はじめに
AWSでDBのレプリケーションを行うのに一番お手軽なのがAuroraやRDSのRead Replicaの機能を使うことだが、たとえば異なるDBMSや、Aurora⇒DynamoDBにレプリケーションをしたくなることもあるだろう。
そういう時には、DMS(Database Migration Service)のレプリケーションインスタンスが便利だ。今回は、最もシンプルな同一のネットワーク内、同一のDMBSに対してレプリケーションするDMSインスタンスをTerraformで自動構築してみよう。
前提知識としては、以下あたり。
- TerraformでのAWSサービスの構築経験がある
- Auroraについてある程度理解している
Auroraについては、SourceとTargetを構築済みであることを前提にしているため、この記事あたりも参考にして構築しておいていただきたい。
全体構成
DMSのレプリケーションインスタンスの構成要素は以下の通り。
- レプリケーションインスタンス
- サブネットグループ
- エンドポイント
- データベース移行タスク
それぞれの要素について、ポイントを抑えながら構築していこう。
準備
なお、今回はソースDBをMySQLにしている。MySQLをソースにする場合、DBクラスターパラメータグループに以下の設定を入れておく必要がある。
AWS公式のユーザーガイドでは、「binlog_format パラメータを ROW、STATEMENT、または MIXED に設定します」と書いてあるが、ROW以外はエラーになったので注意。
なお、この項目はapply_methodにimmediateが設定できないため、後で追加した場合はAuroraの再起動をしておく必要がある。
parameter {
name = "binlog_format"
value = "ROW"
apply_method = "pending-reboot"
}
レプリケーションインスタンス
レプリケーションインスタンスは、aws_dms_replication_instanceのリソースで作成する。
特段難しい部分はないが、商用利用するときはmulti_azをtrueに設定して耐障害性を高めよう。
preferred_maintenance_windowは設定しない場合、ランダムに設定される。
また、以下の例では設定していないが、vpc_security_group_idsでセキュリティグループをアタッチできる。デフォルトでは、VPCのデフォルトセキュリティグループがアタッチされるため、必要に応じてアドレスとポートを絞ろう。
resource "aws_dms_replication_instance" "example" {
replication_instance_id = local.replication_instance_identifier
engine_version = "3.4.5"
replication_instance_class = "dms.t2.micro"
allocated_storage = 5
publicly_accessible = true
multi_az = false
availability_zone = data.aws_subnet.for_dms_instance.availability_zone
replication_subnet_group_id = aws_dms_replication_subnet_group.example.id
preferred_maintenance_window = "sun:10:30-sun:14:30"
apply_immediately = true
auto_minor_version_upgrade = false
}
サブネットグループ
サブネットグループは、aws_dms_replication_subnet_groupのリソースでレプリケーションインスタンスの所属するサブネットを定義する。
Auroraのサブネットグループと同じような考え方だ。
data "aws_subnet_ids" "my_vpc" {
vpc_id = data.aws_vpc.my.id
}
resource "aws_dms_replication_subnet_group" "example" {
replication_subnet_group_id = local.replication_subnet_group_identifier
replication_subnet_group_description = local.replication_subnet_group_description
subnet_ids = data.aws_subnet_ids.my_vpc.ids
}
エンドポイント
エンドポイントは、aws_dms_endpointのリソースで、ソースDBとターゲットDBのエンドポイントの設定を行い、レプリケーション移行タスクに渡す。
Auroraの場合は以下のように設定すれば良い。
resource "aws_dms_endpoint" "source" {
endpoint_id = local.replication_source_endpoint_identifier
endpoint_type = "source"
engine_name = "aurora"
server_name = aws_rds_cluster.source.endpoint
database_name = local.aurora_source_database_name
username = local.aurora_source_master_username
password = local.aurora_source_master_password
port = 3306
}
resource "aws_dms_endpoint" "target" {
endpoint_id = local.replication_target_endpoint_identifier
endpoint_type = "target"
engine_name = "aurora"
server_name = aws_rds_cluster.target.endpoint
database_name = local.aurora_target_database_name
username = local.aurora_target_master_username
password = local.aurora_target_master_password
port = 3306
}
データベース移行タスク
さて、あと一歩といったところだが、ここからが大変だ。
データベース移行タスクは、aws_dms_replication_taskで定義する。
replication_instance_arn/source_endpoint_arn/target_endpoint_arnは、ここまでに定義してきたリソースを参照する。
migration_typeには、全データ移行か差分移行かを定義可能だ。今回は、差分移行のみを試してみるため、cdc(Change Data Capture)を設定する。CDCには、「いつからの差分をレプリケーションするか」の日時をcdc_start_timeで渡す。この項目がUNIXタイムスタンプを渡す必要があり面倒なので、time_staticモジュールを使おう。time_staticモジュールでは、RFC3339形式で渡せて、日本のタイムゾーンでも設定が可能なので分かりやすい(例: 2021-08-21T11:00:00+09:00で日本時間の午前11時で渡せる)
resource "aws_dms_replication_task" "example" {
replication_task_id = local.replication_task_identifier
replication_instance_arn = aws_dms_replication_instance.example.replication_instance_arn
source_endpoint_arn = aws_dms_endpoint.source.endpoint_arn
target_endpoint_arn = aws_dms_endpoint.target.endpoint_arn
migration_type = "cdc"
cdc_start_time = time_static.cdc.unix
replication_task_settings = file("./dms_replication_task_setting.json")
table_mappings = file("./dms_table_mapping.json")
}
resource "time_static" "cdc" {
rfc3339 = local.replication_cdc
}
レプリケーションタスクの設定
レプリケーションの詳細は、JSON形式で定義する。
この部分は、ユーザーガイドを参考に詳細を決定していく必要があるが、今回は「とりあえず動かす」ことが目的なので、デフォルトの設定そのままを使用する。
{
"TargetMetadata": {
"TargetSchema": "",
"SupportLobs": true,
"FullLobMode": false,
"LobChunkSize": 64,
"LimitedSizeLobMode": true,
"LobMaxSize": 32,
"InlineLobMaxSize": 0,
"LoadMaxFileSize": 0,
"ParallelLoadThreads": 0,
"ParallelLoadBufferSize": 0,
"BatchApplyEnabled": false,
"TaskRecoveryTableEnabled": false,
"ParallelLoadQueuesPerThread": 0,
"ParallelApplyThreads": 0,
"ParallelApplyBufferSize": 0,
"ParallelApplyQueuesPerThread": 0
},
"FullLoadSettings": {
"CreatePkAfterFullLoad": false,
"StopTaskCachedChangesApplied": false,
"StopTaskCachedChangesNotApplied": false,
"MaxFullLoadSubTasks": 8,
"TransactionConsistencyTimeout": 600,
"CommitRate": 10000
},
"Logging": {
"EnableLogging": false,
"LogComponents": [
{
"Id": "SOURCE_UNLOAD",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "SOURCE_CAPTURE",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TARGET_LOAD",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TARGET_APPLY",
"Severity": "LOGGER_SEVERITY_DEFAULT"
},
{
"Id": "TASK_MANAGER",
"Severity": "LOGGER_SEVERITY_DEFAULT"
}
],
"CloudWatchLogGroup": null,
"CloudWatchLogStream": null
},
"ControlTablesSettings": {
"ControlSchema": "",
"HistoryTimeslotInMinutes": 5,
"HistoryTableEnabled": false,
"SuspendedTablesTableEnabled": false,
"StatusTableEnabled": false
},
"StreamBufferSettings": {
"StreamBufferCount": 3,
"StreamBufferSizeInMB": 8,
"CtrlStreamBufferSizeInMB": 5
},
"ChangeProcessingDdlHandlingPolicy": {
"HandleSourceTableDropped": true,
"HandleSourceTableTruncated": true,
"HandleSourceTableAltered": true
},
"ErrorBehavior": {
"DataErrorPolicy": "LOG_ERROR",
"DataTruncationErrorPolicy": "LOG_ERROR",
"DataErrorEscalationPolicy": "SUSPEND_TABLE",
"DataErrorEscalationCount": 0,
"TableErrorPolicy": "SUSPEND_TABLE",
"TableErrorEscalationPolicy": "STOP_TASK",
"TableErrorEscalationCount": 0,
"RecoverableErrorCount": -1,
"RecoverableErrorInterval": 5,
"RecoverableErrorThrottling": true,
"RecoverableErrorThrottlingMax": 1800,
"RecoverableErrorStopRetryAfterThrottlingMax": false,
"ApplyErrorDeletePolicy": "IGNORE_RECORD",
"ApplyErrorInsertPolicy": "LOG_ERROR",
"ApplyErrorUpdatePolicy": "LOG_ERROR",
"ApplyErrorEscalationPolicy": "LOG_ERROR",
"ApplyErrorEscalationCount": 0,
"ApplyErrorFailOnTruncationDdl": false,
"FullLoadIgnoreConflicts": true,
"FailOnTransactionConsistencyBreached": false,
"FailOnNoTablesCaptured": false
},
"ChangeProcessingTuning": {
"BatchApplyPreserveTransaction": true,
"BatchApplyTimeoutMin": 1,
"BatchApplyTimeoutMax": 30,
"BatchApplyMemoryLimit": 500,
"BatchSplitSize": 0,
"MinTransactionSize": 1000,
"CommitTimeout": 1,
"MemoryLimitTotal": 1024,
"MemoryKeepTime": 60,
"StatementCacheSize": 50
},
"ValidationSettings": {
"EnableValidation": false,
"ValidationMode": "ROW_LEVEL",
"ThreadCount": 5,
"FailureMaxCount": 10000,
"TableFailureMaxCount": 1000,
"HandleCollationDiff": false,
"ValidationOnly": false,
"RecordFailureDelayLimitInMinutes": 0,
"SkipLobColumns": false,
"ValidationPartialLobSize": 0,
"ValidationQueryCdcDelaySeconds": 0,
"PartitionSize": 10000
},
"PostProcessingRules": null,
"CharacterSetSettings": null,
"LoopbackPreventionSettings": null,
"BeforeImageSettings": null
}
テーブルマッピングの設定
テーブルマッピングもJSONで定義する。
ここも、データ変換やカラム名変換、フィルタ等色々なことができるので、ユーザーガイドを参考に目的によって中身を書いていこう。
今回は、Aurora(MySQL)のCOMPANYデータベースの中身を全部レプリケーションするということで、以下の設定を行う。
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "COMPANY",
"table-name": "%"
},
"rule-action": "include"
}
]
}
レプリケーションを開始する
これまでの設定をterraform applyすると、一通り必要なリソースが作成されるが、移行タスクは自動では開始しない。
DMSのマネージメントコンソールからタスクを開始しよう。

しばらくすると、ステータスが「レプリケーション進行中」になり、テーブルの統計が見られるようになる。
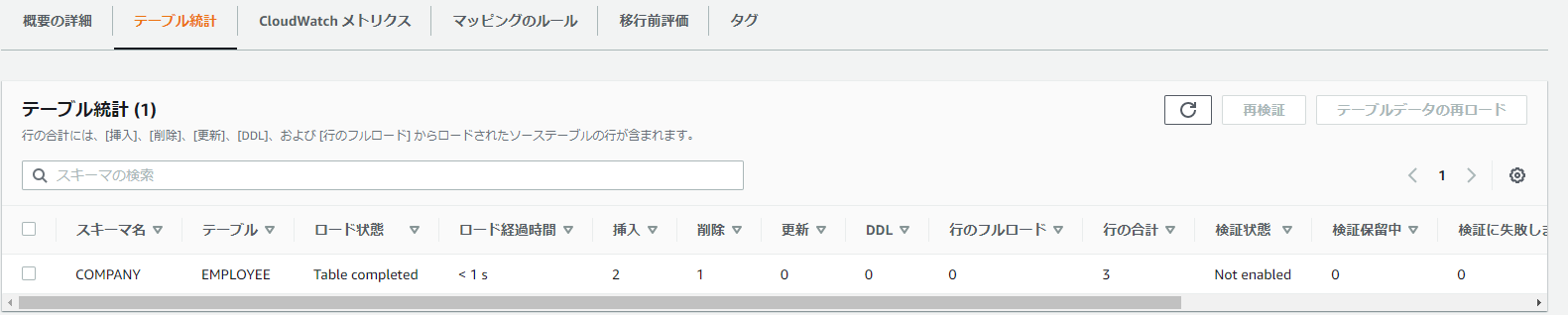
ここで、ソースDBに接続してレコードのINSERTやDELETEを行うと、上記統計にも内容が反映され、ターゲットDBでも同じ情報が見られるようになる。
上記のマネコン画面への情報反映は多少タイムラグがあるが、ターゲットDBへの反映はそれほどラグはないのでご心配なく。
これで、基本のレプリケーションができるようになった!
2021/8/28追記 ターゲットDBをDynamoDBにする
これまでの説明はターゲットDBがAuroraだったが、DynamoDBをターゲットにするのも簡単だった。
エンドポイント
エンドポイントは、ターゲットの設定を以下のように変更する。
Auroraのように接続のエンドポイントを設定しなくても良いのだろうか、というのが気になったが、この後のテーブルマッピングの設定で書き込み先の指定をするので問題がないらしい。
該当のテーブルにアクセスする権限を持ったIAMロールを作る必要があるのがポイントだ。
resource "aws_dms_endpoint" "target" {
endpoint_id = local.replication_target_endpoint_identifier
endpoint_type = "target"
engine_name = "dynamodb"
service_access_role = aws_iam_role.dms_dynamodb.arn
}
IAMロール
ということで、IAMロールは以下のように作成しておく。
なお、必要なロールはユーザーガイドに記載されているものを転記した。
resource "aws_iam_role" "dms_dynamodb" {
name = local.iam_dms_dynamodb_role_name
assume_role_policy = data.aws_iam_policy_document.dms_dynamodb_assume.json
}
data "aws_iam_policy_document" "dms_dynamodb_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"dms.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy" "dms_dynamodb_custom" {
name = local.iam_dms_dynamodb_policy_name
role = aws_iam_role.dms_dynamodb.id
policy = data.aws_iam_policy_document.dms_dynamodb_custom.json
}
data "aws_iam_policy_document" "dms_dynamodb_custom" {
statement {
effect = "Allow"
actions = [
"dynamodb:ListTables",
]
resources = [
"*",
]
}
statement {
effect = "Allow"
actions = [
"dynamodb:PutItem",
"dynamodb:CreateTable",
"dynamodb:DescribeTable",
"dynamodb:DeleteTable",
"dynamodb:DeleteItem",
"dynamodb:UpdateItem",
]
resources = [
data.aws_dynamodb_table.target.arn,
]
}
}
テーブルマッピング
テーブルマッピングは以下のようにする。なお、Auroraのスキーマ名やDynamoDBのテーブル名は、template_fileで渡すことを前提に書いているので、外部の参照した値を使ってほしい。
最初のselectionのルールはAuroraと変わっていないが、DynamoDBへの反映部分はobject-mappingのルールで定義する。この定義が、ユーザーガイドのこの項くらいしか情報がなくて大変分かりにくい……。
ひとまず、attribute-mappingsでハッシュキーをソースDBの値から紐づけてあげないとうまく動かないということは分かった。
※attribute-mappingsを設定しなくてもエラーにはならず、レプリケーションの反映が行われないので、トラブルシュートに苦労する……
このセクションで、Aurora⇒DynamoDBのカラム名や属性のマッピング、文字列結合を行える。指定しない場合は、そのままDBに入れられるようだ。
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "${AURORA_DATABASE_NAME}",
"table-name": "%"
},
"rule-action": "include"
},
{
"rule-type": "object-mapping",
"rule-id": "2",
"rule-name": "2",
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "${AURORA_DATABASE_NAME}",
"table-name": "EMPLOYEE"
},
"target-table-name": "${DYNAMODB_TABLE_NAME}",
"mapping-parameters": {
"partition-key-name": "id",
"attribute-mappings": [
{
"target-attribute-name": "id",
"attribute-type": "scalar",
"attribute-sub-type": "string",
"value": "$${id}"
}
]
}
}
]
}
これでデータベース移行タスクを開始すれば、無事、DynamoDBをターゲットにしたレプリケーションが成功した!
ちなみに、DynamoDBですでにあるハッシュキーのレコードが存在していて、Auroraには存在しないという不整合をあえて起こした上で、Aurora側にInsertを行う実験をしてみたところ、DynamoDB側のレコードは完全に上書きされた(Auroraには存在しないカラム名を持ったレコードを作っておいたが、そのカラムは消えてなくなった)。