はじめに
機械学習、初心者です。むかし、ほんのほんのちょこっとだけ解析とかやってましたが素人に毛が生えた程度です。久々に本屋に行ったら、技術書コーナーがディプラーニングで染まっていたので流れに乗ってみようとおもいました。平積みになっていた「TensorFlowで学ぶディプラーニング入門」を一通り読みCNNの概要を把握したのですが、やはり実感が湧きません。こういうときは実際に手を動かすのが1番と思い、Yahoo!ニュースを解析してみることにしました。今回の目的は、自分で集めたデータでとにかくTensorFlowしてみるですので、もっと最適な分類方法はあるかもしれません。
ソースコードはこちらです。コメントがあまり書かれていないので汚いです。すこしずつ整理しております。
https://github.com/naronA/news-category-learning
なにするの?
Yahoo!ニュースの本文から、そのニュースのカテゴリーを推測してみます。下記画像の赤丸がYahoo!ニュースのカテゴリーの一例です。


ただし、カテゴリーによっては1週間で数件しか集まらないこともあるので、毎日で50件以上は集まるカテゴリーに絞りました。
具体的には、**「IT総合」「映画」「経済総合」「野球」「社会」「ライフ総合」「エンタメ総合」「サッカー」「スポーツ総合」**の9つを分類します。
スクレイピング
当然ですが手元には何もデータがないですし、Yahoo!ニュースはアーカイブを公開していないので、スクレイピングしてきます。Yahoo!のニュースはRSSでも配信されています。RSSのxmlには「記事タイトル」「記事のURL」「カテゴリー」「出版日」が記述してあるので、RSSで全てカバーできます。ちなみにスクレイピングには、BeautifulSoupを用い、4列のCSV形式で出力します。
カテゴリー, ニュースタイトル, 原稿文字数, 原稿本文
ニュースタイトルは、取得できるので念のためスクレイピングしていますが、今回は使用していません。原稿文字数は、短すぎる原稿はデータとして使えないので後ほど足切りをするために加えました。
ソースコードは長くなるので、URLを貼っておきます。
https://github.com/naronA/news-category-learning/tree/master/scrape
ベクトル化
カテゴリー
「IT総合」「映画」「経済総合」「野球」「社会」「ライフ総合」「エンタメ総合」「サッカー」「スポーツ総合」の9カテゴリーなので9次元のベクトルを作っていきます。
IT総合 = [ 1, 0, 0, 0, 0, 0, 0, 0, 0 ]
映画 = [ 0, 1, 0, 0, 0, 0, 0, 0, 0 ]
…
スポーツ総合 = [ 0, 0, 0, 0, 0, 0, 0, 0, 1 ]
ニュース原稿
ニュース原稿からTFIDFベクトルを構築していきます。形態素解析にはjanomeを使用します。流行りはWord2Vecのように単語単位のベクトル化のようですが、今回はあくまでTensorFlow入門なので、学習データにはあまり拘らないようにします。Word2Vecは後々つかってみようと思います。当然ですが、スッカスカの数万次元の疎ベクトルになります。日を重ね、データ集まるごとにメモリを圧迫してしまうため、最後に主成分分析をもちいて1000次元にまで削減します。
ノーマライズ&トークナイズ
大半のニュース記事は終始日本語ですが、時々ですが特殊な記事が混じります。所々に英文が引用される記事や、スポーツ系のスコアなど数字と記号の羅列が含まれている記事があります。形態素解析にはjanomeを用いましたのですが、janomeは「英文」や「数字、記号の羅列」を読み込ませるとIndexErrorを返します。「英文」や「数字、記号の羅列」は、テゴリーを表現する大きな特徴にはなりそうもないので、すべて句読点「、」に置き換えてIndexErrorを回避します。(日本語文の中の英字はなるべく削除しません)
def filter_manuscript(manuscript: str) -> str:
# 英文を取り除く(日本語の中の英字はそのまま)
manuscript = re.sub(r'[a-zA-Z0-9]+[ \,\.\':;\-\+?!]', '', manuscript)
# 記号や数字は「、」に変換する。
# (単純に消してしまうと意味不明な長文になりjanomeがエラーを起こす)
manuscript = re.sub(r'[0-9]+', '、', manuscript)
manuscript = re.sub(
r'[!"“#$%&()\*\+\-\.,\/:;<=>?@\[\\\]^_`{|}~]+', '、', manuscript)
manuscript = re.sub(r'[()【】『』{}「」[]《》〈〉]', '、', manuscript)
return manuscript
形態素解析でトークナイズしたのち、**「名詞」「動詞」「形容詞」**のみを使ってTFIDFを作っていきます。原形が取得できれば、原形を用います。日本語の文章に含まれている全角の英字を半角にしておきます。半角変換には、mojimojiを使用しています。
tokenizer = Tokenizer()
def tokenize(manuscript: str) -> list:
token_list = []
append = token_list.append
try:
tokens = tokenizer.tokenize(manuscript)
except IndexError:
print(manuscript)
return None
for tok in tokens:
_ps = tok.part_of_speech.split(',')[0]
if _ps not in ['名詞', '動詞', '形容詞']:
continue
# 原形があれば原形をリストに入れる
_w = tok.base_form
if _w == '*' or _w == '':
# 原形がなければ表層系(原稿の単語そのまま)をリストに入れる
_w = tok.surface
if _w == '' or _w == '\n':
continue
# 全角英数はすべて半角英数にする
_w = mojimoji.zen_to_han(_w, kana=False, digit=False)
# 半角カタカナはすべて全角にする
_w = mojimoji.han_to_zen(_w, digit=False, ascii=False)
# 英語はすべて小文字にする
_w = _w.lower()
append(_w)
return token_list
ベクトル化と主成分分析による次元削減
TFIDFはsklearnで作成できますが、今回は自作していきます。ノーマライズとトークナイズは前処理として全て済ましてからベクトル化しています。 前処理のによって「最大次元数」「各単語の次元」「各単語のIDF」等は予め算出しておきます。
また、およそ1週間でTFIDFベクトルの次元数が6万次元を越えたため主成分分析で次元削減を行うことにしました。ただし単純に主成分分析するとメモリ不足になるので、IncrementalPCAを用いて削減していきます。
class PCATfidfVectorizer:
def __init__(self, prep: Preprocessor, dimension: int):
self.prep = prep
self.cat_list = list(self.prep.categories)
self.cat_len = len(self.prep.categories)
self.max_dim = self.prep.token_seq_no
self.ipca = IncrementalPCA(n_components=dimension)
def fit(self, tokenized_news: list,
batch_size: int) -> None:
news_len = len(tokenized_news)
random.shuffle(tokenized_news)
for i in range(0, news_len, batch_size):
chunks = tokenized_news[i:i + batch_size]
mat = [self.tfidf(c[1]) for c in chunks]
self.ipca.partial_fit(mat)
def vectorize(self, tokenized_news: list) -> np.array:
data = []
for news in tokenized_news:
category = news[0]
category_vec = self.prep.category_dic[category]
token_counter = news[1]
tf_vec = self.tfidf(token_counter)
reshaped = np.array(tf_vec).reshape(1, -1)
dimred_tfidf = self.ipca.transform(reshaped)[0]
data.append((category_vec, dimred_tfidf))
return np.array(data)
def tfidf(self, token_counter: Counter) -> list:
prep = self.prep
tf_vec = [0.0] * self.max_dim
total_tokens = sum(token_counter.values())
for token, count in token_counter.items():
uid = prep.token_to_id[token]
tf_vec[uid] = float(count) / total_tokens * prep.idf[token]
return tf_vec
(おまけ)削減後のデータをグラフ化
1000次元に削減した各カテゴリーのベクトルの平均値を横に並べたグラフです。次元削減をしているので、もはやTFIDFベクトルではありませんが、傾向をつかめるとおもいグラフ化してみました。
ただし全次元を表示すると潰れてしまって何が何だかわかりません。
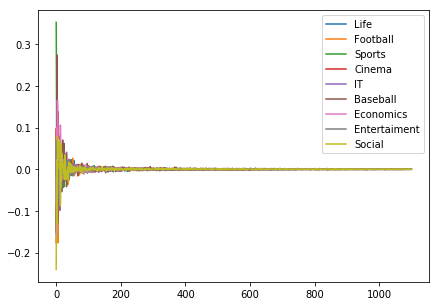
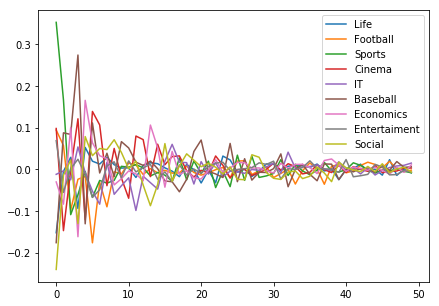
そこで目視でも特徴が見て取れそうな先頭50次元を抜き出します。ただし、1,2次元目は、他の値に対してかなり大きな値になっておりグラフが潰れてしまうので、3次元から表示しています。なんとなくですが、特徴が見て取れます。
いざディプラーニング
といってもデータ収集や前処理にくらべて学習は「TensorFlowヨロシク」なので、これといって語ることないですね…。パラメーター調整の勘所が全くなくて苦労したのが思い出でしょうか。
隠れ層2層の単純なニューラルネットワークを形成します。各パラメータは試行錯誤の結果です。確率的勾配降下法をもちいて100件ずつ学習したり、Dropoutを用いて学習用データの少なさをカバーしています。あっという間に発散してしまうので学習率はかなり小さくしています。ニューロン数は4000。
- データ数 約15000 記事
- 訓練用データ: 約13000 (ランダムに選んだ100記事で訓練)
- 予測用データ: 約1300
- 隠れ層: 2
- ニューロン数: 4000
- 学習率: 0.000001
- Dropout: 50%
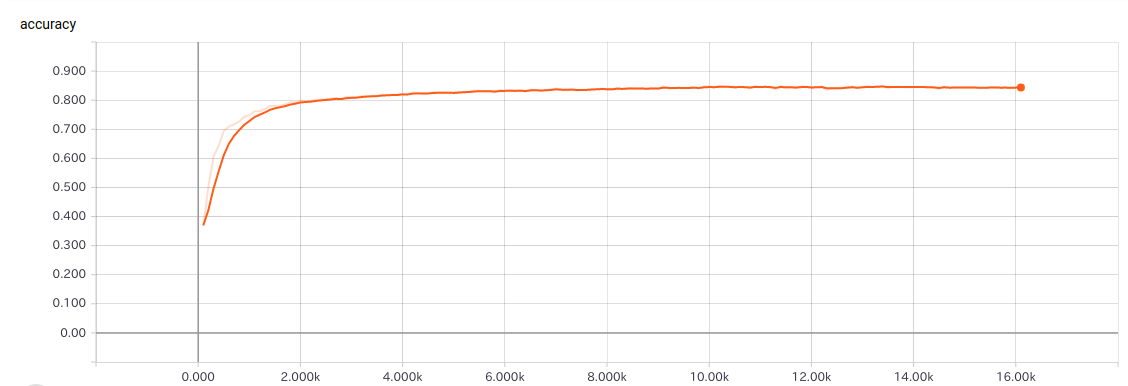
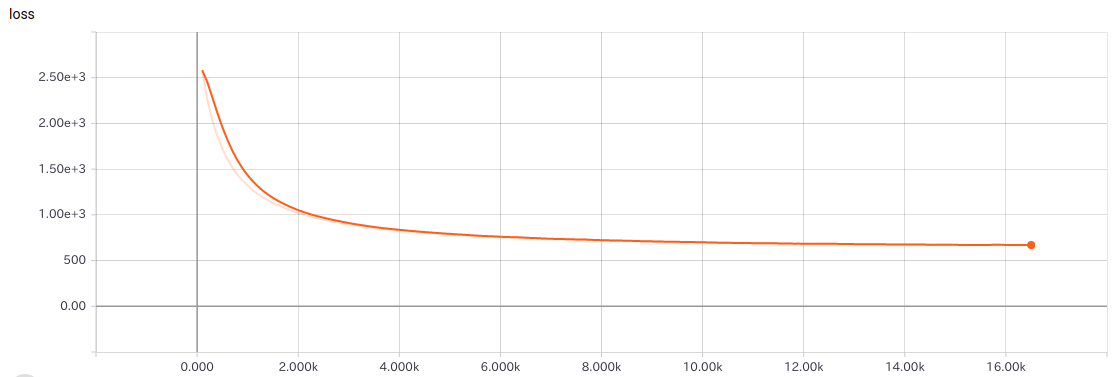
結果
**85%の判定に成功しました。**90%はいきたかった。
評価
- もっとよい方法で、前処理&学習したら90%くらいは越えられそうな気もするが圧倒的に知識が足りない
- ニュース原稿の質はピンキリなので、TFIDFでは分類不能な文書が点在する
- そもそもYahoo!ニュースのカテゴリが厳密ではない可能性も(負け惜しみ)
まとめ
- 苦労の大半はデータ収集と次元削減に費やされました。
- 次元削減が肝の一つだと感じました。TFIDFは、隣接する次元との関連性が全く無いので、フィルター等を用いて特徴を抜き出せないのが難点でした。やはりWord2Vecなのでしょうか。
- はじめてのディプラーニングにしてはデータが高次元すぎました。もうちょっと小さなデータから始めるべきだったかなと思います。