【追記 2026-04-11】 初版公開後、Gemma 4 31B Dense、Qwen 3.5-27B Dense、Qwen 3.5-122B-A10B MoE の 3 モデルを追加検証しました。「64 GB / 96 GB のメモリがあるのに 26B で十分なのか?」という疑問に対して、Dense モデルは品質こそ高い(97-98%)ものの tg 10-12 t/s で対話には厳しいこと、122B-A10B は 69 GiB を占有しつつ品質向上は限定的であることを実データで確認しています。詳しくは 全モデル比較 と 全モデル品質比較 のセクションをご覧ください。
はじめに
先日、DGX Spark 上で Gemma 4 vs Qwen 3.5 のベンチマーク記事 を書きました。結論は「速度・効率重視なら Qwen 3.5、ライセンスの自由度なら Gemma 4」というものでした。
今回は同じ比較を EVO-X2(AMD Ryzen AI Max+ 395) で実施しました。Ryzen AI Max+ 395 は CPU と GPU がメモリを共有する統合型の AI チップで、128 GB の LPDDR5X を CPU/GPU で柔軟に割り当てられます。推論エンジンは同じ llama.cpp ですが、バックエンドは CUDA ではなく Vulkan です。
結果は DGX Spark とは 少し違った構図 になりました。Gemma 4 が速度・品質・サイズのバランスで Qwen 3.5 を上回っているように見えます。その理由は、Qwen 3.5 が採用する GDN(Gated DeltaNet) アーキテクチャと Vulkan の相性にあると考えられます。
検証環境
| 項目 | EVO-X2 | DGX Spark(参考) |
|---|---|---|
| プロセッサ | AMD Ryzen AI Max+ 395(CPU+GPU統合、RDNA 3.5, 40 CUs) | NVIDIA GB10(Grace Blackwell) |
| メモリ | 128 GB LPDDR5X (~256 GB/s)、CPU/GPU共有 | 128 GB LPDDR5X (~273 GB/s)、統合 |
| VGM (GPU割当) | 64 GB / 96 GB(モデルサイズに応じて切替) | 128 GB |
| OS | Ubuntu 25.10 (kernel 6.18.20) | Ubuntu 22.04 (ARM64) |
| llama.cpp | b8672 (Vulkan) | b8665 (CUDA sm_121) |
テストモデル
今回は「64 GB で日常的に使えるモデル」だけでなく、「96 GB にすれば載る大型モデル」や「Dense モデル」も含めて比較しました。「なぜ MoE の 26B-A4B を推すのか」を実データで示すためです。
| モデル | タイプ | Active パラメータ | 量子化 | GGUF サイズ | VGM要件 |
|---|---|---|---|---|---|
| Gemma 4 26B-A4B | MoE | 3.8B | Q4_K_M | 15.6 GiB | 64 GB |
| Qwen 3.5-35B-A3B | MoE | 3B | Q4_K_M | 19.7 GiB | 64 GB |
| Gemma 4 31B | Dense | 30.7B | Q4_K_M | 17.4 GiB | 64 GB |
| Qwen 3.5-27B | Dense (+GDN) | 27B | Q4_K_M | 15.9 GiB | 64 GB |
| Qwen 3.5-122B-A10B | MoE (+GDN) | 10B | Q4_K_M | 69.1 GiB | 96 GB |
DGX Spark の記事では Gemma 4 を F16(47 GiB)、Qwen 3.5 を MXFP4(20.1 GiB)で評価しましたが、EVO-X2 では Q4_K_M に統一してフェアな比較としました。
なぜ Vulkan なのか — Ryzen AI Max+ 395 の GPU バックエンド事情
Ryzen AI Max+ 395(gfx1151)で llama.cpp を動かすバックエンドは、Vulkan(RADV) と ROCm(HIP) の 2 択です。2026 年 4 月時点では Vulkan が推奨だと思います。
| 観点 | Vulkan (RADV) | ROCm (HIP) |
|---|---|---|
| ビルドの容易さ | ◎ apt install libvulkan-dev のみ |
△ ROCm システムインストール必要 |
| MoE モデルの tg 速度 | ◎ 最近の RADV 改善で高速化 | ○ 同等かやや遅い |
| 安定性 | ◎ 安定 | △ "GGGG" 出力問題の報告あり |
| GDN サポート | CPU フォールバック | カーネルあるが RDNA 3.5 で非効率 |
2026 年 3 月の llama.cpp Discussion #10879 では、RADV Vulkan が ROCm HIP を MoE モデルで上回った ことが報告されています。Wave32 対応 Flash Attention(PR #19625)や AMD グラフィックスキューの利用(PR #20551)といった Vulkan 固有の改善が効いています。
4 月 2 日の Phoronix の記事 でも、Ubuntu 26.04 のソフトウェアスタック更新で Strix Halo の Vulkan バックエンドに大きな性能向上があったと報告されています。
Vulkan ビルド
sudo apt install -y libvulkan-dev
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp && git checkout b8672
cmake -B build-vulkan -DGGML_VULKAN=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build-vulkan --config Release -j$(nproc)
CUDA や ROCm のような GPU SDK のインストールが不要で、ビルドが非常にシンプルです。
GDN 問題 — Qwen 3.5 が Vulkan で不利な理由
ここが DGX Spark との違いを生む最大のポイントだと考えています。
Qwen 3.5 は Gated DeltaNet(GDN) というアーキテクチャを採用しています。llama.cpp の PR #19504(b8233 でマージ)で GGML_OP_GATED_DELTA_NET として実装されましたが、Vulkan 用のコンピュートシェーダーが存在しません。そのため GDN 演算は CPU にフォールバックします。
HIP(ROCm)にはカーネルが存在しますが、RDNA 3.5 では hipMemcpyWithStream がボトルネックとなり、実効性能は CPU フォールバックと同等の約 12 t/s にとどまるようです(Issue #20354)。
Gemma 4 は GDN を使いません。 標準的な Transformer + MoE アーキテクチャなので、Vulkan の性能がフルに発揮されます。この構造的な差が、EVO-X2 での比較結果を大きく左右していると思われます。
llama-bench 速度ベンチマーク
以下のコマンドで純粋な推論速度を計測しました。
llama-bench -m <model.gguf> -ngl 99 -fa 1 -mmp 0 -p 2048 -n 32 -ub 2048
-mmp 0 は mmap を無効にするオプションです。ネットワーク越し(Samba)にモデルファイルを配置しているため、mmap ではなく全量を VRAM にロードする設定としました。-ngl 99 で全レイヤを GPU にオフロード、-fa 1 で Flash Attention を有効化しています。
MoE モデル(日常利用候補)
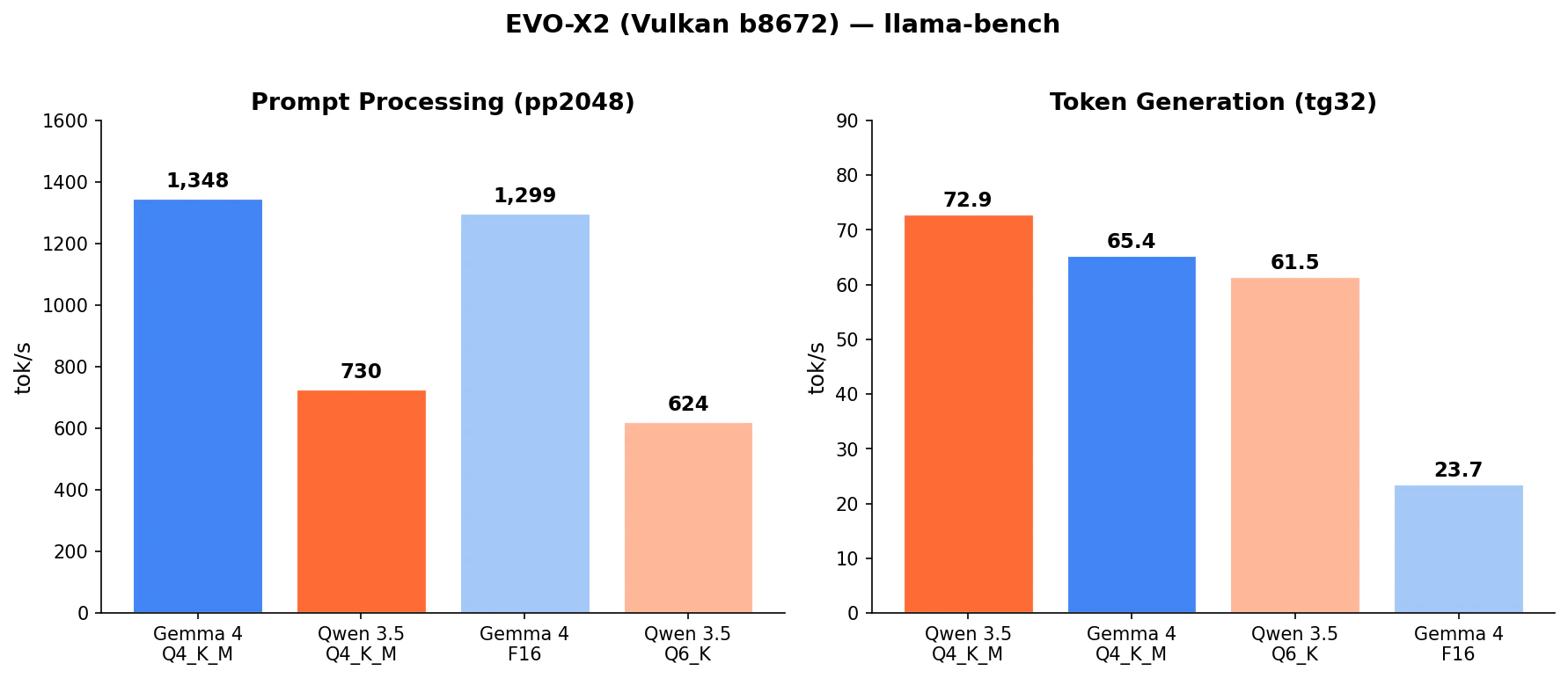
| モデル | タイプ | Active | サイズ | pp2048 (tok/s) | tg32 (tok/s) |
|---|---|---|---|---|---|
| Gemma 4 26B-A4B | MoE | 3.8B | 15.6 GiB | 1,348 | 65.4 |
| Qwen 3.5-35B-A3B | MoE | 3B | 19.7 GiB | 730 | 72.9 |
Prompt Processing で Gemma 4 が 1.8 倍速い(1,348 vs 730 tok/s)。GDN を使わないため、Vulkan のコンピュートパイプラインがフルに活用されていると考えられます。
Token Generation では Qwen 3.5 がわずかに速い(72.9 vs 65.4 tok/s)。これは Active パラメータの差(3B vs 3.8B)によるもので、帯域律速環境では読み出すウェイト量が少ない方が有利です。
全モデル比較 — なぜ MoE を選ぶのか
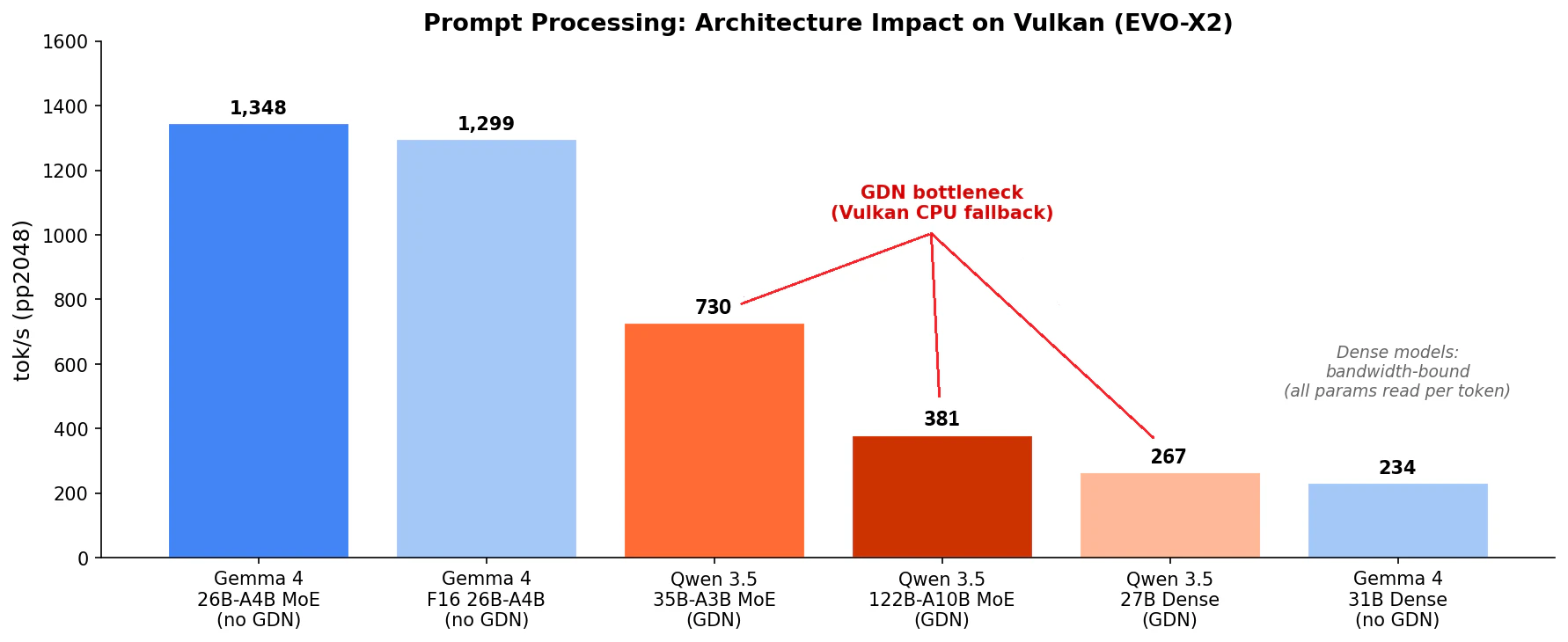
| モデル | タイプ | Active | サイズ | pp2048 (tok/s) | tg32 (tok/s) |
|---|---|---|---|---|---|
| Gemma 4 26B-A4B | MoE | 3.8B | 15.6 GiB | 1,348 | 65.4 |
| Qwen 3.5-35B-A3B | MoE | 3B | 19.7 GiB | 730 | 72.9 |
| Qwen 3.5-122B-A10B | MoE (+GDN) | 10B | 69.1 GiB | 381 | 28.6 |
| Qwen 3.5-27B | Dense (+GDN) | 27B | 15.9 GiB | 267 | 12.1 |
| Gemma 4 31B | Dense | 30.7B | 17.4 GiB | 234 | 10.9 |
EVO-X2 のような統合メモリ環境では、Active パラメータの大きさが速度を決定的に左右します。Token Generation ではトークンごとに Active パラメータ分のウェイトをメモリから読み出す必要があるため、帯域がボトルネックになります。
- MoE 小型(Active 3-4B): 65-73 t/s — 対話に十分快適
- MoE 大型(Active 10B): 28.6 t/s — 使えるが体感は遅め
- Dense(Active 27-31B): 10-12 t/s — 対話用途には厳しい
Dense モデルは総パラメータのほぼ全てを毎トークン読み出すため、16 GiB 程度のモデルでも tg が 10-12 t/s にとどまります。「サイズが小さいから速い」わけではなく、Active パラメータが速度を支配する という点が重要です。
Qwen 3.5-122B-A10B は 96 GB の VGM を使えば載りますが、69 GiB を占有するため他のツールとの同居は困難です。そして 28.6 t/s は快適とは言いにくいと思います。
DGX Spark との比較
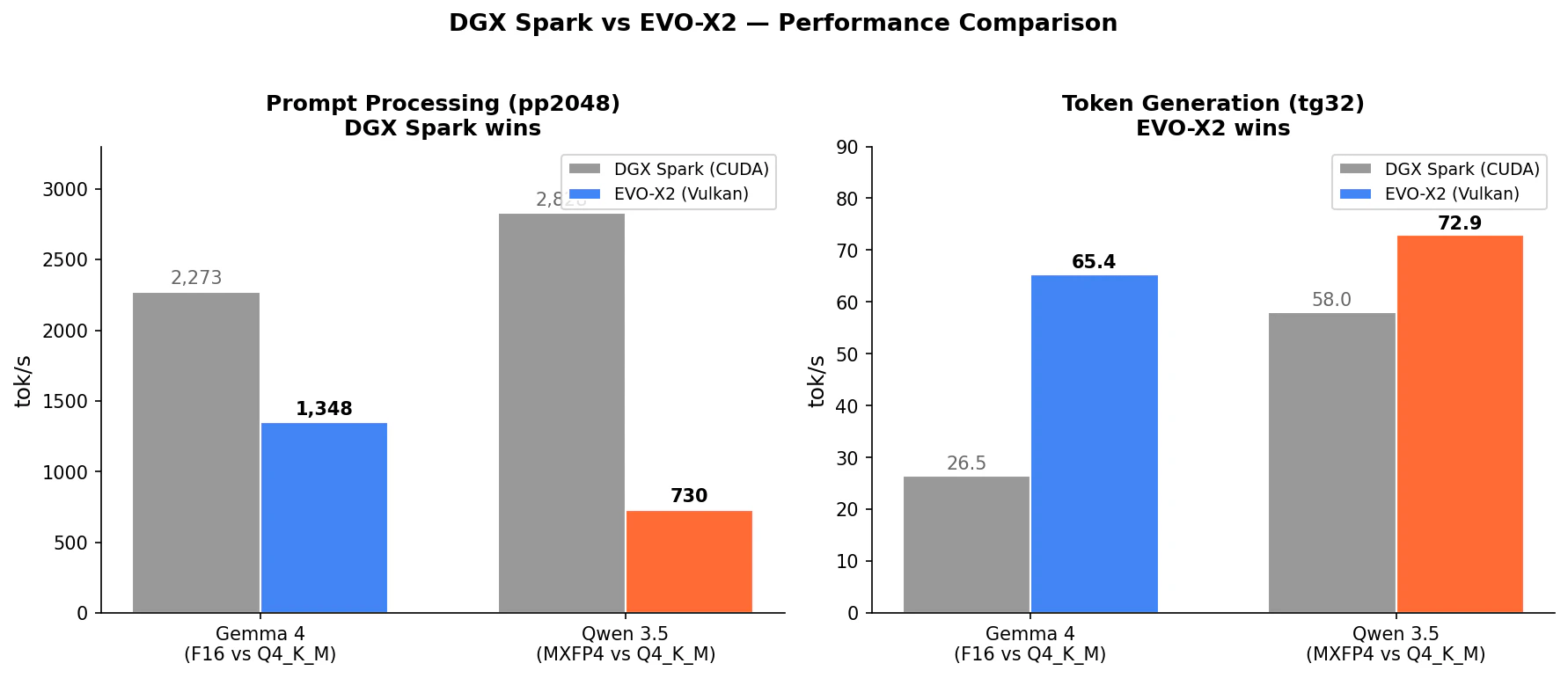
| モデル | 量子化 | DGX Spark | EVO-X2 | |
|---|---|---|---|---|
| Gemma 4 | F16 / Q4_K_M | pp2048 | 2,273 | 1,348 |
| Qwen 3.5 | MXFP4 / Q4_K_M | pp2048 | 2,828 | 730 |
| Gemma 4 | F16 / Q4_K_M | tg32 | 26.5 | 65.4 |
| Qwen 3.5 | MXFP4 / Q4_K_M | tg32 | 58.0 | 72.9 |
Prompt Processing は DGX Spark が圧倒的に速い(2-4 倍)。CUDA の成熟度と Blackwell のハードウェアサポート(MXFP4 ネイティブ演算など)が効いていると考えられます。
一方、Token Generation では EVO-X2 が上回っています。メモリ帯域は DGX Spark の方が上(273 vs 256 GB/s)ですが、Vulkan RADV ドライバの効率が高いようです。量子化の差(DGX の F16/MXFP4 vs EVO の Q4_K_M)も寄与しており、Q4_K_M の方がトークンあたりの読み出しデータ量が少ないため tg では有利に働きます。
なお、DGX Spark の Gemma 4 31B Q4_K_M も 10.43 t/s で、EVO-X2 の 10.88 t/s とほぼ同じでした。Dense 30.7B の帯域律速は環境を問わず同じ結果になるようです。
実用上、対話的な利用では tg 速度(= 体感のレスポンス速度)が重要なので、EVO-X2 の 65-73 t/s は十分快適だと感じています。
テキストベンチマーク: JCommonsenseQA
DGX Spark の記事と同じ JCommonsenseQA v1.1 を使用しました。1,119 問の日本語 5 択常識推論問題を 3-shot プロンプトで評価しています。検証スクリプトは GitHub で公開しています。
全モデル品質比較
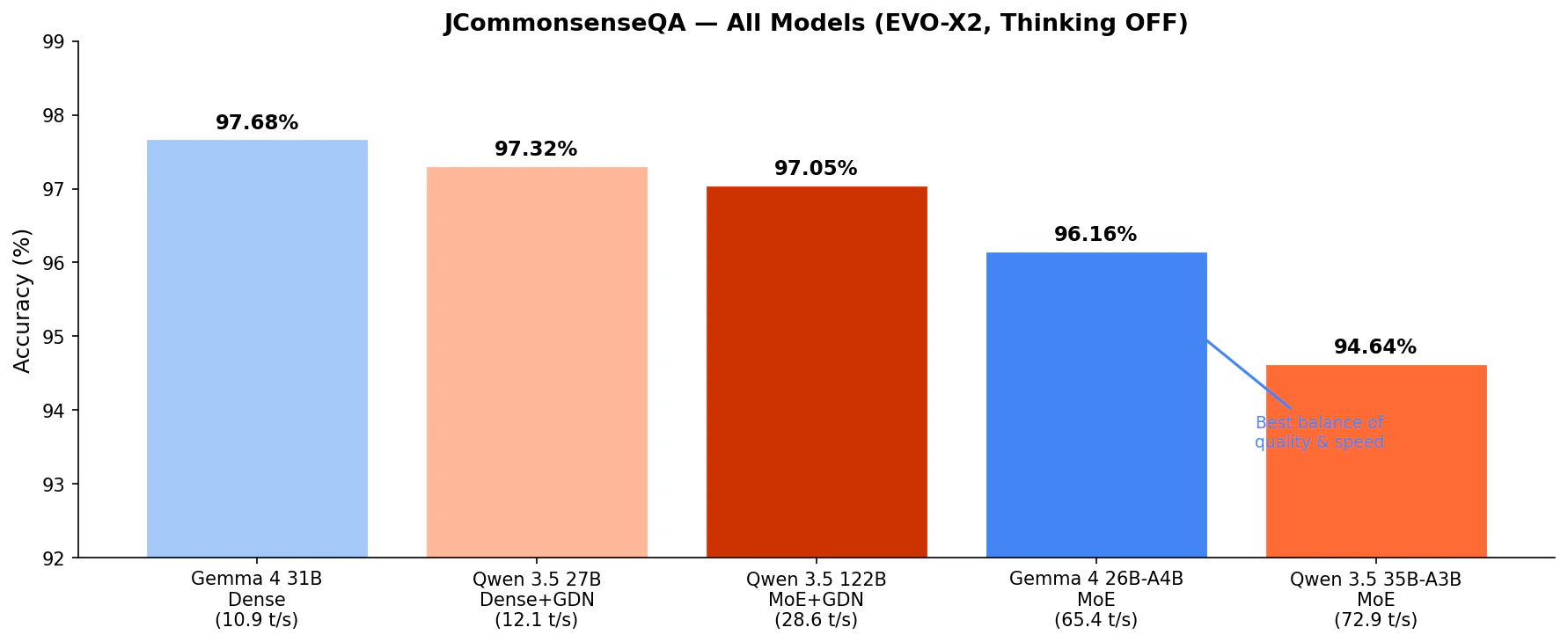
| モデル | タイプ | Active | サイズ | 正解率 | tg32 |
|---|---|---|---|---|---|
| Gemma 4 31B | Dense | 30.7B | 17.4 GiB | 97.68% | 10.9 |
| Qwen 3.5-27B | Dense (+GDN) | 27B | 15.9 GiB | 97.32% | 12.1 |
| Qwen 3.5-122B-A10B | MoE (+GDN) | 10B | 69.1 GiB | 97.05% | 28.6 |
| Gemma 4 26B-A4B | MoE | 3.8B | 15.6 GiB | 96.16% | 65.4 |
| Qwen 3.5-35B-A3B | MoE | 3B | 19.7 GiB | 94.64% | 72.9 |
品質トップは Gemma 4 31B Dense(97.68%)ですが、tg 10.9 t/s で対話には不向きです。Qwen 3.5-27B(97.32%)や 122B-A10B(97.05%)も品質は高いものの、速度面で実用性に課題があります。
Gemma 4 26B-A4B(96.16%)はトップから 1.5pt 劣るだけで、65.4 t/s の快適な速度を実現しています。 この 1.5pt のために 6 倍遅くなることを受け入れるかどうか — 多くの場合、26B-A4B で十分ではないかと思います。
興味深いのは Qwen 3.5-122B-A10B(97.05%)が Gemma 4 31B Dense(97.68%)を下回っている点です。122B のパラメータ数と 69 GiB の VRAM 消費に見合うほどの品質向上は得られていないように見えます。
量子化耐性の比較
DGX Spark の結果と合わせると、量子化による品質低下にも差があります。
| モデル | DGX Spark (高精度) | EVO-X2 (Q4_K_M) | 低下幅 |
|---|---|---|---|
| Gemma 4 26B-A4B | 96.51% (F16) | 96.16% | -0.35pt |
| Qwen 3.5-35B-A3B | 96.16% (MXFP4) | 94.64% | -1.52pt |
Gemma 4 は量子化に対して非常に頑健です。F16 → Q4_K_M で わずか 0.35 ポイントの低下にとどまっています。一方 Qwen 3.5 は 1.52 ポイント低下しており、量子化の影響がやや大きいようです。
Thinking モードの効果
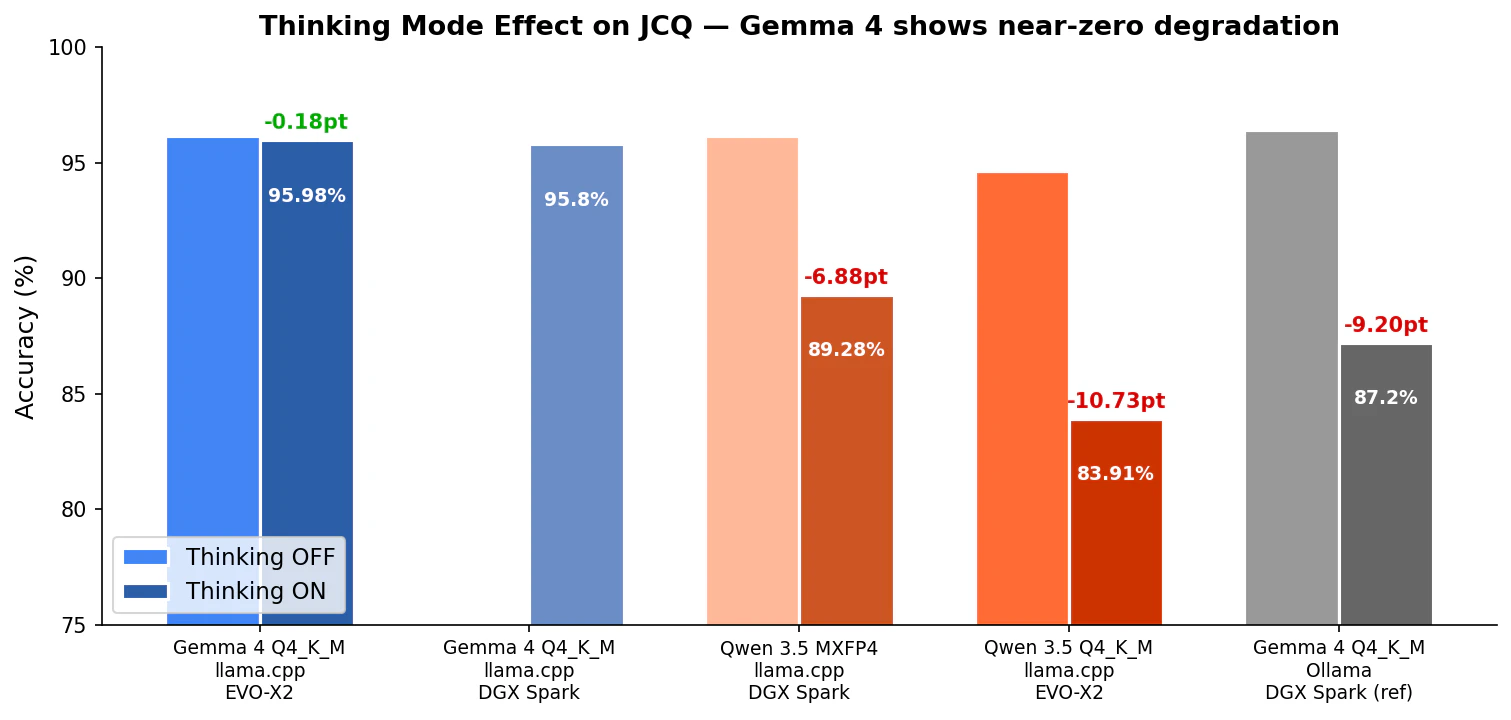
Thinking ON/OFF は日常利用候補の MoE 2 モデルで検証しました。
| モデル | 量子化 | 環境 | nothink | think | 差分 |
|---|---|---|---|---|---|
| Gemma 4 Q4_K_M | llama.cpp | EVO-X2 | 96.16% | 95.98% | -0.18pt |
| Gemma 4 Q4_K_M | llama.cpp | DGX Spark | — | 95.80% | — |
| Qwen 3.5 MXFP4 | llama.cpp | DGX Spark | 96.16% | 89.28% | -6.88pt |
| Qwen 3.5 Q4_K_M | llama.cpp | EVO-X2 | 94.64% | 83.91% | -10.73pt |
| Gemma 4 Q4_K_M | Ollama | DGX Spark (元記事) | 96.4% | 87.2% | -9.2pt |
Gemma 4 の Thinking 劣化がほぼゼロ(-0.18pt) という結果は、今回の検証で最も驚いた発見です。
元記事(Ollama)では Gemma 4 でも -9.2pt の劣化が報告されていました。今回 llama.cpp b8672 + Q4_K_M の組み合わせでほぼ劣化しなかったのは、ランタイムの Thinking 処理の違いが影響しているのかもしれません。
一方、Qwen 3.5 は Q4_K_M だと -10.73pt と DGX Spark の MXFP4(-6.88pt)より悪化しています。量子化が Thinking の推論品質にも影響しているように見えます。
DGX Spark の記事と同じく、知識系 5 択問題では Thinking モードは無効にした方がよい という結論は変わりませんが、Gemma 4 + llama.cpp の組み合わせでは劣化が極めて小さいという点は注目に値すると思います。
Gemma 4 Thinking バグの追試 — F16 固有の問題だった
DGX Spark の記事では、llama.cpp b8665 で Gemma 4 の Thinking モードが <unused49> トークンを出し続けるバグを報告し、GitHub Discussion #21338 に投稿しました。
今回 EVO-X2 で b8672 にアップデートしたところ、Q4_K_M では Thinking ON が正常に動作。これを受けて DGX Spark でもクリーンリビルド(b8672)して追試した結果、バグの原因はバージョンではなく F16 GGUF 固有の問題 であることが判明しました。
| モデル | 量子化 | バックエンド | Thinking ON |
|---|---|---|---|
| Gemma 4 | F16 | CUDA (DGX Spark, b8672) | ❌ <unused49> 発生 |
| Gemma 4 | Q4_K_M | CUDA (DGX Spark, b8672) | ✅ 正常動作 |
| Gemma 4 | Q4_K_M | Vulkan (EVO-X2, b8672) | ✅ 正常動作 |
この追試結果は Discussion #21338 にフォローアップコメントとして報告し、GitHub リポジトリの README も更新しました。
回避策: Thinking モードを使いたい場合は、F16 ではなく量子化 GGUF(Q4_K_M で確認済み)を使用してください。
マルチモーダルベンチマーク
DGX Spark の記事と同じ画像セット(展示会写真 5 枚 + PPE 検出用 3 枚)で、日常利用候補の MoE 2 モデルについて 3 つのタスクを実施しました。Dense モデルは tg 10-12 t/s のため、VLM(画像のプリフィル処理が追加される)ではさらに時間がかかると予想されます。速度比較は llama-bench のデータで十分と判断し、VLM は MoE モデルに絞りました。
# mmproj(マルチモーダルプロジェクタ)を指定して起動
llama-server \
-m gemma-4-26B-A4B-it-Q4_K_M.gguf \
--mmproj mmproj-gemma-4-26B-A4B-it-f16.gguf \
-ngl 99 --jinja \
--chat-template-kwargs '{"enable_thinking":false}' \
--port 8080 --temp 1.0 --top-p 0.95 --top-k 64
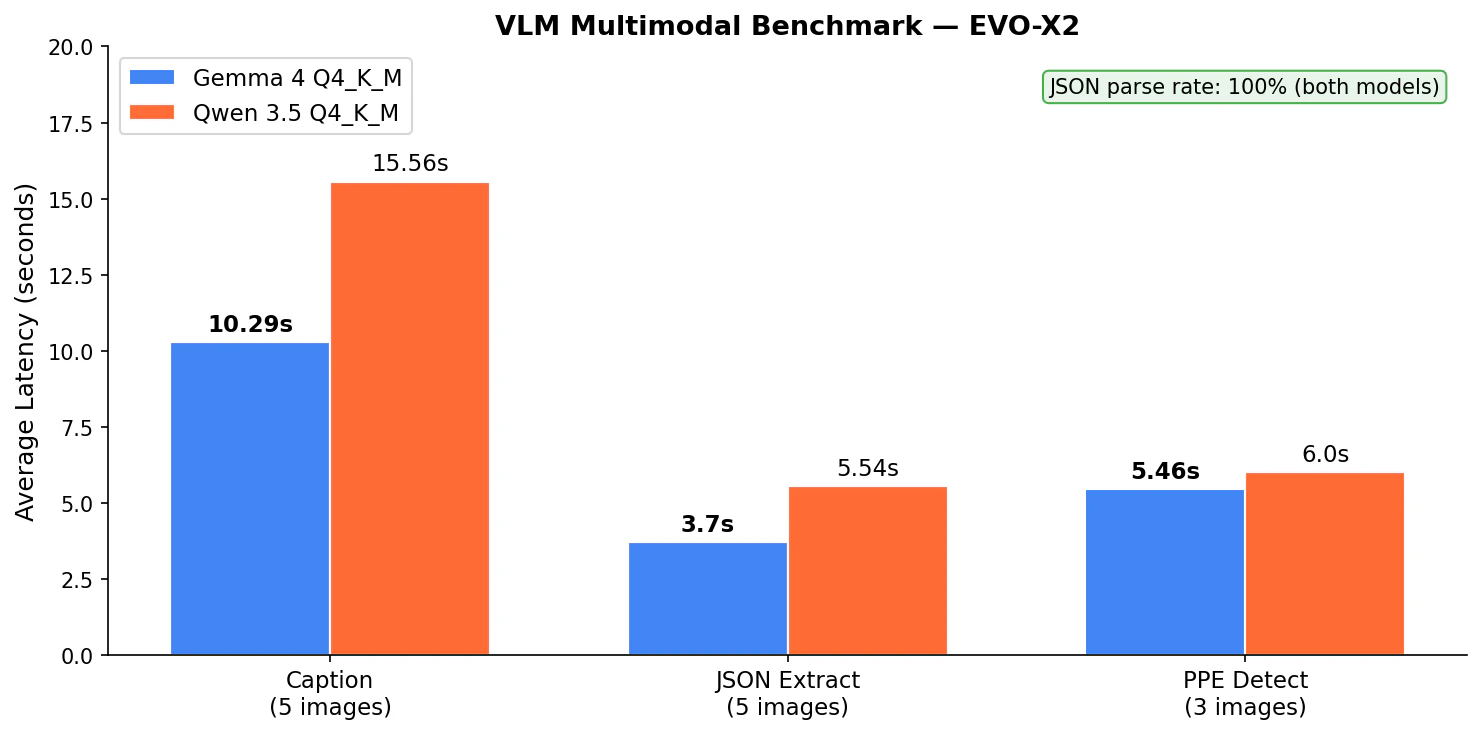
| テスト | Gemma 4 Q4_K_M | Qwen 3.5 Q4_K_M |
|---|---|---|
| キャプション平均 | 10.29s | 15.56s |
| JSON 抽出平均 | 3.70s | 5.54s |
| JSON parse 率 | 100% | 100% |
| PPE 検出平均 | 5.46s | 6.00s |
| PPE parse 率 | 100% | 100% |
Gemma 4 が全タスクで高速でした。 キャプション生成で 1.5 倍、JSON 抽出で 1.5 倍の差がついています。JSON parse 率は両モデルとも 100% で、構造化データ抽出の信頼性は互角のようです。
DGX Spark の記事と比較すると、EVO-X2 の方が全体的にレイテンシが短くなっています。Q4_K_M の軽量さと Vulkan の tg 速度の高さが効いていると思われます。
全体まとめ
MoE モデル直接比較(日常利用候補)
| 指標 | Gemma 4 Q4_K_M | Qwen 3.5 Q4_K_M |
|---|---|---|
| llama-bench pp2048 | 1,348 t/s | 730 t/s |
| llama-bench tg32 | 65.4 t/s | 72.9 t/s |
| JCQ 正解率(nothink) | 96.16% | 94.64% |
| JCQ 正解率(think) | 95.98% | 83.91% |
| VLM キャプション | 10.29s | 15.56s |
| VLM JSON parse | 100% | 100% |
| VLM PPE 検出 | 5.46s | 6.00s |
| GGUF サイズ | 15.6 GiB | 19.7 GiB |
| ライセンス | Apache 2.0 | 独自(制限あり) |
全モデル品質 vs 速度
右上(高品質・高速)ほど理想的です。バブルの大きさは GGUF サイズを表しています。Gemma 4 26B-A4B が品質と速度のスイートスポットに位置していることがわかります。30 t/s を下回ると対話での体感が遅くなり始めると感じています。
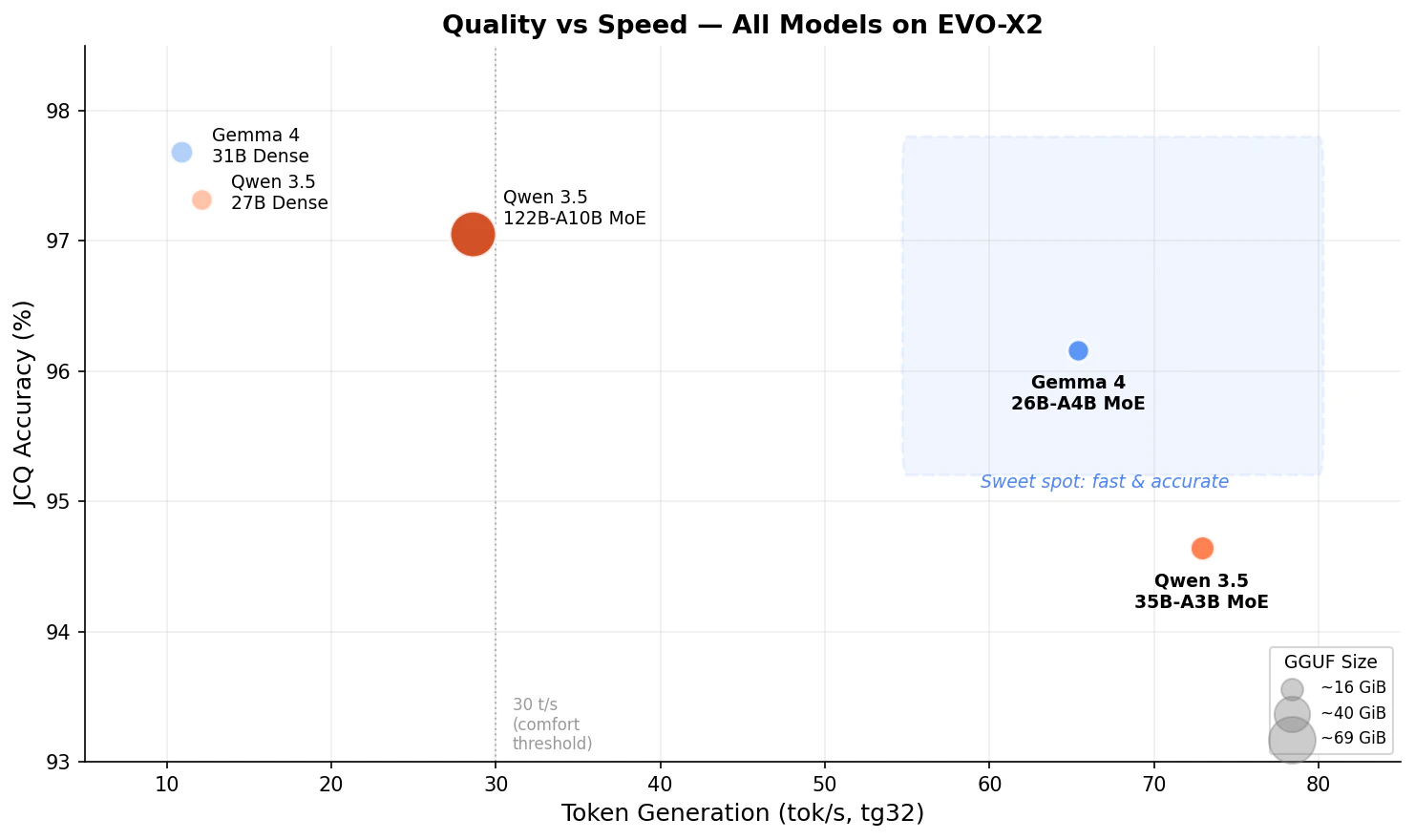
| モデル | タイプ | JCQ | tg32 | 実用性 |
|---|---|---|---|---|
| Gemma 4 31B | Dense | 97.68% | 10.9 | △ 品質最高だが対話には遅い |
| Qwen 3.5-27B | Dense+GDN | 97.32% | 12.1 | △ 同上。GDN問題で pp も遅い |
| Qwen 3.5-122B-A10B | MoE+GDN | 97.05% | 28.6 | ○ 96GB必要、他ツール同居困難 |
| Gemma 4 26B-A4B | MoE | 96.16% | 65.4 | ◎ 品質と速度のベストバランス |
| Qwen 3.5-35B-A3B | MoE | 94.64% | 72.9 | ○ tg最速だが品質でやや劣る |
DGX Spark とは少し違った構図
DGX Spark(CUDA)では Qwen 3.5 の MXFP4 量子化が効いて速度面で優位でしたが、EVO-X2(Vulkan)では GDN 問題のない Gemma 4 の方が総合的に優れている という結果になりました。
この違いは GPU やハードウェアの優劣ではなく、モデルアーキテクチャとバックエンドの相性 に起因していると考えています。
- CUDA 環境: GDN が効率的に動くため Qwen 3.5 のポテンシャルが発揮される。MXFP4 量子化も Blackwell のハードウェアサポートで高速
- Vulkan 環境: GDN シェーダーが未実装のため Qwen 3.5 の pp が律速される。一方 Gemma 4 は標準的な Transformer で Vulkan の性能をフル活用
EVO-X2 / Ryzen AI Max ユーザーへの推奨
Gemma 4 26B-A4B Q4_K_M が現時点での最良の選択肢だと思います。
- 15.6 GiB と軽量で、他のツールとの同居も容易
- pp/VLM で Qwen 3.5 を大きく上回る
- JCQ 品質で 1.5pt 優位、Thinking 劣化もほぼゼロ
- Apache 2.0 ライセンスで商用利用も自由
「96 GB にすればもっと大きなモデルが載るのでは?」という疑問については、Qwen 3.5-122B-A10B(69 GiB)を試しましたが、品質は 97.05% と Gemma 4 31B Dense(97.68%)を下回り、tg 28.6 t/s で快適とは言い難い結果でした。大容量メモリは「大きなモデルを載せる」よりも「長いコンテキスト」や「他ツールとの同居」に活かす方が実用的ではないかと感じています。
ただし、今後 llama.cpp の Vulkan バックエンドに GDN シェーダーが実装されれば、Qwen 3.5 の pp 速度が大幅に改善する可能性があります(Issue #20354 で追跡中)。また、Ubuntu 26.04 LTS(4 月 23 日リリース予定)で Mesa RADV ドライバのさらなる改善も見込まれるため、定期的な再評価をおすすめします。
検証スクリプト・データ
- EVO-X2 ベンチマーク: GitHub: gemma4-vs-qwen35-evo-x2
- DGX Spark ベンチマーク: GitHub: gemma4-vs-qwen35-dgx-spark
- 元記事: Gemma 4 を DGX Spark で動かして日本語とマルチモーダルをベンチマークしてみた(DevelopersIO)
参考リンク
- DGX Spark での Gemma 4 vs Qwen 3.5 ベンチマーク(Qiita / 前回記事)
- llama.cpp Vulkan Performance Discussion #10879
- GDN Issue on gfx1151 — Issue #20354
- Known-Good Strix Halo ROCm Stack — Discussion #20856
- Strix Halo Wiki: llama.cpp with ROCm
- Phoronix: Ubuntu 26.04 Strix Halo Performance
- Gemma 4 Thinking Bug — Discussion #21338
- Google Blog: Gemma 4
- JCommonsenseQA v1.1