どんな記事?
深層学習のモデリングであれやこれや試してみたいけど、どうやって実装したらいいかわからん人向けに
割と自由度が高く、程よく抽象化されている枠組みとしてのkerasのfunctional APIを使って
sequentialでは難しいseq2seqをなるべくシンプルに実装してみる
目次
この記事のモチベーション
kerasを使えば深層学習の実装ができることはわかる。
深層学習には前処理ってのがいるのはわかる。
じゃあどうすればkerasの深層学習機能を使える形式にデータを変換できるの?
という疑問にお答えするのが主です。
前処理で必要なこと
開始・終了トークンの付与
翻訳モデルが文の冒頭の単語を推定する際に、仮想的な単語である開始トークン<start>を入力として取ります。
同様に、次の単語が終了トークンであることを翻訳モデルが推定した場合、そこで文を終了できるよう終了トークン<end>を付与しておきます。
単語列の数値化
機械学習モデルに入力するためにはロードしてきた文字列データを何らかの方法で数値化する必要があります。
Bag of wordsとか、各単語のone-hot encodingなんかが有名な手法ですね。
今回はkerasのEmbeddingレイヤーをネットワークの序盤で使いたいので単語に単語IDを割り振り、単語IDの列に変換します。
Embeddingレイヤー
https://keras.io/ja/layers/embeddings/
単語列長の統一
可能なら、単語列の長さをデータセット内で統一しておくと、後段のLSTMへの入力が簡単になります。
今回は単語列の長さをデータセット内の最大長に合わせるように0埋めで調整しています。
teacher forcingのための加工
seq2seqモデルの学習時のテクニックとしてteacher forcingがあります。
本来、デコーダーは1つ前の単語の推定結果を使って次の単語を推定しますが
学習時は正解データが使えるので、1つ前の推定結果ではなく、1つ前の正解単語を使って次の単語を推定させます。
図にすると、以下のような流れですね
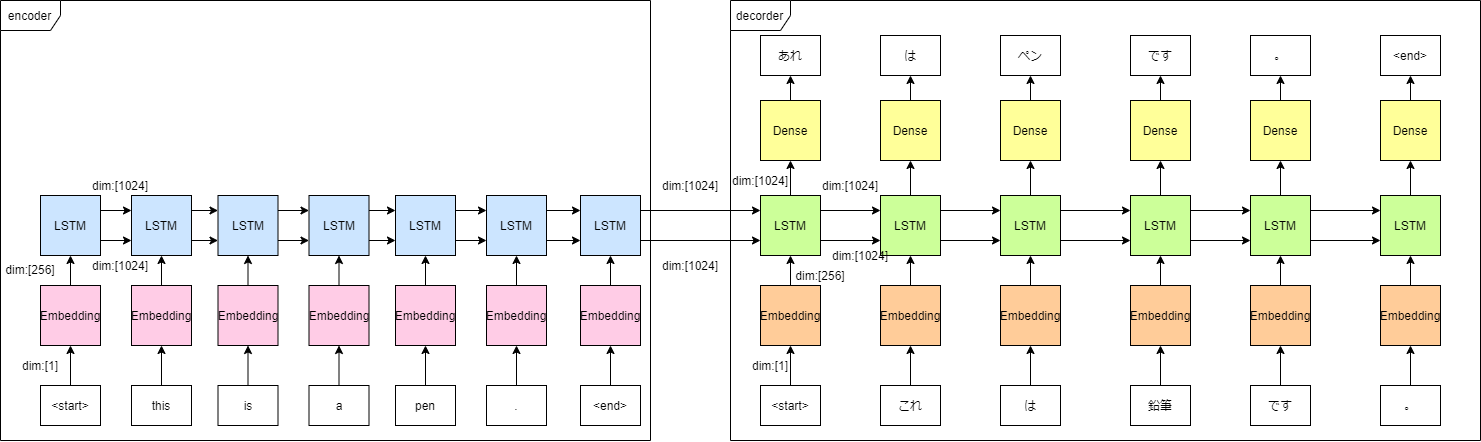
「あれ」と「これ」、「ペン」と「鉛筆」の推論が間違えていたとしても、次の入力は正解データに直してしまいます。
これを実現するため、targetとする単語列に対して1つだけ単語をずらした単語列をデコーダーの入力として用意しておきます。
例
推定対象が「これ は ペン です 。 <end>」の場合、
デコーダーの入力として「<start> これ は ペン です 。」という単語列を用意する
処理の流れまとめ
以上の流れをまとめるとこんな感じ。
- 開始と終了にそれぞれ<start>と <end>という特別な単語を付与し、文章の開始終了をモデルが判断できるようにする。
- 単語を単語と一対一対応するIDに変換する変換則を定義し、単語列を単語のID列に変換することにする。
- 単語列の長さはデータセット内の最大長に0埋めで合わせておく。
- デコーダーへの入力は、teacher forcingという学習テクニックを用いるため、デコーダー出力の正解データに対して位置をずらす
以上の処理を行うと、例えばこんな感じの変換が行われます
データセットの単語列
<start> i can 't tell who will arrive first . <end>
↓
単語IDの列
[2, 6, 42, 20, 151, 137, 30, 727, 234, 4, 3, 0, 0, 0, 0, 0, 0 ,0] (18要素)
前処理の実装
開始・終了トークンの付与
次の2つの関数を定義し、データセットから各行ごとにデータを読み込み、開始・終了トークンを付与します
def preprocess_sentence(w):
w = w.rstrip().strip()
# 文の開始と終了のトークンを付加
# モデルが予測をいつ開始し、いつ終了すれば良いかを知らせるため
w = '<start> ' + w + ' <end>'
return w
def create_dataset(path, num_examples):
with open(path) as f:
word_pairs = f.readlines()
word_pairs = [preprocess_sentence(sentence) for sentence in word_pairs]
return word_pairs[:num_examples]
preprocess_sentenceとか言ってる割に、開始終了トークンの付与しかしてないですね、あまり良くない関数の命名です。
create_datasetの中の変数がword_pairsになっているのも、参考にしたTensorFlowのサンプルコードのまんまだからです。
全然pairsじゃないです、num_examples個の開始・終了トークン付与済み単語列が返ります。
単語IDへの変換則を定義
単語IDの列に変換
ここはkerasのkeras.preprocessing.text.Tokenizerがとても便利で一息でいけちゃいます。
def tokenize(lang):
lang_tokenizer = keras.preprocessing.text.Tokenizer(filters='', oov_token='<unk>')
lang_tokenizer.fit_on_texts(lang)
tensor = lang_tokenizer.texts_to_sequences(lang)
tensor = keras.preprocessing.sequence.pad_sequences(tensor, padding='post')
return tensor, lang_tokenizer
fit_on_textsメソッドで入力した単語列のリストから単語と単語IDの変換則を決め、
texts_to_sequencesメソッドを使うと、入力した単語列のリストを単語ID列のリストに変換してくれます。
keras.preprocessing.sequence.pad_sequencesで0埋めもやっています。
teacher forcingのための加工
input_tensorを、前述の方法で処理した入力単語ID列
target_tensorを、前述の方法で処理した正解単語ID列として、以下のように加工します
encoder_input_tensor = input_tensor
decoder_input_tensor = target_tensor[:,:-1]
decoder_target_tensor = target_tensor[:,1:] #これでteacher forcingを実現
これでseq2seqモデルで使うデータが得られました。
次の記事でモデリングと学習を行います。
参考
前処理部分は下記
アテンションを用いたニューラル機械翻訳
https://www.tensorflow.org/tutorials/text/nmt_with_attention
学習・推論部分のコードのベースは下記
Sequence to sequence example in Keras (character-level).
https://keras.io/examples/lstm_seq2seq/
学習に使ったデータは下記
https://github.com/odashi/small_parallel_enja
本記事のコードが入ってるリポジトリ
https://github.com/nagiton/simple_NMT