この記事は Metaps Advent Calendar 2023 10日目の記事となります。
概要
こんにちは。メタップスホールディングスのSREエンジニア @sre_yamakita です。
皆さんはre:Invent 2023で発表されたアップデートはご覧になりましたでしょうか 1。特に生成AI系のサービスで数多くの発表が行われた印象です。
今回はその中でも個人的に気になったベクトル検索について、プロトタイプ実装を交えて紹介したいと思います。
そもそもベクトル検索とは?
AWS Blog - Vector search for Amazon DocumentDB では次のように定義されています。
Vector search is an emerging technique used in machine learning (ML) to find similar data points to given data by comparing their vector representations using distance or similarity metrics. Vectors are numerical representation of unstructured data created from large language models (LLM) hosted in Amazon Bedrock, Amazon SageMaker, and other open source or proprietary ML services.
ベクトル検索は、機械学習(ML)において、距離や類似性のメトリクスを用いてベクトル表現を比較することで、与えられたデータに類似するデータ点を見つけるために使用される新しいテクニックである。ベクトルは、Amazon Bedrock、Amazon SageMaker、その他のオープンソースまたはプロプライエタリのMLサービスでホストされている大規模言語モデル(LLM)から作成された非構造化データの数値表現です。
何かを検索するとき、名前が分からなくても特徴や仕組みから検索することができますが、その基盤に使われる技術がベクトル検索です。
コンテンツはプレーンテキストではなくEmbeddingsされた数値として扱われるため、画像や音声といった非構造化データを扱うこともでき、類似性に基づく精度の高い回答が可能です。
AWSではAmazon BedrockというLLM基盤モデルサービスを提供しており、LLMに対し追加学習可能なFine tuningのほか、RAG (検索拡張生成) をサポートしています。
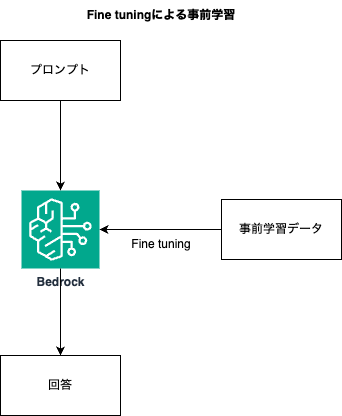
膨大な計算リソースが必要となるFine tuningと比較して、RAGはVector store (Amazon AuroraやAmazon RDS for PostgreSQL、Amazon OpenSearch Serviceなど) と連携することで、比較的簡単に生成AIアプリケーションを活用した開発が可能となります。
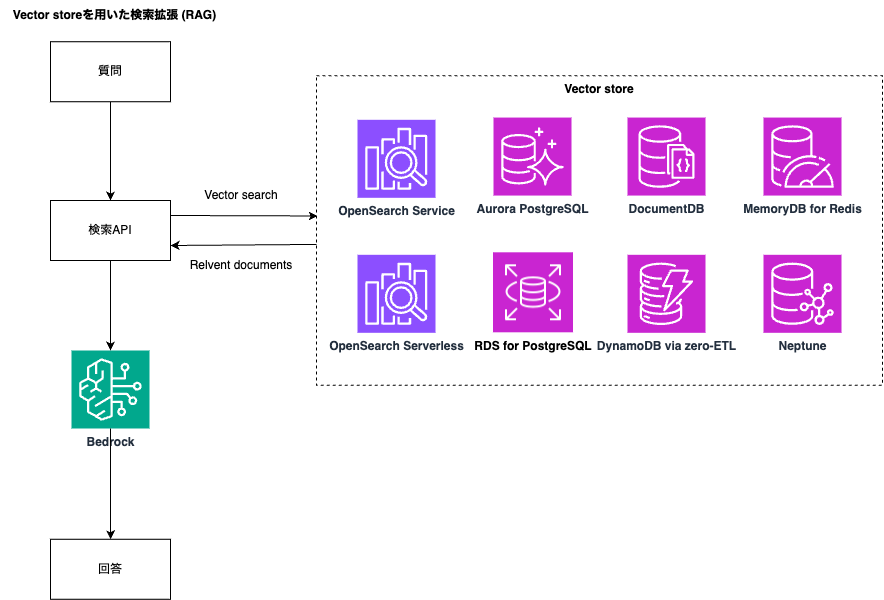
今回のre:Invent 2023では、Vector storeとして新たにAmazon DocumentDB、Amazon DynamoDBのサポートが発表されました。
SREチームの課題
弊社のSREチームは、開発チームから調査依頼が発生した際、必要に応じてプレイブックやランブックを作成しているのですが、インシデント発生時にオンコールメンバーが調査の当たりをつけるため、過去のナレッジから類似するドキュメントを提案するインターフェースを提供すればトラブルシューティングを迅速に行えるのではないかと考えました。
今回は AWS Blog を参考に、Vectore storeとしてDocumentDBを利用した次の構成で、インシデントに関連性の高いドキュメントを提案する仕組みを実装してみることにしました。
いか
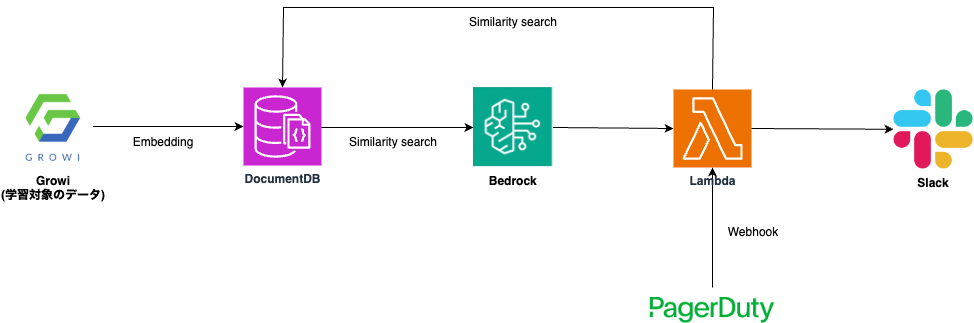
- ドキュメント管理にはGrowiを利用しているため、事前にGrowi API経由でプレイブック・ランブックをクロールし、EmbeddingsしたデータをDocumentDBに格納する仕組みが必要となります。
- インシデントのエスカレーションにはPagerDutyを利用しているため、Webhook経由でLambda Function URLを実行し、ペイロードに含まれるデータをEmbeddingsした上でDocumentDBでVector Matchingを実行。関連性の高いドキュメントをSlackに通知する仕組みを実装します。
このように、LLMの外部にある知識をVector Databaseに基づいてLLMから回答を生成する仕組みをRAG (Retrieval Augment Generation) と呼びます。
Embeddingsデータの格納
学習対象となるドキュメントをEmbeddingsした上でDocumentDB2 に格納するコードです。
手元の環境でRubyを使いましたが、言語はAWS SDKがサポートするものであれば何でも構いません。
今回、LLMにはBedrockが提供する Titan Embeddings G1 - Text モデルを使ってみました。
docdb_user = URI.encode_www_form_component(ENV['DOCDB_USER'])
docdb_password = URI.encode_www_form_component(ENV['DOCDB_PASSWORD'])
mongo = Mongo::Client.new(
"mongodb://#{docdb_user}:#{password}@#{ENV{'DOCDB_HOST']}:#{ENV['DOCDB_PORT']}/#{ENV['DOCDB_DB']}",
{
ssl: true,
ssl_ca_cert: 'rds-combined-ca-bundle.pem',
retry_writes: false
}
)
bedrock_runtime = Aws::BedrockRuntime::Client.new
response = bedrock_runtime.invoke_model(
body: JSON.generate(inputText: 'コンテンツデータ'),
model_id: 'amazon.titan-embed-text-v1',
accept: 'application/json',
content_type: 'application/json'
)
response_body = JSON.parse(response.body.read)
embedding = response_body['embedding']
playbook = mongo['playbook']
playbook.insert_one(
sentence: growi_page_id,
vectorField: embedding,
title: growi_title,
url: growi_url,
)
DocumentDBに接続すると、playbooks コレクションではEmbeddingsされた数値データが格納されていることが確認できます。
rs0:PRIMARY> db.playbooks.find({}).limit(1).pretty();
{
"_id" : ObjectId("656b5f811ca7bf20ba3a522e"),
"sentence" : "651505a3d19991d1a709ac8f",
"title" : "/SRE/プレイブック/reshine/xxxxxxxx_OpenSearchでunreachable master nodeが発生",
"url" : "xxx",
"vectorField" : [
0.4332549,
0.0018117264,
0.3374425,
-0.032563478,
...
インデックスを作成する
次にDocumentDBでベクトル検索を有効化するためのインデックスを作成します。
DocumentDBでは IVFFLAT と呼ばれるインデックスを使うことにより、LLMにおいて関連性の高いデータを効率的に検索する仕組みが提供されています。
similarity には類似度の計算方法に使用する距離メトリクスとして、euclidean、cosine、dotProduct が有効です 3。
rs0:PRIMARY> db.playbooks.createIndex (
{ vectorField: "vector" },
{ "name": "index_test",
"vectorOptions": {
"dimensions": 1536,
"similarity": "euclidean",
"lists": 100
}
}
);
# レスポンスの例
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1,
"operationTime" : Timestamp(1701436711, 1)
}
ベクトル検索の実装
最後にLambdaを用いたベクトル検索を実装します。
PagerDutyはWebhook経由でLambda関数をリクエストする際、ペイロードにインシデントのサマリーを含みます。サマリーは ALB target HTTP 5xx on loadbalancer:app/xxx といった文字列です。この文字列をベクトルデータに変換した上で、DocumentDBから類似性の高いデータを返す形です。
def transform_to_vector(question)
bedrock_runtime = Aws::BedrockRuntime::Client.new
response = bedrock_runtime.invoke_model(
body: JSON.generate(inputText: question),
model_id: 'amazon.titan-embed-text-v1',
accept: 'application/json',
content_type: 'application/json'
)
response_body = Oj.load(response.body.read, symbol_keys: true)
response_body[:embedding]
end
def vector_search(embedding)
docdb_user = URI.encode_www_form_component(ENV['DOCDB_USER'])
docdb_password = URI.encode_www_form_component(ENV['DOCDB_PASSWORD'])
mongo = Mongo::Client.new(
"mongodb://#{docdb_user}:#{docdb_password}@#{ENV['DOCDB_HOST']}:#{ENV['DOCDB_PORT']}/#{ENV['DOCDB_DB']}",
{
ssl: true,
ssl_ca_cert: 'rds-combined-ca-bundle.pem',
retry_writes: false
}
)
aggregate_command = [
{
'$search' => {
'vectorSearch' => {
'vector' => embedding,
'path' => 'vectorField',
'k' => 5,
'similarity' => 'euclidean',
'probes' => 1
}
}
}
]
playbooks = mongo['playbooks']
playbooks.aggregate(aggregate_command).to_a
end
def send_slack(service, summary, suggestions)
# 省略
end
def handler(event:, context:)
body = Oj.load(event['body'], symbol_keys: true)
service = body[:event][:data][:service][:summary]
summary = body[:event][:data][:title]
suggestions = []
results = vector_search(transform_to_vector(summary))
results.each do |result|
suggestions << result
end
send_slack(service, summary, suggestions)
{ result: 'success' }
end
テスト
インシデントを擬似的に発火させることで、過去に調査した類似性の高いプレイブックをSlackで提案することができました。
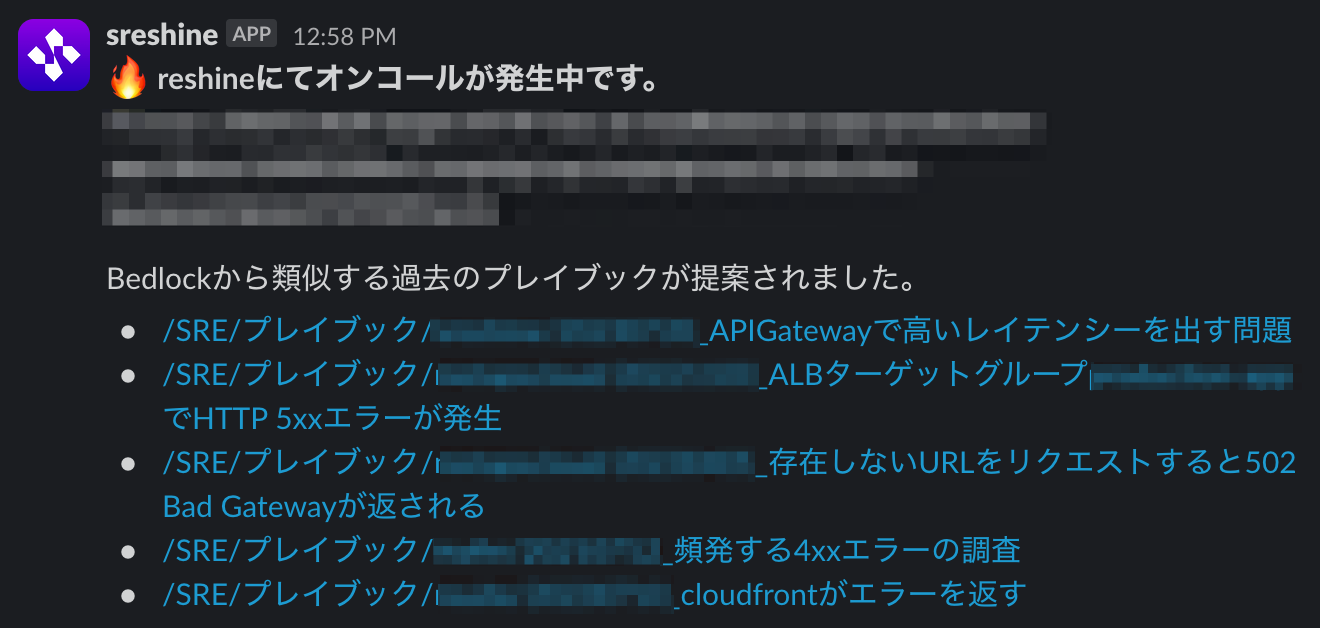
ベクトル検索を軽く検証した限り、インシデントのサマリーに類似する並びでドキュメントが返されることは確認できました。
精度についてはまだ詳しく調べていませんが、英語に翻訳した上でEmbeddingsしたほうが、より求めている回答に近い感じがします。
| 質問 | 提案されたプレイブックのタイトル (★は実際にAPI Gatewayに関連するドキュメント) |
|---|---|
| API Gatewayのレイテンシーが上昇しているのは何故ですか? | 1. API Gateway xxxでレイテンシーの上昇を検知 (★) 2. API Gateway: xxx-core 5xx (★) 3. ユーザー一覧ページのレイテンシーが上昇 4. 管理画面の外形監視が失敗 5. ALB target HTTP5xxエラーが多発 |
| Why is API Gateway latency increasing? | 1. API Gateway xxxでレイテンシーの上昇を検知 (★) 2. API Gatewayのレイテンシーが継続的に上昇 (★) 3. CloudFrontがHTTP 502エラーを返す (★) 4. HTTP 5xx on loadbalancer 5. API Gateway経由で実行されるLambdaのエラー調査方法 (★) |
このあたりはTranslateやComprehendといったサービスも組み合わせてチューニングを行うと、より精度が高まるのかもしれません。

今回の検証では、Bedrockを使うことで比較的簡単にRAGベースのアプリケーションが構築できることが分かりました。