はじめに
Googleが提唱するSREプラクティスの一つにトイルの削減 1 があります。トイル (toil) という言葉は日本語であまりなじみがありませんが、「苦労する・こつこつ働く」といった意味合いがあります。
SREにおけるトイルの定義は、原典とも言える書籍 SRE サイトリライアビリティエンジニアリング 内で次のように定義されています。
トイルとは、プロダクションサービスを動作させることに関係する作業で、手作業で繰り返し行われ、自動化することが可能であり、戦術的で長期的な価値を持たず、作業量がサービスの成長に比例するといった傾向を持つものです。
本記事では、システム運用におけるトイルの定義を再確認し、トイルを削減する上での実践的なノウハウの一例を紹介します。
トイルの定義
SRE サイトリライアビリティエンジニアリング では、次の分類に1つ以上当てはまるような業務はトイルとなる性質が高いと紹介されています。
| 分類 | 説明 | 具体例 |
|---|---|---|
| 手作業であること | 何らかのタスクを自動化するスクリプトが手作業で実行されている。 | ディスク使用率のアラートが発生したら、エンジニアが対象サーバーにログインし、重要ではないファイルを探して削除する。 |
| 繰り返されること | 同じ作業を繰り返し行っている。 | 不要なファイルの削除作業をエンジニアが繰り返し行っている。 |
| 自動化できること | システムに置き換え可能なタスク (タスクの実行に人間の判断が必要であればトイルとは言えない)。 | 不要ファイルの削除スクリプトをエンジニアが実行している。 |
| 戦術的であること | 割り込み作業に対する自動化。 | ディスク使用率のアラートやサーバーダウンといったアラートに対し、エンジニアが都度調査・対応に当たっている。 |
| 長期的な価値を持たないこと | タスクを終えた後もサービスの状態が変わらない。 | アラート発生時にエンジニアが調査し、システムの動作に影響がないことを確認して作業を終了する (システム自体に改善の変化がない)。 |
| サービスの成長に対してO (n) であること | トラフィックやユーザー数に応じた自動化されたスケーリング。 | トラフィックに応じてアプリケーションやデータベースサーバーがオートスケールする。 |
トイルとして分類されるタスクはシステムを安定運用する上で必要性の高いタスクではありますが、必ずしも付加価値の高い作業であるとは限りません。そのため、一つひとつのトイルは小さいものの、トイルがたまるに連れ、原因不明のエラー調査に追われ、チームでは新たなスキルを学ぶ時間が取れない、達成感が得られないといった弊害をもたらす可能性もあります。
これらの問題に対し、GoogleのSRE組織では、SREが付加価値のないトイルに時間を取られないよう、トイルの削減を各人の50%以下のリソース配分とし、残りの時間はより付加価値の高いエンジニアリング作業 (アプリケーションの開発やインフラ構成のアップグレード、アラートの解消など) に費やしているようです。
SREの探求 では、トイルとエンジニアリング作業の特性として、次のような比較が紹介されています。
| トイル | エンジニアリング作業 |
|---|---|
| 永続的な価値がない | 永続的な価値を生み出す |
| 機械的な繰り返し | 創造的で反復可能 |
| 戦術的 | 戦略的 |
| スケールに伴って増加 | 適切なスケーリングが可能 |
| 自動化が可能 | 人間の創造性が必要 |
トイルの特定
まずはシステムにおけるトイルを洗い出してみます。誰が最もトイルを特定しやすい立場にいるかは組織にもよりますが、実際に作業するエンジニアを含めて検討すると良いでしょう。
メタップスでは毎週SREの進捗定例とは別に、SREチームを中心にDeep Diveを実施し、運用中のシステムに関わる課題やトイル、ポストモーテムを議論する場を設けています。
運用に関わるトピックはGitHub Discussionで話し合い、対応方針が定まったタスクはIssueに変換します。全てのDiscussionには1つ以上のラベルを付けており、そのうちの一つとして toil が存在します。
| ラベル名 | 説明 | 具体例 |
|---|---|---|
| enhance | 機能の改善 | GitHub ActionsのWorkflowはComposite actionとして提供する。 |
| cost | コストの削減 | GitHub Actionsのテストに時間がかるため、コンテナのベースイメージを作成する。 |
| security | セキュリティ運用の改善 | AWS Security HubでCIS AWS Foundations 1.4.0を有効化する。 |
| refactor | コードのリファクタリング | Terraformのディレクトリ構成を再設計する。 |
| toil | トイルの削減 | 不要なコンテナイメージを定期的に自動削除する。 |
トイルを特定したら、次にどのような改善策を取れるかメンバーと話し合い、優先度を付けて自動化への取り組みを始めると良いでしょう。
ケーススタディ 1: セキュリティパッチ適用の自動化
課題
ある組織では、Amazon EC2インスタンスへのセキュリティパッチ適用をSREエンジニアが手作業で行っていましたが、サーバー台数が増えるにつれエンジニアへの負担が高まり、パッチ適用漏れといったヒューマンエラーも発生しやすい状況となっています。
トイルか否か
エンジニアが手作業でコマンドの実行・動作結果の反復を行うことから、これはトイルと言えます。
解決策
AWS Systems Managerを使うことで、複数のEC2インスタンスに対し同じコマンドを実行できます。Amazon Linuxであれば、yum update –security コマンドでセキュリティパッチを適用します。
イベントの定期実行方法としては、例えばAmazon EventBridge + AWS Lambda経由で RunShellScript を起動し、コマンドの実行結果をSlackなどに通知するデザインが考えられます。
ケーススタディ2: HTTP 4XXsの調査
課題
あるシステムでは、Application Load Balancer (ALB) から不定期にHTTP 4XXsアラートが上がります。SREエンジニアであるあなたは、それが不正アクセスをブロックした結果か、クライアント側に起因する問題なのかを調査する必要があります。
トイルか否か
エンジニアが手作業で調査し、長期的な価値を持たない可能性があることから、トイルと言えます。
解決策
ALBのアクセスログはS3に保管されるため、一般的にはGlueでパーティショニングしたアクセスログに対し、Athenaから日付やHTTPステータスコードを条件にスキャンを実行します。
こうしたトラブルシューティングは日々発生しやすいタスクの一つですが、アラートをトリガーに調査プロセスを自動化することで、エンジニアの負担を軽減できる可能性があります。
アラート監視にDatadogを利用しているのであれば、Webhook -> API Gateway -> Lambda -> Athena (あるいはDatadog Workflowを利用してDatadogから直接Lambda実行) の流れで、アラートのサマリーをSlackなどに送ることができます。
トイルの測定
サイトリライアビリティワークブック では、トイル削減プロジェクトを開始する前に、コスト対メリットの分析を実施し、トイル撲滅によって節約される時間が自動化されたソリューションの開発コストに見合っているかどうかを評価し、エンジニアリングの投資に対するリターンを最大化するために問題の優先順位付けが必要と定義しています。
また、節約できる時間と投資できるリソースの比較から、一見利益がないように見えるプロジェクトも、間接的な価値を生み出す可能性があります。
- 割り込みによるコンテキストスイッチの減少 (アラート対応の自動化)
- セキュリティ対応の自動化
- ヒューマンエラーによる障害の減少
前述のケーススタディにおいては、HTTP 4XXsエラーがそこまで頻度高く発生していないのであれば、セキュリティパッチの自動化を優先して対応することで、運用コスト・セキュリティリスクの低減という恩恵を受けられます。
トイルの自動化
トイルを解決するにはツールの実装を必要とするため、SREにはSWE (ソフトウェアエンジニア) に近いプログラミングスキルが求められます。更にトイルを解決するには、ツールの実行基盤を構築しなければなりません。AWSを利用しているのであれば、EC2やFargate、Lambdaなどが候補に上げられるでしょう。
メタップスにおけるトイルは、比較的コンピューティングリソースを消費しないタスクが多いこともあり、運用の容易性も考慮した上で、Lambda + Serverless Framework2 を基盤としています。
Lambdaで実装したアプリケーションは Serverless Application Repository に公開し、アプリケーションを利用するAWSアカウントは、CloudFormation経由で必要なファンクションをデプロイする仕組みを構築しました。この仕組みはトイルを抱える複数のシステムに対し、運用自動化ツールを安定して供給できる基盤となります。
下図はアプリケーションを利用するAWSアカウント側の画面です。現在は全てのアプリケーションを限定したAWSアカウントに公開しているため、Private applicationとしてアプリケーションが列挙されていることが確認できます 3。
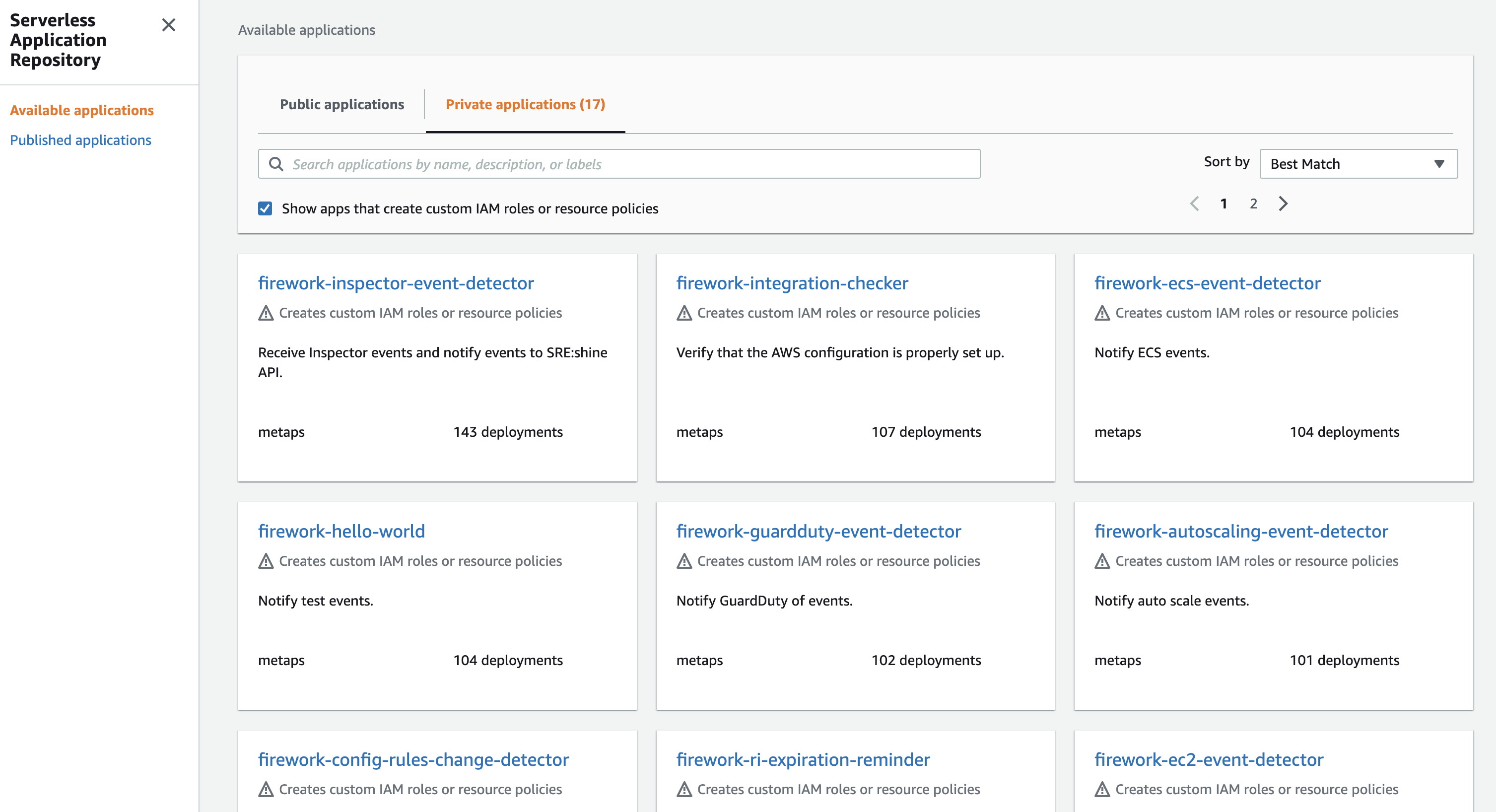
アプリケーションを選択し、セットアップ情報を登録することでデプロイが開始されます 4。
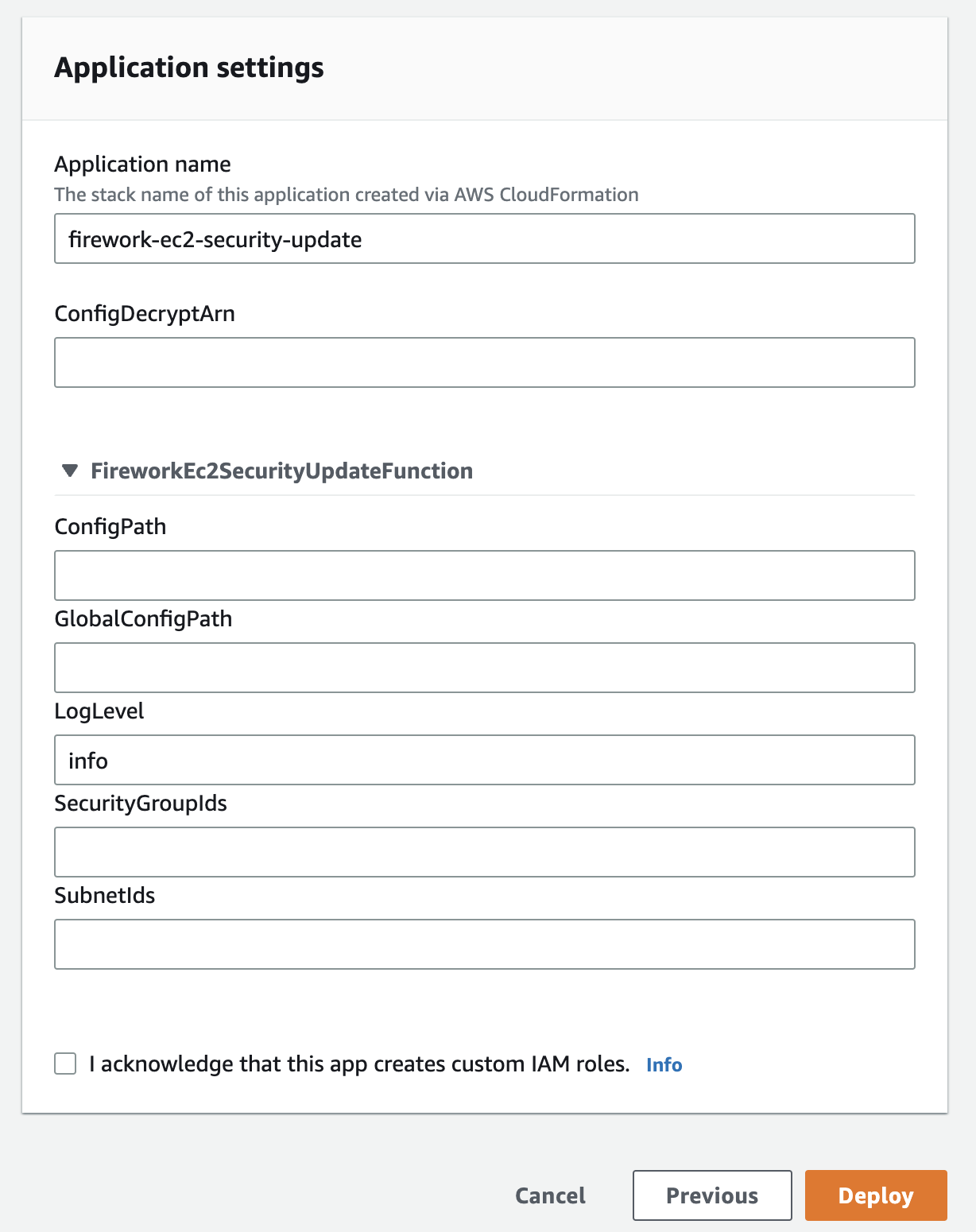
Lambdaアプリケーションの実装方法として、AWS SAM フレームワークを利用する手もありますが、開発当時はLambdaレイヤーを使ったLambdaファンクションのローカル実行が遅い問題 5 や、Serverless Framworkの過去の実績もあり、SAMの採用を見送っています。
なお、Serverless Application RepositoryはSAMテンプレートでアプリケーションを登録する必要があるため、Serverless Frameworkの構成ファイル serverless.yml からファンクション単位でSAMテンプレートを書き起こすプラグインを独自に実装して対応しました。
Serverless Application Repositoryからアプリケーションをデプロイすると、SAMテンプレートを元にCloudFormationのスタックが展開されます。アプリケーションによってはLambdaのほか、EventBridegeやSQSといったリソースも構築されます。
SAMテンプレートはCloudFormationの拡張仕様のため、CloudFormationを利用したことがあれば扱いは難しくありません。
メタップスで開発する自動化ツールはリソースの異常検知・自動修復のほか、AWSやDatadogの各種イベント・メトリクスデータをSREエンジニアが毎日チェックするプロダクト共通のダッシュボードに送信する機能も提供します。
このような仕組みを導入することで、SREエンジニアは多数のプロダクトの稼働状況をダッシュボードで一元管理できるようになりました 6。
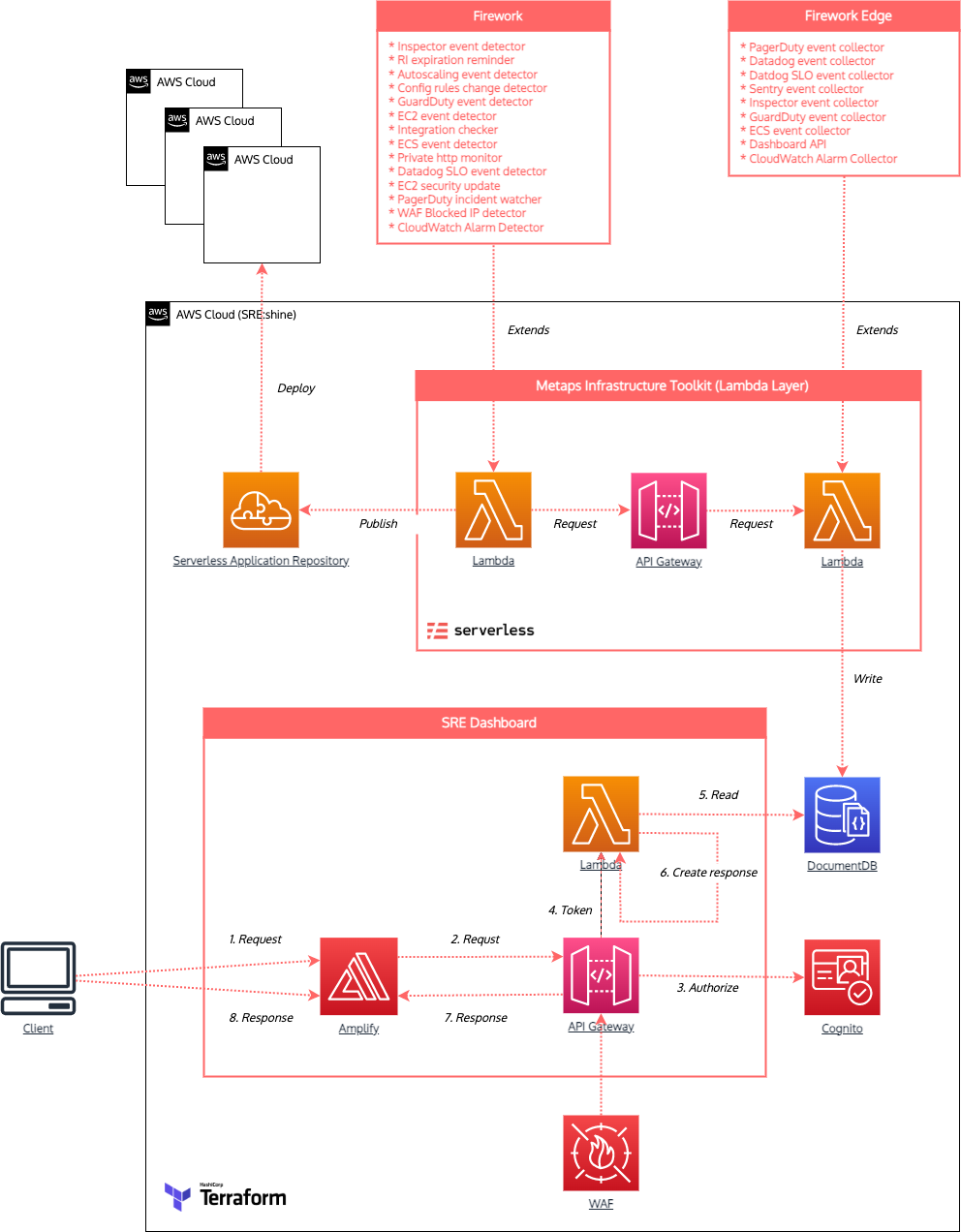
施策例
下表は直近1年で弊社が取り組んだトイル削減の一例となります。
| トイル | 今までの運用 | 改善後 |
|---|---|---|
| EC2インスタンスのセキュリティアップデート | SREが定期的に手動でセキュリティパッチを適用。 | Systems Managerを用いてパッチ運用を自動化。 |
| メンテナンスの自動化 | SREエンジニアがALBにメンテナンスページを表示するルールを追加。 | Step Functions + Lambdaを用いてメンテナンス切り替えを自動化。 |
| Opensearch Service上の古いインデックスの削除 | インデックスの蓄積によってディスクを圧迫することがあった。 | 古いインデックスを定期削除するLambdaファンクションを実装。 |
| Dependabotによるセキュリティパッチの適用 | SREが都度Pull Reqeustを確認して手動マージ。 | Composite actionを利用して、テストとマージを自動化 + 汎用化。 |
| Fargate異常タスクの強制終了 | スケジュール実行するタスクが稀に停止せず起動し続けるケースや、Run taskを誤ってサーバー起動し続け、コストが上がってしまう問題があった。 | スケジュールタスクやスタンドアロンタスクの起動が一定時間以上起動している場合は強制終了 (あるいはアラート通知)。 |
| ログの監視 | 不正アクセスを検知するため、エンジニアが毎月アクセスログレポートを作成していた。 | アクセスログのレポート生成・送信を自動化。 |
| CISから不正なAPIコールに関するアラートが通知される | CIS Benchmarkとして CIS AWS Foundations Controls を利用しているが、アラートの調査はエンジニアが都度行っていた。 | CloudTrailから対象時間帯の関連ログを通知する仕組みを実装。 |
| インフラ構築後の動作テスト | 新規サービス立ち上げに伴いインフラを構築する際は、環境構築後にテスト仕様書に従ってシステムの動作チェックを実施。 | 動作テストを自動化する仕組みを実装。定期実行されるため、機能改善に伴うデグレードも検知可能。 |
システムの運用を続けていく上ではトイルの根絶を目指すのではなく、手作業によるインシデントの発生抑止・チームのキャパシティ・運用コストといった観点から、実現可能なレベルで対応に取り掛かる必要があると言えるでしょう。