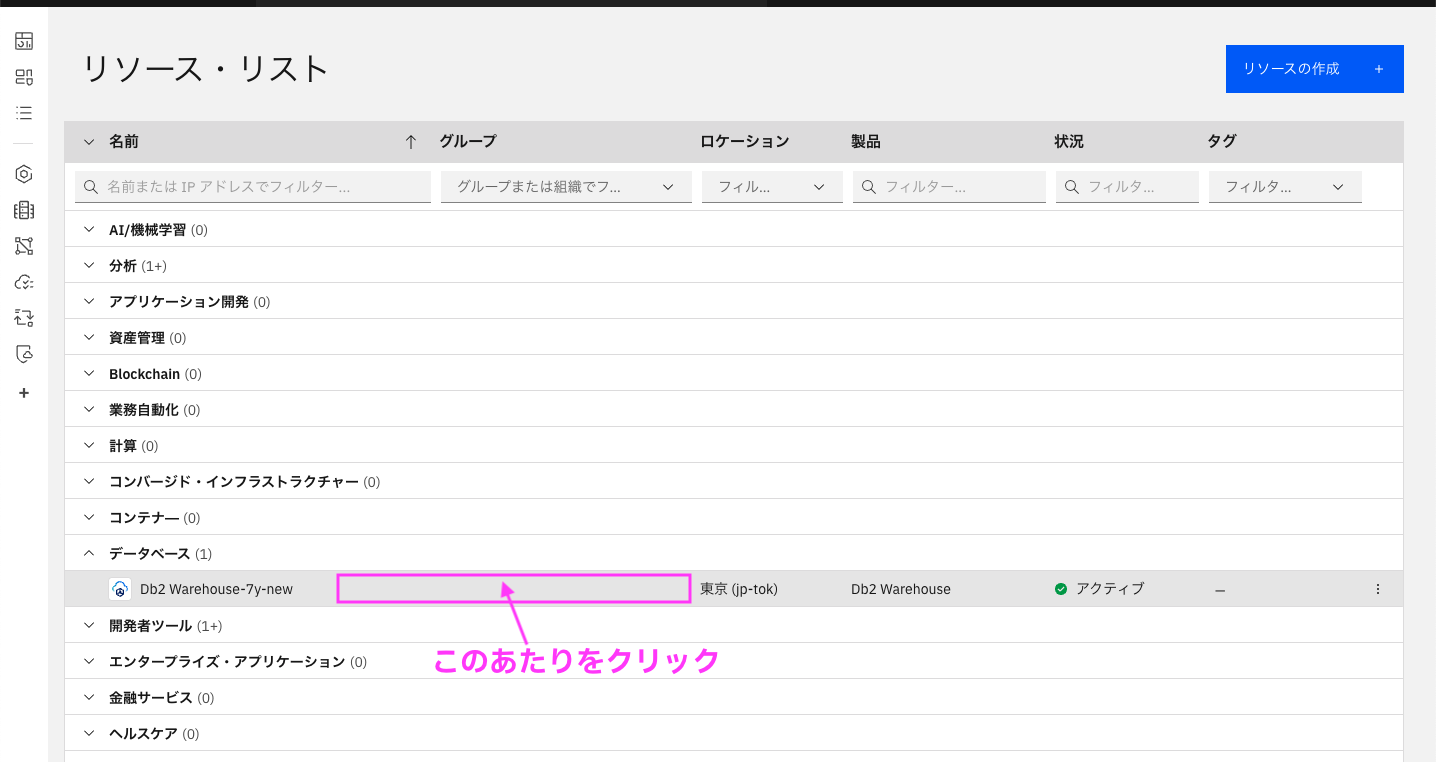
1.2.2. 「データベース」をクリックして開き、接続したいDb2 Warehouseの名前の行の「真ん中あたり」をクリックします。
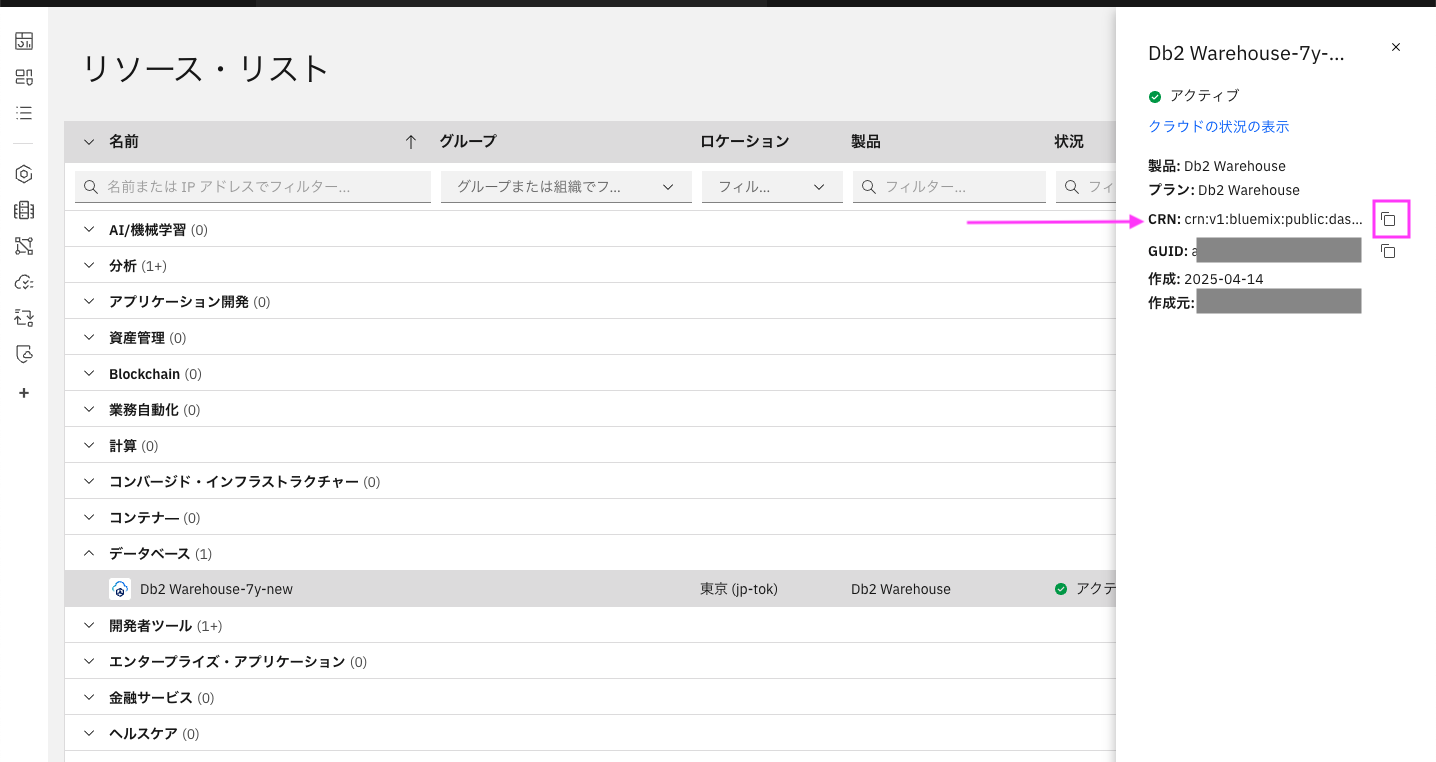
1.2.3. CRNが表示されるので、右側のコピーアイコンでコピーし、テキストファイルなどどこかに貼り付けておく
ここで取得したCRNをAPI使用時に使います。
1.3 データファイルのS3へのアップロード
ロードするファイルをS3にアップロードしておいてください。ここではCSVファイルとします。
重要
- 2025年12月10日現在、ロードするCSVファイルの一行目にヘッダー(項目名)が付いているファイルは、ヘッダーを除いたロードができませんので、ヘッダーを除いたデータのみのCSVファイルを準備してください。
- ファイルの文字コードがUTF-8の場合は「BOMなし」で準備してください。BOMがあると一行目一文字目の読み込みで思わぬエラーが発生する可能性があります。
2. アクセストークンの取得
ここからはPythonまたはcurlコマンドを使用します。
Db2のuserid, passwordを使用して、API実行に必要なアクセストークンをREST APIで取得します。またはアクセス権限のあるIDのAPIKEYからも取得可能です。
指定したuseridの権限と、APIで実行可能な権限は同じです。
ここではDb2のuserid, passwordを使用した方法で取得します。
アクセス権限のあるIDのAPIKEYからも取得する場合は、以下を参考に取得してください:
ibm-cloud-sdk-coreのIAMAuthenticatorを使って IAM トークンの生成(Python)
API Doc:https://cloud.ibm.com/apidocs/db2-warehouse-on-cloud/db2-warehouse-on-cloud-v5#authenticate
Python
Python前準備
スクリプトの冒頭で必要なライブラリと変数を設定します。アクセストークンの取得だけでなく、以降で使用する変数も設定します。
<> で囲まれた部分は、前準備で取得した値に置き換えてください。
#必要なライブラリのimport
import requests
import json
import sys
#必要な変数のセット
REST_API_URL = "<1.1.2で取得したREST API ホスト名>"
DEPLOYMENT_ID = "<1.2.3で取得したCRN>"
DB_USERID = "<dbのuserid>"
DB_PW = "<dbのpassword>"
LOAD_FILE = "<ロードするファイル名(S3のPATH付き)>"
SCHEMA_NAME = "<ロード先テーブルのスキーマ名>"
TABLE_NAME = "<ロード先テーブル名>"
S3_ENDPOINT="<s3エンドポイント s3.ap-northeast-1.amazonaws.com など>"
S3_AUTHID="<S3 Access Key>"
S3_SECRET="<S3 Secret Key>"
S3_BUCKET="<S3バケット名>"
本編
実行が成功すると変数access_tokenにアクセストークンの値が入ります。
#REST API の URL 作成
service_name = '/dbapi/v5/auth/tokens'
url = 'https://' + REST_API_URL + service_name
# request header作成
headers = {}
headers ['content-type'] = "application/json"
headers ['x-deployment-id'] = DEPLOYMENT_ID
# parameter dbアクセス用のuid, pwを指定
params = {}
params['userid'] = DB_USERID
params['password']= DB_PW
# Call the RESTful service
try:
r = requests.post(url, headers=headers, json=params)
except Exception as err:
print("RESTful call failed. Detailed information follows.")
print(err)
sys.exit()
# Check for Invalid credentials
if (r.status_code == 401): # There was an error with the authentication
print("RESTful called failed.")
message = r.json()['errors']
print(message)
sys.exit()
# Check for anything other than 200/401
if (r.status_code != 200): # Some other failure
print("RESTful called failed. Detailed information follows.")
print(r.json())
sys.exit()
# Retrieve the access token
try:
access_token = r.json()['token']
#print(r.json())
except:
print("RESTful call did not return an access token.")
print(r.json())
sys.exit()
print (access_token)
curl
<>で囲まれた部分は前準備で取得した値に置き換えて実行してください。
curl -X POST https://<1.1.2で取得したAPI hostname>/dbapi/v5/auth/tokens \
-H 'content-type: application/json' \
-H 'x-deployment-id: <1.2.3で取得したCRN>' \
-d '{"userid":"<dbのuserid>","password":"<dbのpassword>"}'
出力例: tokenの値(青くマークした部分)がアクセストークンの値になります(一部マスキングしてます)。

3. データロードジョブの作成(外部表利用)
S3 に配置したファイルを外部表を利用してロードするジョブを作成し、実行します。使用するのはload_jobs_ET Method 「Creates a data load job, load uses external table technology」です。
https://cloud.ibm.com/apidocs/db2-warehouse-on-cloud/db2-warehouse-on-cloud-v5#createetloadjob
この記事では説明しませんが、別途サーバーにアップロードしたファイルをロードすることも可能です。その場合の方法はv4の記事を参照してください。Header に x-deployment-id を設定すれば、v4 を v5 に置き換えるだけで同じことができます。:
Db2 Warehouse on CloudのREST APIを使用したデータロード (python & curl)
以下がAPI Docに記載されているRequestパラメーターの説明です:
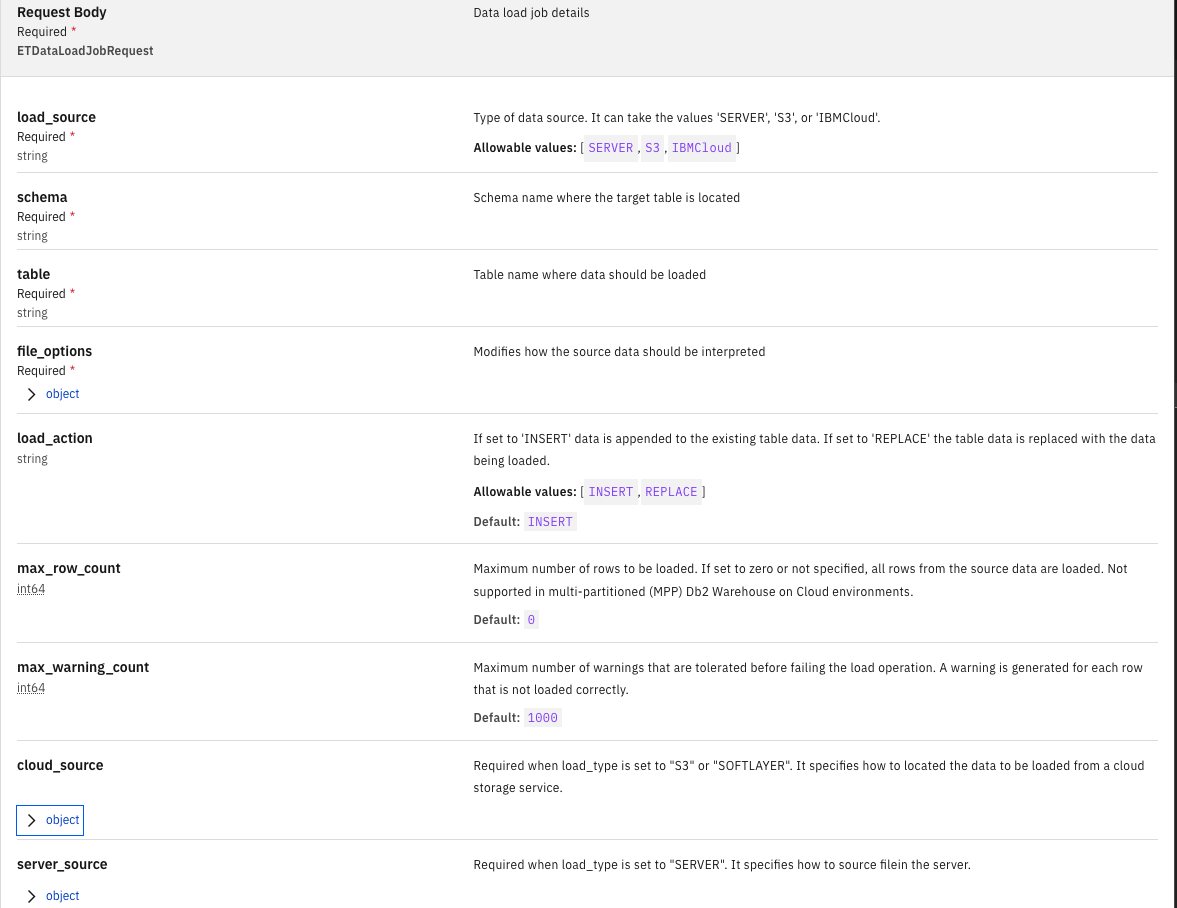
*は必須
-
load_source*:S3にセットします -
schema*: ターゲットのスキーマ名 -
table*: ターゲットのテーブル名 -
file_options*: 詳細は後述 -
load_action: 追加でINSERT INSERT / データの置換 REPLACE, デフォルト: INSERT -
max_row_count: ロードする行の最大数。0に設定するか指定しない場合、ソースデータの全行がロードされます。マルチパーティション(MPP)のDb2 Warehouse on Cloud環境ではサポートされていません。デフォルト: 0 -
max_warning_count: ロード操作が失敗する前に許容される警告の最大数。正しくロードされなかった各行に対して警告が生成されます。デフォルト: 1000 -
cloud_source: S3アクセス情報、詳細は後述 -
server_source: S3からのロードの場合は設定不要
file_options (必須)
ソースデータの解釈方法を指定します。すべてオプションです。
| フィールド名 | 型 | 説明 |
|---|---|---|
| encoding | string | ファイルのエンコーディング方式。 UTF8: UTF8でNCHAR/NVARCHARのみ。 LATIN9: LATIN9でCHAR/VARCHARのみ。 INTERNAL: UTF8とLATIN9が混在、または不明な場合。システムがチェックし必要に応じて変換します(パフォーマンス低下のため必要時のみ使用)。デフォルトは INTERNAL。 |
| code_page | string | ソースファイルの文字コード。サポートされるコードページ一覧に従う。デフォルトは 1208(UTF-8)。code_page と encoding は同時指定不可。 |
| has_header_row | string | ヘッダ行に列名があるか。Db2 Warehouse SaaSではサポートされないため、値は no のみ。デフォルト: no。 |
| column_delimiter | string | 列区切り文字。デフォルトは ,(カンマ)。0xJJ形式で16進指定可能(0x00, 0x0A, 0x0D, 0x20, 0x2E は不可)。 |
| string_delimiter | string | 文字列の囲み文字。許容値: NO, SINGLE, DOUBLE。 string_delimiter参照。デフォルト: DOUBLE。 |
| date_style | string | 日付スタイル(詳細は date_style 参照)。 |
| time_style | string | 時刻スタイル(詳細は time_style 参照)。 |
| date_delimiter | string | 日付区切り文字(詳細は date_delimiter 参照)。 |
| date_format | string | 日付フィールドのフォーマット。TIMESTAMP_FORMAT関数で受け入れられる形式。デフォルト: YYYY-MM-DD。DATE_FORMAT と DATEDELIM/DATESTYLE は同時指定不可。 |
| time_format | string |
時刻フィールドのフォーマット。デフォルト: HH.MI.SS。TIME_FORMAT と TIMEDELIM/TIMESTYLE は同時指定不可。 |
| timestamp_format | string |
タイムスタンプフィールドのフォーマット。デフォルト: YYYY-MM-DD HH.MI.SS。TIMESTAMP_FORMAT と他のスタイル指定は同時指定不可。 |
| bool_style | string | ブール値の表現方法。許容値: 1_0(デフォルト), T_F, Y_N, YES_NO, TRUE_FALSE。 |
| ignore_zero | string | CHAR/VARCHARフィールド内のバイト値0を無視するか。許容値: ON(無視), OFF(無視しない、デフォルト)。 |
| require_quotes | string | 引用符を必須にするか。許容値: ON(必須), OFF(デフォルト)。QUOTEDVALUE が YES/SINGLE/DOUBLE の場合のみ有効。 |
| ctrl_chars | string | CHAR/VARCHARフィールドでASCII値1-31を許可するか。許容値: ON(許可), OFF(デフォルト)。NULL, CR, LFはエスケープ必須。 |
| escape_char | string | エスケープ文字。次の文字を区切りや改行ではなく値として扱う。グラフィック文字列データでは無視。デフォルトなし。 |
使用例
"file_options":{
"code_page":"1208", #ファイルのコードページ, utf-8であれば1208
"has_header_row":"no",#Header(1行目の項目名) なし no / あり yes, ただしnoしかセットできない
"column_delimiter":",", #カラムのデリミター
"date_format":"YYYY-MM-DD", #Dateのフォーマット
"time_format":"HH:MM:SS", #Timeのフォーマット
"timestamp_format":"YYYY-MM-DD HH:MM:SS"}, #TimeStampのフォーマット
}
cloud_source (必須)
load_type が "S3" に設定されている場合に必須です。クラウドストレージサービス(Amazon S3)からロードするデータの場所を指定します。
フィールド一覧 (pathの書き方が重要!)
| フィールド名 | 型 | 説明 |
|---|---|---|
| endpoint | string (必須) | データが存在するクラウドストレージのエンドポイントURL。s3.ap-northeast-1.amazonaws.comなど |
| path | string (必須) |
重要 S3のバケット名とロードするファイル名(PATH付き)。 ::で区切って記載(※この仕様は API ドキュメントには記載されていません)。バケット名が testbucket01、PATH付きファイル名がdata/TEST01.csvの場合、testbucket01::data/TEST01.csv と入れる |
| auth_id | string (必須) | 認証ID(Amazon S3のアクセスキー) |
| auth_secret | string (必須) | 認証シークレット(Amazon S3のシークレットキー)。 |
使用例
バケット名がtestbucket01、PATH付きファイル名がdata/TEST01.csvの場合
"cloud_source": {
"endpoint": "s3.ap-northeast-1.amazonaws.com",
"path": "testbucket01::data/TEST01.csv",
"auth_id": "zsxdcfvgbh",
"auth_secret": "zaq12wsxcde34frfvgg"
}
Python
2の前準備、本編、3のコードを実行して、必要なシェル変数、access_tokenにアクセストークンの値、 FILE_PATHの値が入っていること、ロードするファイルのアップロード実施済みが前提です。
実行が成功すると変数JOB_IDにアップロードしたデータロード ジョブのIDの値が入ります。
#REST API の URL 作成
service_name = '/dbapi/v5/load_jobs_ET'
url = 'https://' + REST_API_URL + service_name
# request header作成
headers = {}
headers ['content-type'] = "application/json"
headers ['authorization'] = 'Bearer ' + access_token #アクセストークンをHeaderにセット
headers ['x-deployment-id'] = DEPLOYMENT_ID
# ロード属性のセット
data = {
"load_source": "S3",
"schema": SCHEMA_NAME,
"table":TABLE_NAME,
"file_options":{
"code_page":"1208", #ファイルのコードページ, utf-8であれば1208
"has_header_row":"no",#Header(1行目の項目名) なし no / あり yes, ただしnoしかセットできない
"column_delimiter":",", #カラムのデリミター
"date_format":"YYYY-MM-DD", #Dateのフォーマット
"time_format":"HH:MM:SS", #Timeのフォーマット
"timestamp_format":"YYYY-MM-DD HH:MM:SS"}, #TimeStampのフォーマット
"load_action": "REPLACE", # 追加でINSERT INSERT / データの置換 REPLACE
"cloud_source":
{"endpoint":S3_ENDPOINT,
"path":S3_BUCKET+'::'+LOAD_FILE,
"auth_id":S3_AUTHID,
"auth_secret":S3_SECRET
}
}
try:
r = requests.post(url, headers=headers, json=data)
print( r.status_code)
except Exception as err:
print("RESTful call failed. Detailed information follows.")
print(err)
# Check for Invalid credentials
if (r.status_code == 401): # There was an error with the authentication
print("RESTful called failed.")
message = r.json()['errors']
print(message)
# Check for anything other than 201/401
elif (r.status_code != 201): # Some other failure
print("RESTful called failed. Detailed information follows.")
print(r.text)
#print(json.dumps(r.json(), indent=4))
# Print response
else:
print(json.dumps(r.json(), indent=4))
JOB_ID = r.json()["id"]
print(f"JOB_ID: {JOB_ID}" )
出力例:
1でS3のアップロードしたdata/TESTDATA.0000MB.55cols_new.csvファイルの データロードジョブを作成。 JOB_IDは1765359901357
201
{
"schema": "YYYYYY",
"database": "crn:v1:bluemix:public:dashdb:jp-tok:a/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz:xxxxxxxxxxxxxxxx::",
"load_source": "S3",
"load_action": "REPLACE",
"id": 1765359901357,
"userid": "XXXXXXXX",
"table": "0000MB_55COLS",
"status": "Initialized"
}
JOB_ID: 1765359901357
curl
${REST_API_URL}のように${XXX}で書かれた部分のXXXXは環境変数です。以下の環境変数実行前にセットしてください。
環境変数のセット(Mac or Linuxの場合):
export REST_API_URL = "<1.1.2で取得したREST API ホスト名>"
export DEPLOYMENT_ID = "<1.2.3で取得したCRN>"
export LOAD_FILE = "<ロードするファイル名(S3のPATH付き)>"
export SCHEMA_NAME = "<ロード先テーブルのスキーマ名>"
export TABLE_NAME = "<ロード先テーブル名>"
export S3_ENDPOINT="<s3エンドポイント s3.ap-northeast-1.amazonaws.com など>"
export S3_AUTHID="<S3 Access Key>"
export S3_SECRET="<S3 Secret Key>"
export S3_BUCKET="<S3バケット名>"
export ACCESS_TOKEN="<2で取得したアクセストークンの値>"
curlコマンド
curl -X POST "https://${REST_API_URL}/dbapi/v5/load_jobs_ET" \
-H "content-type: application/json" \
-H "authorization: Bearer ${ACCESS_TOKEN}" \
-H "x-deployment-id: ${DEPLOYMENT_ID}" \
-d "{
\"load_source\": \"S3\",
\"schema\": \"${SCHEMA_NAME}\",
\"table\": \"${TABLE_NAME}\",
\"file_options\": {
\"code_page\": \"1208\",
\"has_header_row\": \"no\",
\"column_delimiter\": \",\",
\"date_format\": \"YYYY-MM-DD\",
\"time_format\": \"HH:MM:SS\",
\"timestamp_format\": \"YYYY-MM-DD HH:MM:SS\"
},
\"load_action\": \"REPLACE\",
\"cloud_source\": {
\"endpoint\": \"${S3_ENDPOINT}\",
\"path\": \"${S3_BUCKET}::${LOAD_FILE}\",
\"auth_id\": \"${S3_AUTHID}\",
\"auth_secret\": \"${S3_SECRET}\"
}
}"
出力例:
idの値は次で使います。
{"schema":"YYYYYY","database":"crn:v1:bluemix:public:dashdb:jp-tok:a/zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz:xxxxxxxxxxxxxxxx::","load_source":"S3","load_action":"REPLACE","id":1765330106936,"userid":"XXXXXXXX","table":"0000MB_55COLS","status":"Initialized"
4. データロードジョブの状況確認
作成したジョブの実行状況を確認します。
API Doc: https://cloud.ibm.com/apidocs/db2-warehouse-on-cloud/db2-warehouse-on-cloud-v5#getloadjobbyid
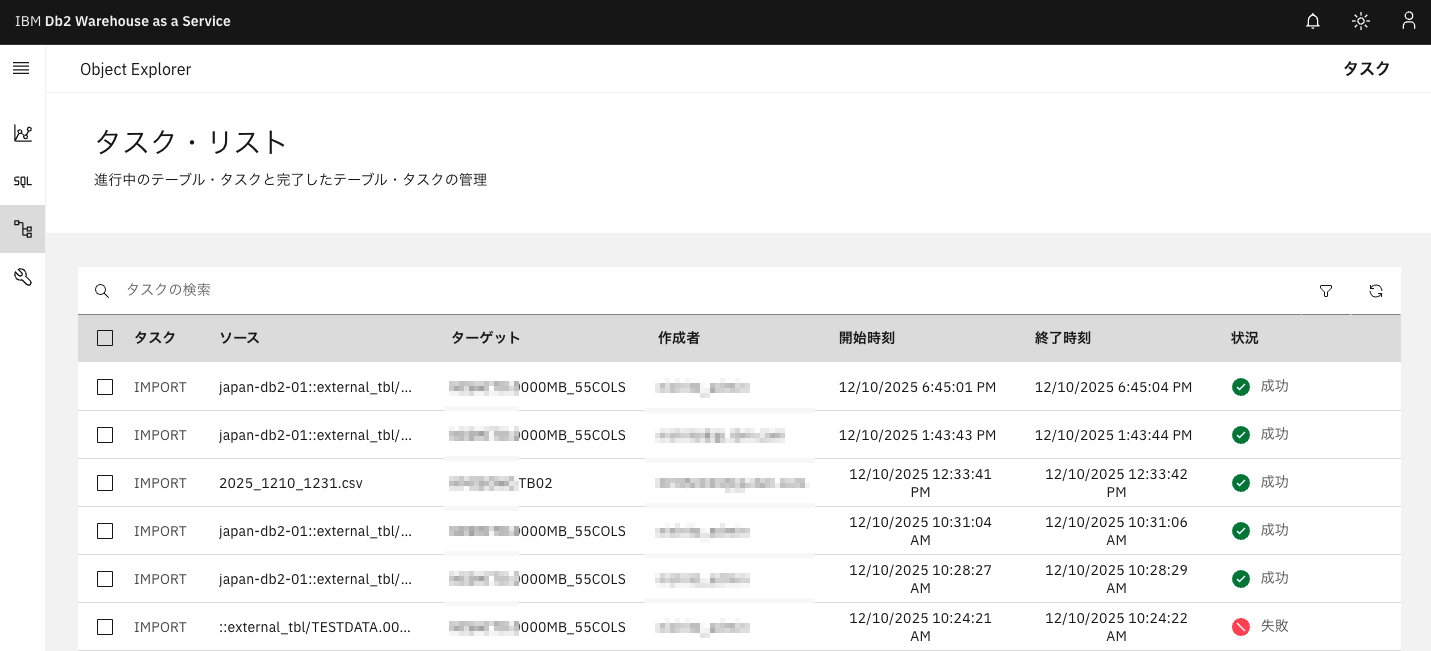
ここで確認できる内容はWebコンソールの「Object Exploror」→「タスク」→「タスク・リスト」でも確認できます。
Python
1の前準備、本編、2,3のコードを実行して、必要なシェル変数、access_tokenにアクセストークンの値、 JOB_IDの値が入っていることが前提です。
#REST API の URL 作成
service_name = '/dbapi/v5/load_jobs'
url = 'https://' + REST_API_URL + service_name + '/' + str(JOB_ID)
# request header作成
headers = {}
headers ['content-type'] = "application/json"
headers ['authorization'] = 'Bearer ' + access_token #アクセストークンをHeaderにセット
headers ['x-deployment-id'] = DEPLOYMENT_ID
try:
r = requests.get(url, headers=headers)
print( r.status_code)
except Exception as err:
print("RESTful call failed. Detailed information follows.")
print(err)
# Check for Invalid credentials
if (r.status_code == 401): # There was an error with the authentication
print("RESTful called failed.")
message = r.json()['errors']
print(message)
# Check for anything other than 201/401
elif (r.status_code != 200): # Some other failure
print("RESTful called failed. Detailed information follows.")
print(r.text)
# Print response
else:
print(json.dumps(r.json(), indent=4))
出力例:
3で出力されたJOB_IDのデータロードジョブの状況確認。
status.statusに"status": "Success"となっており、成功しています。
ロードされた行数など状況詳細はstatusの中身に記載されています。
200
{
"request": {
"schema": "YYYYYY",
"stream_source": {
"file_name": ""
},
"auto_create_table": {
"column_names": [],
"execute": ""
},
"load_source": "S3",
"cloud_source": {
"path": "testbucket01::data/TESTDATA.0000MB.55cols_new.csv",
"endpoint": "s3.ap-northeast-1.amazonaws.com",
"authSecret": "zaq12wsxcde34frfvgg",
"authId": "zsxdcfvgbh"
},
"max_warning_count": "1000",
"isET": "true",
"load_action": "REPLACE",
"server_source": {
"file_path": ""
},
"file_options": {
"boolean_style": "1_0",
"ignore_zero": "false",
"has_header_row": "no",
"time_format": "",
"string_delimiter": "NO",
"column_delimiter": ",",
"null_value": "NULL",
"require_quotes": "false",
"delimiter_priority": "",
"code_page": "1208",
"timestamp_format": "",
"string_blanks": "",
"cde_analyze_frequency": "",
"identity_columns": "",
"use_defaults_for_missing_values": "",
"implicitly_hidden_columns": "",
"ctrl_chars": "false",
"date_format": ""
},
"table": "0000MB_55COLS"
},
"metadata": {
"updated_at": "",
"guid": "",
"created_at": "",
"url": ""
},
"scripts_status": null,
"id": "1765378093979",
"display_userid": "XXXXXXXX",
"userid": "XXXXXXXX",
"status": {
"rows_loaded": 9,
"sub_status": "Success",
"end_time": 1765378096490,
"rows_rejected": 0,
"bad_file": "BLUDB.XXXXXXXX.SYSTET64402.TESTDATA.0000MB.55cols_new.csv.00013738.0000009.bad",
"error_count": 0,
"start_time": 1765378094515,
"rows_read": 9,
"rows_deleted": 0,
"rows_committed": 0,
"errors_summary": [],
"log_file": "BLUDB.XXXXXXXX.SYSTET64402.TESTDATA.0000MB.55cols_new.csv.00013738.0000009.log",
"warning_count": 0,
"warnings_summary": [],
"rows_partitioned": 0,
"log_content": "",
"status": "Success",
"rows_skipped": 0
}
}
S3のロードするデータが置いてある場所と同じ場所にログファイルが作成されます。上記出力の"log_file"のファイル名で作成されています。
curl
1, 2, 3のコードを実行して、アクセストークンの値取得済み、ロードするファイルのアップロード 、データロードジョブ実施済み、が前提です。
<>で囲まれた部分は前準備、1,2,3で取得した値に置き換えてください。
curl -X POST https://<1.1.2で取得したREST API ホスト名>/dbapi/v5/load_jobs/<3で取得したid> \
-H 'authorization: Bearer <2で取得したアクセストークンの値>'\
-H 'content-type: application/json' \
-H 'x-deployment-id: <1.2.3で取得したCRN>' \
出力例:
{"request":{"schema":"XXXXXXXX","stream_source":{"file_name":""},"auto_create_table":{"column_names":[],"execute":""},"load_source":"S3","cloud_source":{"path":"testbucket01::data/TESTDATA.0000MB.55cols_new.csv","endpoint":"s3.ap-northeast-1.amazonaws.com","authSecret":"zaq12wsxcde34frfvgg","authId":"zsxdcfvgbh"},"max_warning_count":"1000","isET":"true","load_action":"REPLACE","server_source":{"file_path":""},"file_options":{"boolean_style":"1_0","ignore_zero":"false","has_header_row":"no","time_format":"","string_delimiter":"NO","column_delimiter":",","null_value":"NULL","require_quotes":"false","delimiter_priority":"","code_page":"1208","timestamp_format":"","string_blanks":"","cde_analyze_frequency":"","identity_columns":"","use_defaults_for_missing_values":"","implicitly_hidden_columns":"","ctrl_chars":"false","date_format":""},"table":"0000MB_55COLS"},"metadata":{"updated_at":"","guid":"","created_at":"","url":""},"scripts_status":null,"id":"1765378093979","display_userid":"XXXXXXXX","userid":"XXXXXXXX","status":{"rows_loaded":9,"sub_status":"Success","end_time":1765378096490,"rows_rejected":0,"bad_file":"BLUDB.XXXXXXXX.SYSTET64402.TESTDATA.0000MB.55cols_new.csv.00013738.0000009.bad","error_count":0,"start_time":1765378094515,"rows_read":9,"rows_deleted":0,"rows_committed":0,"errors_summary":[],"log_file":"BLUDB.XXXXXXXX.SYSTET64402.TESTDATA.0000MB.55cols_new.csv.00013738.0000009.log","warning_count":0,"warnings_summary":[],"rows_partitioned":0,"log_content":"","status":"Success","rows_skipped":0}}
6. まとめ
Db2 Warehouse SaaS Gen3のREST API v5を使用したS3からのデータロードには以下のステップを踏むことが必要です:
- アクセストークンの取得
- データロードジョブの作成
- データロードジョブの状況確認
ここでのコードは説明のために冗長に書いています。関数などでまとめてしまえば簡単に書けるかと思いますので、ぜひ実際の業務でも使用してみてください。
こちらで使用しているpythonのコードはnotebookとして以下でダウンロード可能です:
https://github.com/kyokonishito/Db2onCloud_RESTAPI/blob/main/notebooks/Db2_Warehouse_on_Cloud_API_v5_Load_from_S3.ipynb