はじめに
Amazon AuroraはRDSよりもさらにマネージドな範囲の広いDBのサービスで、さまざまな耐障害性、可用性オプションを選択して構築することがで着て便利。しかし、慣れないとTerraformでの構築はハマりポイントがあるので、整理してみた。
今回の前提知識は以下。
それほど難易度は高くないだろう。
- Amazon AuroraのBlack Beltの資料はざっと目を通して概要を理解している
- TerraformでのAWSサービスの構築経験がある
構成
今回は、シンプルにシングルプライマリインスタンスと、マルチAZでリードレプリカを配置する構成にする。
Auroraはもともとデータは複数AZに分散配置されるため耐障害性は高く、上記のようにすることで、プライマリインスタンスに障害が発生することで、リードレプリカがプライマリに昇格してダウンタイムを減らすことができるようになる。
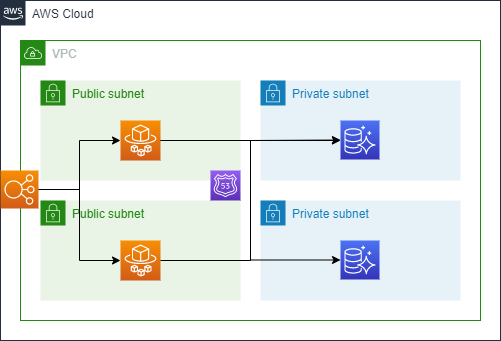
作成するTerraformでは以下のような構成が作られる。

一方で、本来はAuroraはインターネットからは直接接続をさせず、以下のようにPrivateなサブネットに配置するのがセキュアで良いとされている。実際に扱う場合は間違えないように気をつけよう。
Terraform
ネットワーク設定
まずは、DBが所属するサブネットグループを定義する必要がある。
既にサブネットが存在する場合はデータソースで参照し、そうでない場合は作成して、aws_db_subnet_group にサブネットIDのリストを渡そう。
data "aws_subnet_ids" "my_vpc" {
vpc_id = data.aws_vpc.my.id
}
resource "aws_db_subnet_group" "example" {
name = local.db_subnet_group_name
subnet_ids = data.aws_subnet_ids.my_vpc.ids
}
Aurora
Auroraについては以下のように定義する。
メインになるリソースは以下だ。
- aws_rds_cluster: Auroraクラスタの定義
- aws_rds_cluster_instance:Auroraクラスタ上で起動するDBインスタンスの定義
- aws_rds_cluster_parameter_group: クラスタ単位に設定するDBパラメータの定義
- aws_db_parameter_group: インスタンス単位に設定するDBパラメータの定義
Auroraクラスタとパラメータ
Auroraクラスタのdb_subnet_group_nameについては、↑で作成したDBサブネットグループを設定する。
RDBMSのエンジンは、今回はMySQL5.7互換のAurora2.09.2を使う。
セキュリティグループについては、インバウンドで3306を開けたセキュリティグループを作っておけば良い。
resource "aws_rds_cluster" "example" {
cluster_identifier = local.aurora_cluster_identifier
engine = "aurora-mysql"
engine_version = "5.7.mysql_aurora.2.09.2"
master_username = local.aurora_master_username
master_password = local.aurora_master_password
port = 3306
vpc_security_group_ids = [aws_security_group.aurora.id]
db_subnet_group_name = aws_db_subnet_group.example.name
db_cluster_parameter_group_name = aws_rds_cluster_parameter_group.example.name
skip_final_snapshot = true
apply_immediately = true
}
resource "aws_rds_cluster_parameter_group" "example" {
name = local.rdscluster_parameter_group_name
family = "aurora-mysql5.7"
parameter {
name = "character_set_client"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "character_set_connection"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "character_set_database"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "character_set_filesystem"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "character_set_results"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "character_set_server"
value = "utf8mb4"
apply_method = "immediate"
}
parameter {
name = "collation_connection"
value = "utf8mb4_general_ci"
apply_method = "immediate"
}
parameter {
name = "collation_server"
value = "utf8mb4_general_ci"
apply_method = "immediate"
}
parameter {
name = "time_zone"
value = "Asia/Tokyo"
apply_method = "immediate"
}
}
Auroraインスタンスとパラメータ
Auroraインスタンスは、必要な個数分起動する。
今回は、Writerインスタンス1つとReaderインスタンス2つを起動するためにcountを3で起動する。
別に3つ定義しても良いが、面倒だと思うのでcountを使おう。
RDBMSエンジンの設定がハマりどころで、aws_rds_cluster_instanceにもaws_rds_clusterと同じ値を設定しないとパラメータエラーになってしまう。下記のように、Auroraクラスタへの参照で良いでの設定しておくようにしよう。
publicly_accessible は、本来の構成であれば不要で、今回、インターネットから直接接続テストをするために設定している。これを設定するとパブリックのDNSにエンドポイントのホストが登録されるようになる設定だ。
モニタリングについては後述する。
resource "aws_rds_cluster_instance" "example" {
count = 3
cluster_identifier = aws_rds_cluster.example.id
identifier = "${local.aurora_cluster_identifier}-instance-${count.index}"
engine = aws_rds_cluster.example.engine
engine_version = aws_rds_cluster.example.engine_version
instance_class = "db.t3.small"
db_subnet_group_name = aws_db_subnet_group.example.name
db_parameter_group_name = aws_db_parameter_group.example.name
monitoring_role_arn = aws_iam_role.aurora_monitoring.arn
monitoring_interval = 60
publicly_accessible = true
}
resource "aws_db_parameter_group" "example" {
name = local.db_parameter_group_name
family = "aurora-mysql5.7"
}
なお、以下は設定しなくても起動するが、Destroyできなくなるので、検証用リソースには設定しておこう。
未設定でDestroyすると問答無用で消え去るので、商用リソースではちゃんと考えて設定するように。
skip_final_snapshot = true
apply_immediately = true
さて、これで起動すると、
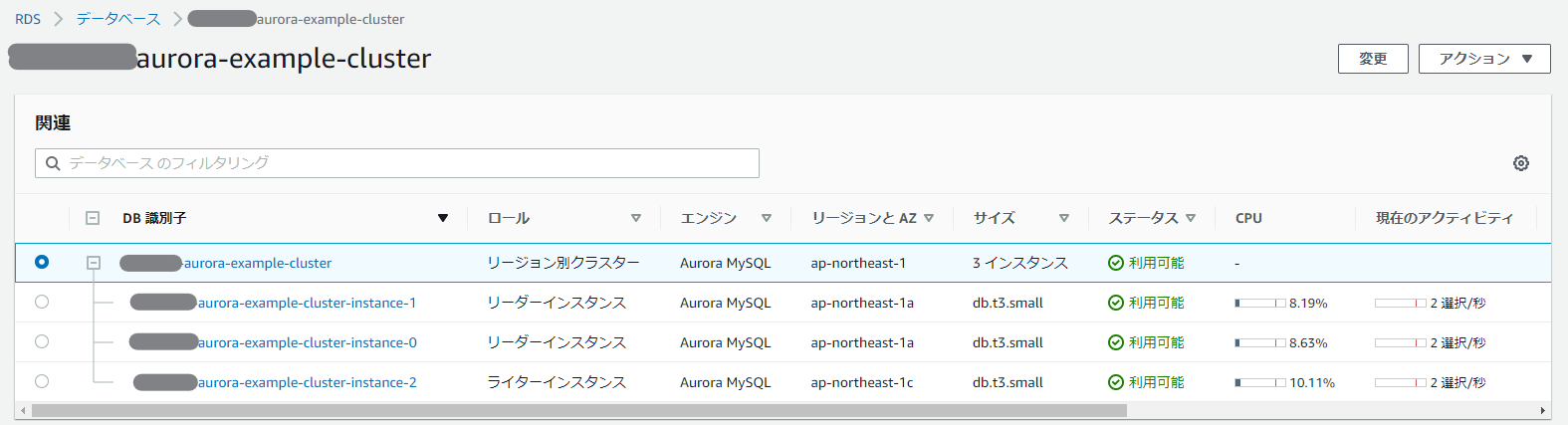
といった感じで、複数AZに分散していることが分かる。が、Readerインスタンスが1つのAZに偏ってしまっていてイケてない。
3AZ構成にすべきなのだろうか……。
なお、接続は
$ mysql -h aurora-example-cluster.cluster-ro-xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com -P 3306 -u 設定したユーザ名 -p
で接続可能だ。
ちなみに、digで上記ホストを参照すると、複数IPアドレスが返されるので、AWSのDNS側で振り分けをしてくれているのが分かる。
ついでに構築後にDBやテーブルも自動で作ろう
テーブルの作成はTerraformリソースは存在しないので、null_resourceを使う。
MySQLの場合、コマンドラインでパスワードを指定しないようにするには、configファイルを作らないといけないので、template_fileとlocal_fileを使って自動で作ろう。
resource "local_file" "mysql_config_file" {
filename = "./.my.cnf"
content = data.template_file.mysql_config_file.rendered
}
data "template_file" "mysql_config_file" {
template = file("./aurora_mysql_conf_template.cnf")
vars = {
aurora_user = local.aurora_master_username
aurora_password = local.aurora_master_password
aurora_host = aws_rds_cluster.example.endpoint
aurora_port = aws_rds_cluster.example.port
}
}
resource "null_resource" "db_setup" {
depends_on = [
aws_rds_cluster.example,
aws_rds_cluster_instance.example,
]
provisioner "local-exec" {
command = "mysql --defaults-extra-file=./.my.cnf ${aws_rds_cluster.example.database_name} < ./aurora_create_db.sql"
}
}
[client]
user = ${aurora_user}
password = ${aurora_password}
host = ${aurora_host}
port = ${aurora_port}
CREATE TABLE EMPLOYEE (
id CHAR(5) PRIMARY KEY,
name CHAR(20) NOT NULL,
age INTEGER
);
INSERT INTO EMPLOYEE VALUES ( '00001', 'Taro', 35 );
INSERT INTO EMPLOYEE VALUES ( '00002', 'Jiro', 30 );
INSERT INTO EMPLOYEE VALUES ( '00003', 'Saburo', 28 );
INSERT INTO EMPLOYEE VALUES ( '00004', 'Shiro', 24 );
INSERT INTO EMPLOYEE VALUES ( '00005', 'Goro', 40 );
これで、構築直後から以下のようにテーブルとレコードにアクセスできるようになっている。
MySQL [COMPANY]> select * from EMPLOYEE;
+-------+--------+------+
| id | name | age |
+-------+--------+------+
| 00001 | Taro | 35 |
| 00002 | Jiro | 30 |
| 00003 | Saburo | 28 |
| 00004 | Shiro | 24 |
| 00005 | Goro | 40 |
+-------+--------+------+
5 rows in set (0.01 sec)
拡張モニタリング
Auroraのマネージメントコンソール画面では、以下の情報を参照することができる。
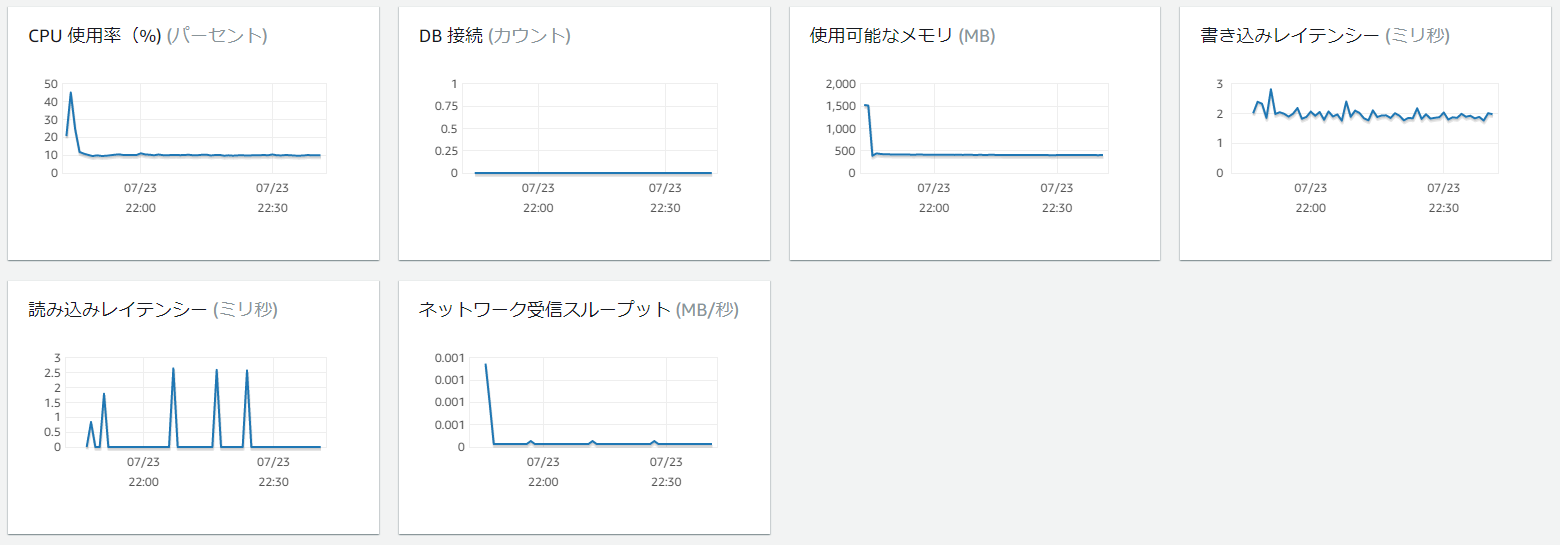
上記以外に、拡張モニタリングを有効化すればさらに以下の情報を参照することが可能になる。
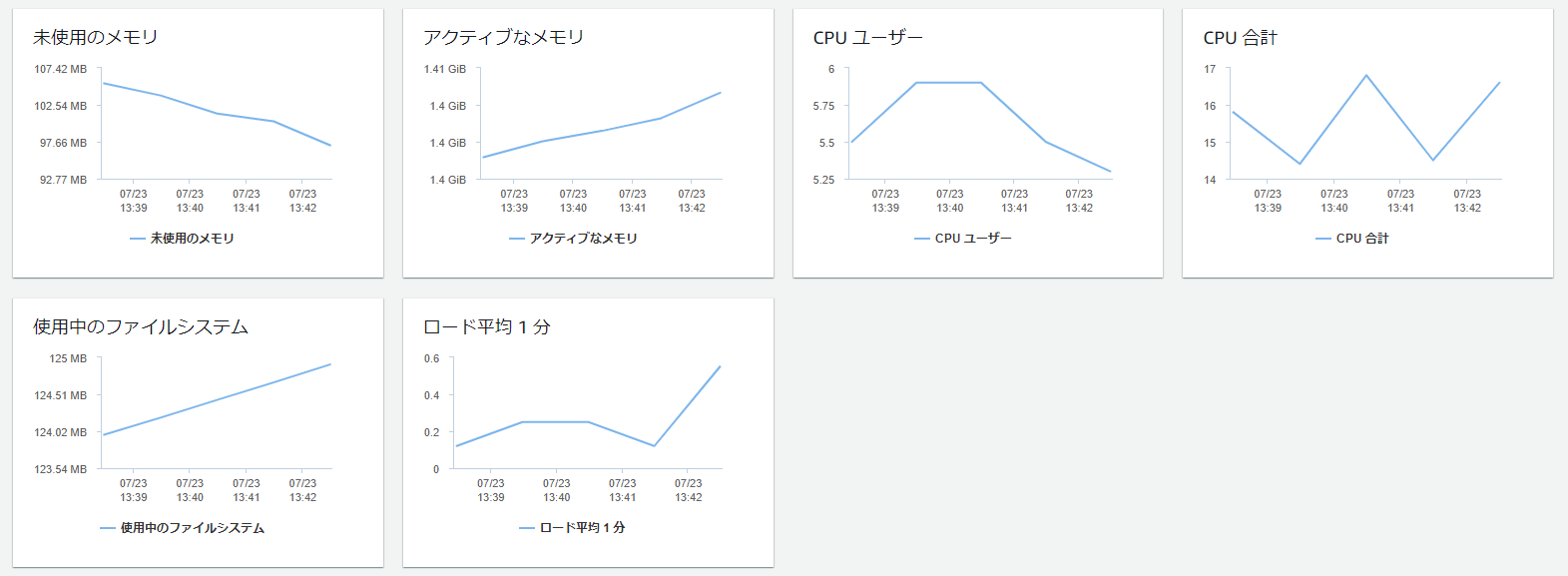
拡張モニタリングは、↑に書いた通り、aws_rds_cluster_instanceの
monitoring_role_arn = aws_iam_role.aurora_monitoring.arn
monitoring_interval = 60
で設定が可能だ。IAMの設定は以下のように行おう。
resource "aws_iam_role" "aurora_monitoring" {
name = local.iam_aurora_role_name
assume_role_policy = data.aws_iam_policy_document.aurora_monitoring_assume.json
}
data "aws_iam_policy_document" "aurora_monitoring_assume" {
statement {
effect = "Allow"
actions = [
"sts:AssumeRole",
]
principals {
type = "Service"
identifiers = [
"monitoring.rds.amazonaws.com",
]
}
}
}
resource "aws_iam_role_policy_attachment" "aurora_monitoring" {
role = aws_iam_role.aurora_monitoring.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonRDSEnhancedMonitoringRole"
}
アプリケーションからの接続に関するプラクティス
前述したとおり、Auroraは、プライマリインスタンスに障害が発生した時、リードレプリカをプライマリに昇格する。
この際、参照系のトランザクションが流れ込んでしまうと負荷分散の都合上あまりよろしくないため、リードレプリカに接続しなおしたい。
こちらの記事にあるとおり、innodb_read_onlyとmysql.ro_replica_statusというパラメータがあるため、たとえばSpringBootなどではActuatorでこのパラメータを監視して、必要に応じてグレースフルにコンテナを再起動して接続をやりなおしてあげるのが良いだろう。
他にはRDSプロキシを使うという手段もありそうだが、これはまた別途、Terraformでの設定の方法を検証する。