アドベントカレンダー16日目の記事です。
概要
メタップスホールディングスでは、SRE が横断的に複数のプロダクトを支えています。その背景には、日々の試行錯誤と改善の積み重ねがあります。
SRE という職種は技術的な専門性だけでなく、運用効率の向上や信頼性確保のため、組織の文化やプロセスの改善も担う役割です。
今回の記事では、SRE 組織の立ち上げから得られた実践例や学びを共有します。
これから SRE を始める方や、導入を検討している方にとって何かしらのヒントになれば幸いです。
ベストプラクティスの実践
弊社が Google の SRE 本1 で紹介されているベストプラクティスを全てを実践できているかと言われれば、必ずしもそうではありません。
例えば、SLO (Service Level Objective) やエラーバジェット 2、トイルの削減といった基本的な概念は意識しながらも、限られたリソースの中で、完璧に実践するのは現実的ではありません。その代わりとして、特にインフラ基盤の安定性向上と障害を未然に防ぐための仕組み作りに注力してきました。
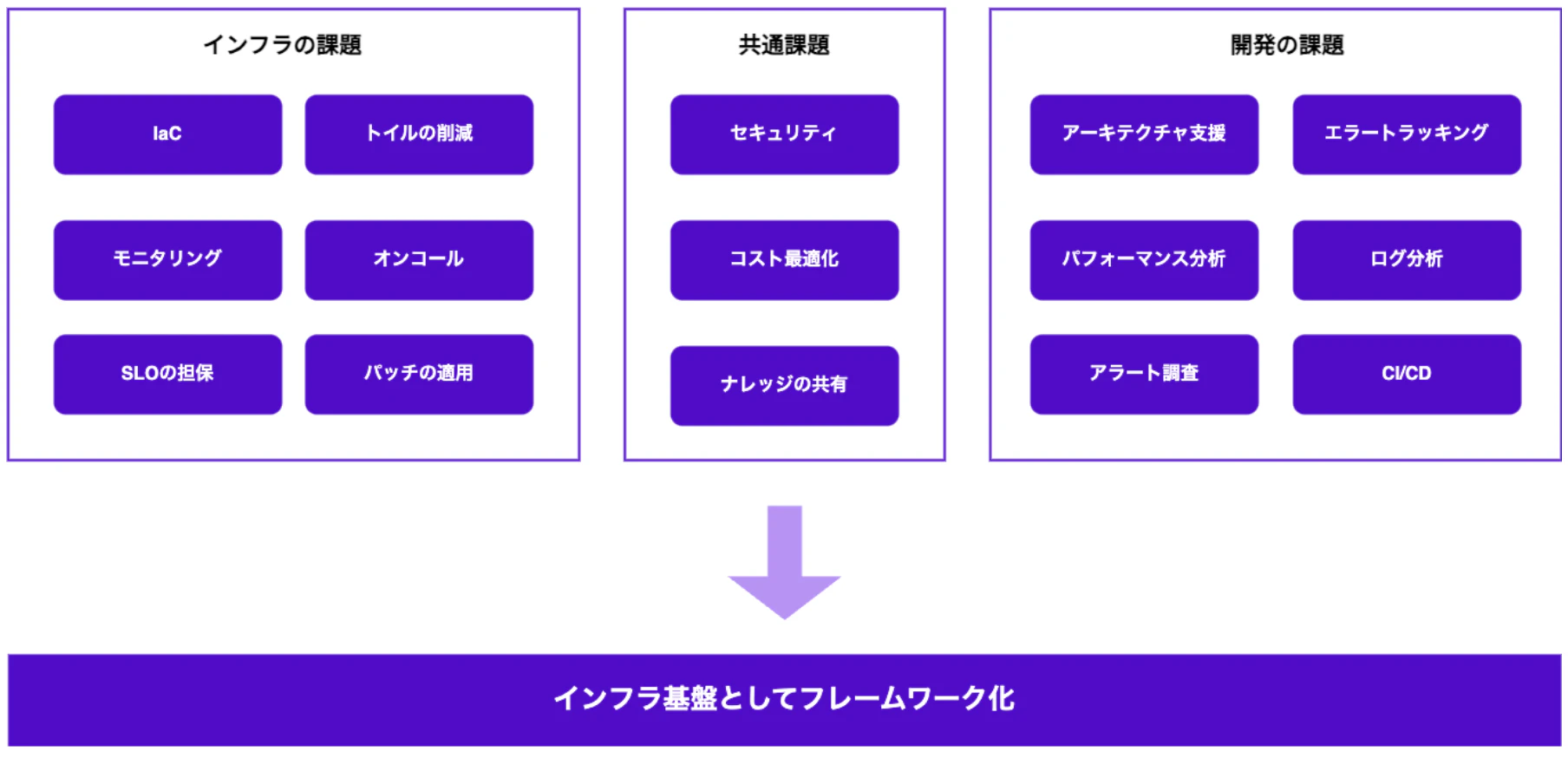
具体的には、クラウドインフラの構築や自動化、監視体制の整備にリソースを集中させています。
高可用性アーキテクチャの採用やスケーラビリティの向上といった、障害が発生しにくい設計を心掛けるとともに、異常が発生した際に迅速に検知・対応できるよう、Datadog や PagerDuty といったツールを活用した監視基盤を整備しています。
組織編成
SRE チームの編成は、開発体制やプロダクトチームの数や規模、方向性に応じて柔軟に考える必要があり、その実現方法としては、開発チームが主体となって運用改善を進める SREing や、専任の SRE チームを設ける手段があります。
メタップスでは、複数の自社プロダクトを展開していることや、開発組織の拡大に伴うスケールの課題、またインフラ領域における高度な専門性が求められる課題に対応する必要がありました。
このため、プロダクトを横断した SRE チームを編成し、各プロダクトチームに SRE エンジニアが参画する仕組みを採用しました。
また、SRE チームの役割を明確化するため、Embedded SRE と Platform SRE の 2 つの役割に分けて活動しています。Embedded SRE は各プロダクトチームに参画し、現場の課題解決や運用改善をサポートします。一方で、Platform SRE はインフラ基盤となるフレームワークや共通ツールを開発し、全プロダクトに横展開する役割を担っています。
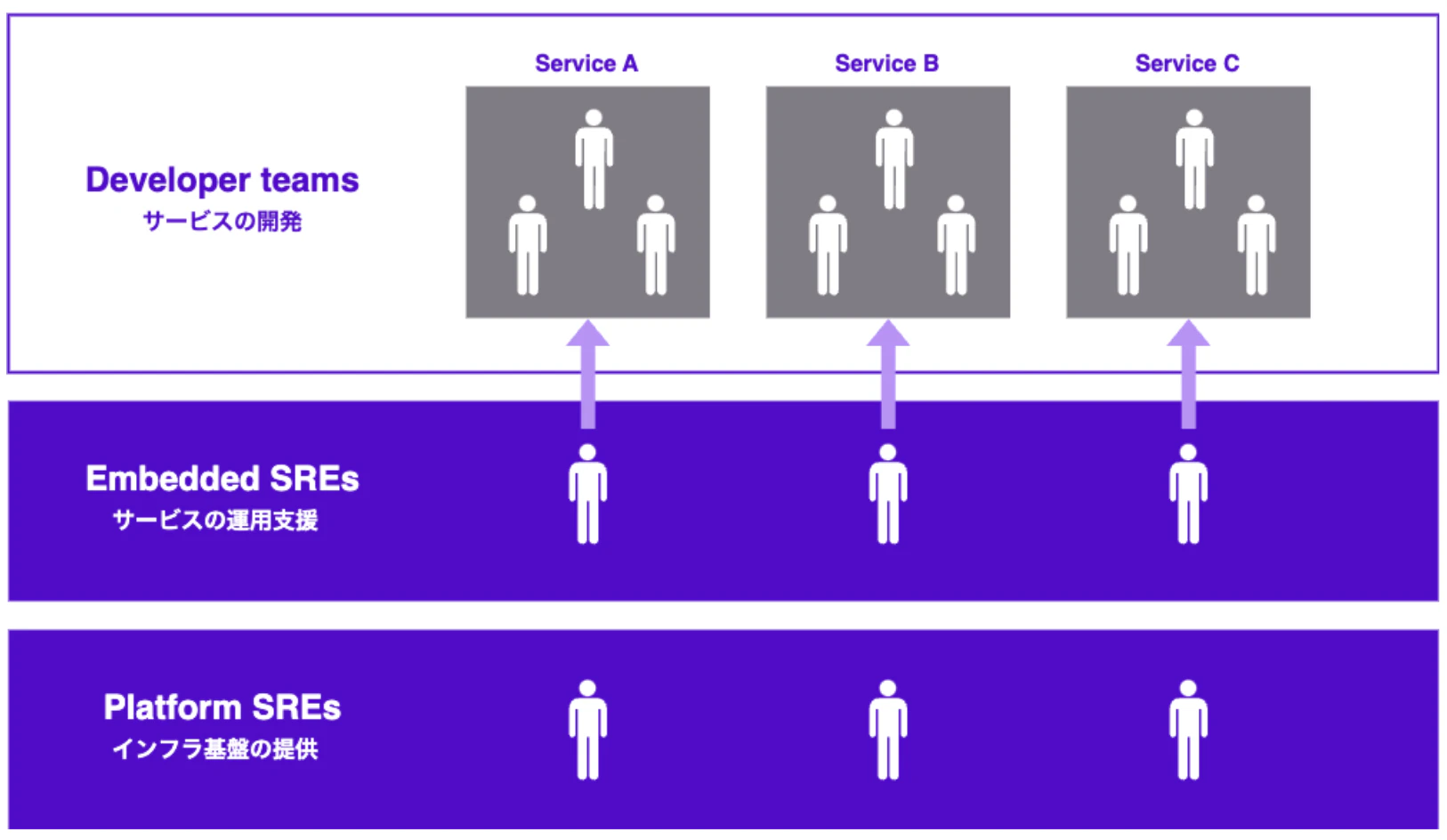
この構成により、Embedded SRE はプロダクトごとの固有のニーズに迅速に対応しながら、Platform SRE が提供する標準化された基盤を活用して効率的な運用を実現しています。
結果として、プロダクトごとの柔軟性と組織全体としてのスケーラビリティを両立する SRE の仕組みを築くことができました。
アーキテクチャ
インフラ構成は、SRE 組織立ち上げ当初から Amazon ECS を主軸に構築されており、データベースには Amazon RDS、キャッシュには Amazon ElastiCache を使用しています。
また、ログ管理には Fluentd と Datadog を活用し、アプリケーションのエラートラッキングには Sentry、オンコール対応には PagerDuty を採用しています。
この基本的な構成は、組織を立ち上げて 6 年が経過した現在も変わらず安定した運用を支えています。
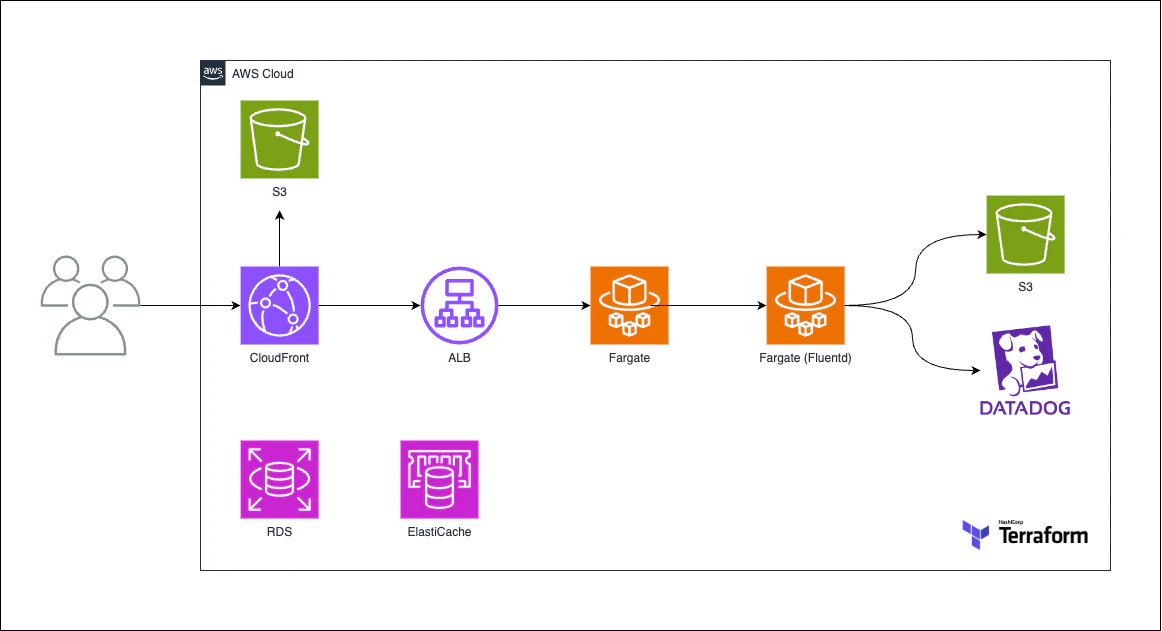
プロダクトの要件に応じて構成を拡張することもあります。例えば、予測不能なトラフィックへの対応には Amazon Kinesis と AWS Lambda を組み合わせ、大規模なログデータの集積基盤には Amazon OpenSearch Service を活用するケースがあります。
これらのサービスを活用するだけでなく、プロダクトの要件や成長に合わせてリアーキテクトを行うことで、スケーラブルかつ効率的なデータ処理を最適な形で実現しています。
SLO
SLO は Datadog を活用して監視しています。各プロダクトの特性に応じた基準値を定義し、それを Datadog 上でリアルタイムに可視化することで、プロダクトの稼働状況を迅速に把握できる環境を整えています。
また、自社で開発した専用のダッシュボード3 を活用することで、Datadog アカウントを横断し、より視覚的に SLO の状況を把握しやすくしています。これにより、プロダクトの稼働率やレイテンシーといった重要な指標を、直感的に理解できる仕組みを構築しています。
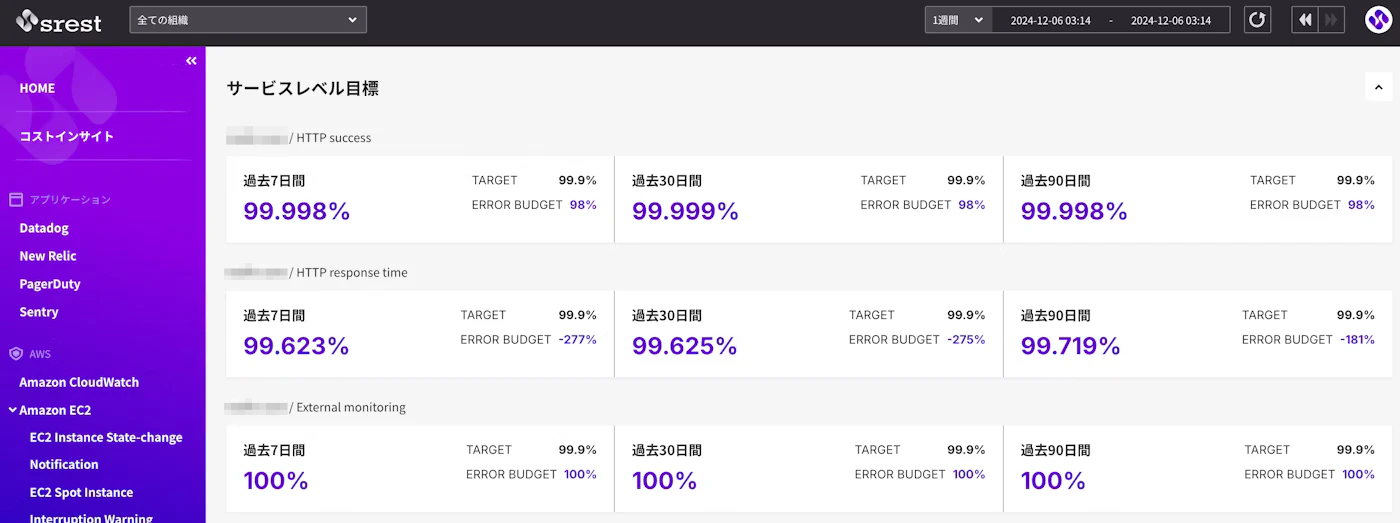
現状では、ユーザージャーニーを軸にした包括的な計測やエラーバジェットの厳密な管理までは到達していませんが、プロダクトの状況を把握し、安定性の向上に向けた取り組みを進めるための有効な基盤となっています。
IaC
Terraform を採用しています。AWS CloudFormation や AWS CDK といった選択肢も検討しましたが、AWS 以外のサービスも一元的にコード管理したいという目的から Terraform を選びました。
具体的には以下のサービスを Terraform で管理しています。
- AWS
- Google Cloud
- Datadog
- Sentry
- GitHub
- PagerDuty
- SendGrid
Terraform を使用する際に悩みどころとなるのがディレクトリ構成です。
メタップスでは、AWS や Datadog などのリソースを管理する上で、以下のようなディレクトリ構成を長年に渡って採用してきました。
providers/aws
general
ap-northeast-1
chatbot
main.tf
...
cloudtrail
cloudwatch
global
route53
application
ap-northeast-1
ec2
documentdb
opensearch_service
このディレクトリ構成は、直感的で分かりやすい点が特徴です。万が一オペレーションミスが発生しても障害範囲を最小限に抑えられるほか、複数人が同時に編集してもコンフリクトが起きにくい利点があります。
一方で、state がディレクトリ単位に分割されることにより、リソース間の依存関係を data ソースで参照するケースが増え、コードが複雑化し、可読性が低下するという課題も抱えていました。
この課題については、数年にわたり社内で議論を重ねてきましたが、今年から以下のような新しいディレクトリ構成へと大幅な変更を実施しました。
providers/aws
general
network
vpc.tf
cloudmap.tf
route53.tf
...
storage
application
analytics
compute
database
新しいディレクトリ構成の最大の特徴は、各リソースを network や storage といった抽象化されたレイヤーごとに分割し、ディレクトリ階層を簡素化した点です。この変更により、state の分散による課題を解消するとともに、複数人でコードを編集する際のコンフリクトも最小限に抑えることができました。
さらに、このディレクトリ構成は全プロダクトで共通化されており、管理の効率化を実現しています。具体的には、AWS 公式のモジュール 4 の利用に加え、社内のプライベートリポジトリで Terraform モジュールを管理する仕組みを導入し、再利用性を高める運用を構築しています。
モニタリング
インフラの監視には Datadog を活用しています。主に利用している機能は Monitor、Synthetic Monitoring & Testing、SLOs あたりです。これらのリソースは全て Terraform によってモジュール化されており、各プロダクトではモジュールを利用するかどうかの選択と、しきい値の設定だけで対応可能な仕組みを構築しています。

Datadog は SRE チームだけでなく、アプリケーションエンジニアも利用するため、年に 1 回程度のペースで APM やログの活用方法に関する勉強会を開催しています。これにより、エンジニア全体の監視ツールへの理解を深め、より効果的な運用ができる環境を整えています。
ログ
アプリケーションから出力されたログは、AWS Fargate から AWS FireLens 経由で Fluentd に集約し、フォーマットを整形した上で各種ログサービスに配送しています。
オブザーバビリティの観点からは、Datadog を活用してメトリクス、トレース、ログを一元管理できる利点がありますが、同時にアプリケーションによってはログの転送量が膨大になるケースがあり、Datadog のコストが課題となることもあります。
そこで Fluentd を活用し、Datadog Log に加えて S3 にもログを配送する仕組みを導入しました。この運用により、開発者は直近のログを Datadog で素早く確認し、さらに古いログについては Amazon Athena を使用して必要に応じて検索できるフローを整備しました。
また、Datadog のコスト課題に対処するため、以下の施策を実施しています。
-
ログの保管期間の見直し
必要以上に長期間ログを保持せず、Datadog Log の転送量と保存コストを抑制します -
ログレベルの最適化
アプリケーションから出力されるログを精査し、不要なログレベル (デバッグログなど) の出力を削減することでデータ量を削減します -
Fluentd によるログの整形
配送前に Fluentd を活用し、不要な情報を削除して効率的なログ管理を実現しています
これらの対策により、一定のコスト削減を実現していますが、一部のプロダクトではこれだけでは十分な効果が得られない場合もあります。
こうした場合には、Datadog Log を使用せず、ログを直接 S3 に保存する運用を採用しています。
このように、Datadog を中心とした監視体制を維持しながら、コストと効率のバランスを考慮し、プロダクトごとに適した柔軟なログ管理運用を行っています。
Fargate を利用したアプリケーションログの設計については、以前に Qiita の記事でも詳しく解説していますので、参考にしてみてください。
トレース
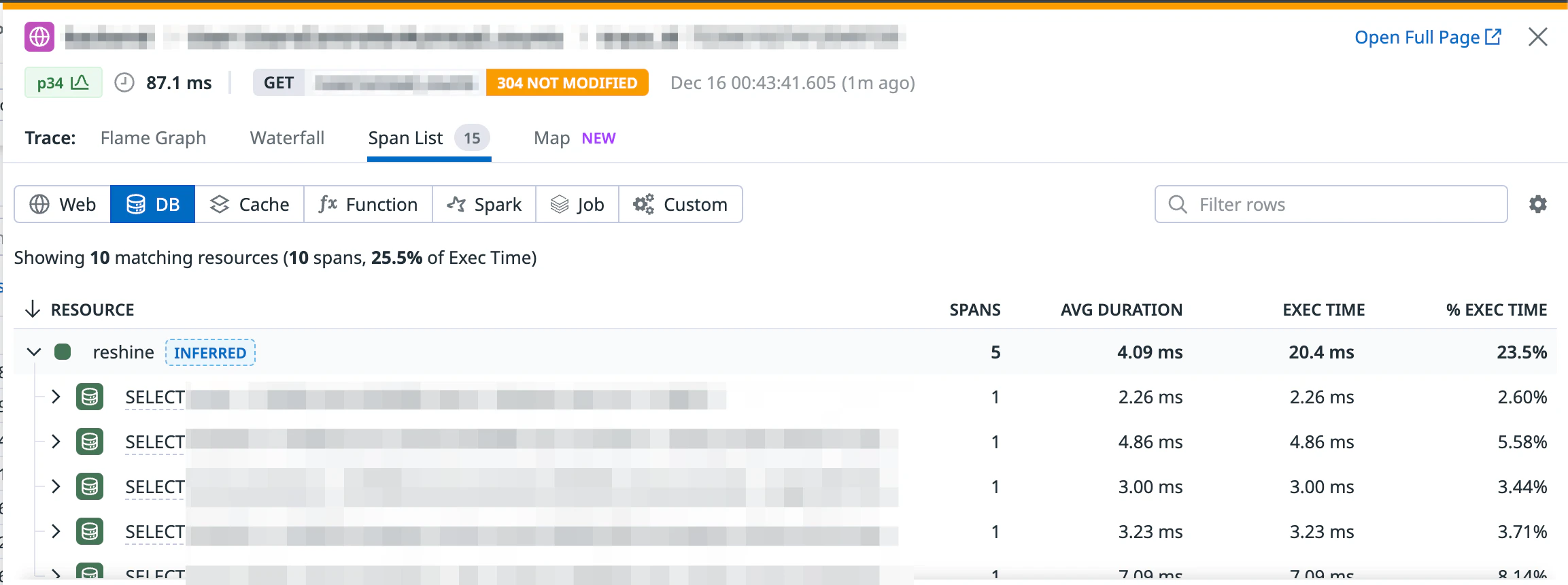
アプリケーションのトレースには Datadog APM を活用し、リクエスト単位で処理の流れを調査できる仕組みを整えています。
Datadog APM は特に N+1 クエリや外部 API の呼び出しといったボトルネックの可視化に優れており、これを活用して開発者はパフォーマンス改善に取り組んでいます。
また、レイテンシーが高い場合には APM を確認することで、問題のあるリクエストを即座に特定・分析できるため、迅速なトラブルシューティングが可能になります。
エラートラッキング
アプリケーションのエラートラッキングには Sentry を導入し、エラーの検知と分析を効率化しています。
Sentry の利用にあたって、以下のポイントに留意しながら運用を進めています。
-
クォーター対策
-
ローカル環境でのエラー通知を無効化
ローカル環境で発生したエラーが Sentry に通知されないよう設定し、不要なエラーの記録を防いでいます -
サンプリングレートの活用
トラフィックの多いサービスにおいては、エラーのサンプリングレートを設定し、重要な情報を維持しつつクォーターを節約しています
-
ローカル環境でのエラー通知を無効化
-
フロントエンドのバグ再現
Sentry Replay を活用することで、フロントエンドのバグを正確に再現可能な環境を整備しています -
Slack 連携
最近のアップデート 5 で Slack でのメンションがサポートされ、運用がさらに便利になりました -
ログレベル、環境、コンテキスト
エラーメッセージにログレベル、環境、コンテキストなどの付加情報を追加することで、エラー内容を詳細に記録しています -
Terraform によるコード化
Sentry のアラート設定や通知ルールを Terraform によりコード化しています。この取り組みにより、設定内容の管理が効率化され、アラート運用の一貫性を確保できるようになりました
CI/CD
GitHub Actions を採用しています。主にアプリケーションのテストやデプロイ、Terraform の実行といった用途で活用しており、開発と運用の効率化に寄与しています。
AWS ECS のデプロイには、内製で開発した genova を利用しています。
このツールは SRE 組織立ち上げ当初から運用されており、社内のフィードバックを反映しながら継続的にアップデートを行ってきました。genova により、ECS 環境へのアプリケーションデプロイが効率化され、安定した運用が可能になっています。

一方で、GitHub Actions は各チームが共通して利用しているため、時間帯によってはリソースの占有が問題になる場合があります。このため、CI 実行時間の最適化が重要な課題となっています。
現在は、実行時間を可視化する取り組みを進めており、Datadog の CI Visibility のようなツールの導入も検討しています。
構成のアップデート
インフラの改善タスクは大きく 2 つのカテゴリに分けられます。
一つは、特定のプロダクトに依存するタスクです。例えば、サーバーのスケールアップや接続元 IP アドレスの許可設定など、プロダクト固有の要件に応じた変更がこれに該当します。
もう一つは、複数のプロダクトに共通する横断的な改善タスクです。Terraform のアップグレードや DMARC レコードの追加といった変更は、このカテゴリに属します。
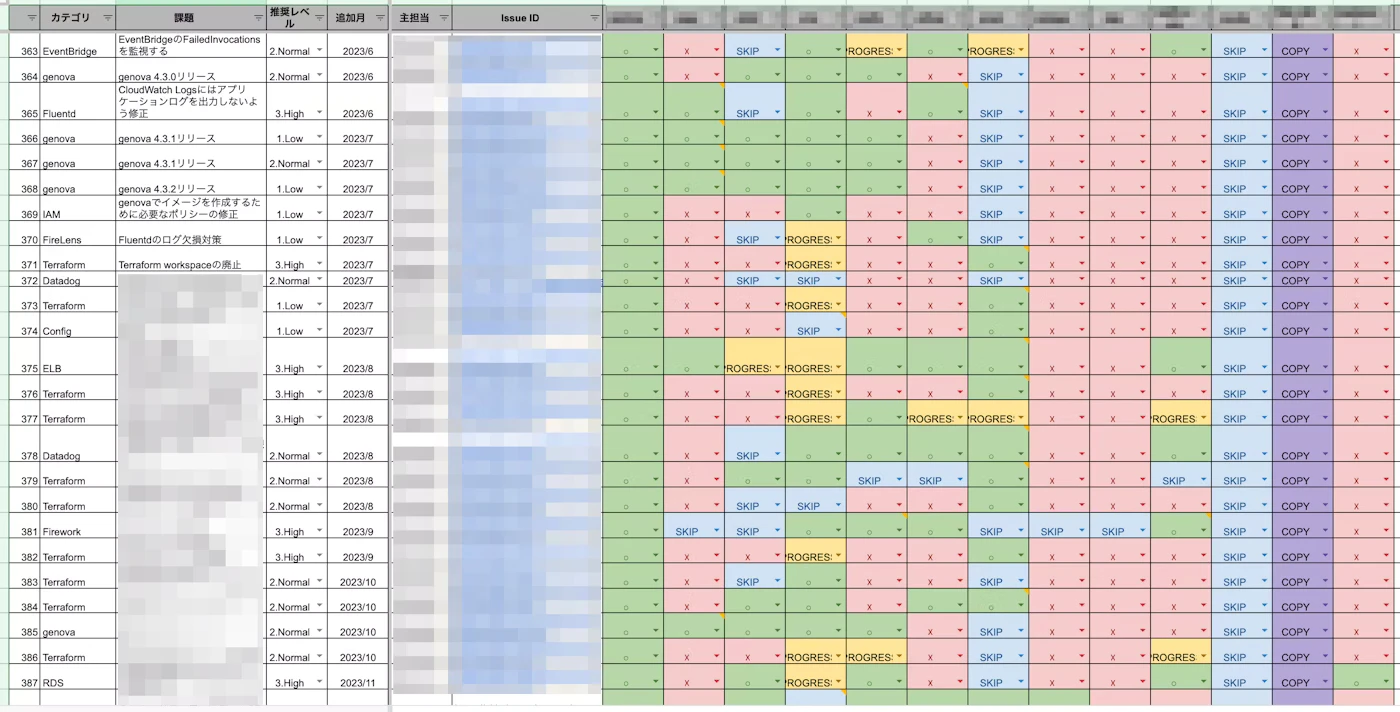
メタップスでは、こうした横断的なタスクを効率的に運用保守できるよう、インフラ構成を極力共通化し、全てのプロダクトに対してスムーズに変更を展開する仕組みを整えています。
さらに、共通となる変更内容はスプレッドシートで管理し、各プロダクトごとの対応状況を可視化する仕組みを導入しています。この仕組みによって、全体の進捗を把握しやすくなり、抜け漏れのリスクを最小化しています。
この取り組みは、SRE 組織立ち上げ当初から続けられており、累計で 450 件を超えるアップデートを横展開してきました。この継続的な改善プロセスにより、全体的なインフラの信頼性と保守性を大幅に向上させています。
議論と意思決定のプロセス
クラウド技術は日々進化し、新しいサービスや仕組みが次々と登場しています。しかし、無闇矢鱈に新技術に飛びつくのではなく、導入することでプロダクトにどのような恩恵があるか、また横断的に展開すべきかどうかを慎重に検討することが重要です。
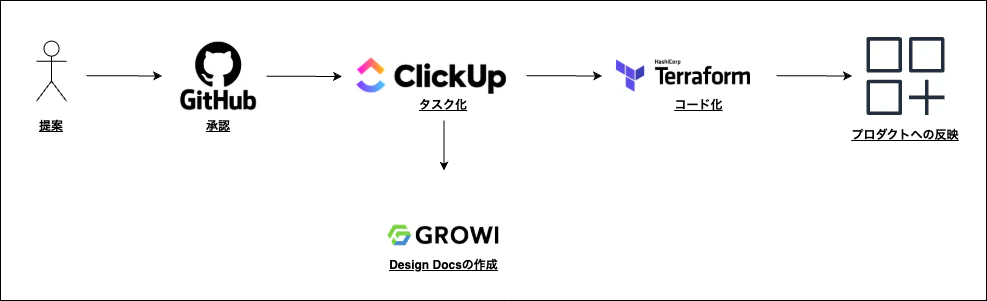
新しい仕組みを導入する際、メタップスでは GitHub Discussions を活用して提案を行うことから始めます。
提案の内容が具体化し、SRE チームやプロダクトチームから一定の評価を得られた場合には、タスクとして明確に落とし込みます。さらに、プロダクトや運用全体に影響を与える大きな変更の場合は、Design Docs を作成し、詳細な検討を経て合意形成を図ります。
これにより、議論を通じてチーム内で透明性と共通理解を確保しながら、新しい仕組みの導入を効果的かつ適切に進める仕組みを整えています。
インシデント対応
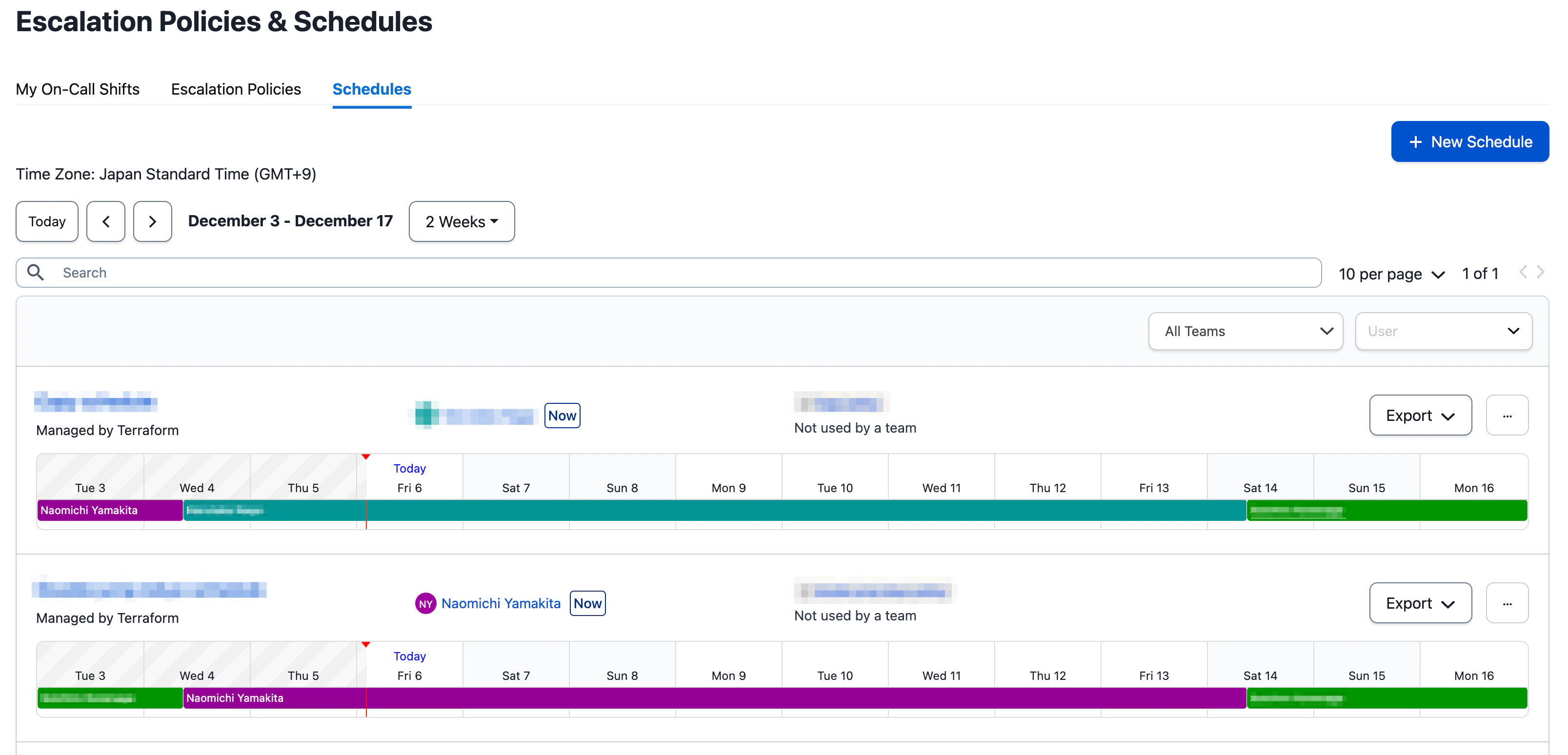
オンコール対応には、Datadog と PagerDuty を組み合わせて利用しています。Datadog ではモニタールールごとに Priority を設定しており、特定の Priority にマッチするイベントを PagerDuty に連携する仕組みを構築しています。この設定により、重要度に応じたオンコール対応を効率的に行います。
また、PagerDuty はプロダクトやグループごとにオンコールシフトを柔軟に組むことができるため、SRE チームは全員がオンコールに参加しています。この体制により、チーム全体で責任を分担しながら、迅速な対応を可能にしています。
また、現在のオンコール体制では、アプリケーションレベルの問題 (HTTP 5XX) についても SRE が一次対応を行っています。しかし、アプリケーションの問題はドメイン知識を要するケースが多く、開発者が直接確認したほうが迅速かつ的確に対応できる場合が少なくありません。そのため、開発者を含めた新しいオンコール体制の構築が課題となっています。
プレイブック
SRE チームではアラートが発生した際に調査結果を調査ログとして詳細に記録しています。これらの調査ログはプレイブック 6 の形式で整理され、問題発生時の対応手順や原因究明のプロセス、再発防止のための知見がまとめられています。
SRE チームはこれらのプレイブックを Amazon Bedrock に学習させる取り組みも進めており、障害発生時には過去のプレイブックの内容を AI が自動的に提案する仕組みを構築しています。
この仕組みにより、障害対応の迅速化やナレッジの活用がさらに促進され、チーム全体の信頼性向上に貢献しています。

ポストモーテム
システムで発生した障害はポストモーテムとして詳細に記録し、後日開発メンバーを含めて共有する体制を整えています。これは原因究明、再発防止策の策定、知見の共有を目的としています。
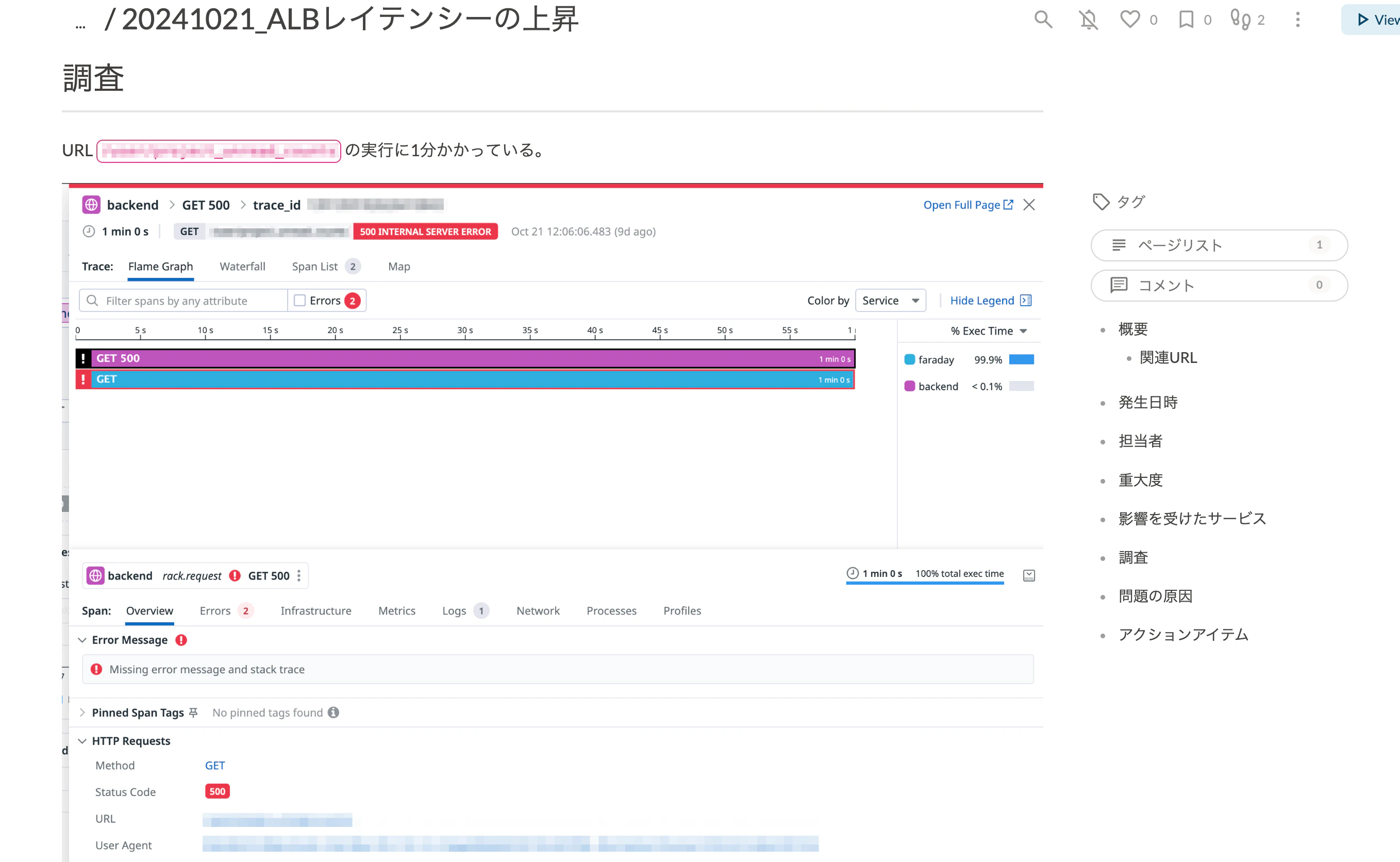
以下は社内で使用しているポストモーテムのテンプレートです。
# 概要
<!-- 何が起きたのか、何を調査するのか。 発生した問題の概要を簡潔に記載する。 -->
## 関連URL
<!-- SlackやDatadogアラートのURL、過去に発生した関連インシデントなど。 -->
# 発生日時
<!--
* 調査対象の問題が発生した日時 (2021/8/1 13:00-14:00など)。
* 複数の日時で発生している場合はリスト化する。
-->
# 担当者
* SRE: <!-- 担当者のメンバーリスト -->
* 開発: <!-- 担当者のメンバーリスト -->
* フォローアップ: <!-- 担当者のメンバーリスト -->
# 重大度
<!-- Low〜Criticalで定義。 -->
# 影響を受けたプロダクト
<!-- 影響を受けたドメイン、プロダクト名など。 -->
# 調査
<!--
* どのような観点で、何を調査したかを時系列で記述する。
* 調査した内容が結果的に問題に紐付いていない場合でも、調査ログとして記録を残す。
-->
# 問題の原因
<!-- 問題が発生した原因を完結に記載。 -->
# 教訓
<!-- うまくいったこと、うまくいかなかったこと、幸運だったこと。 -->
# アクションアイテム
<!-- 再発防止のためのアクションプランを策定。 -->
| アクションアイテム | 種類 | 優先度 | 担当 | 対応状況 |
| ----------------------------- | -------------------------- | ------------------ | ------------------------------------------ | ----------------------------------- |
| <!-- 再発防止策をタスク化。タスク管理URLがあればリンク。 --> | <!-- 修復・調査・再発防止・改善 --> | <!-- Low〜High --> | <!-- 開発orSREチーム、あるいは担当者名 --> | <!-- タスクが進行中か完了済みか --> |
テンプレート内のインシデントの「重要度」は次のような区分けとなっています。
| 重大度レベル | 説明 | 例 | ポストモーテムの実施 | 部門長の参加 |
|---|---|---|---|---|
| Low | ビジネスへの影響が発生しない | * 検証環境で発生した障害 | 不要 | 不要 |
| Middle | ビジネスに軽微な影響を与える | * 顧客向けプロダクトを一部のユーザーが短時間に渡り利用できない * 重要性の低い機能の一時的なダウン |
必須 | 任意 |
| High | ビジネスに深刻な影響を与える | * 顧客向けプロダクトを一部のユーザーが長時間に渡り使用できない * 重要性の高い機能の一時的なダウン |
必須 | 検討 |
| Critical | ビジネスに致命的な影響を与える | * 顧客向けプロダクトが長時間に渡りダウン * 顧客データの不整合や消失が発生 |
必須 | 必須 |
トイルの削減
SRE チームでは、運用効率化を目指し、トイル (繰り返し作業) の削減にも注力しています。トイルといえるものとしては、次のような作業が挙げられます。
| 役割 | 説明 | 主な利用するサービス |
|---|---|---|
| WAF で検知された攻撃元 IP アドレスの自動ブロック | 手動で対応していた作業を自動化し、迅速な対応と負担軽減を実現 | Lambda、WAF |
| RDS 監査ログの重要な変更内容を Slack に通知 | 管理者が即座に重要な変更を把握できる仕組みを構築 | Lambda、RDS、CloudWatch |
| システムメンテナンスページ表示の自動化 | 指定した時刻に ALB のターゲットグループにメンテナンスターゲットを追加 | Lambda、Step Functions、ALB |
これらの施策により、運用負荷を軽減するとともに、システムのセキュリティや運用の効率性を向上させています。
また、メタップスでは複数のプロダクトを横断して管理するために、Serverless Application Repository を活用した各プロダクトへのアプリケーション提供を行っています。
詳しいトイル削減の取り組みについては、以下の記事で紹介していますので、ぜひご覧ください。
ミーティング
SRE チームでは、全メンバーが参加する定例ミーティングを週次で開催しています。このミーティングは主に以下の 2 種類に分かれています。
-
進捗定例
各メンバーの進捗状況を共有し、タスクの優先順位や課題について確認します -
Deep Dive
各プロダクトで発生した障害や事例を詳細に共有し、ナレッジの共有や障害の再発防止策を検討する場です。また、AWS や Datadog の最新アップデートを共有し、自社プロダクトに取り入れるべきものを検討します
Deep Dive では、運用に関する善提案を GitHub Discussions に落とし込んだ上で議論を進め、ミーティング内で採択の可否を決定します。これにより、チーム全体での意思決定を迅速に行い、継続的な改善を図っています。
年間スケジュールの策定
SRE は日々の業務に加え、年間を通じて計画的に取り組むべき重要な業務があります。
例えば、弊社では以下のような業務を定期的に実施しています (一部抜粋)。
| 業務 | 概要 | 実施のタイミング |
|---|---|---|
| モニターしきい値の見直し | アラートの発生頻度を確認し、適切なしきい値に調整する。オーバースペックなリソースについてはサイズの見直しを検討する。 | 適宜状況を見て判断 |
| SaaS/PaaS の料金見直し | AWS (RI、SP)、Datadog、Sentry などの料金プランを確認し、コスト最適化を図る。 | 年1回 (契約単位) |
| 復旧テスト | 意図的にシステム障害を発生させ、ランブック 7 に基づいて適切な復旧が行われるかを検証する。 | 年1回 |
| アカウントの棚卸し | 各種サービスの権限を見直し、不要なアカウントや過剰な権限が残っていないかを確認する。 | 四半期に1回 |
| 脆弱性試験の実施 | 外部ベンダーに脆弱性診断を依頼し、セキュリティリスクを洗い出す。 | 年1回 |
| 不要な接続元 IP アドレスの洗い出し | インフラ・アプリケーションレベルで、不要な接続元の許可設定を確認して削除する。 | 年1回 |
| セキュリティトレーニング | 社内メンバーに対し、セキュリティインシデントやリスク回避のためのトレーニングを実施する。 | 年1回 |
教育と育成
SRE エンジニアは、アプリケーションとインフラの両方に精通した幅広い知識と経験が求められます。しかし、こうした高度なスキルを備えた SRE の採用は難しいため、最近では比較的若いエンジニアを採用し、社内での育成に力を入れています。
若手エンジニアの場合、開発経験が十分でないことも多いため、余剰時間を活用してプロダクト開発に携わり、アプリケーションの知識や課題について学ぶ機会を設けています。この実践を通じて、SRE として必要な視点を養い、スキルの幅を広げることを目指しています。
また、オンコール対応は特に経験則が重要となるため、初めのうちは経験豊富なメンバーと共にオンコールに参加し、テレカンを利用したハンズオン形式で対応の流れを学んでいます。
このような取り組みを通じて、若いエンジニアが SRE として成長できる環境を整え、チーム全体のスキル向上と継続的な成長を支えています。
総括
SRE 組織を立ち上げて 6 年、私たちは試行錯誤を繰り返しながら、少しずつ運用の形を磨いてきました。理想と現実の間で悩むことも多いですが、小さな改善の積み重ねが大きな成果に繋がることを実感しています。
この記事が、これから SRE を始める方や導入を考えている方にとって、ヒントや気づきになれば幸いです。