はじめに
DynamoDB Streamsは便利そうなのだけど、イマイチ正体が分からないので確認してみた。
Lambdaの仕組みをある程度理解していて、プログラムを書けることを前提とする。
参考
通知イベント
通知されるイベントの内容を調べてみようとしたら、クラスメソッド先生が既にちゃんと調べていた。
さすが。
【Developers.IO】DynamoDB Streamで渡されるeventデータの表示タイプごとの内容をまとめてみた
設定方法
設定方法は2種類。
DynamoDB側から設定する方法と、Lambda側でイベントソースを設定する方法。
前者は、以下のような感じで詳細な設定をすることができない。

↑この画面で「トリガーの作成」から「新規作成」を選択すると、ちゃんと設定ができるが、まあいきなりコンソールで関数を書き始める人はそうそういないだろう。
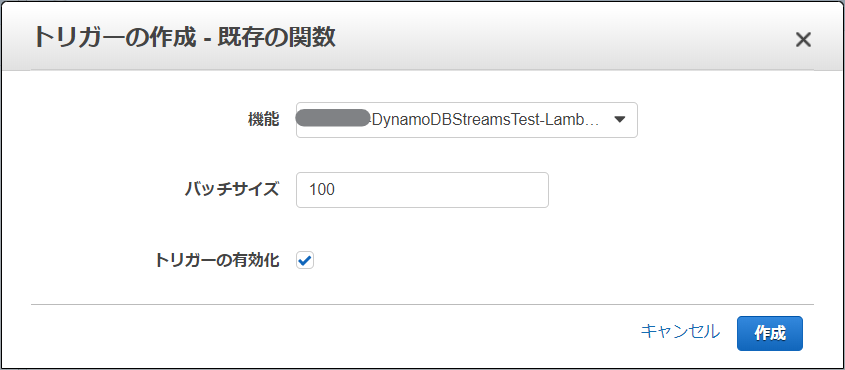
というわけで、「既存のLambda関数」を選択すると、以下のようなダイアログしか出てこなくてチューニングができない。しかも、この方法で作ってしまうと、いきなり以下のような感じになってしまい更新ができなくなってしまう。更新ボタンはどこに!
あと、↑の画面の「トリガーの削除」を押すと、なんとLambda関数もろとも消滅したので注意が必要だ。
いやいや、たしかに「トリガーの関数を削除」って書いてあるけどさ……。SAMで再現性ある作成をしてなかったら泣いてるところだったぞ……。
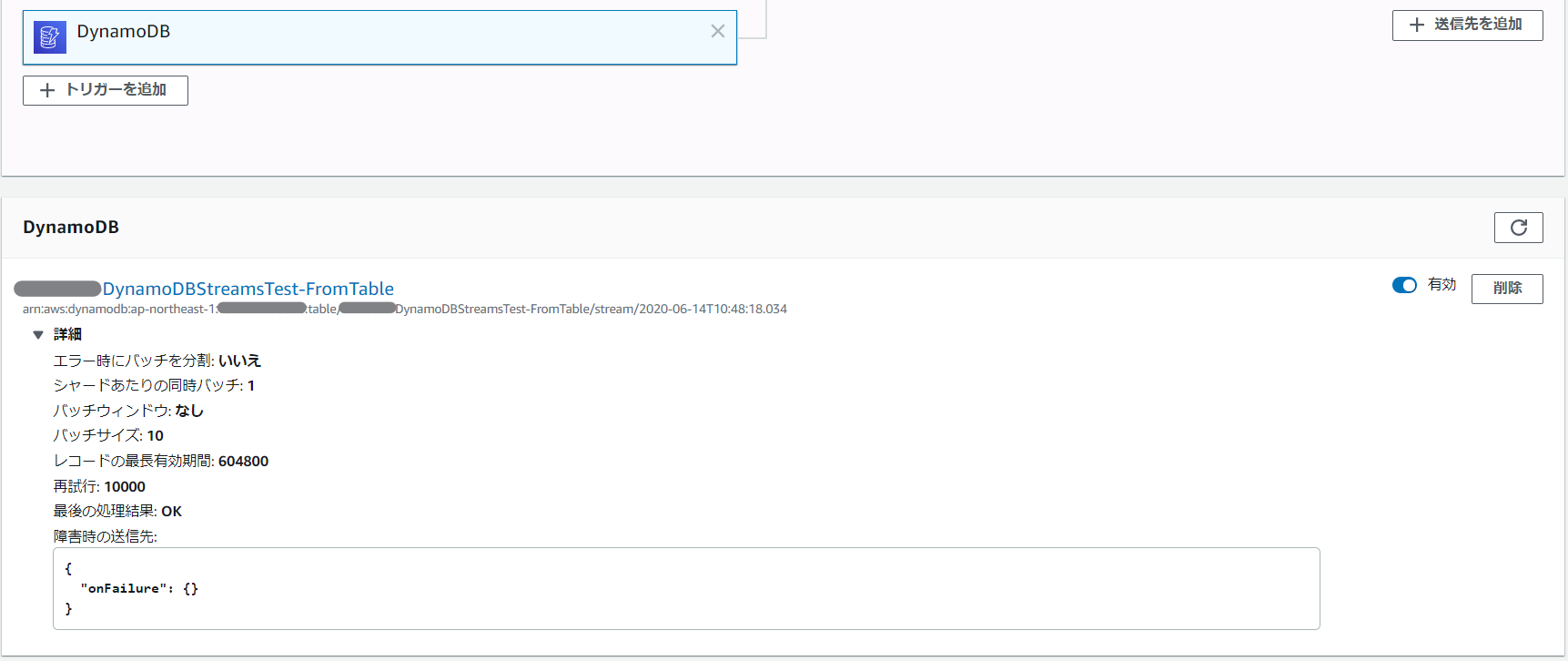
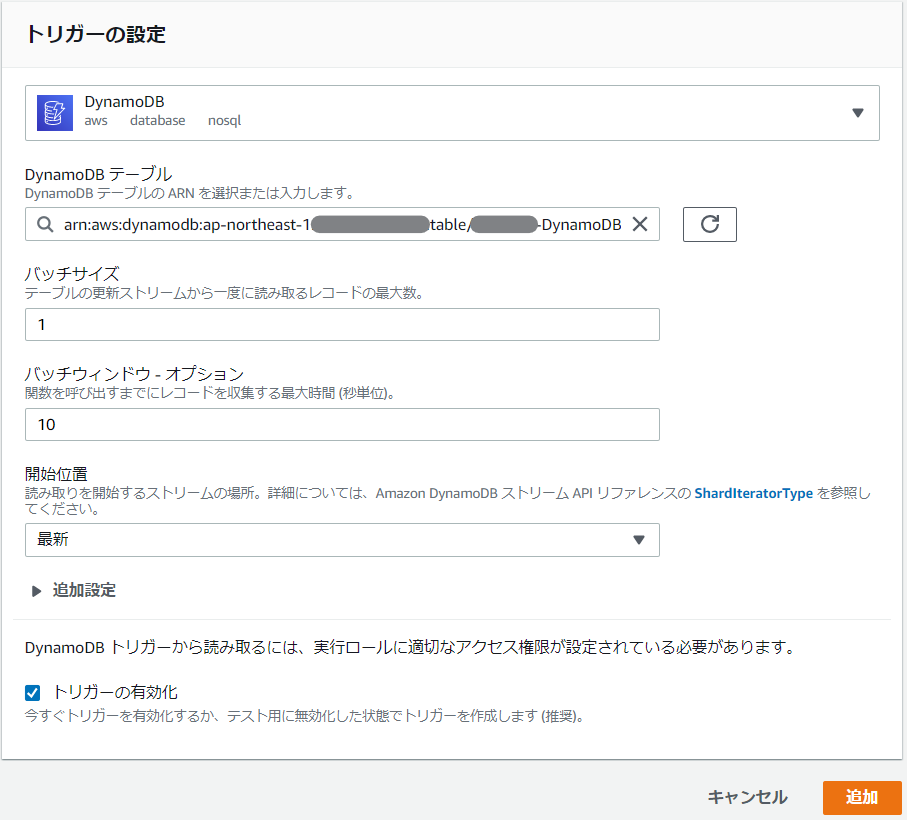
後者の方は、以下のボタンから「DynamoDB」を選択すれば良い。
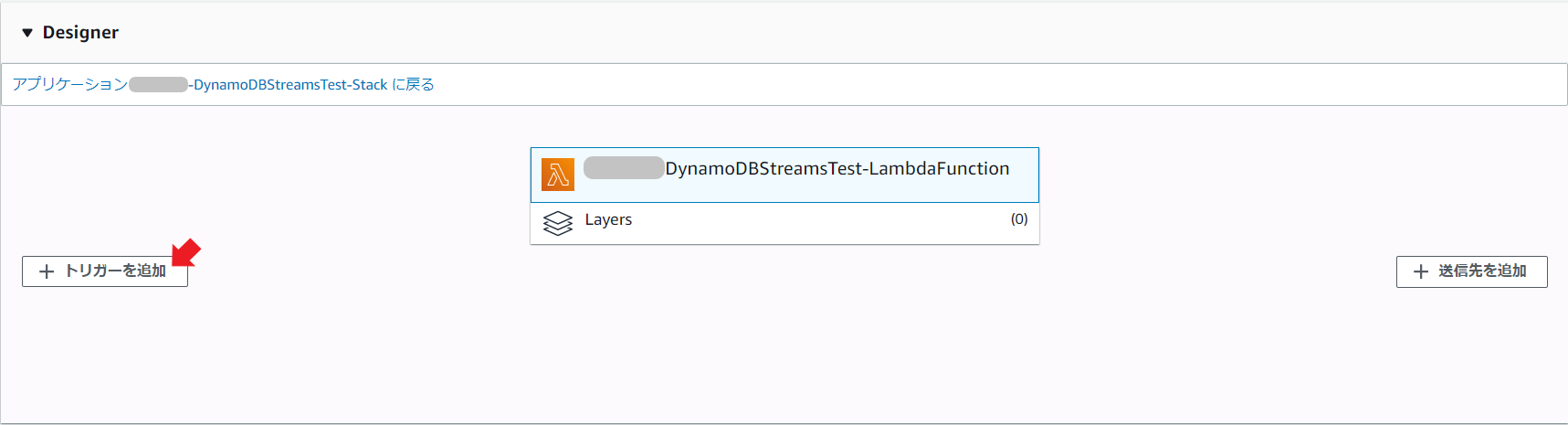
こんな感じで詳細設定画面が出る。
まあ、結局更新ができないので、以下の方法を取るしかないのだけど。
- CLIでupdate-event-source-mapping
- Terraformのaws_lambda_event_source_mapping
- CloudFormationのAWS::Lambda::EventSourceMapping
Lambdaを使う場合は、イベントソースのストリームのARNが必要になるので、あらかじめ用意するDynamoDBテーブルの定義でStreamArnをGetAtt関数でアウトプットしておこう。
今回は、事前のテーブル定義をTerraformで作ってしまった都合、aws_lambda_event_source_mappingを使う方法で試してみる。
なお、TerraformでDynamoDB Streamsを有効化するには、aws_dynamodb_table のリソースに以下の設定を加える。stream_view_type は設定しないとエラーになるので、要件に合わせて設定しよう。
stream_enabled = true
stream_view_type = "NEW_AND_OLD_IMAGES"
チューニングしながら考えてみる
さて、以下のようにTerraformのtfファイルを作成したらチューニングをしてみよう。
data "aws_dynamodb_table" "from_table" {
name = "[DynamoDBテーブル名]"
}
data "aws_lambda_function" "test" {
function_name = "[Lambda関数名]"
}
resource "aws_lambda_event_source_mapping" "dynamodb_streams" {
event_source_arn = "${data.aws_dynamodb_table.from_table.stream_arn}"
function_name = "${data.aws_lambda_function.test.arn}"
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
}
キモになるのは、batch_sizeとmaximum_batching_window_in_secondsだ。
Terraformのドキュメントに以下のように書いてあるので、上記設定にしておけば、Streamsに10件放り込んだら、1件ずつLambdaが起動するのではなかろうか。
The maximum amount of time to gather records before invoking the function, in seconds. Records will continue to buffer until either
maximum_batching_window_in_secondsexpires orbatch_sizehas been met. Defaults to as soon as records are available in the stream. If the batch it reads from the stream only has one record in it, Lambda only sends one record to the function.
だが、結果としては、1回のLambda起動で1件の処理ではあるものの、Streamsに情報が溜まっているので、次々と起動されている。うーむ、若干「これじゃない」的な動作……。

では続いて、
batch_size = 20
maximum_batching_window_in_seconds = 10
としたところに10件だけデータを放り込んだらどうなるだろうか。
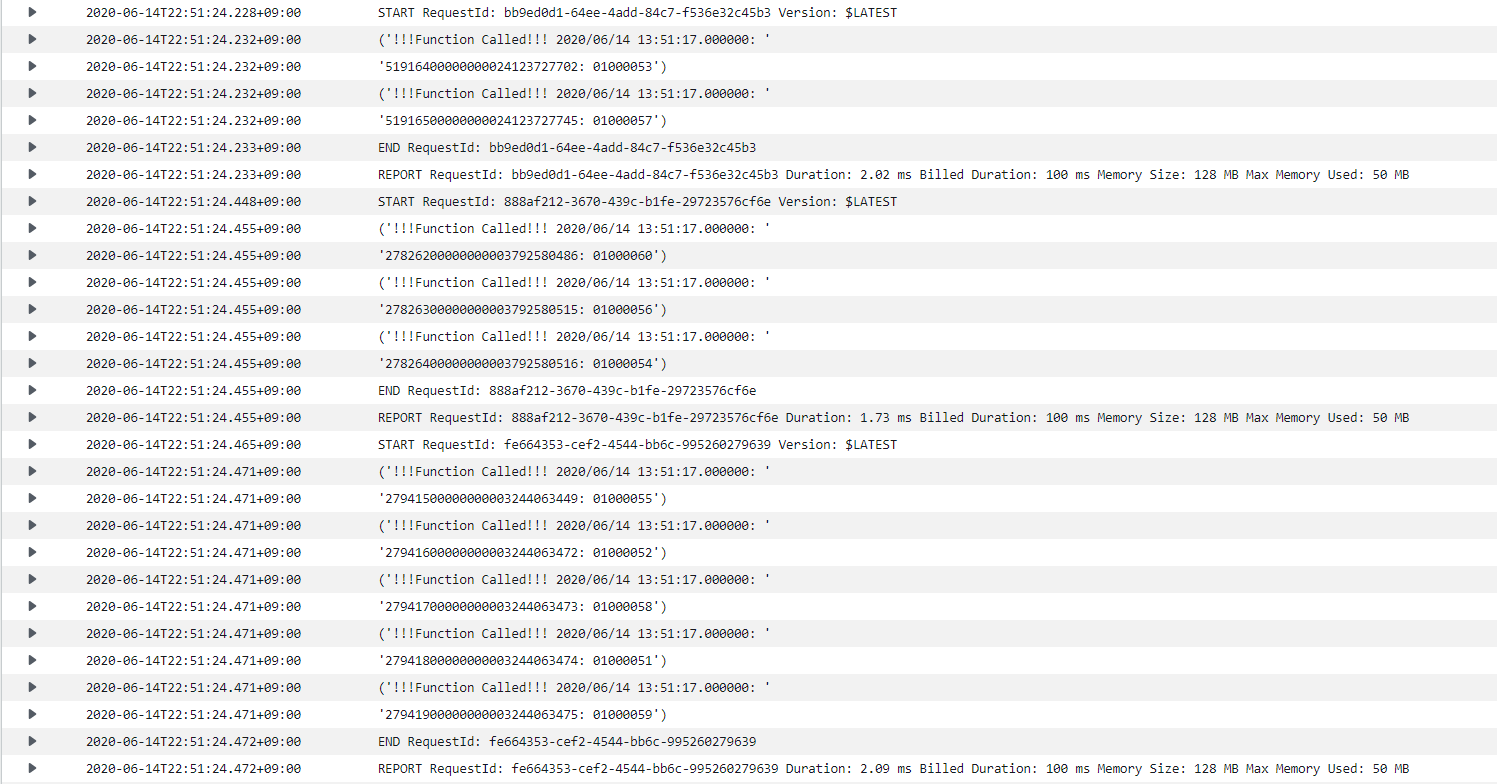
今度はちゃんと10秒後に、20件溜まっていなくても処理をしてくれた。
Streamsには10件溜まってるのだから、まとめて10件処理するかと思ったらLambdaが3回コールされているのは気になるところ。
ともあれ、この辺の値をコントロールしつつ、並列度を考えればもう少しトラフィックコントロールもできるだろう。並列度についてはまた別途検証を行う予定。
おまけ
検証用に用いたLambda関数は以下のような感じ。
ランタイムはPython3.7です。
import json
import pprint
from datetime import datetime
def lambda_handler(event, context):
json_records = event['Records']
for json_record in json_records:
json_dynamodb = json_record['dynamodb']
ApproximateCreationDateTime = json_dynamodb['ApproximateCreationDateTime']
now_from_ts = datetime.fromtimestamp(ApproximateCreationDateTime)
pprint.pprint("!!!Function Called!!! " + now_from_ts.strftime("%Y/%m/%d %H:%M:%S.%f") + ": " + json_dynamodb['SequenceNumber'] + ": " + json_dynamodb['Keys']['id']['S'])
return {
'statusCode': 200,
'isBase64Encoded': 'false'
}
(追記)緩やかな流量制御はできるのか
さて、↑でチューニングと書いたが、これでできるのはあくまでも「いかにスピードを出すか」のチューニングであり、「ゆっくり手加減しながら処理する」ためのチューニングはできない。
なぜなら、DynamoDBのシャード数は自分で制御することができないからだ。せっかく手加減するチューニングをしたとしても、勝手にシャードが増えたり、シャードが偏ったときに想定通りの処理速度にならないからだ。
【Qiita】[AWS]私が経験したDynamoDBアンチパターン
上記の記事にあるように、ちゃんと「ゆっくり手加減しながら処理する」ためには、間にKinesis Data Streamsを噛ませるしかないようだ。DynamoDBをオンデマンドキャパシティにしておけば、完全に「使用量に応じた課金」にできるのに、時間制課金のKinesis Data Streamsを使うことになるのは歯痒いところではあるが……。
Kinesisの作成
あまり深く考えずに作るなら以下のような感じで。暗号化等は必要に応じて実施する。
シャード数に応じた時間制課金なので、いきなりシャード数を大きくし過ぎないように注意。
resource "aws_kinesis_stream" "streams_test" {
name = local.kinesis_stream_name
shard_count = 20
}
Kinesisに書き込むLambdaの設定
特に難しい設定はないが、Lambda実行のIAMロールのポリシーには以下の権限を付与しておこう。
※今回のサンプルでは PutRecord しかしていないので、厳密には PutRecords は不要。必要に応じて書く。
"kinesis:PutRecord",
"kinesis:PutRecords",
サンプルのスクリプトは以下のような感じで書いている。Python3.7で記述。
DynamoDB Streamsからトリガ起動されてきたイベントを、ひたすらKinesis Data Streamsに書き込んでいる。
途中で record['RelayDateTime'] = str(datetime.datetime.now()) としているのは、後で集計時にKinesisへの中継処理をした日時が分かるようにだ。
import json
import datetime
import boto3
client = boto3.client('kinesis')
def lambda_handler(event, context):
for record in event['Records']:
if record['eventName'] != 'REMOVE':
record['RelayDateTime'] = str(datetime.datetime.now())
try:
client.put_record(
Data = json.dumps(record),
PartitionKey = record['dynamodb']['NewImage']['id']['S'],
StreamName = 'dynamodb-streams-test-stream'
)
except Exception as error:
print(error)
Kinesisからイベントを受け取るLambdaの設定
受信側もイベントトリガで起動するようにする。受信側のLambda関数を作り、以下のイベントソースマッピングを行う。
resource "aws_lambda_event_source_mapping" "kinesis" {
event_source_arn = aws_kinesis_stream.streams_test.arn
function_name = aws_lambda_function.receive.arn
starting_position = "LATEST"
batch_size = 1
maximum_batching_window_in_seconds = 10
parallelization_factor = 1
}
受信側のLambda実行のIAMロールのポリシーには以下の権限を付与しておこう。
"kinesis:DescribeStream",
"kinesis:DescribeStreamSummary",
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:ListShards",
"kinesis:ListStreams",
"kinesis:SubscribeToShard",
受信側のLambdaは以下のようなサンプルで。こちらもPython3.7。
流量制御するためにレコード処理ごとに time.sleep() を入れている。サーバレスな仕組みなのにSleepするとか超イケてないのだけど……ストリームにデータが入ってたらLambdaが起動してしまうので仕方がない……。
また、Kinesisのデータ部はByte列のBase64エンコードになっているので、デコードして json.loads でdict型に変換している。
import json
import base64
import datetime
import time
def lambda_handler(event, context):
for kinesis_record in event['Records']:
record = json.loads(base64.b64decode(kinesis_record['kinesis']['data']).decode('utf-8'))
approx_create_dt = datetime.datetime.fromtimestamp(int(record['dynamodb']['ApproximateCreationDateTime']))
print(json.dumps(dict(
request_id = record['dynamodb']['NewImage']['request_id']['S'],
id = record['dynamodb']['NewImage']['id']['S'],
writeDateTime = record['dynamodb']['NewImage']['write_date']['S'],
relayDateTime = record['RelayDateTime'],
processedDateTime = str(datetime.datetime.now())
)))
time.sleep(0.18)
さて、こんな感じで、バッチサイズやウィンドウサイズを調整しながら実際にどれくらいの流量制御ができるかを確認してみる。
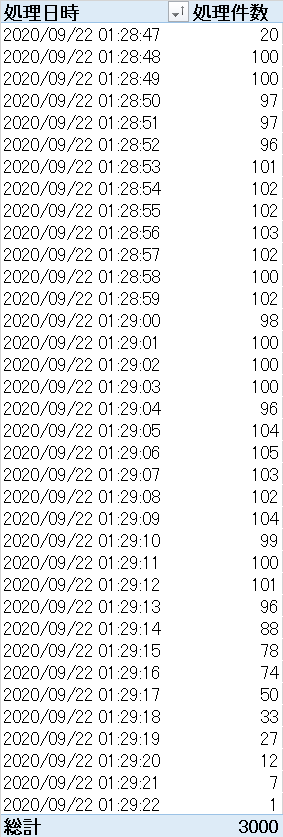
確認結果
バッチサイズを減らした場合、Lambdaが次に起動してくるまでのオーバーヘッドがある分を考慮したスリープ時間の設定が必要なのと、その部分がAWS任せになって制御不能なので、安定しにくい気がする。また、実行回数が多い場合は課金額に影響する。
一方で、バッチサイズを増やすと、「後回し」にされるケースが増えるため、終盤が安定しないが、全体でみればこちらの方が細かく制御できるだろう。
結論を言えば、「ピッタリこの流量」という制御は難しいが「この値は絶対超えない」とか「大体これくらい」であれば実現可能であると言えそうだ。
シャード数20, バッチサイズ5, ウィンドウサイズ5
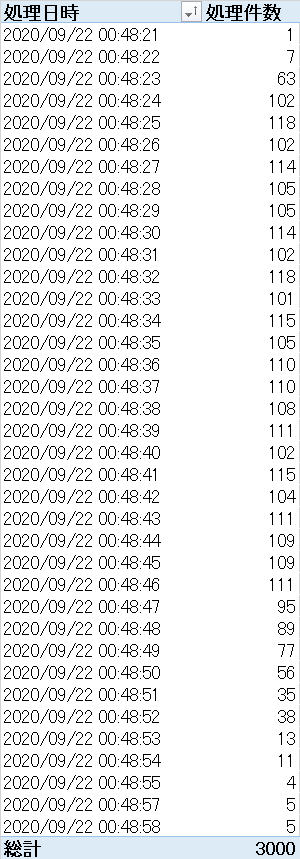
シャード数20, バッチサイズ1, ウィンドウサイズ10