主旨
強化学習アルゴリズムは多すぎて,結局どういう条件でどのアルゴリズムを使ったらよいかわからなかったので,調べてみました.
系図
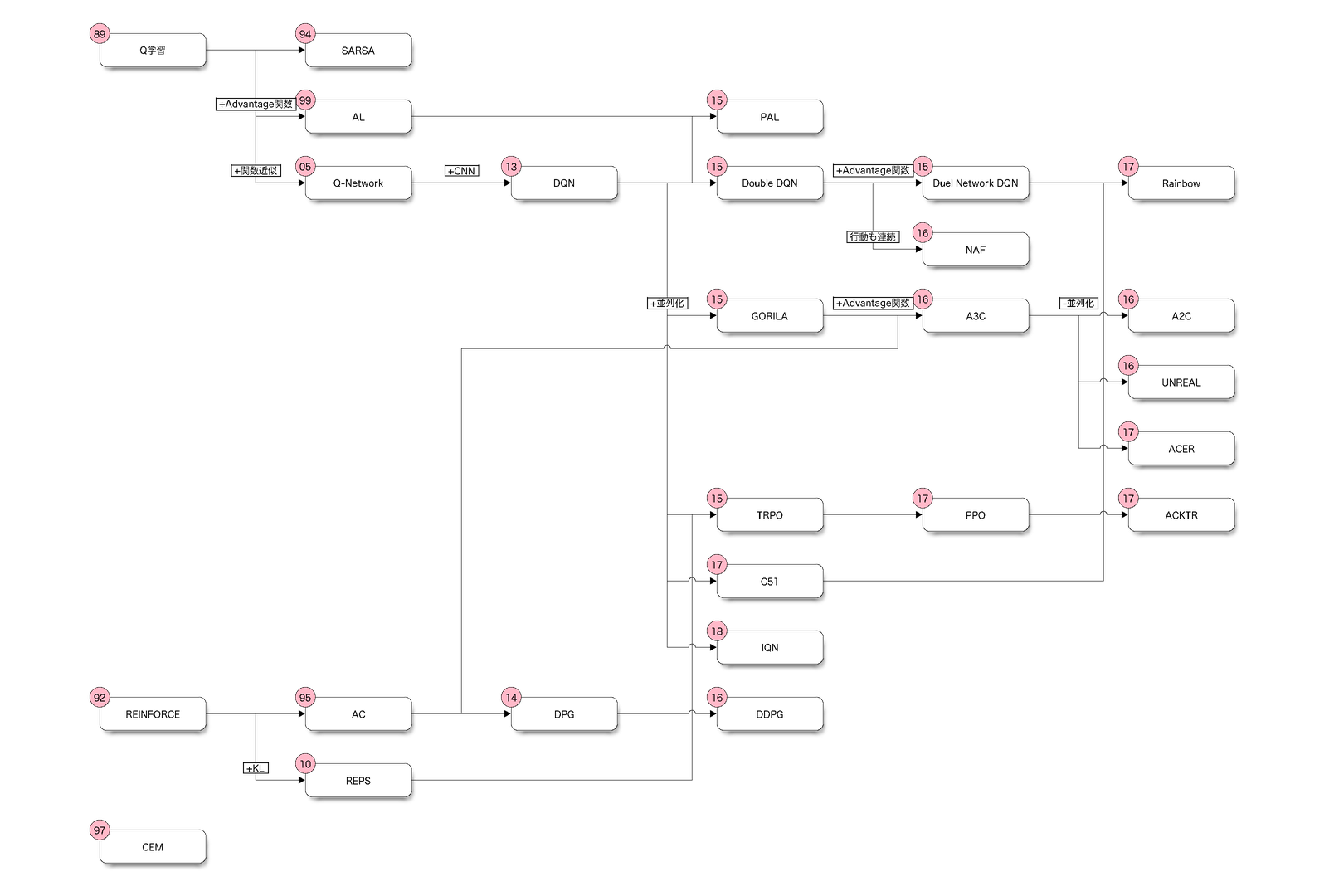
図: 主要なアルゴリズム(左上の数字は誕生年)
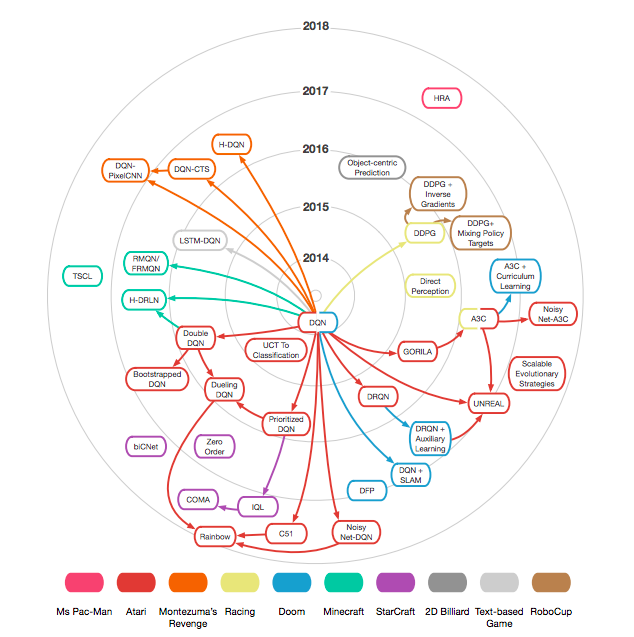
図: DQN誕生以降版(Deep Learning for Video Game Playingより引用)
アルゴリズムの選択基準
- 問題の空間(離散/連続)と手法,工夫によってアルゴリズム名が変わる.
- 手法は行動価値関数$Q(s,a)$を更新するために利用
| アルゴリズム | 状態空間 | 行動空間 |
|---|---|---|
| DQN | 離散/連続 | 離散 |
| DDPG | 離散/連続 | 連続 |
| NAF1 | 離散/連続 | 連続 |
| CEM | 離散/連続 | 離散 |
| Sarsa | 離散 | 離散 |
| Q学習 | 離散 | 離散 |
| Deep Sarsa | 離散/連続 | 離散 |
問題例
| 状態空間 | 行動空間 | 例 |
|---|---|---|
| 離散 | 離散 | 三目並べ, 迷路, テトリス, 囲碁 |
| 離散 | 連続 | ダーツ |
| 連続 | 離散 | 倒立振子 |
| 連続 | 連続 | ブロック崩し, インベーダー |
サンプルコード
OpenAI Gymの倒立振子は,
- 状態空間: 連続(座標と傾き)
- 行動空間: 離散(左 or 右)
なので,上記表よりDQNかCEM, Deep Sarsaで解けば良いことがわかります.
Keras-RLにあるCEMで解くサンプルです.
import gym
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten
from rl.agents.cem import CEMAgent
from rl.memory import EpisodeParameterMemory
env = gym.make("CartPole-v0")
nb_actions = env.action_space.n
model = Sequential()
model.add(Flatten(input_shape=(1,) + env.observation_space.shape))
model.add(Dense(nb_actions))
model.add(Activation('softmax'))
memory = EpisodeParameterMemory(limit=1000, window_length=1)
cem = CEMAgent(model=model, nb_actions=nb_actions, memory=memory,
batch_size=50, nb_steps_warmup=2000, train_interval=50, elite_frac=0.05)
cem.compile()
cem.fit(env, nb_steps=100000, visualize=False, verbose=1)
cem.test(env, nb_episodes=5, visualize=True)
References
DQN
- Playing Atari with Deep Reinforcement Learning, Mnih et al., 2013
- Human-level control through deep reinforcement learning, Mnih et al., 2015
- Deep Reinforcement Learning with Double Q-learning, van Hasselt et al., 2015
- Dueling Network Architectures for Deep Reinforcement Learning, Wang et al., 2016
- [Survey]Playing Atari with Deep Reinforcement Learning, Fujita, 2014
- [Survey]深層強化学習の動向 / survey of deep reinforcement learning, Seno et al., 2017
DDPG(Deep Deterministic Policy Gradient)
- Deterministic Policy Gradient Algorithms, Silver et al., 2014
- Continuous control with deep reinforcement learning, Lillicrap et al., 2015
NAF(Normalized Advantage Functions)
- Continuous Deep Q-Learning with Model-based Acceleration, Gu et al., 2016
- [Survey][DL輪読会]Continuous Deep Q-Learning with Model-based Acceleration, 2017
CEM(Cross-Entropy Method)
- Learning Tetris Using the Noisy Cross-Entropy Method, Szita et al., 2006
- Deep Reinforcement Learning (MLSS lecture notes), Schulman, 2016
Sarsa
- Reinforcement learning: An introduction, Sutton and Barto, 2011
References
- これから強化学習を勉強する人のための「強化学習アルゴリズム・マップ」と、実装例まとめ
- 小川雄太郎. つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~. マイナビ出版, (2018).
- Justesen, Niels, et al. "Deep learning for video game playing." arXiv preprint arXiv:1708.07902 (2017).
- これからの強化学習, Makino et al., 2016.
- Keras-RL, matthiasplappert, 2016
- 連続な空間における強化学習, Kimura et al., 1999
補足
-
NAF: Normalized Advantage Functionの略称.DQNで行動空間が連続な問題を解くために用いられます. ↩