はじめに
DynamoDBをデータベースにしたアーキテクチャでシステムを構築し、運用をし始めてから1年近く経ったので、DynamoDBを使い始める前に感じていた幻想と、実際に使った後に打ち付けられた現実を、DynamoDBはこんな使い方に向いてないっていうパターンを合わせて書き連ねたいと思います。
DynamoDBについての説明は割愛します。
あのとき幻想…
当時、DynamoDBって
- 短いスパンの書き込みに強い
- ある程度のスパイクには耐えてくれる
- オートスケールでキャパシティを自動で増減できる
- DAXとかグローバルテーブルとか色んな機能もあって素敵やん
という印象を持っており、
DynamoDBって有能やん!!!
と思っていた時期もありました………
現実は甘くない
現実はそんなに甘くなかった。
デバイスから無造作に投げられるデータ。
そのデータをさばくKinesisDataStreamsやAWSLambda。
あとはDynamoDBにデータが格納されれば何も問題はなかった…
[アンチパターン1] オートスケールに頼りすぎる問題
DynamoDBにはオートスケールという機能があり、各テーブルに対してのRead/Writeごとのキャパシティを、負荷をトリガーに自動的に増減させてくれる機能があります。
なので、「デバイスからのデータ量やリクエスト量が増えても、オートスケールが発動してキャパシティ上げてくれるから安心やな!」と思っていました。
なにが問題かって言うと、
「オートスケールよ。お前スロースターターやのう…」
ということです。
何が起きたか
デバイスから一度のリクエストで2000件近くのデータを投げていて、KinesisDataStreamsやLambdaは問題なく可動しているんだが、DynamoDBの該当テーブルには途中までしかデータが格納されていなかった…
実際に確認してみた
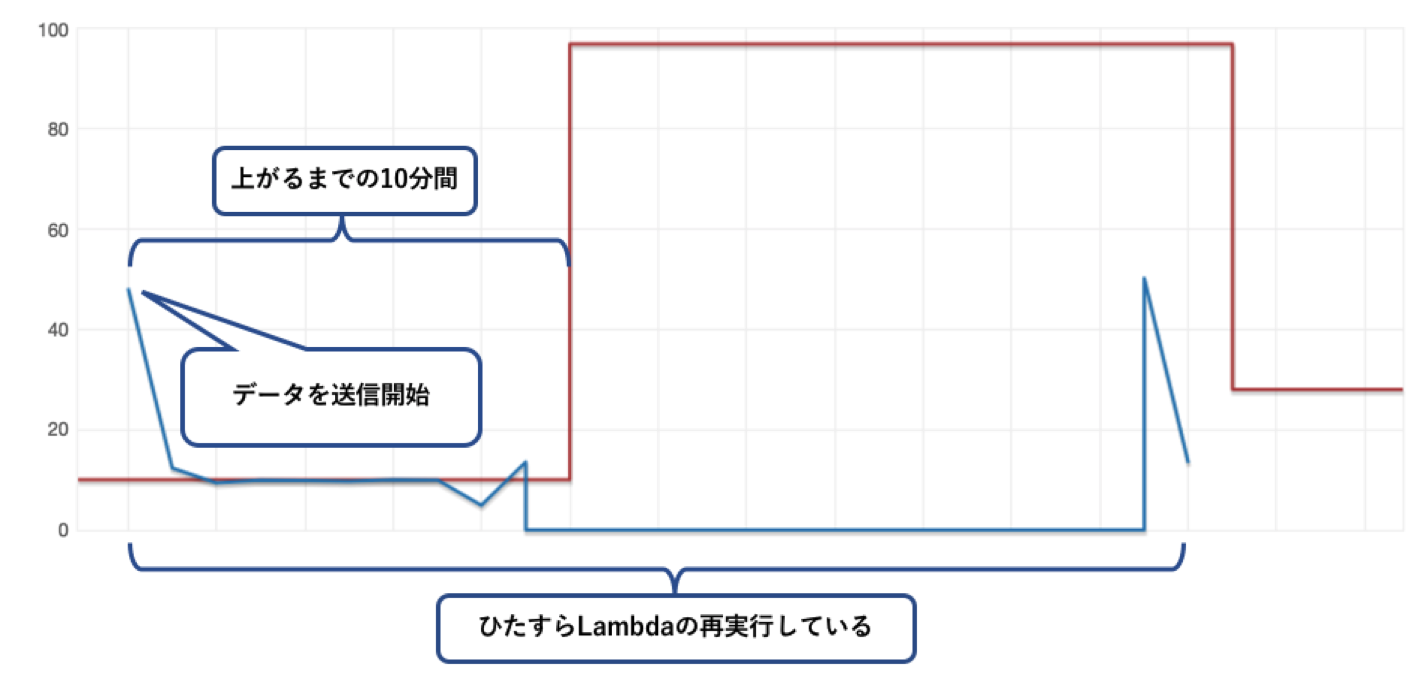
オートスケールのトリガーがあってから、キャパシティが反映されるまで約10分程度かかってました…
DynamoDBはキャパシティ不足が続くと、おそらくすべてのテーブルに対する操作を拒否します。したがってLambdaが死にます。それに伴い、Lambdaに渡されたデータは闇へ葬り去られます…
どうするのか
- 1件あたりのデータ量が多くなる可能性がある場合は、予めキャパシティに余裕を持たせておきましょう。ここをケチると痛い目に遭います。
- キャパシティ上げたら金額上がるから、オートスケールでなんとかしたい…という場合は、大人しくLambdaの前にKinesisDataStreamsをはさみましょう。オートスケールが仕事をするまでリトライ処理をしてくれます。
[アンチパターン2] DynamoDBStreamsのシャード数いじれない問題
DynamoDBStreamsという機能があります。
各テーブルに対して何かしらのイベントが発生したら、それをトリガーにLambdaを実行することができる機能です。
テーブルからデータを加工して、他のテーブルに書き込みをすることができたりします。
私が携わる案件では、デバイスから送信されてくるデータをサマライズするのによく利用しています。
何が起きたか
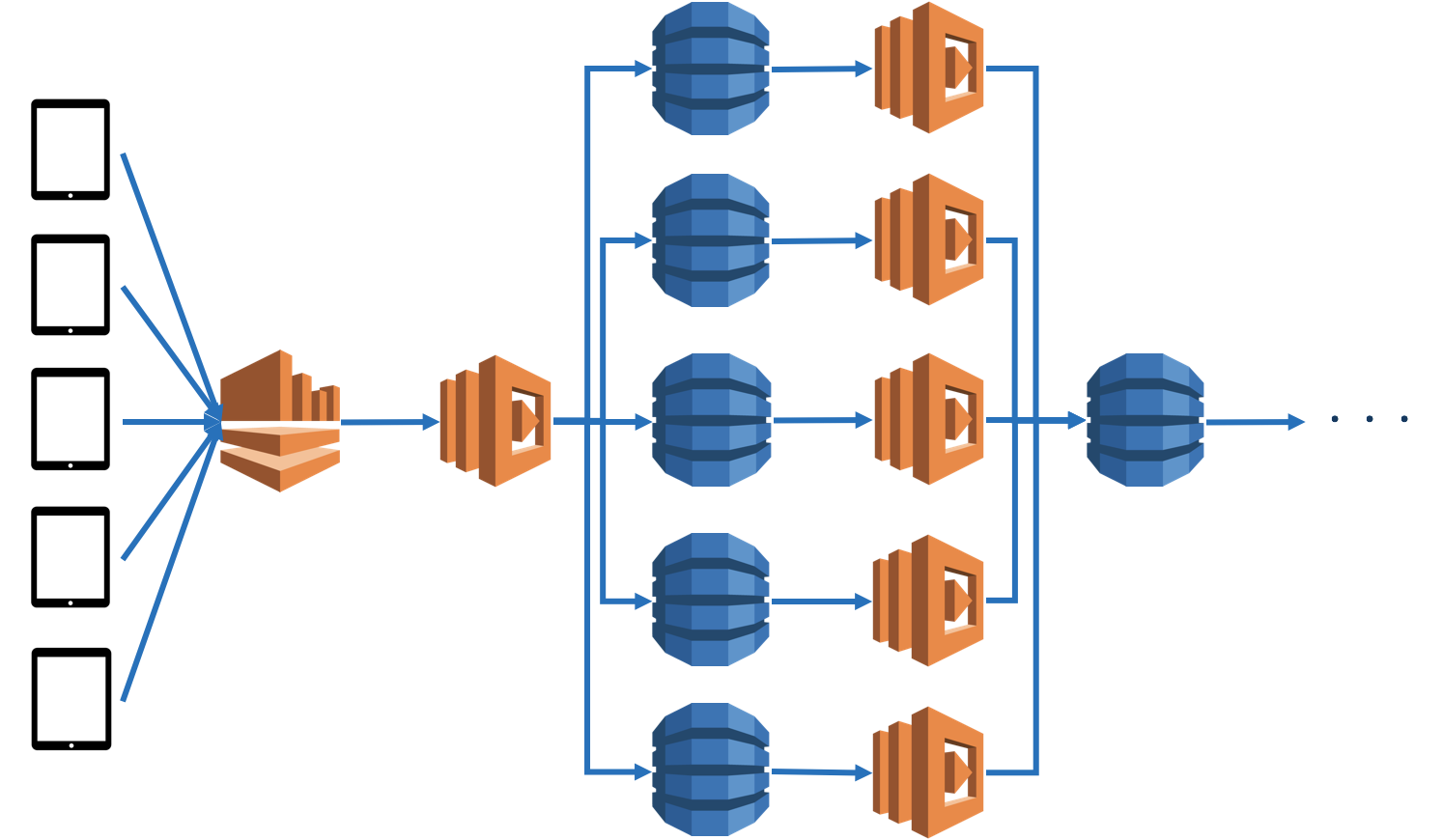
こんな感じのアーキテクチャがあって、デバイスからデータが送信されてきて各テーブルに書き込まれた後、そこからサマライズして違うテーブルに書き込むような処理をしています。
ある日突然何台かのデバイスから想定していないインターバルでデータが送信されてきたときに問題が起きました。
DynamoDBStreamsが詰まりに詰まって、データの処理が半日程度遅延していました。
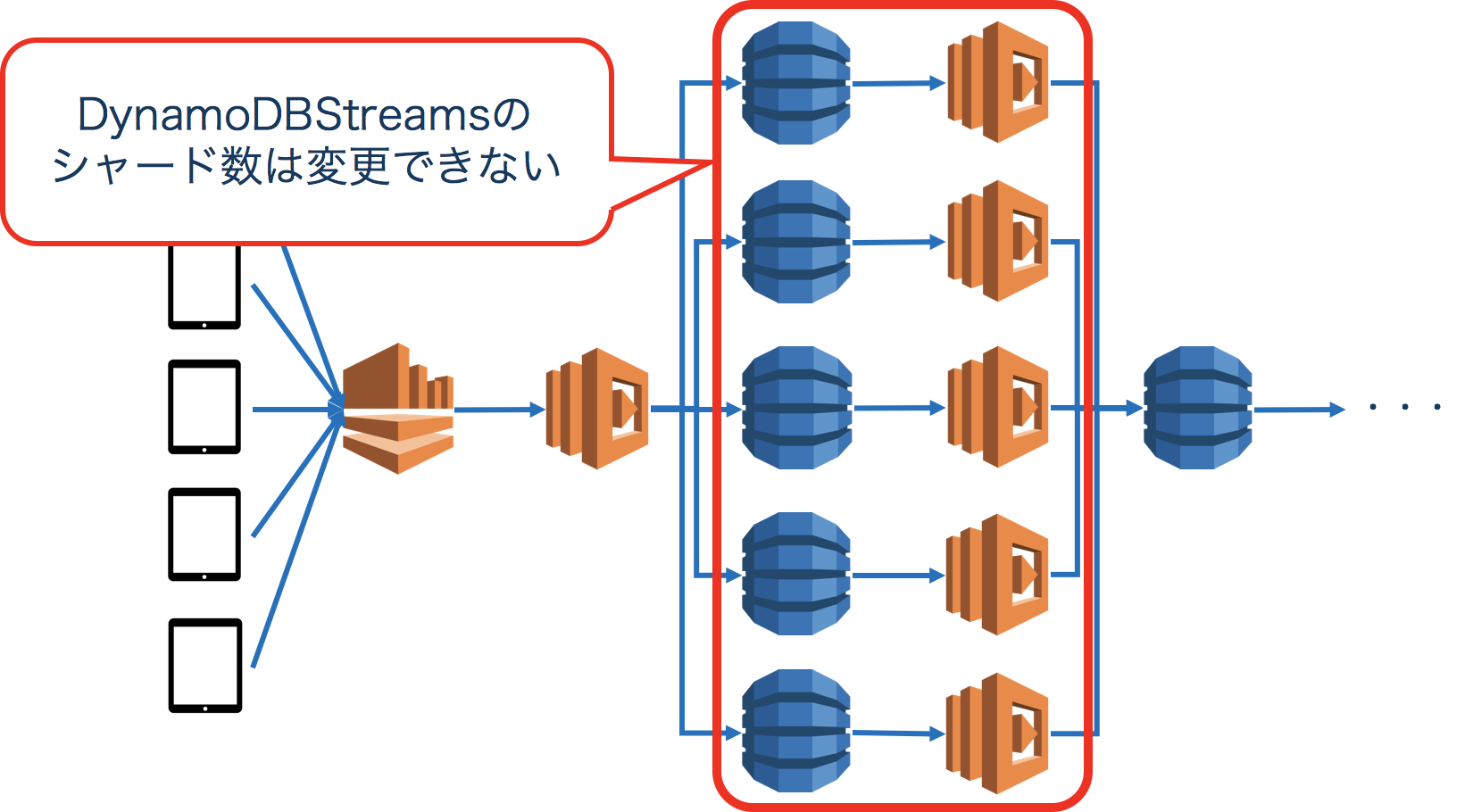
DynamoDBStreamsのシャード数はAWS内部で自動的に生成しては、削除してという感じになっているので、ユーザー側からコントロールすることができないのです…
どうするのか
現段階で回避するにはDynamoDBStreamsからLambdaの間にKinesisDataStreamsを挟む方法が有効です。

さいごに
DynamoDBはNoSQLなので、IoTとは相性が良いので、データの格納先にはベストなんだと思っています。
ですが決してとりあえず投げ込めばいいや。ということではないので、付随するサービスも合わせてアーキテクチャを考えていかないといけません。
またRDBと違い
- トランザクションという概念がない
- SQLは書けない
という特徴があるので、マスターデータなどの情報をDynamoDBで持つと、これも痛い目に遭うと思います。(これもアンチパターンの一つですかね…)
ではまた!