1.概要
これまで公開されているDatasetを用いて、PytorchによるSemantic Segmentationの方法についていくつか紹介しました。
Semantic Segmentation紹介記事
Pytorchによる航空画像の建物セグメンテーションの作成方法.
PyTorchによるMulticlass Segmentation - 車載カメラ画像のマルチクラスセグメンテーションについて.
MMSegmentationによる多数クラス画像(Multi Class)のセマンティックセグメンテーション(Semantic Segmentation).
航空写真から道路モデルを作成する方法
ただ、これまではどなたかが用意していただいたアノテーション(マスク)データを用いていたけども、自分でアノテーションデータを作る場合、どれだけ正確につくらないといけないのか? と疑問になりました。
そこで、先日紹介した航空写真から道路モデルを作成する方法のアノテーションデータをベースにマスク画像を縮小・膨張処理することで、学習モデルからの予測(推測、Prediction)がどのように異なるのか*、比較してみましたので紹介します。
GSIデータセット
出典:国土地理院(2022)

道路のアノテーション画像と膨張処理したアノテーション画像の比較

膨張処理したアノテーションマスクより作成した学習モデルの推定結果の比較
ここで用いた道路Datasetの入手方法やアノテーションデータの縮小・膨張処理のサンプルコードをGoogle Colaboratoryにアップしましたので,ご興味のある方は試してみてください.ご参考になれば幸いです。
2. アノテーションデータの縮小・膨張処理
アノテーションデータの縮小・膨張処理は、OpenCVの機能であるモフォロジー変換を用いました。
詳しくは、モフォロジー変換の紹介ページを参考にいただければと思いますが、縮小処理(erosion)の場合、”画像に対して(フィルタリング,2D convolutionに使われる)カーネルをスライドさせていきいます.原画像中の(1か0のどちらかの値を持つ)画素は,カーネルの領域に含まれる画素の画素値が全て1であれば1となり,そうでなければ0として出力されます.”となります。
出典:モルフォロジー変換
例えば、こちらのJというイメージ(Jの部分が1,それ以外が0)に対して、縮小(erosion)処理します。

import cv2
import numpy as np
img = cv2.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv2.erode(img,kernel,iterations = 1)
ここでは、5x5のピクセルの中に0が含まれていれば、その部分を0にします。 つまり、Jの周囲を削る処理になります。

すると、上記のように処理前のイメージとしてJが細くなっているのがわかります。
このとき、iterations=1として、1回のみ処理していますが、こちらの数字を増やすことで、処理後の画像に同じ処理を複数回実施することができます。
逆に、膨張(Dilation)するときは、以下のコードとなります。
import cv2
import numpy as np
img = cv2.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
dilation = cv2.dilate(img,kernel,iterations = 1)

処理後は、上記のように膨張(Dilation) しているのがわかります。
こちらの機能をもちいて、道路のアノテーションデータを縮小・膨張処理を行います。

道路アノテーションデータの縮小・膨張処理結果
道路マスクが縮小・膨張されているのがわかります。特に、縮小時は、細い道路の場合、複数回縮小処理をするとそのものがなくなります。(Erosion2やErosion3は、5x5マスク処理を2回、3回していることを意味しています。)
実際の道路画像に重畳させてみます。

道路アノテーションデータの縮小処理

道路アノテーションデータの膨張処理
先程確認したように、細い道路は複数回の縮小処理でマスクがなくなっています。一方、膨張処理した場合、道路脇の森林や建物まで道路マスクが広がっているのがわかります。
このように、道路を道路でない(縮小処理) や 道路以外を道路である(膨張処理) したアノテーションデータを用いた学習モデルが、推定(Prediction)にどのような影響 を及ぼすのか確認します。
3. セグメンテーションモデルの作成と評価
3.1 データセットの作成
セグメンテーションモデルの準備や学習モデルの作成については、こちらの記事をご参考ください。
航空写真から道路モデルを作成する方法
今回は、前回準備した道路のアノテーションデータに、2項の縮小・膨張処理をほどこし、それをマスクデータとして用いた学習モデルを作成します。
このとき、上記の記事との違いは、TrainとValidationのアノテーションデータは縮小・膨張処理したもの 、Testのアノテーションデータは未処理のデータ(正確) を用いて評価します。
例えば、下記のようにします。
# モデル作成用と検証用にデータを確認します。
DATA_DIR = './output/'
mask_dir = './mask286_dil3/' #dilation 3のアノテーションマスク
#分割した画像データのディレクトリを指定する.
x_train_dir = os.path.join(DATA_DIR, 'train/org286/')
y_train_dir = os.path.join(DATA_DIR, 'train/' +mask_dir )
#Validataion用データ
x_valid_dir = os.path.join(DATA_DIR, 'val/org286/')
y_valid_dir = os.path.join(DATA_DIR, 'val/' + mask_dir)
#test用データ
x_test_dir = os.path.join(DATA_DIR, 'test/org286/')
y_test_dir = os.path.join(DATA_DIR, 'test/mask286/') #test maskは標準データとして、評価する
#ファイル数の確認
print(f"Train size: {len(os.listdir(x_train_dir ))}")
print(f"Valid size: {len(os.listdir(x_valid_dir ))}")
print(f"Test size: {len(os.listdir(x_test_dir ))}")
#分割した画像データのファイルリストを作成する.
x_train_files = glob.glob(x_train_dir +'/*')
y_train_files = glob.glob(y_train_dir +'/*')
このときの学習モデルのlossおよびiouの結果が以下となります。
(Google Colaboratory(無償)ではGPUが制限されるため、こちらはローカルのPC(RTX 3080)の処理結果になります。)
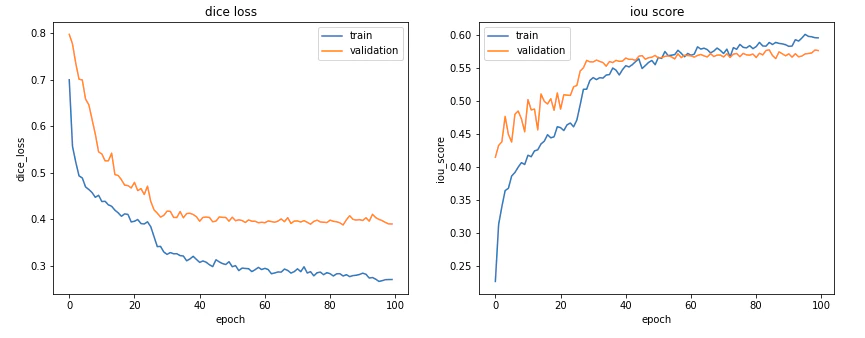
erosion3の学習推移
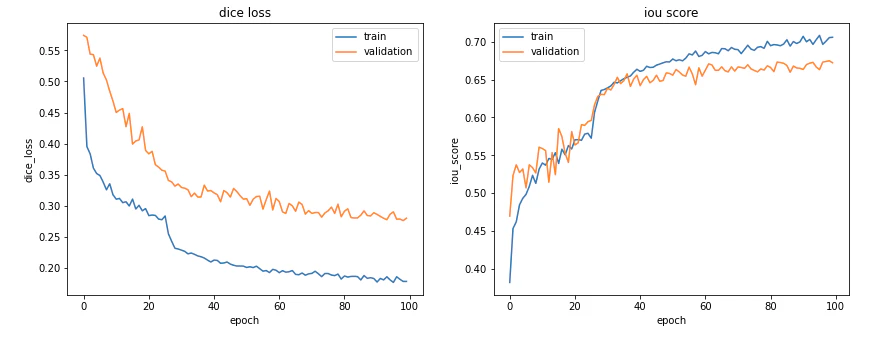
dilation3の学習推移
ここで気になるのが、膨張(Dilation)処理したアノテーションデータを用いた学習モデルの精度(IoU)が未処理のものと比べて高く なったことです。これが何を示すのかは、未処理のアノテーションデータ(test) を用いて確認します。
3.2 モデルの評価
次に、今回作成したモデルを評価します。まずは、モデルをロードします。
# 学習モデルの確認
best_model = torch.load('./best_model_Unet_resnet50.pth')
best_model
作成したモデルにテストデータを適用し評価します。まずは、テスト用のDatasetの準備です。
# create test dataset
test_dataset = Dataset(
x_test_dir,
y_test_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
test_dataloader = DataLoader(test_dataset)
# evaluate model on test set
test_epoch = smp.utils.train.ValidEpoch(
model=best_model,
loss=loss,
metrics=metrics,
device=DEVICE,
)
次に、テスト用データによりモデルを評価します。
出力
| Annotation | dice_loss | iou_score |
|---|---|---|
| Normal | 0.3117 | 0.6244 |
| Erosion1 | 0.3707 | 0.5654 |
| Erosion2 | 0.4435 | 0.4933 |
| Erosion3 | 0.5241 | 0.4359 |
| Dilation1 | 0.3486 | 0.6117 |
| Dilation2 | 0.355 | 0.5662 |
| Dilation3 | 0.398 | 0.5196 |
この結果より、膨張したアノテーションデータのほうが縮小したものよりも影響が少ない 、ということです。特に、複数回の縮小処理をしたものは影響が大きいことがわかります。これは、先程紹介したように、細い道路がアノテーションからなくなったためうまく道路を認識できなくなったことが原因と思われます。
一方、膨張処理したものはその影響があまり大きくありません。 特に、今回用いたアノテーションデータのサイズは286x286であり、5x5サイズの膨張は道路からはみ出した部分がある程度大きいにもかかわらず、その影響が少ないことがわかりました。
これらの結果は、アノテーションのデータセットを作成時の参考になると思います。
4. 学習したモデルによるテスト画像の評価
Test画像を表示するためのDatasetを作成します。
#test 画像に学習モデルを適用し、道路を検出する
test_dataset_vis = Dataset(
x_test_dir, y_test_dir,
classes=CLASSES,
)
では、準備はできたのでテスト画像より学習したモデルを用いて道路情報を作成します。
学習モデルは、それぞれの学習時に作成したモデルを読み込んで処理します。
例えばこんな感じです。
best_model_ero1 = torch.load('./best_model_Unet_resnet50_ero1.pth')
best_model_ero2 = torch.load('./best_model_Unet_resnet50_ero2.pth')
best_model_ero3 = torch.load('./best_model_Unet_resnet50_ero3.pth')
best_model_dil1 = torch.load('./best_model_Unet_resnet50_dil1.pth')
best_model_dil2 = torch.load('./best_model_Unet_resnet50_dil2.pth')
best_model_dil3 = torch.load('./best_model_Unet_resnet50_dil3.pth')
では、1000枚のテスト画像からランダムに5枚選んで出力します。
縮小(Erosion)処理結果
for i in range(5):
n = np.random.choice(len(test_dataset))
image_vis = test_dataset_vis[n][0].astype('uint8')
image, gt_mask = test_dataset[n]
gt_mask = gt_mask.squeeze()
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
pr_mask = best_model.predict(x_tensor)
pr_mask = (pr_mask.squeeze().cpu().numpy().round())
pr_mask_ero1 = best_model_ero1.predict(x_tensor)
pr_mask_ero1 = (pr_mask_ero1.squeeze().cpu().numpy().round())
pr_mask_ero2 = best_model_ero2.predict(x_tensor)
pr_mask_ero2 = (pr_mask_ero2.squeeze().cpu().numpy().round())
pr_mask_ero3 = best_model_ero3.predict(x_tensor)
pr_mask_ero3 = (pr_mask_ero3.squeeze().cpu().numpy().round())
visualize(
image=image_vis,
ground_truth_mask=gt_mask,
predicted_mask=pr_mask,
predicted_mask_erosion1=pr_mask_ero1,
predicted_mask_erosion2=pr_mask_ero2,
predicted_mask_erosion3=pr_mask_ero3,
)

縮小処理のアノテーションデータを用いた学習モデルより推定した道路地図
この結果から、大きな道路は検出できていますが、細い道路は縮小処理によりアノテーションデータからなくなったためか、識別できていない のがわかります。また、誤検知もみられました。
次に、膨張処理の結果です。
縮小(Erosion)処理結果
for i in range(5):
n = np. random.choice(len(test_dataset))
image_vis = test_dataset_vis[n][0].astype('uint8')
image, gt_mask = test_dataset[n]
gt_mask = gt_mask.squeeze()
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
pr_mask = best_model.predict(x_tensor)
pr_mask = (pr_mask.squeeze().cpu().numpy().round())
pr_mask_dil1 = best_model_dil1.predict(x_tensor)
pr_mask_dil1 = (pr_mask_dil1.squeeze().cpu().numpy().round())
pr_mask_dil2 = best_model_dil2.predict(x_tensor)
pr_mask_dil2 = (pr_mask_dil2.squeeze().cpu().numpy().round())
pr_mask_dil3 = best_model_dil3.predict(x_tensor)
pr_mask_dil3 = (pr_mask_dil3.squeeze().cpu().numpy().round())
visualize(
image=image_vis,
ground_truth_mask=gt_mask,
predicted_mask=pr_mask,
predicted_mask_dilation1=pr_mask_dil1,
predicted_mask_dilation2=pr_mask_dil2,
predicted_mask_dilation3=pr_mask_dil3,
)

膨張処理のアノテーションデータを用いた学習モデルより推定した道路地図
こちらは、縮小処理の結果と比べると、多くの道路を検出できている のがわかります。ただし、大きく膨張したデータセット(Dilation3)を用いた学習モデルより推定した道路情報は、未処理のアノテーションデータより学習したモデルの推測結果(Predicted Mask)では検出できなかった道路が検出できています。
深層学習(AI)をどのように使うかによりますが、例えば 対象を漏れなく検出したい場合(高い再現率)は、アノテーションデータは対象物よりも大きくすることで、精度を上げることができるかもしれません。 使い方によりますね。
5. まとめ
国土地理院が公開したGISデータセットを用いて、航空写真から道路を識別するデータセットを用いて、アノテーションデータの正確性がモデル(推定)に与える影響を調べてみました。
自分でアノテーションデータを作る場合、対象にたいしてどこまで(ピクセルレベルで)正確につくらないといけないのか、気になるところです(心配にもなります)。今回の結果から、その傾向を共有することができたのであれば幸いです。
私が誤解している部分や知らないことなど多々あるかと思いますので、本記事に対して忌憚なくご意見いただければ嬉しいです。また、みなさの経験をコメントにて共有いただければ、さらに嬉しいです。
6. 参考記事
GSIデータセット
衛星画像のSegmentation(セグメンテーション)により建物地図を作成する.
Pytorchによる航空画像の建物セグメンテーションの作成方法.
航空写真から道路モデルを作成する方法
モルフォロジー変換