1.概要
ぴっかりんさんのTweetで国土地理院が航空写真の深層学習用のデータセットを公開していることを知りましした。
GSIデータセット
出典:国土地理院(2022)
以前 同じく航空画像から建物セグメンテーションを行っていましたので、今回は別のデータセットで建物よりも難しいかもしれない、道路モデルを試してみました。
Pytorchによる航空画像の建物セグメンテーションの作成方法.
提供されたデータセットをみると、道路上に車や、建物の影、駐車場と道路の区別、郊外や森の道路など、建物以上に条件が複雑でした。
出典:国土地理院(2022):CNNによる道路抽出のための教師画像データ,国土地理院技術資料 H1-No.17
本記事では、提供されたデータセットから学習用の道路マスクの画像を作成し、モデルはPytorchによるSemantic Segmetation modelで学習しました。また、データセットを学習用、評価用とテスト用に分離する方法もここで紹介します。
ここで用いたコードのサンプルをGoogle Colaboratoryにアップしましたので,ご興味のある方は試してみてください.ご参考になれば幸いです。
2. データセットの前処理
最初に、提供されているサイトからデータセットを取得します。Google Colaboratoryでの取得のためwgetを用いてリンク先のデータをダウンロードし確認します。ここでは、比較的画像サイズの小さい286pixelのデータを選びました。 そして、取得したデータセットをunzipで解答し確認します。
#データのダウンロード
!wget https://gisstar.gsi.go.jp/gsi-dataset/02/H1-No17-286.zip
#ダウロードしたデータのunzip処理
import shutil
shutil.unpack_archive('./H1-No17-286.zip', 'data')
Unzipしたデータを確認すると、"org286" と"val286"の2つのフォルダが作成されており、"org286"が航空写真のみ、"val286"が航空写真に道路のマスク情報が重畳されたものになります。
イメージ数を確認します。
#画像ファイル数の確認
import glob
import os
img_dir = './data/org286/*'
val_dir = './data/val286/*'
img_files = glob.glob(img_dir)
val_files = glob.glob(val_dir)
print('画像ファイル数:', len(img_files))
出力
画像ファイル数: 10000
全部で10000枚ですね。これだけの量のアノテーション(マスク処理)は大変だったと思います。
では、取得画像を確認します。
from PIL import Image
import cv2
im_image =Image.open(img_files[100])
im_image
航空写真

val_image =Image.open(val_files[100])
val_image
航空写真とマスク画像

こちらはデータセットの例ですが、道路と近くの駐車場と同じ画像の場合、道路のみがマスクされています。(どうやって、道路と駐車場を区別したのか?)
また、視覚的にわかりやすいようにと思いますが、val286のアノテーション画像は、航空写真とマスク画像が重畳されており、学習モデルを作成するためにはマスク画像のみに分離する必要があります。まず、アノテーション画像から道路のマスク情報のみを抽出します。
説明によると、アノテーション画像の赤色がマスク情報とのことなので、まずはRGB画像からRのみを抽出しました。
import matplotlib.pyplot as plt
val_image =Image.open(val_files[100])
plt.imshow(val_r)

まずは、Rのみの1チャンネルの情報にしましたが、Rの最大値(255)のみでマスクできるのか確認します。
# Rが255を1,それ以外を0とするマスク画像に変換(簡易)
val_mask = np.where(val_r == 255, 1, 0)
plt.imshow(val_mask)
道路部分は捉えられていますが、それ以外の部分(白い車や、建物の白い屋根など)もマスクとして残っています。このままではノイズとして残ってしまうため、GreenやBlueも含めて、マスク画像を作成します。
#R:255, G:0, B:0 を1とするマスクを作成する。
val_g = val_img[:, :, 1]
val_b = val_img[:, :, 2]
mask = np.zeros(val_r.shape, dtype=np.uint8)
mask[((val_r == 255 ) & (val_g == 0)) & (val_b == 0 )] = 1
まずは、処理した画像の各ピクセルの値を確認します。
numpy_image = np.array(mask)
numpy_image

適切に処理できたようなので、画像として保存した後、表示して確認します。
plt.imsave('test.png', mask)
test_img = Image.open('./test.png')
test_img

先ほどと異なり、道路部分以外の情報は削除されており、これで適切にマスク画像が作成できることを確認しました。では、取得した画像のピクセル情報を確認します。
numpy_test = np.array(test_img)
numpy_test

すると、マスク画像が1次元ではなく、3次元構成となっており、かつマスク情報(1:道路、0:それ以外)が異なる値に変換されています。このままでは、適切に学習できないため、マスク処理した画像をarrayに変換したのち保存処理します。
pil_img = Image.fromarray(numpy_image.astype(np.uint8))
pil_img.save('./test2.png')
では、保存した画像を取得し表示します。
test2_img = Image.open('./test2.png')
#画像をarrayに変換
im_list_gt = np.asarray(test2_img )
plt.imshow(im_list_gt)
plt.show()
マスク画像のピクセル情報を確認します。
numpy_test2 = np.array(test2_img)
numpy_test2

これでマスク画像として利用できるフォーマットで処理できることを確認しましたので、取得したすべてのアノテーション画像からマスク画像を作成します。マスク画像は、あらたに作成した"mask286”のディレクトリに保存します。
# val286にある画像をmask画像に変換する。
if not os.path.exists('./data/mask286'):
os.mkdir('./data/mask286')
val_dir = './data/val286/*'
val_files = glob.glob(val_dir)
for file in val_files:
val_image =Image.open(file)
val_image_array = np.asarray(val_image)
val_r = val_image_array[:, :, 0]
val_g = val_image_array[:, :, 1]
val_b = val_image_array[:, :, 2]
mask = np.zeros(val_r.shape, dtype=np.uint8)
mask[((val_r == 255 ) & (val_g == 0)) & (val_b == 0 )] = 1
pil_img = Image.fromarray(mask.astype(np.uint8))
basename = os.path.basename(file)
pil_img.save("./data/mask286/" + basename)
では、作成したマスク画像を確認します。
はじめに、複数の画像を並べて表示するために、以下の関数を宣言します。(私はこちらをよく使っています)
# 航空機画像とマスク画像を並べて表示させるための関数を設定
def visualize(**images):
"""PLot images in one row."""
n = len(images)
plt.figure(figsize=(12, 7))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
では、ランダムに5枚選んでならべて表示させます。
img_dir = './data/org286/'
mask_dir = './data/mask286/'
file_list = os.listdir(img_dir)
for i in range(5):
n = np.random.choice(len(file_list))
visualize(
base_img= Image.open(img_dir + file_list[n]),
mask_img =Image.open(mask_dir + file_list[n]),
)

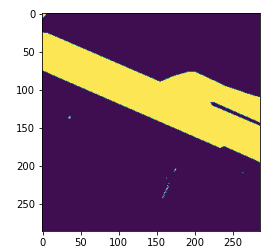
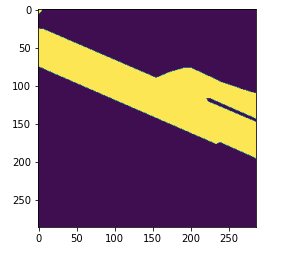
試してみていただくとわかりますが、これは多種にわたす道路データです。 駐車場と道路はどうやって区別するのか、そもそも区別できるのか気になります。影がかかっている道路もあります。
次に、航空写真とマスク画像を重ねて表示させ、アノテーションがどのようにつくられているのか(特に、道路とそれ以外をどのレベルまで区別しているのか)確認してみます。
#maskのチェック
#対象とする航空写真のファイルを取得
img_dir = './data/org286/'
mask_dir = './data/mask286/'
#water bodyディレクトリのファイル名の取得
file_name_extension =[]
img_files= os.listdir(img_dir)
#print(len(img_files))
img_files.sort()
for i in img_files:
file_name_extension.append(i)
file_name_extension.sort()
for i in range(10):
n = np.random.choice(len(file_name_extension))
file_name = os.path.splitext(os.path.basename(file_name_extension[n]))[0]
im_image = cv2.imread(img_dir+ file_name +'.png')
im_image = cv2.cvtColor(im_image, cv2.COLOR_BGR2RGB)
im_mask = cv2.imread(mask_dir + file_name +'.png')[...,0].squeeze()
im_mask2 = cv2.cvtColor(im_mask, cv2.COLOR_GRAY2BGR)
im_mask2 = im_mask2 * 150 # 255/im_test_mask2.max()
heatmap = cv2.applyColorMap(im_mask2, cv2.COLORMAP_RAINBOW)
blended = cv2.addWeighted(src1=im_image,alpha=0.6,src2= heatmap,beta=0.3,gamma=0)
visualize(
image = im_image,
image_with_mask=blended,
)

これは難しい。2枚めの駐車場なんて、人間が見ればわかるけども、学習モデルが本当に区別できるのか、疑問でもあり興味があります。
今回はこれ以上の処理はせず、学習モデルを作成しテストします。
3. セグメンテーションモデルの作成と評価
3.1 データセットの作成
今回は、準備した航空画像とマスク画像を、学習用、評価用およびテスト用にわけてモデルの作成とその評価を行います。
データの分離は以下の記事を参考にしました。
Easily Split Your Directory Into Train, Validation, and Testing Format
データ分離用のモジュールをインストールします。
!pip install split-folders
データを、7割を学習用、2割を評価用、1割をテスト用に分離します。
import splitfolders
splitfolders.ratio('./data/', output="output", seed=1337, ratio=(.7, 0.2,0.1))
では、作成したデータを確認します。
# モデル作成用と検証用にデータを確認します。
DATA_DIR = './output/'
#分割した画像データのディレクトリを指定する.
x_train_dir = os.path.join(DATA_DIR, 'train/org286/')
y_train_dir = os.path.join(DATA_DIR, 'train/mask286/')
#Validataion用データ
x_valid_dir = os.path.join(DATA_DIR, 'val/org286/')
y_valid_dir = os.path.join(DATA_DIR, 'val/mask286/')
#test用データ
x_test_dir = os.path.join(DATA_DIR, 'test/org286/')
y_test_dir = os.path.join(DATA_DIR, 'test/mask286/')
#ファイル数の確認
print(f"Train size: {len(os.listdir(x_train_dir ))}")
print(f"Valid size: {len(os.listdir(x_valid_dir ))}")
print(f"Test size: {len(os.listdir(x_test_dir ))}")
#分割した画像データのファイルリストを作成する.
x_train_files = glob.glob(x_train_dir +'/*')
y_train_files = glob.glob(y_train_dir +'/*')
出力
Train size: 7000
Valid size: 2000
Test size: 1000
データが適切に分離できていることを確認しました。
次に、Pytorchでのデータセットを準備します。こちらについては、過去の記事に詳細を説明していますので、こちらをご参考ください。
はじめに、使用している環境を確認します。GPUを設定できているのも確認できます。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
if not torch.cuda.is_available():
raise Exception("GPU not availalbe. CPU training will be too slow.")
print("GPU device name", torch.cuda.get_device_name(0))
次に、モジュールをimportします。
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
では、Datasetを宣言します。
class Dataset(BaseDataset):
"""CamVid Dataset. Read images, apply augmentation and preprocessing transformations.
Args:
images_dir (str): path to images folder
masks_dir (str): path to segmentation masks folder
class_values (list): values of classes to extract from segmentation mask
augmentation (albumentations.Compose): data transfromation pipeline
(e.g. flip, scale, etc.)
preprocessing (albumentations.Compose): data preprocessing
(e.g. noralization, shape manipulation, etc.)
"""
CLASSES = ['unlabelled', 'road'] #変更
def __init__(
self,
images_dir,
masks_dir,
classes=None,
augmentation=None,
preprocessing=None,
):
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
# convert str names to class values on masks
self.class_values = [self.CLASSES.index(cls.lower()) for cls in classes]
#print(self.class_values)
self.augmentation = augmentation
self.preprocessing = preprocessing
def __getitem__(self, i):
# read data
image = cv2.imread(self.images_fps[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(self.masks_fps[i], 0)
#mask = np.array(Image.open(self.masks_fps[i]))
#print(self.images_fps[i])
#print(self.masks_fps[i])
#print(mask)
# extract certain classes from mask (e.g. cars)
masks = [(mask == v) for v in self.class_values]
#print(masks)
mask = np.stack(masks, axis=-1).astype('float')
# apply augmentations
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# apply preprocessing
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
return image, mask
def __len__(self):
return len(self.ids)
宣言したDatasetに学習用データをインプットし、処理結果を確認します。
dataset = Dataset(x_train_dir, y_train_dir, classes=['road'])
image, mask = dataset[13] # get some sample
visualize(
image=image,
road_mask=mask.squeeze(),
)

うん、難しい。(本当に、道路と駐車場(それ以外)どのルールで区別されたのか。くどい。)
次に、データ拡張(Augumantation)を実行します。
まずは有名なモジュールのインストールです。
!pip install -U git+https://github.com/albu/albumentations --no-cache-dir
では、データ拡張の関数を宣言します。
import albumentations as albu
def get_training_augmentation():
train_transform = [
albu.HorizontalFlip(p=0.5),
albu.ShiftScaleRotate(scale_limit=0.5, rotate_limit=0, shift_limit=0.1, p=1, border_mode=0),
albu.PadIfNeeded(min_height=320, min_width=320, always_apply=True, border_mode=0),
albu.RandomCrop(height=320, width=320, always_apply=True),
albu.IAAAdditiveGaussianNoise(p=0.2),
albu.IAAPerspective(p=0.5),
albu.OneOf(
[
albu.CLAHE(p=1),
albu.RandomBrightness(p=1),
albu.RandomGamma(p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.IAASharpen(p=1),
albu.Blur(blur_limit=3, p=1),
albu.MotionBlur(blur_limit=3, p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.RandomContrast(p=1),
albu.HueSaturationValue(p=1),
],
p=0.9,
),
]
return albu.Compose(train_transform)
def get_validation_augmentation():
"""Add paddings to make image shape divisible by 32"""
test_transform = [
albu.PadIfNeeded(288, 288)
]
return albu.Compose(test_transform)
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
def get_preprocessing(preprocessing_fn):
"""Construct preprocessing transform
Args:
preprocessing_fn (callbale): data normalization function
(can be specific for each pretrained neural network)
Return:
transform: albumentations.Compose
"""
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
こちらの関数のパレメータはデフォルトのままです。何が効果あるのか、学習結果を参考に、皆さんで試してみてください。
では、拡張データを確認します。
augmented_dataset = Dataset(
x_train_dir,
y_train_dir,
augmentation=get_training_augmentation(),
classes=['road'],
)
# same image with different random transforms
for i in range(3):
image, mask = augmented_dataset[261]
visualize(image=image, mask=mask.squeeze(-1))

次に、今回用いるセグメンテーションモジュールである、Segmentation models pytorchをインストールします。
!pip install segmentation-models-pytorch
その後、モジュールのimport、モデルの宣言、Dataset、Dataloaderの設定、ロス関数等を設定し、学習を実行します。
import torch
import numpy as np
import segmentation_models_pytorch as smp
ENCODER = 'resnet50'
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['road']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multicalss segmentation
DEVICE = 'cuda'
# create segmentation model with pretrained encoder
model = smp.Unet(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
train_dataset = Dataset(
x_train_dir,
y_train_dir,
augmentation=get_training_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
valid_dataset = Dataset(
x_valid_dir,
y_valid_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=12)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=4)
from segmentation_models_pytorch import utils as smp_utils
#smp.utilsでエラーとなるため、こちらを使用
loss = smp_utils.losses.DiceLoss()
metrics = [
smp.utils.metrics.IoU(threshold=0.5),
]
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=0.0001),
])
train_epoch = smp.utils.train.TrainEpoch(
model,
loss=loss,
metrics=metrics,
optimizer=optimizer,
device=DEVICE,
verbose=True,
)
valid_epoch = smp.utils.train.ValidEpoch(
model,
loss=loss,
metrics=metrics,
device=DEVICE,
verbose=True,
)
では、モデルやDatasetの設定が終わりましたので、学習を実行します。Colaboratoryでは、使用時間の制限から30エポックまでとしていますが、こちらでは100まで実行しました。
max_score = 0
#train accurascy, train loss, val_accuracy, val_loss をグラフ化できるように設定.
x_epoch_data = []
train_dice_loss = []
train_iou_score = []
valid_dice_loss = []
valid_iou_score = []
for i in range(0, 100): #学習モデルの精度を高めたいときは、こちらの数字を大きくします。ただし、それだけ学習に時間がかかります。
print('\nEpoch: {}'.format(i))
train_logs = train_epoch.run(train_loader)
valid_logs = valid_epoch.run(valid_loader)
x_epoch_data.append(i)
train_dice_loss.append(train_logs['dice_loss'])
train_iou_score.append(train_logs['iou_score'])
valid_dice_loss.append(valid_logs['dice_loss'])
valid_iou_score.append(valid_logs['iou_score'])
# do something (save model, change lr, etc.)
if max_score < valid_logs['iou_score']:
max_score = valid_logs['iou_score']
torch.save(model, './best_model_Unet_resnet50.pth')
print('Model saved!')
if i == 25:
optimizer.param_groups[0]['lr'] = 1e-5
print('Decrease decoder learning rate to 1e-5!')
if i == 50:
optimizer.param_groups[0]['lr'] = 5e-6
print('Decrease decoder learning rate to 1e-6!')
これで学習が終了しましたので、モデルを評価します。
3.2 セグメンテーションモデルの作成
学習中のモデルの評価をlogsファイルに保存していましたので、そちらを読み込みます。
fig = plt.figure(figsize=(14, 5))
ax1 = fig.add_subplot(1, 2, 1)
line1, = ax1.plot(x_epoch_data,train_dice_loss,label='train')
line2, = ax1.plot(x_epoch_data,valid_dice_loss,label='validation')
ax1.set_title("dice loss")
ax1.set_xlabel('epoch')
ax1.set_ylabel('dice_loss')
ax1.legend(loc='upper right')
ax2 = fig.add_subplot(1, 2, 2)
line1, = ax2.plot(x_epoch_data,train_iou_score,label='train')
line2, = ax2.plot(x_epoch_data,valid_iou_score,label='validation')
ax2.set_title("iou score")
ax2.set_xlabel('epoch')
ax2.set_ylabel('iou_score')
ax2.legend(loc='upper left')
plt.show()
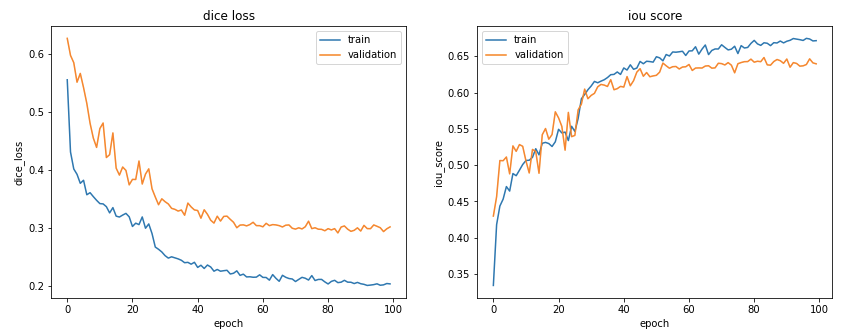
Dice Lossの低下、およびIoUの上昇が確認できました。
ただ、Trainデータは上がっていますが、Valデータの向上はそれほどみられませんね。
これ以上学習すると、過学習になるかもしれません。
3.3 モデルの評価
次に、今回作成したモデルを評価します。まずは、モデルをロードします。
# 学習モデルの確認
best_model = torch.load('./best_model_Unet_resnet50.pth')
best_model
作成したモデルにテストデータを適用し評価します。まずは、テスト用のDatasetの準備です。
# create test dataset
test_dataset = Dataset(
x_test_dir,
y_test_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
test_dataloader = DataLoader(test_dataset)
# evaluate model on test set
test_epoch = smp.utils.train.ValidEpoch(
model=best_model,
loss=loss,
metrics=metrics,
device=DEVICE,
)
次に、テスト用データによりモデルを評価します。
logs = test_epoch.run(test_dataloader)
出力
valid: 100%|██████████| 1000/1000 [00:37<00:00, 26.98it/s, dice_loss - 0.3117, iou_score - 0.6244]
IoUが0.62とあまり高くありません。それなりには、道路が識別できたかな、というところです。
では、実際のテスト画像を用いて結果を確認します。
4. 学習したモデルによるテスト画像の評価
Test画像を表示するためのDatasetを作成します。
#test 画像に学習モデルを適用し、道路を検出する
test_dataset_vis = Dataset(
x_test_dir, y_test_dir,
classes=CLASSES,
)
では、準備はできたのでテスト画像より学習したモデルを用いて道路情報を作成します。
ランダムに1000枚の画像から5枚選んでいますので、実行を繰り返すといろいろな画像にかわります。
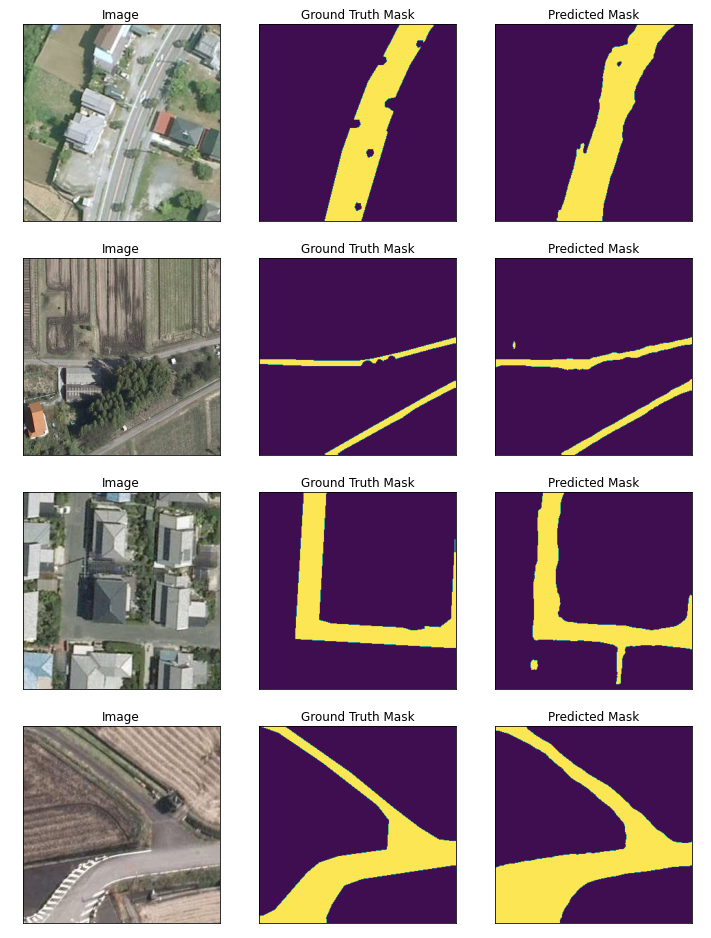
for i in range(5):
n = np.random.choice(len(test_dataset))
image_vis = test_dataset_vis[n][0].astype('uint8')
image, gt_mask = test_dataset[n]
gt_mask = gt_mask.squeeze()
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
pr_mask = best_model.predict(x_tensor)
pr_mask = (pr_mask.squeeze().cpu().numpy().round())
visualize(
image=image_vis,
ground_truth_mask=gt_mask,
predicted_mask=pr_mask
)

結果をみると、道路でない部分の誤検知はないようにみえますが、道路のような場所である駐車場は道路と誤検知されていたり、逆に道路未検出のようなものがみられます。
画像に駐車場が含まれているは、前処理をすることで誤検知を削減できそうです。(今はアイデアはありませんが)
ただ、これらの航空写真から道路のみを正確に抽出するのは難しい。
説明によると、”物抽出性能が一定以上(抽出性能の評価に用いられる一般的な指標の一つであるF値という値が0.800以上となったもの)”とのことですので、是非 ベースマップとなるモデルを紹介いただけると嬉しいです。
5. まとめ
国土地理院が公開したGISデータセットを用いて、航空写真から道路を識別するセグメンテーションモデルの作成方法を紹介しました。
深層学習を学ぶための画像とアノテーション(マスク)画像のデータセットはいくつか公開されていますが、今回のように日本にて航空写真のデータセットが提供はあまりないかと思います。しかも、10000枚もの画像を準備するのは大変だったと思います。国土地理院には、このような場を準備いただく感謝いたします。(ただ、道路は難しいです)
今回は航空写真でしたが、次回は衛星画像からの道路の識別や、建物の形状モデルの作成など、何か新しいことに挑戦していきます。
航空機や人工衛星の画像に関心を持つ方が多くなり,その応用の発展に寄与できれば幸いです.
6. 参考記事
GSIデータセット
衛星画像のSegmentation(セグメンテーション)により建物地図を作成する.
Pytorchによる航空画像の建物セグメンテーションの作成方法.
Segmentation Models
Easily Split Your Directory Into Train, Validation, and Testing Format