kerasで簡単に転移学習が回せるということを知ったので、夏休みにやってた乃木坂46メンバーの顔認識プログラムのニューラルネットワークを転移学習モデルに変えて学習してみました。今回はVGG16,VGG19,ResNet50を試してみました。元々の記事のプログラムから変えた部分と、Google Colaboratoryを使ったのでその説明、学習結果について書いていきます。
前回の記事はこちら。
乃木坂メンバーの顔をCNNで分類
google colaboratory
Googleが機械学習の教育や研究用に提供しているツールで、jupyter notebookと似た環境を簡単に利用することができます。そして重要な点は高性能なGPU(NVIDIA Tesla K80)を無料で利用できる点です。最初は自分のローカルPCで学習をしていたんですが、1epochに15分近くかかっていたのでcolabを使ってみました。1epoch10秒くらいでした。速い!
データセットのアップロード方法だけ2つ紹介いたします。
① ローカルからのデータのアップロード
from google.colab import files
uploaded = files.upload()
これを実行するとファイルアップロードのボタンが出てくるので、データセットをzipファイルに圧縮してアップロードします。
!unzip all.zip
これで解凍することでデータを利用できるようになります。
② google driveからのアップロード
まずデータセットのzipファイルをgoogle driveに入れておきます。
import google.colab
import googleapiclient.discovery
import googleapiclient.http
google.colab.auth.authenticate_user()
drive_service = googleapiclient.discovery.build('drive', 'v3')
upload_filename = 'all.zip'
file_list = drive_service.files().list(q="name='" + upload_filename + "'").execute().get('files')
# ファイル ID を取得します。
file_id = None
for file in file_list:
if file.get('name') == upload_filename:
file_id = file.get('id')
break
if file_id is None:
# ファイル ID を取得できなかった場合はエラーメッセージを出力します。
print(upload_filename + ' が見つかりません.')
else:
# colab 環境へファイルをアップロードします。
with open(upload_filename, 'wb') as f:
request = drive_service.files().get_media(fileId=file_id)
media = googleapiclient.http.MediaIoBaseDownload(f, request)
done = False
while not done:
progress_status, done = media.next_chunk()
print(100*progress_status.progress(), end="")
print("%完了")
print('GoogleドライブからColab環境へのファイル取り込みが完了しました.')
!unzip all.zip
途中でdrive認証のurlが出てくるので、そのurlから自分のアカウントを認証するとパスワードが出てくるのでそれをcolab側に入力します。
これでデータセットのアップロードができたら準備は完了です。
VGG16
こちらのサイトを参考にしました。
https://lp-tech.net/articles/ks8F9
モデルのサマリーを表示するとこんな感じです。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 64, 64, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 64, 64, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 64, 64, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 32, 32, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 32, 32, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 32, 32, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 16, 16, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 16, 16, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 16, 16, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 16, 16, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 8, 8, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 8, 8, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 4, 4, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 2, 2, 512) 0
_________________________________________________________________
sequential_1 (Sequential) (None, 5) 558085
=================================================================
Total params: 15,272,773
Trainable params: 7,637,509
Non-trainable params: 7,635,264
_________________________________________________________________
今回、fine-tuningをして、上図でのblock5_conv1 (Conv2D)から先の重みを更新しています。
コードは前回記事のlearn.pyのモデル部分を変更しています。
# VGG-16モデルの構造と重みをロード
# include_top=Falseによって、VGG16モデルから全結合層を削除
input_tensor = Input(shape=(64,64,3))
vgg16_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 全結合層の構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256))
top_model.add(Activation("sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128))
top_model.add(Activation('sigmoid'))
top_model.add(Dense(5))
top_model.add(Activation("softmax"))
# 全結合層を削除したVGG16モデルと上で自前で構築した全結合層を結合
model = Model(input=vgg16_model.input, output=top_model(vgg16_model.output))
# モデル重みを固定(VGG16のモデル重みを用いる)
for layer in model.layers[:15]:
layer.trainable = False
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
結果は最後にまとめて載せます。
VGG19
モデルはVGG16より少し層が多いだけなので割愛します。モデル部分のコードだけ。
# VGG-19モデルの構造と重みをロード
# include_top=Falseによって、VGG19モデルから全結合層を削除
input_tensor = Input(shape=(64,64,3))
vgg19_model = VGG19(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 全結合層の構築
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16_model.output_shape[1:]))
top_model.add(Dense(256))
top_model.add(Activation("sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128))
top_model.add(Activation('sigmoid'))
top_model.add(Dense(5))
top_model.add(Activation("softmax"))
# 全結合層を削除したVGG19モデルと上で自前で構築した全結合層を結合
model = Model(input=vgg19_model.input, output=top_model(vgg19_model.output))
# モデル重みを固定(VGG19のモデル重みを用いる)
for layer in model.layers[:17]:
layer.trainable = False
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
ResNet50
kerasでダウンロードしたResNetの全結合層以外の層は175層ありました。ResNetは残差学習をしてるのでmodel.summaryで中身を見てもどこがどうつながってるのかよくわからない。。。とりあえず全て固定して回してみたんですがあまりいい学習をしてくれなかったのでバッチノーマリゼーション層だけ固定しないという方法を試してみました。また、ResNetの入力は197×197pixel以上の画像でなくてはならず、今回は元データを256×256にリサイズしました。コードはこちら
# ResNetモデルの構造と重みをロード
# include_top=Falseによって、ResNet50モデルから全結合層を削除
input_tensor = Input(shape=(256,256,3))
resnet50_model = ResNet50(include_top=False, weights='imagenet', input_tensor=input_tensor)
# 全結合層の構築
top_model = Sequential()
top_model.add(Flatten(input_shape=resnet50_model.output_shape[1:]))
top_model.add(Dense(256))
top_model.add(Activation("relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128))
top_model.add(Activation('relu'))
top_model.add(Dense(5))
top_model.add(Activation("softmax"))
# 全結合層を削除したresnet50モデルと上で自前で構築した全結合層を結合
model = Model(input=resnet50_model.input, output=top_model(resnet50_model.output))
# BN層以外のモデル重みを固定(ResNet50のモデル重みを用いる)
for layer in resnet50_model.layers:
if 'BatchNormalization' in str(layer):
...
else:
layer.trainable = False
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
学習結果
比較対象として、前回記事のCNNモデルを同じテストデータで、colab上で回した結果も示します。
・前回のCNN
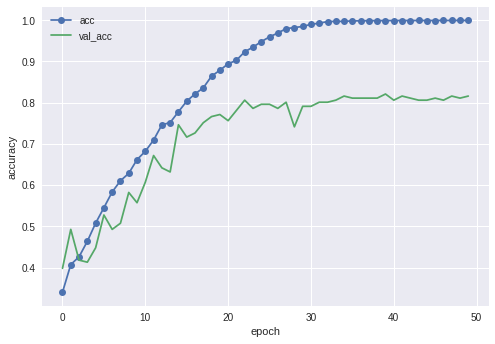
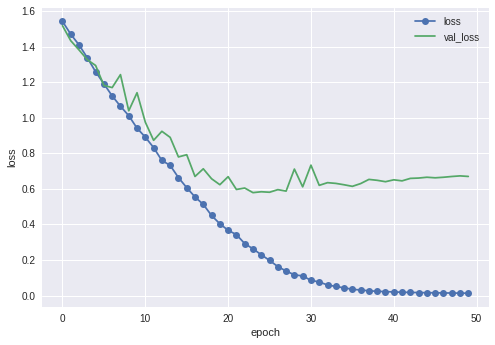
最終的なテストデータでのaccuracyは81.6%でした。
・VGG16
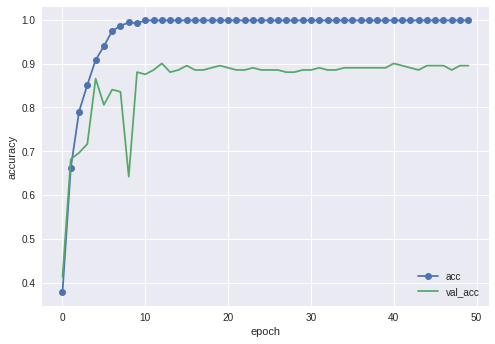
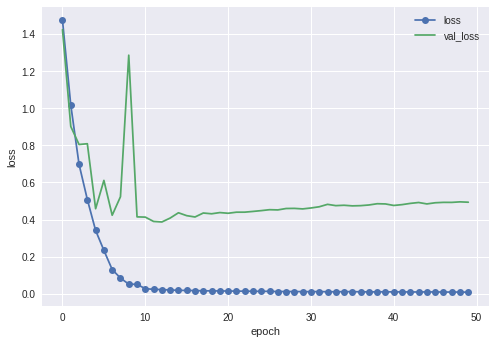
最終結果は89.6%でした。以前のモデルに比べるとだいぶ上がったかなと思います。
・VGG19
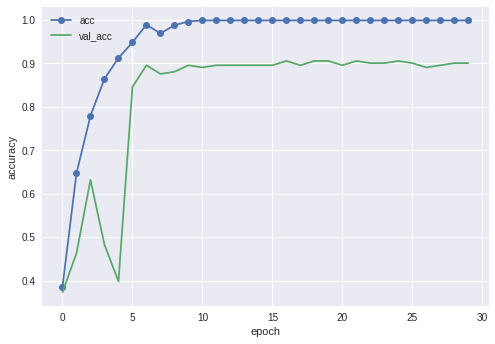
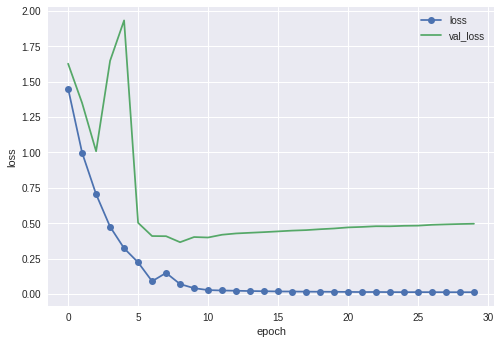
今回やってみたなかでは一番高い精度が出ました。90.0%でした。顔分類ではこれくらいが限界かもしれません。データの質もそこまで良くはありませんので。
VGG16も19も同じところらへんで1回精度落ちているのはなんなんだろう...
・ResNet
全層固定したものとBN層だけ固定しなかったものの両方の結果を貼ります。
まずは全層固定
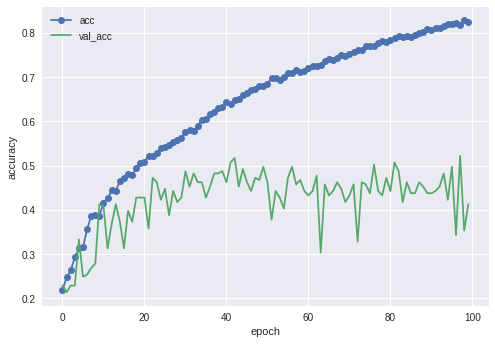
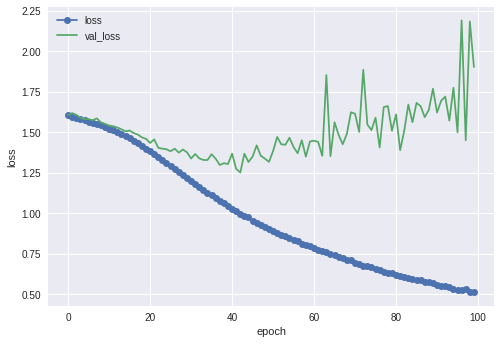
全然よくない。40%くらいしかいってない。
続いてBN層を固定した結果
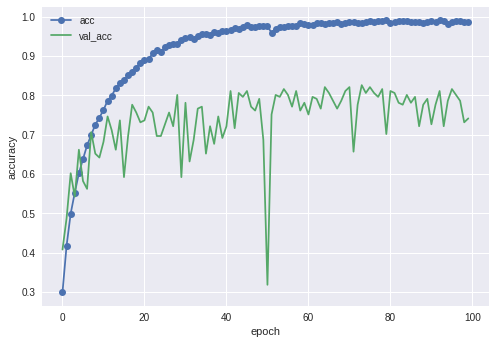
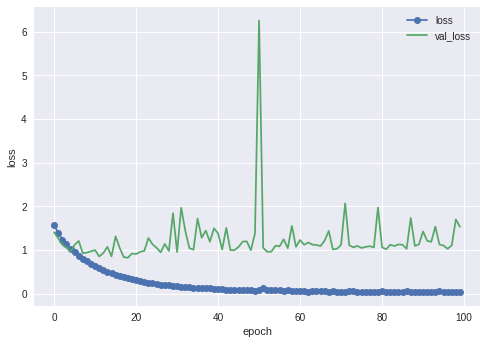
多少良くはなったものの70%台ですね。色々と全結合層いじってみたりバッチサイズ変えてみたりしたんですが改善できませんでした。ResNetが一番よくなってくれると思ってたのになんでだろう?リサイズが原因なのかな?
以上で終わります。世界的な画像コンペで使われたモデルをkerasを使うとこんなに簡単に実装できてしまうんですね。便利ですね。