はじめに
前回の記事でLocustをシングルノードで起動することを試してみたが、これではほとんど性能が出ないので、マルチノードで起動して、かつマシンスペックにとらわれずにスケールするところまで試してみた。
先に言っておくが、ECS+Fargateでスケールするのはかなり自己満足の範囲で、EC2のインスタンスタイプを調整しながらdocker-composeでワーカーを調整する方がお手軽に起動することができる。
EC2でワーカーを起動する
ワーカーを起動するには、locustに対して以下の命令を与える。
ちょっと前のバージョンまでは --slave だったようなのだけど、githubの問題を受けて変わったようだ……。
$ locust --worker --master-host=[マスタのホスト名]
マスタで起動する場合は
$ locust --master
で良い。
さて、masterとworkerでは起動内容が違うが、コンテナの中身は同じで良いので、スクリプトで起動方法を変えられるようにしておこう。環境変数MODEで、マスタ起動かワーカー起動なのかを振り分ける起動用ラッパーシェルを作成する。
# !/bin/bash
echo "mode: $MODE"
if [ "$MODE" == 'master' ]; then
locust --master
elif [ "$MODE" == 'worker' ]; then
locust --worker --master-host=locust-master
fi
で、Dockerfileからはlocustそのものではなく、上記のラッパーシェルを起動するようにする。
FROM python
RUN pip install locust
WORKDIR /locust
COPY ./locustfile.py .
COPY ./run.sh .
RUN chmod 755 ./run.sh
CMD ["./run.sh"]
で、マスタとワーカーを同時に起動できるように、docker-compose.yml を定義する。
ポイントは、真歌のサービス名を locust-master にすること。
これにより、locust-master がワーカー起動時の ---master-hostのホスト名として認識されるようになる。
version: '3.4'
x-locust-service: &locust-service
build: .
services:
locust-master:
<<: *locust-service
ports:
- "80:8089"
environment:
MODE: master
locust-slave-1:
<<: *locust-service
environment:
MODE: worker
locust-slave-2:
<<: *locust-service
environment:
MODE: worker
locust-slave-3:
<<: *locust-service
environment:
MODE: worker
これで、docker-compose up --build で以下のようにワーカーが起動するようになる。
locust-slave-3_1 | mode: worker
locust-slave-1_1 | mode: worker
locust-slave-2_1 | mode: worker
locust-master_1 | mode: master
locust-slave-1_1 | [2020-08-16 04:34:40,234] 8cf353071957/WARNING/locust.main: System open file limit setting is not high enough for load testing, and the OS wouldnt allow locust to increase it by itself. See https://docs.locust.io/en/stable/installation.html#increasing-maximum-number-of-open-files-limit for more info.
locust-slave-1_1 | [2020-08-16 04:34:40,235] 8cf353071957/INFO/locust.main: Starting Locust 1.1.1
locust-slave-2_1 | [2020-08-16 04:34:40,528] 4919b452a0b1/WARNING/locust.main: System open file limit setting is not high enough for load testing, and the OS wouldnt allow locust to increase it by itself. See https://docs.locust.io/en/stable/installation.html#increasing-maximum-number-of-open-files-limit for more info.
locust-slave-2_1 | [2020-08-16 04:34:40,529] 4919b452a0b1/INFO/locust.main: Starting Locust 1.1.1
locust-slave-3_1 | [2020-08-16 04:34:40,544] c75ba98aab87/WARNING/locust.main: System open file limit setting is not high enough for load testing, and the OS wouldnt allow locust to increase it by itself. See https://docs.locust.io/en/stable/installation.html#increasing-maximum-number-of-open-files-limit for more info.
locust-slave-3_1 | [2020-08-16 04:34:40,545] c75ba98aab87/INFO/locust.main: Starting Locust 1.1.1
locust-master_1 | [2020-08-16 04:34:40,651] e1819ab325cb/WARNING/locust.main: System open file limit setting is not high enough for load testing, and the OS wouldnt allow locust to increase it by itself. See https://docs.locust.io/en/stable/installation.html#increasing-maximum-number-of-open-files-limit for more info.
locust-master_1 | [2020-08-16 04:34:40,652] e1819ab325cb/INFO/locust.main: Starting web interface at http://:8089
locust-master_1 | [2020-08-16 04:34:40,660] e1819ab325cb/INFO/locust.main: Starting Locust 1.1.1
locust-master_1 | [2020-08-16 04:34:40,688] e1819ab325cb/INFO/locust.runners: Client '8cf353071957_98e924e305fd45af8d56ffb3496faf46' reported as ready. Currently 1 clients ready to swarm.
locust-master_1 | [2020-08-16 04:34:40,715] e1819ab325cb/INFO/locust.runners: Client '4919b452a0b1_9d793c2ca4e64538a4bebc73c5c9c94d' reported as ready. Currently 2 clients ready to swarm.
locust-master_1 | [2020-08-16 04:34:40,730] e1819ab325cb/INFO/locust.runners: Client 'c75ba98aab87_aa5ede732c11490d823e0be1a2f20948' reported as ready. Currently 3 clients ready to swarm.
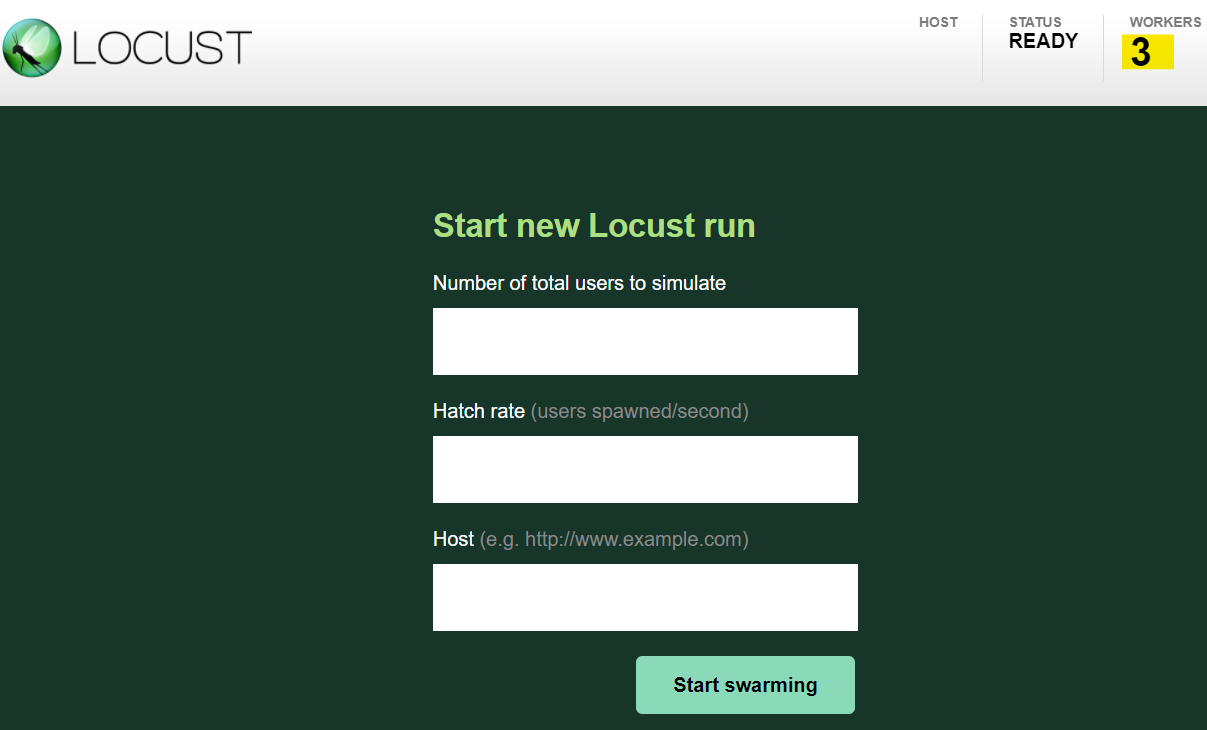
IPアドレスにアクセスすると、ちゃんとWORKERSが3になっている!もちろん性能も3倍!すごい!簡単!
ECS+Fargateでマスタとワーカーを同時に起動する
以下のような構成とする
ECSクラスタ
├── マスタ用サービス(必要数: 1)
│ └── マスタ用タスク定義
│ └── マスタ用コンテナ定義
└── ワーカー用サービス(必要数: 可変)
└── ワーカー用タスク定義
├── マスタヘルスチェック用コンテナ定義
└── ワーカー用コンテナ定義
ワーカーは起動時にマスタに対して通信を行う。
この際、ECSではIPアドレスが可変になってしまうため、サービスディスカバリを使って名前解決をできるようにする。
ただし、サービスディスカバリの登録にはタイムラグがあることと、同一タスク内であれば待ち合わせができるものの、サービスを跨いでの待ち合わせはできないため、マスタヘルスチェック用コンテナがサービスディスカバリの登録を待ち合わせ、その上でワーカー用コンテナを起動するという仕組みだ。
上記を踏まえて、以下のような設定を行う。
マスタ用サービス
マスタ用サービスのポイントは以下。
- Webサービス用ポートと、ワーカーからの通信用ポートを通すセキュリティグループを作る
- 上記の通りのサービスディスカバリの定義を行う
なお、VPCやECS用のIAMロールやCloudWatchLogsのロググループは事前に作ってあり、ECRへのコンテナイメージも事前にPUSHできている前提である。
resource "aws_security_group" "locust_master" {
name = "locust-master"
description = "Locust Master port allow"
vpc_id = data.aws_vpc.my.id
ingress {
description = "Locust Master Web Port"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Locust Master Internal Traffic Port"
from_port = 5557
to_port = 5557
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Locust Master Internal Traffic Port"
from_port = 5558
to_port = 5558
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_service_discovery_private_dns_namespace" "locust" {
name = local.namespace
vpc = data.aws_vpc.my.id
}
resource "aws_service_discovery_service" "locust_master" {
name = local.service_name
dns_config {
namespace_id = aws_service_discovery_private_dns_namespace.locust.id
dns_records {
ttl = 10
type = "A"
}
routing_policy = "MULTIVALUE"
}
health_check_custom_config {
failure_threshold = 1
}
}
resource "aws_ecs_cluster" "locust" {
name = local.cluster_name
}
resource "aws_ecs_service" "master" {
name = local.master_service_name
cluster = aws_ecs_cluster.locust.id
launch_type = "FARGATE"
task_definition = aws_ecs_task_definition.master.arn
desired_count = 1
deployment_controller {
type = "ECS"
}
network_configuration {
subnets = flatten([data.aws_subnet_ids.my_vpc.ids])
security_groups = [
aws_security_group.locust_master.id,
]
assign_public_ip = "true"
}
service_registries {
registry_arn = aws_service_discovery_service.locust_master.arn
}
}
resource "aws_ecs_task_definition" "master" {
family = local.master_task_family_name
task_role_arn = aws_iam_role.ecs.arn
execution_role_arn = aws_iam_role.ecs_taskexecution.arn
network_mode = "awsvpc"
cpu = "256"
memory = "512"
requires_compatibilities = [
"FARGATE",
]
container_definitions = <<EOF
[
{
"name" : "${local.master_container_name}",
"image": "${data.aws_ecr_repository.my_image.repository_url}:latest",
"cpu": 0,
"memoryReservation": 256,
"environment": [
{
"name": "MODE",
"value": "master"
}
],
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
},
{
"containerPort": 5557,
"hostPort": 5557,
"protocol": "tcp"
},
{
"containerPort": 5558,
"hostPort": 5558,
"protocol": "tcp"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"secretOptions": null,
"options": {
"awslogs-group": "${aws_cloudwatch_log_group.ecstask_log_group.name}",
"awslogs-region": "${data.aws_region.current.name}",
"awslogs-stream-prefix": "ecs"
}
}
}
]
EOF
}
ワーカー用サービス
レプリカ用サービスのポイントは以下。
- 自身は通信を受けないので、アウトバウンド定義のみのセキュリティグループを作成する
- 上記の通り、ヘルスチェックを行うためのダミーコンテナを使う
- 必要数を
desired_count = var.worker_countとして指定できるようにする
esource "aws_security_group" "locust_worker" {
name = "locust-worker"
description = "Locust Worker port allow"
vpc_id = data.aws_vpc.my.id
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_ecs_service" "worker" {
depends_on = [
aws_service_discovery_service.locust_master,
]
name = local.worker_service_name
cluster = aws_ecs_cluster.locust.id
launch_type = "FARGATE"
task_definition = aws_ecs_task_definition.worker.arn
desired_count = var.worker_count
deployment_controller {
type = "ECS"
}
network_configuration {
subnets = flatten([data.aws_subnet_ids.my_vpc.ids])
security_groups = [
aws_security_group.locust_worker.id,
]
assign_public_ip = "true"
}
}
resource "aws_ecs_task_definition" "worker" {
family = local.worker_task_family_name
task_role_arn = aws_iam_role.ecs.arn
execution_role_arn = aws_iam_role.ecs_taskexecution.arn
network_mode = "awsvpc"
cpu = "1024"
memory = "2048"
requires_compatibilities = [
"FARGATE",
]
container_definitions = <<EOF
[
{
"name" : "dummy",
"image": "${data.aws_ecr_repository.my_image_dummy.repository_url}:latest",
"cpu": 0,
"memoryReservation": 256,
"logConfiguration": {
"logDriver": "awslogs",
"secretOptions": null,
"options": {
"awslogs-group": "${aws_cloudwatch_log_group.ecstask_log_group.name}",
"awslogs-region": "${data.aws_region.current.name}",
"awslogs-stream-prefix": "ecs"
}
},
"healthCheck": {
"command": [
"CMD-SHELL",
"curl -f http://${local.service_name}.${local.namespace}/ || exit 1"
],
"interval": 30,
"retries": 10,
"startPeriod": 30,
"timeout": 5
}
},
{
"name" : "${local.worker_container_name}",
"image": "${data.aws_ecr_repository.my_image.repository_url}:latest",
"cpu": 0,
"memoryReservation": 1792,
"environment": [
{
"name": "MODE",
"value": "worker"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"secretOptions": null,
"options": {
"awslogs-group": "${aws_cloudwatch_log_group.ecstask_log_group.name}",
"awslogs-region": "${data.aws_region.current.name}",
"awslogs-stream-prefix": "ecs"
}
},
"dependsOn": [
{
"containerName": "dummy",
"condition": "HEALTHY"
}
]
}
]
EOF
}
マスタ起動待ち合わせの仕組み
マスタ起動待ち合わせの仕組みは、ECS標準の待ち合わせ機能+ヘルスチェック機能を使う。
待ち合わせについては開発者ガイドに記載がある。
↓これをワーカー用のコンテナ定義の中に入れれば良い。
"dependsOn": [
{
"containerName": "dummy",
"condition": "HEALTHY"
}
これは、"name"属性が dummy となっているコンテナのヘルスチェック状態がHEALTHYになるのを待ち合わせてから起動することを意味する。
ヘルスチェックの仕組みは、ECS(というかDocker)の標準機能を利用する。
ECSの仕組みとしては開発者ガイドに記載があり、Dockerの仕組みについてはここの記載が分かりやすかった。
本当は、自分に対するヘルスチェックに使うもののような気がするので、ちょっと変な使い方をしている。
以下のようにして、「curlが成功する=サービスティスカバリの登録が済んで名前解決ができるようになった」こととして、ヘルスチェック成功と扱うようにしている。
EC2とかからサービスディスカバリの名前を参照するとすぐ見つかるが、なぜかコンテナからは5分くらいかかったので、ヘルスチェックは長めに設定している。
{
"name" : "dummy",
"image": "${data.aws_ecr_repository.my_image_dummy.repository_url}:latest",
"cpu": 0,
"memoryReservation": 256,
"logConfiguration": {
"logDriver": "awslogs",
"secretOptions": null,
"options": {
"awslogs-group": "${aws_cloudwatch_log_group.ecstask_log_group.name}",
"awslogs-region": "${data.aws_region.current.name}",
"awslogs-stream-prefix": "ecs"
}
},
"healthCheck": {
"command": [
"CMD-SHELL",
"curl -f http://${local.service_name}.${local.namespace}/ || exit 1"
],
"interval": 30,
"retries": 10,
"startPeriod": 30,
"timeout": 5
}
},
Dockerのヘルスチェックの仕組みは、あくまでもDockerデーモンがコンテナに対して支持を出すものなので、コンテナにcurlが入っていなければいけない。以下のようにしてコンテナを定義しておこう。
FROM alpine
RUN apk add --no-cache curl
WORKDIR /var
COPY ./rundummy.sh .
RUN chmod 755 ./rundummy.sh
CMD ["./rundummy.sh"]
# !/bin/sh
while true; do date; curl -f http://[サービスディスカバリ名]/; echo $?; sleep 60; done
わざわざコンテナの中でもcurlしているのは、ヘルスチェックはどこにもログが出ず、UNHEALTHYになったときにcurlが通らなかったのか別の原因なのかの切り分けができなかったからである。
これで terraform apply -var worker_count=2 したらちゃんとワーカーが2つ上がるようになった!