1.概要
これまで公開されているDatasetを用いて、PytorchによるSemantic Segmentationの方法についていくつか紹介しました。
Semantic Segmentation紹介記事
Pytorchによる航空画像の建物セグメンテーションの作成方法.
PyTorchによるMulticlass Segmentation - 車載カメラ画像のマルチクラスセグメンテーションについて.
MMSegmentationによる多数クラス画像(Multi Class)のセマンティックセグメンテーション(Semantic Segmentation).
航空写真から道路モデルを作成する方法
ここで用いたSemantic Segmentationの学習モデルは、公開されているパラメータをそのまま使用していました。このモデルでは、学習率はあるエポック数にて段階的に変化させる単純なものでした。
そこで学習率をエポック数にあわせて変えるとモデルの精度がどれほど変わるのか、今回は実験してました。
偶然にも、Kaggleの有名人の方々が執筆された「Kaggleに挑む深層学習プログラミングの極意」にて、小嵜さん(@smly)さんが担当された「3章 画像分類入門」にて、学習率の影響を紹介されており、大きめの学習率での最適化を行ってから学習率を小さくしていったほうがよい理由を説明されています。ご関心があるかたは、是非こちらの本をご参考にしてください。
(個人的ですが、2年ほど前に深層学習の画像技術を出版準備していると聞き、首をかなり長ーくして待っていました。 購入して、何度も読み直しています。)
pytorchによる学習率カーブについては、以下に例がまとめられていますので、ご参考ください。
Guide to Pytorch Learning Rate Scheduling
ここで用いた道路Datasetの入手方法や各種学習率カーブを用いたサンプルコードをGoogle Colaboratoryにアップしましたので,ご興味のある方は試してみてください.ご参考になれば幸いです。
2. PytorchのSchedulerを用いた学習率カーブ
pytorchによる学習率カーブがどういった学習が進むとどのように変化するのか、繰り返しになりますがこちらをご参考ください。
では、以前紹介した航空写真から道路モデルを作成する方法をベースに、学習率をSchedulerを用いてエポック数にあわせて変更します。
#StepLR
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.4)
#MultiSteLR
#scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[25,50,], gamma=0.1)
#LAMBDA LR
#lambda1 = lambda epoch: 0.955** epoch
#scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)
#ExpotentialLR
#scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.955)
#CosineAnnealing LR
#scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
ここでは、学習の最初と最後が同じになるよう、それぞれのパラメータを調整しています。具体的には、最初は1E-4とし、100エポックで1E-6になるようにしています。
今回はSchedulerを用いますので、モデル作成部分のコードも変更しました。
max_score = 0
#train accurascy, train loss, val_accuracy, val_loss をグラフ化できるように設定.
x_epoch_data = []
train_dice_loss = []
train_iou_score = []
valid_dice_loss = []
valid_iou_score = []
lerning_rate = []
for i in range(0, 25): #学習モデルの精度を高めたいときは、こちらの数字を大きくします。ただし、それだけ学習に時間がかかります。
print('\nEpoch: {}'.format(i))
train_logs = train_epoch.run(train_loader)
valid_logs = valid_epoch.run(valid_loader)
x_epoch_data.append(i)
train_dice_loss.append(train_logs['dice_loss'])
train_iou_score.append(train_logs['iou_score'])
valid_dice_loss.append(valid_logs['dice_loss'])
valid_iou_score.append(valid_logs['iou_score'])
lerning_rate.append(optimizer.param_groups[0]['lr'])
# do something (save model, change lr, etc.)
if max_score < valid_logs['iou_score']:
max_score = valid_logs['iou_score']
torch.save(model, './best_model_Unet_resnet50.pth') #modelを再利用するときは、モデル名を適切に変更
print('Model saved!')
scheduler.step()
前回との違いは、学習ループで、scheduler.step()を用いて、設定したSchedulerにあわせて学習率をエポック毎に変化させます。また、学習率の履歴も残しています。
では、各学習率カーブによる結果を示します。
3. 学習率カーブによる学習モデルの精度検証
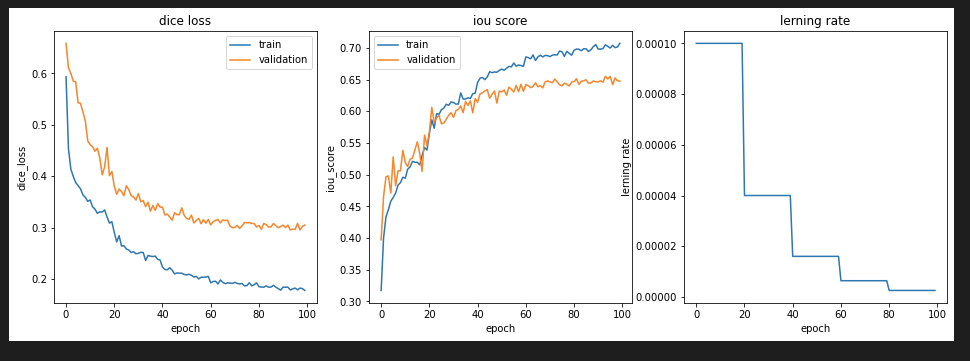
Single Step LR
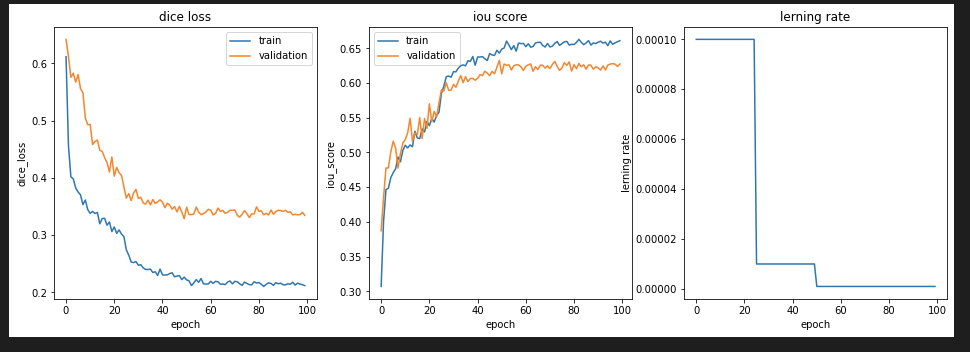
Multi Step LR
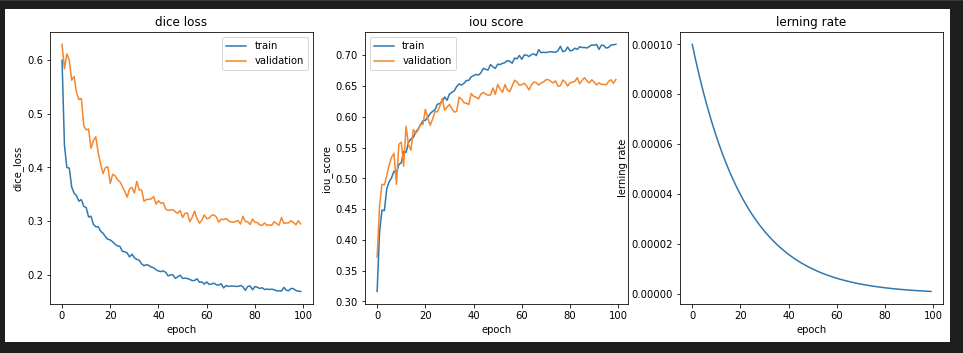
Lambda LR
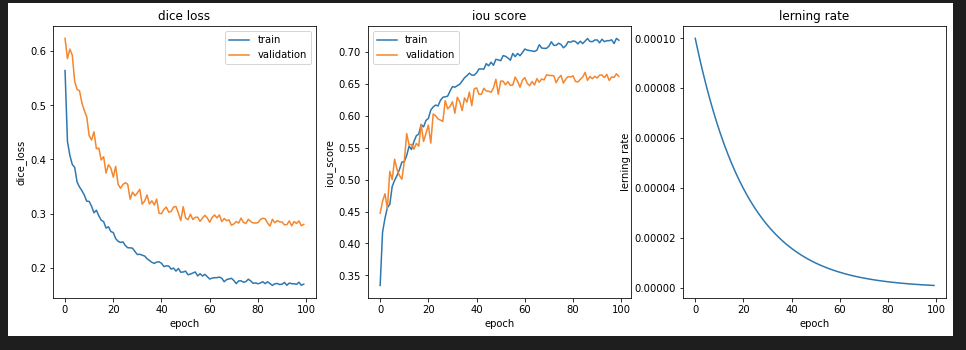
Exponential LR
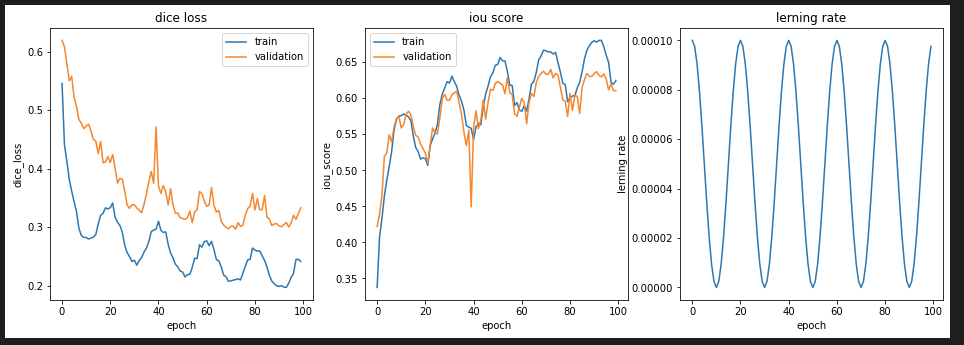
Cosine Annealing LR
前回のMulti Stepの学習率カーブのときは、TrainデータのDice Lossが0.2以下にならなかったのですが、今回はLambdaLRやExponential LRでDice Lossが0.17まで減少しました。
Cosine Annealing LRについて、「Kaggleに挑む深層学習プログラミングの極意」で紹介されている、最終エポック数で学習率が最小となるように修正すると、こちらのような結果となりました。
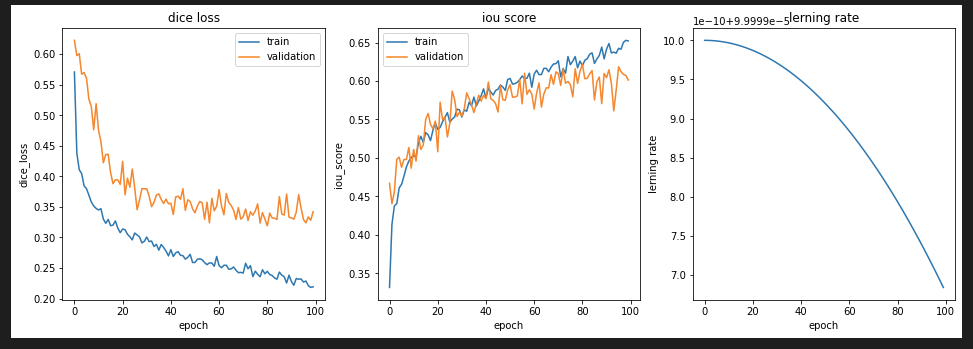
Cosine Annealing LR改
このとき、Multi Stepのときとおなじく、Dice Lossは0.2以上となりました。こちらをみると、学習率の低下率は、エポック数にあわせてまずは大きく減少させておき、学習がすすんでからはその変化を小さくしたほうがよい結果となりました。これは、一般的な学習率とモデル精度との関係で紹介されている学習を進めて学習率を小さくすることで最適解により近づけるに傾向があっていると思います。(例えば、第3回 ディープラーニング最速入門 ― 仕組み理解×初実装(後編)の(5)”学習方法”の設計とモデルの生成:学習率をご参照ください。図で紹介されていますので、イメージがつかみやすいと思います。)
次に、学習や評価で用いなかったテストデータを用いて各学習モデルを評価します。
出力
| Learning Rate Method | dice_loss | iou_score |
|---|---|---|
| Single Step | 0.2949 | 0.6562 |
| Multi Step | 0.3354 | 0.6229 |
| Lambda | 0.2917 | 0.6587 |
| Exponential | 0.2823 | 0.6624 |
| Cosine Annelaing | 0.303 | 0.6303 |
| Cosine Annelaing改 | 0.331 | 0.6075 |
これより、同じ学習量でも、学習率カーブにより予測精度に違いがあるのがわかりました。特に、今回は学習初期に大きく減少させた方が、最終的なモデル精度が向上しています。
4. 学習量による予測精度の改善について
最後に、今回は"Lambda"の学習率カーブにて、学習量を大きくすることでモデル精度がどれだけ改善されるのか試してみました。ここでは、100エポックで学習率を1E-6まで減少させ、1000エポックまではその値を維持しました。結果が以下となります。
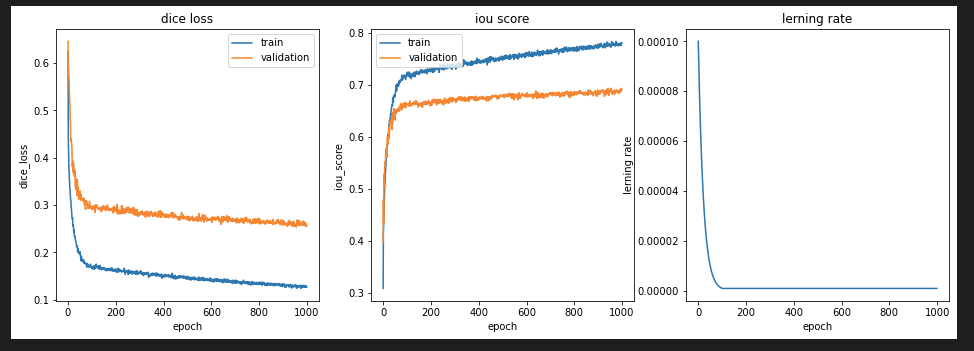
Lambda LR, epoch:1000
100エポックから学習率を同じにしても、学習量を増やすことでDice Lossが改善されているのがわかります。TrainデータのDice Lossは最終的には0.1262まで改善されました。Trainデータのみ改善されていないことから、過学習が発生していないこともわかりました。
それでではテストデータの予測結果を比較してみます。
出力
| Learning Rate Method | dice_loss | iou_score |
|---|---|---|
| Lambda, epoch:100 | 0.2917 | 0.6587 |
| Lambda, epoch:1000 | 0.2558 | 0.6869 |
やはり、学習量(エポック数)は正義ですね。学習するだけ精度が改善されています。
最後に、1000エポックの学習モデルを使った航空写真の道路の抽出結果です。

正解(中央)と比べて予測結果(右)がかなり一致しているのがわかります。前回と比べても改善されていますね。
5. まとめ
国土地理院が公開したGISデータセットとして公開されている航空写真から道路を識別するデータセットを用いて、学習率カーブが学習モデルとその予測精度に与える影響について実験しました。
大事なことは、「Kaggleに挑む深層学習プログラミングの極意」にも書かれていますが、まずは対象とするデータ・セットそのものの理解を深め、その後の改善方法として今回紹介したような各種の学習率カーブを用いて改善傾向を試してみるのがよいと思います。
私が誤解している部分や知らないことなど多々あるかと思いますので、本記事に対して忌憚なくご意見いただければ嬉しいです。また、みなさの経験をコメントにて共有いただければ、さらに嬉しいです。
6. 参考記事
GSIデータセット
衛星画像のSegmentation(セグメンテーション)により建物地図を作成する.
Pytorchによる航空画像の建物セグメンテーションの作成方法.
航空写真から道路モデルを作成する方法
Kaggleに挑む深層学習プログラミングの極意