今Yahooの TensorFlowOnSparkはTensorFlow2.xを更新しました、さっさとSparkと Tensor Flowを連携しようと思います。
しかし、今僕はDatabricksを使っていてOnline環境になっています、オフィシャルガイドは全部ローカル環境です。ちょっと1時間くらいをやってみたらやっとmnist_data_setup.py を成功に動かしました。
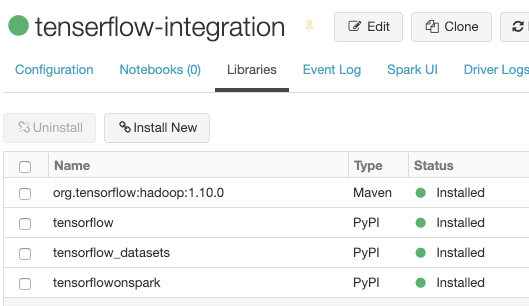
1、必要なライブラリー
PyPIで下記のライブラリーをインストールする
tensorflow ーーーーTensorFlowを使うため
tensorflow_datasets ーーーーMNISTを使うため
tensorflowonspark ーーーーSparkとTensorFlowを連携のため
この三つのパッケージをインストールしたけど、ずっとjava.lang.ClassNotFoundException: org.tensorflow.hadoop.io.TFRecordFileOutputFormatというエラーを報告しました、調査した結果は、下記のパッケージをインスロールしたら正しくファイルを書けます。ここはちょっと時間をかかりました。
Mavenで下記のライブラリーをインストールする
org.tensorflow:hadoop
Databricksでパッケージをインストールするには「Clusters -> Libraries -> Install New」で
最後のイメージ
2、ソースコード
GitHubでmnist_data_setup.pyをコーピしてDatabricksの Notebookにペーストしてください。下記のように要らないコードとエラーになるコードをコメントと修正して動かせます。
import argparse
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
import tensorflow as tf
import tensorflow_datasets as tfds
parser = argparse.ArgumentParser()
# parser.add_argument("--num_partitions", help="Number of output partitions", type=int, default=10) # コメントする部分
# parser.add_argument("--output", help="HDFS directory to save examples in parallelized format", default="/tenserflow-on-spark/data/mnist") #
# args = parser.parse_args() # コメントする部分
# print("args:", args) # コメントする部分
output = '/tenserflow-on-spark/data/mnist' # 追加する部分
# sc = SparkContext(conf=SparkConf().setAppName("mnist_data_setup"))# コメントする部分
mnist, info = tfds.load('mnist', with_info=True)
print(info.as_json)
# convert to numpy, then RDDs
mnist_train = tfds.as_numpy(mnist['train'])
mnist_test = tfds.as_numpy(mnist['test'])
# train_rdd = sc.parallelize(mnist_train, args.num_partitions).cache()# コメントする部分
# test_rdd = sc.parallelize(mnist_test, args.num_partitions).cache()# コメントする部分
train_rdd = sc.parallelize(mnist_train).cache() # 修正する部分
test_rdd = sc.parallelize(mnist_test).cache() # 修正する部分
# save as CSV (label,comma-separated-features)
def to_csv(example):
return str(example['label']) + ',' + ','.join([str(i) for i in example['image'].reshape(784)])
train_rdd.map(to_csv).saveAsTextFile(output + "/csv/train") # 修正する部分
test_rdd.map(to_csv).saveAsTextFile(output + "/csv/test") # 修正する部分
# save as TFRecords (numpy vs. PNG)
# note: the MNIST tensorflow_dataset is already provided as TFRecords but with a PNG bytes_list
# this export format is less-efficient, but easier to work with later
def to_tfr(example):
ex = tf.train.Example(
features=tf.train.Features(
feature={
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[example['label'].astype("int64")])),
'image': tf.train.Feature(int64_list=tf.train.Int64List(value=example['image'].reshape(784).astype("int64")))
}
)
)
return (bytearray(ex.SerializeToString()), None)
train_rdd.map(to_tfr).saveAsNewAPIHadoopFile(output + "/tfr/train", # 修正する部分
"org.tensorflow.hadoop.io.TFRecordFileOutputFormat",
keyClass="org.apache.hadoop.io.BytesWritable",
valueClass="org.apache.hadoop.io.NullWritable")
test_rdd.map(to_tfr).saveAsNewAPIHadoopFile(output + "/tfr/test", # 修正する部分
"org.tensorflow.hadoop.io.TFRecordFileOutputFormat",
keyClass="org.apache.hadoop.io.BytesWritable",
valueClass="org.apache.hadoop.io.NullWritable")
以上で、基本的なSparkとTensorFlowを動かせる環境を構築できました。