はじめに
ECS + Fargate での負荷分散は以下のように行うのが基礎の基礎として教わるところだと思うが、他にも負荷分散の方法がある。
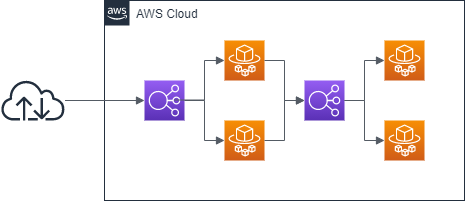
ECS でサービス作成時に設定する「サービスディスカバリ」を使うことで、DNS を使って負荷分散が可能になる。
本記事では、内部通信についてプライベートホストゾーンを使って負荷分散を行うことを前提にする。
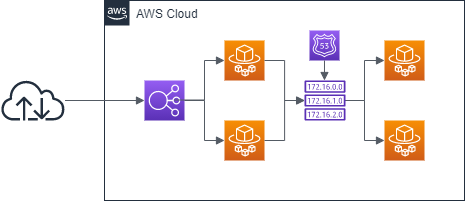
なお、ECS + Fargate の Terraform の HCL は以下の記事を参考にしてもらえれば。
Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
また、コンテナの中身は何でも良いが、後で正常性確認をしやすいように、標準出力でログを出すようにしておこう。
Terraform
Terraform の修正ポイントは以下だ。
- サービスディスカバリのリソース定義
- バックエンドサービスに関する ELB, Listener, TargetGroup を削除する
-
aws_ecs_serviceからload_balancerを削除し、service_registriesを定義 -
aws_ecs_task_definitionで自分でヘルスチェックを定義
以降では、バックエンド側のサービスを service_b として定義している。
フロント側はコード中に登場しないが、service_a とする。
サービスディスカバリのリソース定義
local.service_discovery_namespace については、内部通信なので好きな名前を付けて問題ない。
ここで health_check_custom_config を定義するため、後でコンテナ側でヘルスチェックを行ってあげよう。
################################################################################
# Service Discovery #
################################################################################
resource "aws_service_discovery_private_dns_namespace" "internal" {
name = local.service_discovery_namespace
description = "Service Discovery Example"
vpc = data.aws_vpc.my.id
}
resource "aws_service_discovery_service" "service_b" {
name = local.service_b_service_discovery_nane
dns_config {
namespace_id = aws_service_discovery_private_dns_namespace.internal.id
dns_records {
ttl = 10
type = "A"
}
routing_policy = "MULTIVALUE"
}
health_check_custom_config {
failure_threshold = 1
}
}
ECS系リソースの修正
この後の正常性確認を分かりやすくするために、desired_count は 2 以上を設定しておこう。
resource "aws_ecs_task_definition" "service_b_ecsfargate" {
family = local.service_b_ecs_task_family_name
task_role_arn = aws_iam_role.ecs.arn
execution_role_arn = aws_iam_role.ecstaskexecution.arn
network_mode = "awsvpc"
cpu = "256"
memory = "512"
requires_compatibilities = [
"FARGATE",
]
container_definitions = data.template_file.service_b_ecsfargate.rendered
}
data "template_file" "service_b_ecsfargate" {
template = file("${path.module}/service_b_taskdef.json")
vars = {
service_b_ecs_container_name = local.service_b_ecs_container_name
service_b_image = "${aws_ecr_repository.service_b_image.repository_url}:latest"
service_b_ecstask_log_group_name = aws_cloudwatch_log_group.service_b_ecstask_log_group.name
service_b_region_name = data.aws_region.current.name
}
}
resource "aws_ecs_service" "service_b_ecsfargate_service" {
name = local.service_b_ecs_service_name
cluster = aws_ecs_cluster.service_b_ecsfargate.id
launch_type = "FARGATE"
task_definition = aws_ecs_task_definition.service_b_ecsfargate.arn
desired_count = 2
network_configuration {
subnets = flatten([data.aws_subnet_ids.my_vpc.ids])
security_groups = [
data.aws_security_group.http.id,
]
assign_public_ip = "true"
}
service_registries {
registry_arn = aws_service_discovery_service.service_b.arn
}
}
タスク定義の修正
タスク定義では、ELB によるヘルスチェックが行われなくなるため自前のヘルスチェックを行う。
[
{
"name" : "${service_b_ecs_container_name}",
"image": "${service_b_image}",
"cpu": 0,
"memoryReservation": 512,
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"secretOptions": null,
"options": {
"awslogs-group": "${service_b_ecstask_log_group_name}",
"awslogs-region": "${service_b_region_name}",
"awslogs-stream-prefix": "ecs"
}
},
"healthCheck": {
"command": [
"CMD-SHELL",
"curl http://localhost/ || exit 1"
],
"interval": 5,
"retries": 3,
"startPeriod": 60,
"timeout": 5
}
}
]
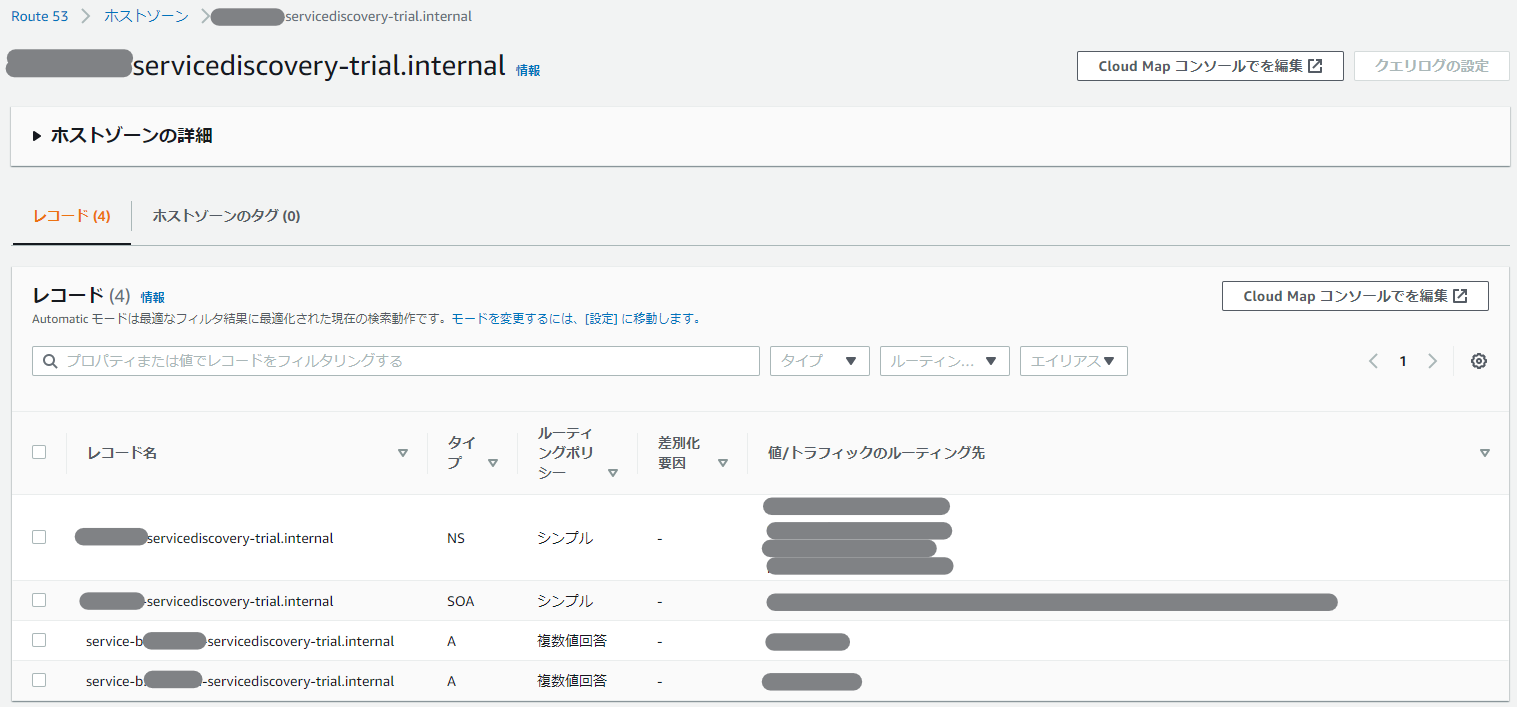
さて、ここまで設定をすると、Route53で以下のように 複数A レコードが設定され、
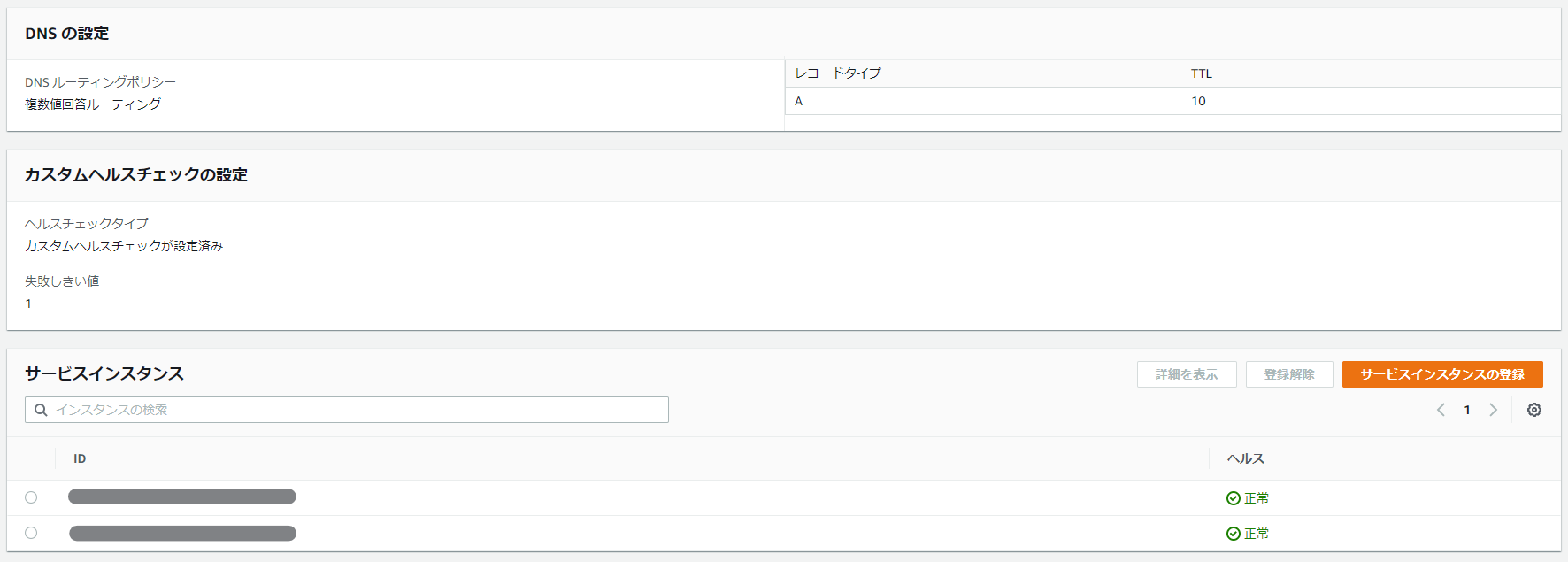
CloudMap では作ったタスクがヘルスチェック OK の状態となっているはずである。
この状態で、service_a 前段の ELB に対して curl をして CloudWatch Logs を確認してみると、ちゃんと両方のタスクでアクセスログが出力されていることが分かるはずだ。
これで、NLB を使わずとも振り分けができるようになった。
実はこれは、AppMesh を使う時に必要だったりするので、知っておくと後々便利になる。