はじめに
Qwen 3.6-35B-A3B が 4 月 16 日にリリースされました。前回の記事では EVO-X2 上で Qwen 3.5 vs Gemma 4 を比較し、昨日の記事では DGX Spark 上で Qwen 3.5 vs Qwen 3.6 を比較しました。
今回は Qwen 3.6 を EVO-X2 で試す のが目的ですが、HuggingFace Hub を眺めると量子化バリエーションが非常に多く、どれを選べばいいか悩みます。
- unsloth が UD-Q4_K_S / UD-Q4_K_M / UD-Q4_K_XL (Unsloth Dynamic 系) と MXFP4_MOE
- bartowski が素の Q4_K_S / Q4_K_M / Q4_K_L
- lmstudio-community, ggml-org, noctrex など多数
迷った挙句、代表的な 3 つを落として EVO-X2 で横並び比較することにしました。
- bartowski Q4_K_M — 素の Q4_K_M、前回記事の Qwen 3.5 と量子化を合わせる
- Unsloth UD-Q4_K_M — Unsloth Dynamic、SOTA 量子化を謳う
- Unsloth MXFP4_MOE — 昨日の DGX Spark 記事で使った量子化、プラットフォーム比較用
結論を先に書くと、EVO-X2 での常用に推すなら bartowski Q4_K_M。DGX Spark で最強だった MXFP4_MOE は、EVO-X2 Vulkan では用途を選ぶ構図でした。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | GMKtec EVO-X2 (AMD Ryzen AI Max+ 395, Radeon 8060S / gfx1151) |
| メモリ | 128 GB LPDDR5X (UMA), BIOS VGM 96 GB 設定 |
| OS | Ubuntu 25.10 (kernel 6.18.20) |
| llama.cpp | b8838 (Vulkan) |
| 比較用 (昨日) | DGX Spark (NVIDIA GB10) + llama.cpp b8672 CUDA |
前回記事では llama.cpp b8672 を使っていましたが、今回は Qwen 3.6 のリリースタイミングに合わせて b8838 に更新しました。b8672 と b8838 では Qwen 3.5 Q4_K_M の pp2048 が 730 → 624 に見えますが、これは測定ノイズの範囲 (b8672 で標準偏差 ±104 t/s あり、b8838 の 624 も区間 [574, 782] に含まれます)。
llama.cpp b8838 のビルド時の落とし穴
Ubuntu 25.10 上で普通に libvulkan-dev を入れてビルドすると、以下のエラーで止まります。
fatal error: spirv/unified1/spirv.hpp: No such file or directory
b8672 から b8838 の間のどこかで SPIR-V ヘッダ依存が追加されたようです。spirv-headers パッケージも入れる必要があります。
sudo apt install -y libvulkan-dev spirv-headers
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp && git checkout b8838
cmake -B build-vulkan-b8838 -DGGML_VULKAN=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build-vulkan-b8838 --config Release -j$(nproc)
モデルのダウンロード
python3 -m venv ~/venv-bench
source ~/venv-bench/bin/activate
pip install huggingface_hub datasets httpx
# Unsloth 系 (UD-Q4_K_M + MXFP4_MOE + mmproj)
hf download unsloth/Qwen3.6-35B-A3B-GGUF \
--include "*UD-Q4_K_M*.gguf" \
--include "*MXFP4_MOE*.gguf" \
--include "mmproj-F16.gguf" \
--local-dir ~/models/Qwen3.6-35B-A3B/
# bartowski の素 Q4_K_M
hf download bartowski/Qwen_Qwen3.6-35B-A3B-GGUF \
--include "Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf" \
--local-dir ~/models/Qwen3.6-35B-A3B/
unsloth のリポジトリには F16 と BF16 の両方の mmproj がありますが、gfx1151 は bf16 非対応 (bf16: 0) なので F16 を使います。
1. llama-bench: 基本速度
まずは純粋な推論速度から。前回記事と同じコマンドで計測しました。
llama-bench -m <model.gguf> -ngl 99 -fa 1 -mmp 0 -p 2048 -n 32 -ub 2048 -r 3
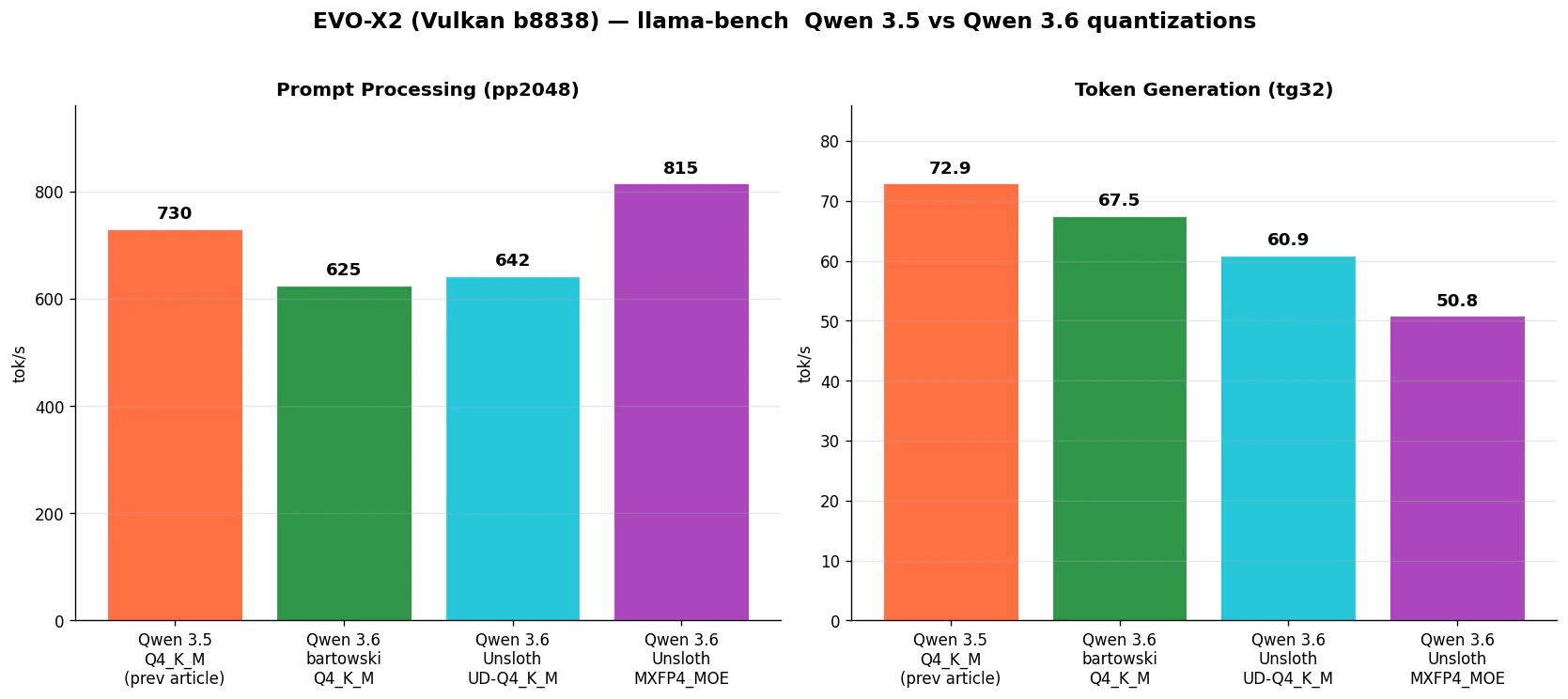
| モデル | サイズ | pp2048 (t/s) | tg32 (t/s) |
|---|---|---|---|
| Qwen 3.5 Q4_K_M (前回記事 / b8672) | 19.71 GiB | 730 | 72.9 |
| Qwen 3.6 bartowski Q4_K_M | 19.91 GiB | 625 | 67.5 |
| Qwen 3.6 Unsloth UD-Q4_K_M | 20.60 GiB | 642 | 60.9 |
| Qwen 3.6 Unsloth MXFP4_MOE | 20.21 GiB | 815 | 50.8 |
pp と tg の非対称
pp (Prompt Processing) は入力プロンプトを GPU で処理するフェーズで、tg (Token Generation) は 1 トークンずつ逐次生成するフェーズです。チャットの体感速度は tg が支配的、RAG や長文要約のように入力が大きい用途では pp が効いてきます。
この図で最も目を引くのは、MXFP4_MOE の pp が 815 t/s と突出 している一方で、tg は 50.8 t/s と最も遅い ことです。pp で +30%、tg で -25% と、同じモデルなのに真逆のポジションに来ています。DGX Spark では MXFP4 が pp/tg の両方で優位でしたが、EVO-X2 Vulkan ではこの非対称性が顕著に出ました。
bartowski Q4_K_M は tg が 67.5 t/s で最速、size も最小 (19.91 GiB) と、対話用途でバランスが良い構成です。
Qwen 3.5 → 3.6 の世代間差
Q4_K_M 同士で比較すると、pp はほぼ同じ (730 → 625 ですが前述の通り測定ノイズ範囲)、tg は 72.9 → 67.5 で -7% です。昨日の DGX Spark 記事では世代間差 ±0.5% でしたが、EVO-X2 では tg がわずかに遅くなりました。Qwen 3.6 の GDN:Attention = 3:1 構造において、Vulkan で CPU fallback となる Gated DeltaNet 層の比率が上がった影響と推測しています。
2. ロングコンテキスト: pp@512/4096/16384
昨日の DGX Spark 記事では、Qwen 3.6 の目玉として ロングコンテキストでの pp 劣化率の改善 が挙がっていました。EVO-X2 Vulkan ではどうでしょうか。
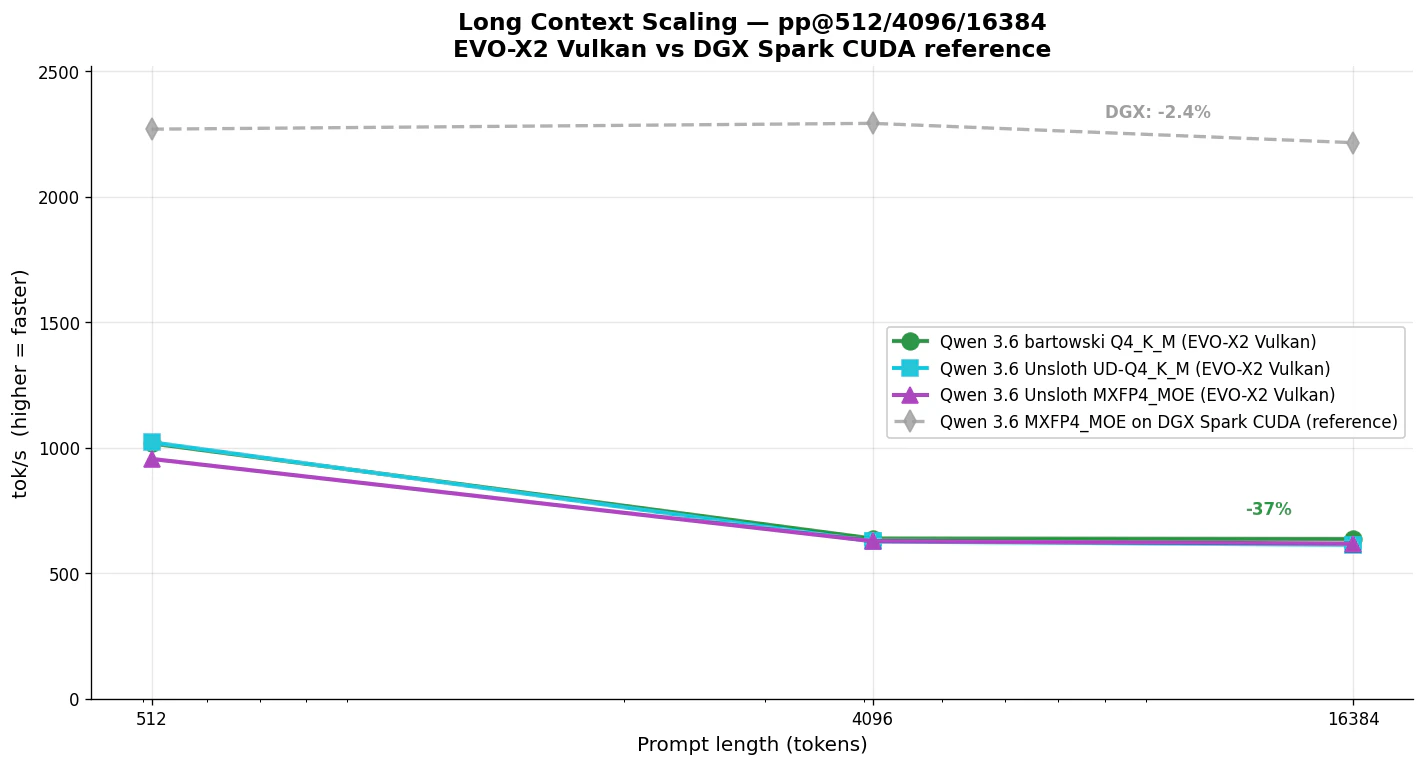
| モデル | pp512 | pp4096 | pp16384 | 劣化率 (512→16K) |
|---|---|---|---|---|
| Qwen 3.6 bartowski Q4_K_M | 1017 | 638 | 636 | -37% |
| Qwen 3.6 Unsloth UD-Q4_K_M | 1022 | 626 | 613 | -40% |
| Qwen 3.6 Unsloth MXFP4_MOE | 955 | 627 | 618 | -35% |
| (参考) DGX Spark CUDA MXFP4_MOE | 2268 | 2292 | 2215 | -2.4% |
DGX Spark は ほぼフラット (-2.4%) なのに対し、EVO-X2 Vulkan では -35〜-40% と大きく劣化 します。pp4096 以降はほぼ saturation しており、-ub 2048 の制約で 2048 を超える入力は複数バッチに分割される効率がそのまま出ていそうです。
昨日の記事の「Qwen 3.6 はロングコンテキストの劣化率が 2.6 倍改善」という嬉しい話は、EVO-X2 Vulkan には残念ながら当てはまりません。16K トークン級の長文 RAG を EVO-X2 で走らせるなら、pp は 600 t/s 台として設計しておくのが無難です。
原因は Vulkan の FLASH_ATTN_EXT のスケーリング、MoE batch 処理の効率、10/40 層ある Gated Attention の負荷など複合要因と思われます。llama.cpp Issue #21284 で gfx1151 特化の prefill 最適化が議論されており、これが上流に取り込まれれば状況が変わる可能性があります。
興味深いのは、pp512 では MXFP4_MOE (955) が Q4_K_M (1017) より遅い こと。llama-bench での pp2048 は MXFP4 が最速だったので、ubatch=2048 の batch 効率と相性があるようです。
3. JCommonsenseQA: 品質ベンチ (nothink)
日本語の常識推論能力を JCommonsenseQA v1.1 で評価しました。1,119 問の 5 択、3-shot プロンプトです。
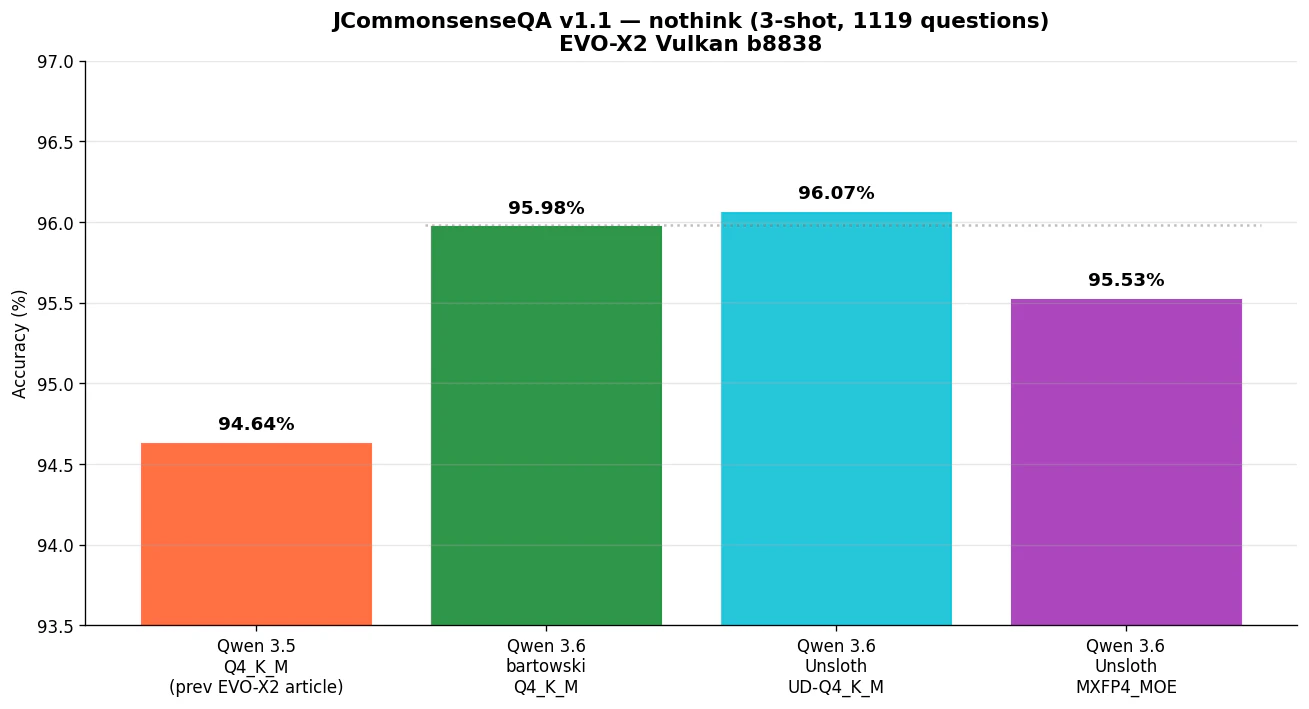
| モデル | 正解率 | Avg tok/s |
|---|---|---|
| Qwen 3.5 Q4_K_M (前回記事) | 94.64% | — |
| Qwen 3.6 bartowski Q4_K_M | 95.98% | 97.6 |
| Qwen 3.6 Unsloth UD-Q4_K_M | 96.07% | 88.9 |
| Qwen 3.6 Unsloth MXFP4_MOE | 95.53% | 86.8 |
世代間差: Qwen 3.5 → 3.6 で +1.34pt
これは素直に嬉しい改善。前回記事で Qwen 3.5 は Q4_K_M で 94.64% でしたが、Qwen 3.6 は 95.98% まで上がりました。DGX Spark の Qwen 3.6 MXFP4_MOE (95.98%) とも完全一致しており、モデルの品質はハードウェアや量子化に大きく依存しないことが確認できます。
3 量子化の差: 誤差範囲
Qwen 3.6 の 3 量子化は 95.53〜96.07% のバンドに収まっており、差は最大 6 問 (0.54pt) です。Unsloth UD の +0.09pt 優位は誤差範囲。UD は SOTA 量子化を謳っていますが、その代償として tok/s が 10% 落ちているので、EVO-X2 での対話用途では素の Q4_K_M を選ぶのが合理的です。
4. JCommonsenseQA: Thinking ON
前回 EVO-X2 記事では、Qwen 3.5 Q4_K_M の Thinking ON が -10.73pt と致命的に劣化していました。「考えさせると逆に間違える」のは、思考トークンで首尾一貫性を保てずに最初の直感からズレていく挙動と推測されていました。
Qwen 3.6 で同じ測定をすると、+0.89pt の改善 に一変しました。11.62pt の大逆転。しかも DGX Spark (+0.45pt) より改善幅が大きく、Thinking 品質に関しては EVO-X2 Q4_K_M が DGX Spark MXFP4_MOE を上回る 結果になりました (1〜2 問差なので統計的には誤差ですが、少なくとも負けてはいません)。
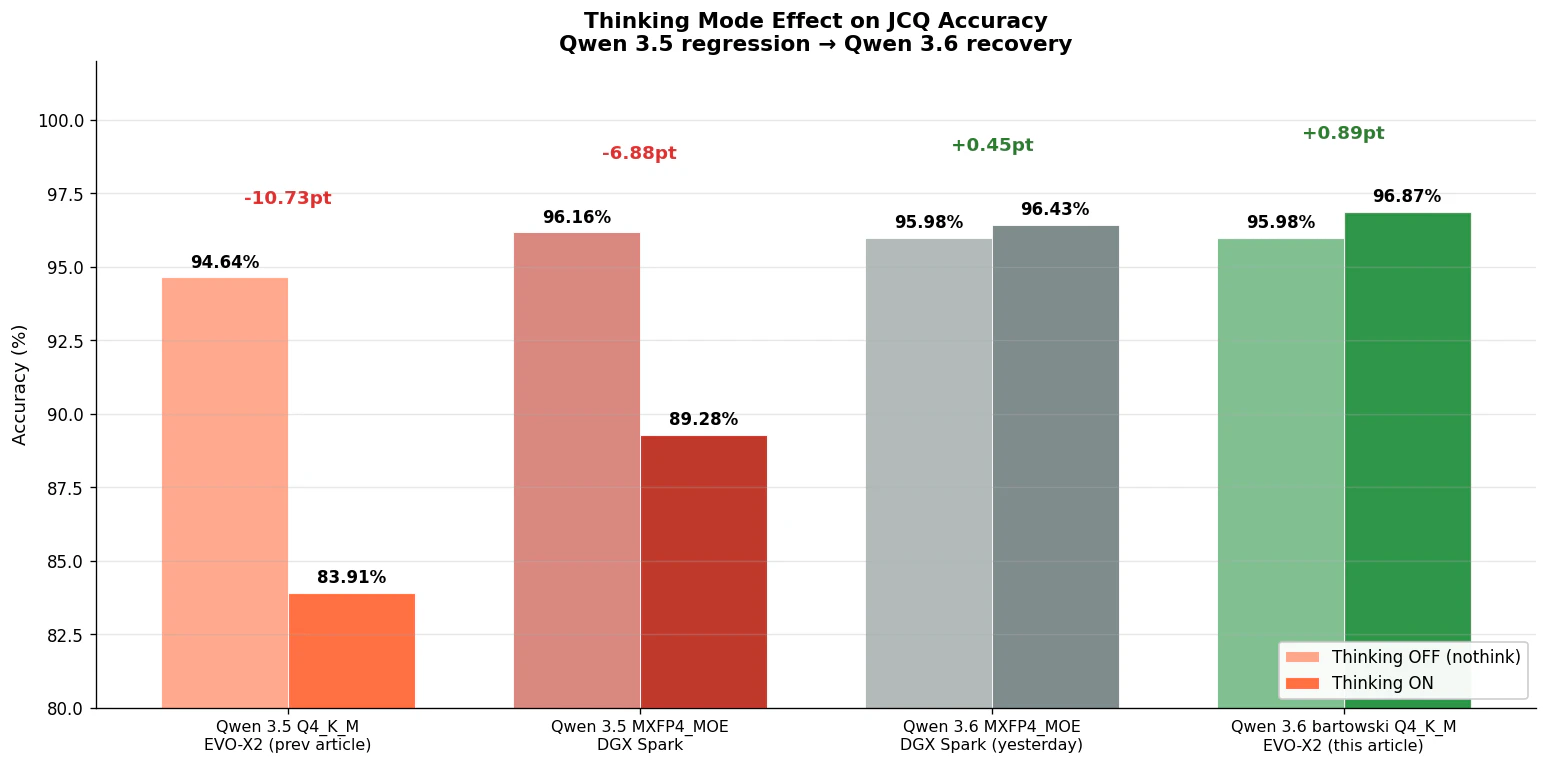
| モデル / 量子化 | 環境 | Thinking OFF | Thinking ON | 差分 |
|---|---|---|---|---|
| Qwen 3.5 Q4_K_M | EVO-X2 (前回記事) | 94.64% | 83.91% | -10.73pt |
| Qwen 3.5 MXFP4_MOE | DGX Spark | 96.16% | 89.28% | -6.88pt |
| Qwen 3.6 MXFP4_MOE | DGX Spark (昨日) | 95.98% | 96.43% | +0.45pt |
| Qwen 3.6 bartowski Q4_K_M | EVO-X2 (今回) | 95.98% | 96.87% | +0.89pt |
DGX Spark の記事で Thinking Preservation の効果が示されていましたが、量子化とハードウェアを問わずに効いている ことが EVO-X2 側の検証でも裏付けられた形です。
Gemma 4 Thinking ON 超え
前回記事の Gemma 4 Q4_K_M Thinking ON は 95.80% でした。今回の Qwen 3.6 bartowski Q4_K_M Thinking ON = 96.87% はこれを 1.07pt 上回っています。
前回記事の結論は「EVO-X2 では Gemma 4 が最良」でしたが、Thinking を常用する用途においては、Qwen 3.6 bartowski Q4_K_M が Gemma 4 を上回る という新しい選択肢が生まれました。
レイテンシ
Thinking ON では回答前に <think>...</think> タグ内で推論過程を生成するため、latency が大きく伸びます。
| モード | Avg latency | Avg tok/s |
|---|---|---|
| nothink (回答のみ) | 0.520s | 97.6 |
| think (思考 + 回答) | 9.169s | 65.2 |
レイテンシは 17.6 倍。tok/s が下がっているのは、VLM と同様で出力トークン量の増加 (数文字 → 400〜1000 トークン) によるものです。全 1,119 問で 約 3 時間 かかりました。
5. VLM マルチモーダル
Qwen 3.6 の VLM 機能を、EVO-X2 で実運用できるレベルで検証します。
起動方法
前回記事では llama-server を手動で起動していましたが、今回は systemd service 化しました。常用に近い構成になります。
# /etc/systemd/system/llama-server-q36-q4km.service
[Unit]
Description=llama-server Qwen3.6-35B-A3B bartowski Q4_K_M + Vision
After=network.target
Conflicts=llama-server-q6k.service llama-server-q4km.service
[Service]
Type=simple
User=nabe
ExecStart=/home/nabe/llama.cpp/build-vulkan-b8838/bin/llama-server \
-m /home/nabe/models/Qwen3.6-35B-A3B/Qwen_Qwen3.6-35B-A3B-Q4_K_M.gguf \
--mmproj /home/nabe/models/Qwen3.6-35B-A3B/mmproj-F16.gguf \
-ngl 99 -fa on --no-mmap \
-c 32768 -np 2 --port 8080 --host 0.0.0.0 \
--jinja --reasoning off --reasoning-budget 0
Restart=on-failure
[Install]
WantedBy=multi-user.target
Conflicts= で既存の日常運用 service (Qwen 3.5) と排他切替になるようにしています。3 量子化分の service を作っておけば、sudo systemctl start llama-server-q36-mxfp4 のように一発で切り替えられます。
セグフォ問題の確認
Unsloth の discussions/1 で、Qwen 3.6 の llama.cpp VLM が画像処理時に segmentation fault を起こすという報告がありました。昨日の DGX Spark 記事では「本環境では発生せず」でしたが、EVO-X2 Vulkan でも再現するか不安だったので、画像 1 枚で先に検証。
結果: 本環境でも segfault は発生しませんでした。bartowski Q4_K_M + mmproj-F16 の組み合わせ、UD-Q4_K_M、MXFP4_MOE のいずれも正常動作しています。
ベンチマークスクリプト
vlm_bench.py は OpenAI 互換 API 越しに画像をアップロードして 3 つのタスクを実行します。スクリプト本体は GitHub リポジトリ にあります。中核部分はこれだけ:
def call_vlm(client, api_url, model, image_path, prompt, max_tokens=1024):
b64 = image_to_base64(image_path)
mime = get_mime(image_path)
messages = [
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": f"data:{mime};base64,{b64}"}},
{"type": "text", "text": prompt}
]}
]
resp = client.post(api_url, json={
"model": model, "messages": messages,
"max_tokens": max_tokens, "temperature": 0.0,
})
return resp.json()
画像を base64 エンコードして image_url に埋め込み、テキストプロンプトと一緒に送るだけ。llama-server の /v1/chat/completions エンドポイントは mmproj を使って画像を読み取り、回答を生成します。
タスク 1: キャプション生成
プロンプト:
この画像を日本語で詳しく説明してください。場所、人物、物体、雰囲気などを含めてください。
5 枚のテスト画像で各モデルを走らせた結果:
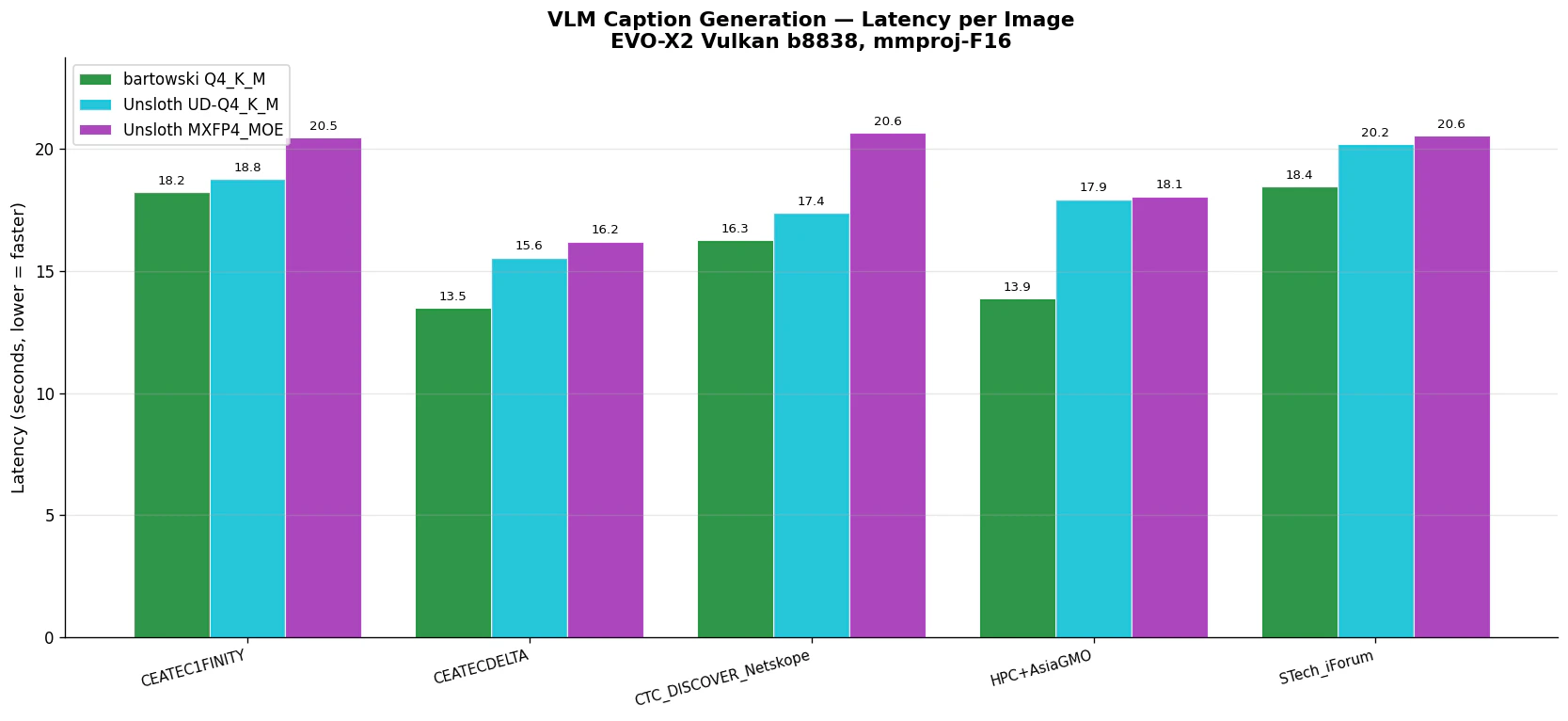
bartowski Q4_K_M が全画像で最速、MXFP4_MOE が最も遅い、という llama-bench の tg の順位がそのまま出ています。キャプションは 1,000 トークン以上の長い出力なので、tg の遅さがそのままレイテンシに響いています。
実際のキャプション (bartowski Q4_K_M の出力を抜粋)
展示会・カンファレンスの写真 5 枚で試しました。キャプションはいずれも 1,000 トークンを超える詳細な出力が得られています (全文は GitHub リポジトリの results/vlm_qwen36_bartowski_q4km.json にあります)。
| 画像 | キャプション抜粋 |
|---|---|
 |
1Finity 株式会社 の CEATEC 2025 ブースと正しく認識。「1FINITY T250 Hitless Protection Demo(無停止保護デモ)」という製品名を前面プレートから読み取り、黄色い光ファイバーケーブル が接続されてリアルタイムデモが行われていることまで把握。QR コードスタンドの「配布資料用 二次元バーコード」「※アンケートが御座います(所要時間1~2分程度)」という細かいテキストまで正確に引用。「DWDM Solution」のパンフレットにも言及。 (レイテンシ: 18.2s / 詳細な製品説明と技術的文脈を含む) |
 |
デルタ電子(DELTA) の「AI Containerized Datacenter(AIコンテナ型データセンター)」を正しく識別。サーバーラックの「Hot Aisle」という表示から冷却システムの設計を推測。「Delta Supports You All the Way」キャッチフレーズも読み取り。来場者の人数・服装・行動(「一人はバックパックを背負い、手に資料を持っている」)まで観察している。 (レイテンシ: 13.5s) |
 |
Netskope Japan 株式会社 のブースと認識。バナーの「SASE 市場を牽引する Netskope。セキュリティ強化で遅くなる?そんな常識、壊しました。」というキャッチコピーを正確に引用。左側のモニター画面(SONY 製)に映った Gemini の質問「Netskope の良いところについて教えてください」 まで読み取り、さらにその回答内容に「SASE(Secure Access Service Edge)の中核を担う統合型クラウドセキュリティプラットフォーム」という説明が含まれていると把握。右側ポスターのハッシュタグ「#こんな SASE/SSE は嫌だ」キャンペーンの趣旨まで読解。 (レイテンシ: 16.3s / この画像が最も情報量が多く、VLM の真価が出る例) |
 |
GMO INTERNET × NVIDIA の共同展示と認識。中央のアクリルケース内の「NVIDIA Blackwell Ultra GPU 搭載 NVIDIA HGX™ B300」という最新 AI プラットフォームを正しく同定。スタッフの制服(「GMO 1」と背中に書かれた黒シャツ)や、背景にチラッと見える「Lenovo」ブースまで検出。来場者層の分析(「ビジネスカジュアルからスーツまで、技術者・投資家・メディア関係者が混在」)も含む。 (レイテンシ: 13.9s) |
 |
「STech I Forum 2025」の落合陽一氏講演と認識。スクリーンに表示された 10 以上の肩書き(メディアアーティスト / 博士(学際情報学) / 筑波大学准教授 / デジタルネイチャー開発センター長 / ピクシーダストテクノロジーズ代表 / 万博シグネチャー事業プロデューサー...)を漏れなく列挙。「計算機と自然」「三次元視覚触覚ディスプレイ」「メタマテリアルと最適化」等のテーマキーワードも拾っている。右下の "Permanent Exhibition of Mirai-kan" という英文注釈まで読解。 (レイテンシ: 18.5s / 最大量の日本語テキスト読解タスク) |
Netskope 画像の読解力について
上記のうち、特に注目したのは Netskope のブース写真です。ブースの前に設置されたモニター画面上の Gemini の対話(日本語入力文と AI の回答)まで読み取れている のは正直驚きました。画像内の小さなブラウザ画面に表示されたテキストを、LLM が「これは Gemini の画面で、ユーザーがこう入力して、AI がこう答えている」と文脈で解釈できるレベルに達しています。
ローカル実行で、画像 1 枚から これだけの情報を日本語で構造化して返してくれるのは、かなり使えます。EVO-X2 レベルのコンパクトなハードウェアでここまで動くのは、以前では考えられませんでした。
タスク 2: JSON タグ抽出
プロンプト:
この画像から以下の情報をJSON形式で抽出してください:
- location: 場所
- event_type: イベントの種類
- subjects: 主要な被写体のリスト
- technologies: 技術やブランド名
- people_count: 人数
- atmosphere: 雰囲気
JSONのみを返してください。
このタスクでは JSON 形式の返答が正しくパースできるか が品質指標になります。
実出力例 (bartowski Q4_K_M, CEATEC での DELTA ブース画像)

{
"location": "展示会場(おそらく国際的な技術見本市)",
"event_type": "ビジネス展示会・製品発表会",
"subjects": [
"Delta社のAIコンテナ型データセンター",
"サーバーラックシステム",
"冷却システム(ホットアイル表示あり)"
],
"technologies": [
"Delta",
"AI Containerized Datacenter",
"Hot Aisle"
],
"people_count": 0,
"atmosphere": "プロフェッショナルでモダンな雰囲気。高性能ITインフラを展示する近未来的な空間"
}
3 モデルとも パース成功率 100%。構造化抽出の信頼性は量子化による差がないことが確認できました。Qwen 3.5 も 100% だったので、世代を超えて安定しています。
タスク 3: PPE (個人保護具) 検出
建設業や製造業向けの実用的なタスク。作業員のヘルメット・安全ベスト・安全メガネ・手袋などの装着状況を JSON で報告させます。
プロンプト:
この画像に写っている作業員の安全保護具(PPE)の着用状況を分析し、
以下のJSON形式で返してください:
{
"workers_count": 人数,
"ppe_items": [{...worker_id, hard_hat, safety_vest, ...}],
"compliance_score": "高/中/低",
"observations": "所見"
}
実出力例 (bartowski Q4_K_M, forklift_worker 画像)
{
"workers_count": 1,
"ppe_items": [{
"worker_id": 1,
"hard_hat": true,
"safety_vest": true,
"safety_glasses": false,
"gloves": true,
"safety_shoes": true,
"other": ["headphones", "earplugs (possible)"]
}],
"compliance_score": "中",
"observations": "作業員は基本的な保護具(ヘルメット、安全ベスト、手袋、安全靴)を着用しているが、安全メガネが確認できない。..."
}
各装備をブール値で返した上で、comp score を「中」と総合判定、さらに所見で「安全メガネが欠けている」という具体的な改善点を指摘しています。ヘッドホン着用にも言及しており、細部までよく観察できています。
3 モデルとも パース成功率 100%。この種の構造化タスクは 3 モデルのどれを選んでも安定運用できそうです。
VLM タスク総合まとめ
bartowski Q4_K_M が全タスクで最速か同等。MXFP4_MOE は Caption で 19.19s と最も遅くなりました。これは llama-bench の tg 速度がそのまま効いている構図です。JSON/PPE は出力トークン数が少ないので差が相対的に小さくなっています。
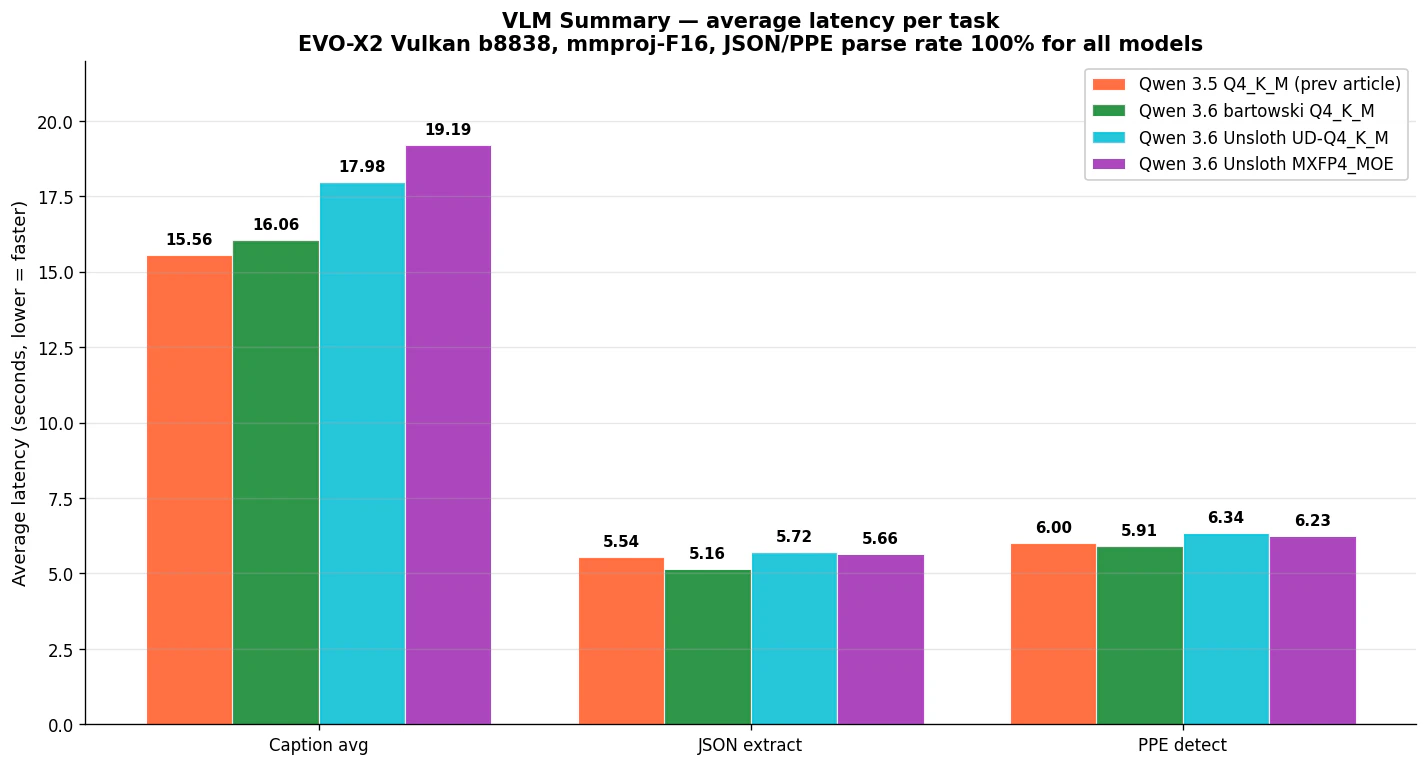
| タスク | Qwen 3.5 Q4_K_M | Qwen 3.6 bartowski | Qwen 3.6 UD | Qwen 3.6 MXFP4 |
|---|---|---|---|---|
| Caption 平均 | 15.56s | 16.06s | 17.98s | 19.19s (最遅) |
| JSON 抽出平均 | 5.54s | 5.16s (最速) | 5.72s | 5.66s |
| PPE 検出平均 | 6.00s | 5.91s (最速) | 6.34s | 6.23s |
| parse 率 | 100% | 100% | 100% | 100% |
Qwen 3.5 → 3.6 の世代差 は VLM では +3% 程度の劣化 (Caption)。これは tg 劣化と整合しており、VLM の品質自体は前回記事と同等です。
6. 常用モデル選定
ここまでの結果から、EVO-X2 での Qwen 3.6 の常用候補を選ぶと bartowski Q4_K_M が最良の選択でした。
| 指標 | bartowski Q4_K_M | Unsloth UD-Q4_K_M | Unsloth MXFP4_MOE |
|---|---|---|---|
| 対話体感 (tg) | ◎ 67.5 | ○ 60.9 | △ 50.8 |
| VLM 全般 | ◎ | ○ | △ |
| JCQ 品質 (nothink) | 95.98% | 96.07% (+0.09pt) | 95.53% |
| JCQ 品質 (Thinking ON) | ◎ 96.87% | (未測定) | (未測定) |
| RAG / 長文処理 (pp) | ○ | ○ | ◎ |
| モデルサイズ | ◎ 19.91 GiB | △ 20.60 GiB | ○ 20.21 GiB |
対話・VLM 用途なら bartowski Q4_K_M を常用にして、RAG や長文バッチなど pp 偏重の用途のみ MXFP4_MOE に切り替える、という使い分けが現実的です。Thinking ON でも劣化せず品質が上がるので、推論を含む用途でも安心して使えます。
UD-Q4_K_M は残念ながら EVO-X2 では中途半端な位置で、選ぶ理由が見当たりませんでした。Thinking ON は未測定ですが、nothink で差がほぼなかったことを考えると、Thinking でも素の Q4_K_M を選ぶ方が素直でしょう。
7. Gemma 4 との比較 (前回記事との接続)
前回記事では、EVO-X2 では Gemma 4 が pp/VLM 速度・品質すべてで Qwen 3.5 を上回る と結論しました。Qwen 3.6 でその構図は変わったでしょうか。
| 指標 | Gemma 4 Q4_K_M (前回) | Qwen 3.6 bartowski Q4_K_M |
|---|---|---|
| pp2048 | 1,348 | 625 |
| tg32 | 65.4 | 67.5 |
| JCQ 正解率 (nothink) | 96.16% | 95.98% |
| JCQ 正解率 (Thinking ON) | 95.80% | 96.87% |
| VLM Caption | 10.29s | 16.06s |
| VLM JSON parse | 100% | 100% |
| サイズ | 15.6 GiB | 19.91 GiB |
速度面では Gemma 4 が依然として優位です。pp は 2 倍以上速く、VLM Caption も 1.5 倍速い。サイズも小さく、他の環境との同居も可能です。
しかし、JCQ の Thinking ON では Qwen 3.6 が Gemma 4 を +1.07pt 上回っています。前回記事で「Gemma 4 は Thinking ON でもほぼ劣化しない (96.51% → 95.80%, -0.71pt)」と特筆した点は依然として強みですが、Qwen 3.6 は改善でさらに上 (96.87%) に抜けました。
使い分けが発生した
EVO-X2 では、これまで「Gemma 4 一択」という状況でしたが、Qwen 3.6 の登場で 用途による使い分けが明確に生まれました。
-
pp/VLM 速度重視 → Gemma 4 Q4_K_M
RAG、長文要約、画像キャプション大量処理など、入力が大きい用途。現時点では代替なし。 -
対話品質・Thinking 常用 → Qwen 3.6 bartowski Q4_K_M
複雑な推論を含む対話、エージェント的な使い方。Thinking ON で Gemma 4 を超える品質。
どちらも常用候補として残り続けます。systemd service で排他切替できるようにしておけば、用途ごとに選択できます。
まとめ
- Qwen 3.6-35B-A3B を EVO-X2 で 3 量子化比較。bartowski Q4_K_M が常用候補
- Unsloth UD-Q4_K_M は EVO-X2 では効果が見えない (+0.09pt、速度 -10%)
- MXFP4_MOE は pp 偏重用途のみ。tg は Q4_K_M 比 -25% で対話用途は厳しい
- ロングコンテキストの pp 劣化率は EVO-X2 で -35〜-40% と DGX Spark (-2.4%) の 15 倍。16K 入力級は設計注意
- VLM は 3 量子化とも JSON/PPE parse 率 100%、実用十分。モニター画面内のテキストまで読み取れる
- Qwen 3.5 → 3.6 で JCQ nothink +1.34pt、Thinking ON は -10.73pt → +0.89pt の大逆転
- Thinking ON で Qwen 3.6 bartowski Q4_K_M は 96.87%。Gemma 4 Q4_K_M Thinking (95.80%) を超え、EVO-X2 のテキスト品質でトップに
前回記事で「EVO-X2 は Gemma 4 一択」と書きましたが、Qwen 3.6 の登場でこの構図は変わりました。pp・VLM 速度重視なら Gemma 4、Thinking 常用の対話品質重視なら Qwen 3.6 という使い分けになります。systemd service で切替可能な運用にしておけば、両方の利点を活かせます。
今後の展望として、llama.cpp Issue #21284 の gfx1151 特化 prefill 最適化や、Ubuntu 26.04 LTS (4/23 リリース予定) 付属の RADV ドライバ改善で、pp や long context の構図は変わる可能性があります。再評価のタイミングを見て更新しようと思います。
検証スクリプト・データ
- 本記事の GitHub リポジトリ: nabe2030/qwen36-evo-x2
- スクリプト (
jcq_bench.py/vlm_bench.py/ グラフ生成) - 全ベンチマーク結果 JSON
- テスト画像
- スクリプト (