に続いて書きます。
結論
- とりあえずAthenaからSnowflakeへ無事に移行完了
- Snowflakeならではの活用はこれから
なぜ移行したか
S3+Athena構成の弊社データ基盤の限界が近い の通りなんですが、抜粋すると
- Athenaの環境を2020年に構築し、利用拡大に伴い厳しさが出てきた
- 社内でもある程度活用されているが、応用的な分析には耐えられない
- パフォーマンスが固定なので、複雑な分析は作成時、閲覧時ともに待ち時間が長くなる
- 複雑なクエリは10分待ちとかも…
- 加工した結果の保存先として別途RDSを使っているので、分析がしにくく管理に支障がある
- AthenaではUPDATE文が実行できないため、delete & insertもしくは別DBに作る必要がある
- 今後も加工したデータを保存するシーンが増えていくのが予想されるため運用負荷が高い
- メインのIoTデータはdelete & insertしたりと複雑な処理になっている
- (時系列データかつ電波状況により遅延データがある中で、集計の都合上、生データに加えて前後の距離や時間の差分が必要なので、加工が必要)
- 項目追加対応が結構大変
- その他テーブルの変更対応も属人化しやすい状態
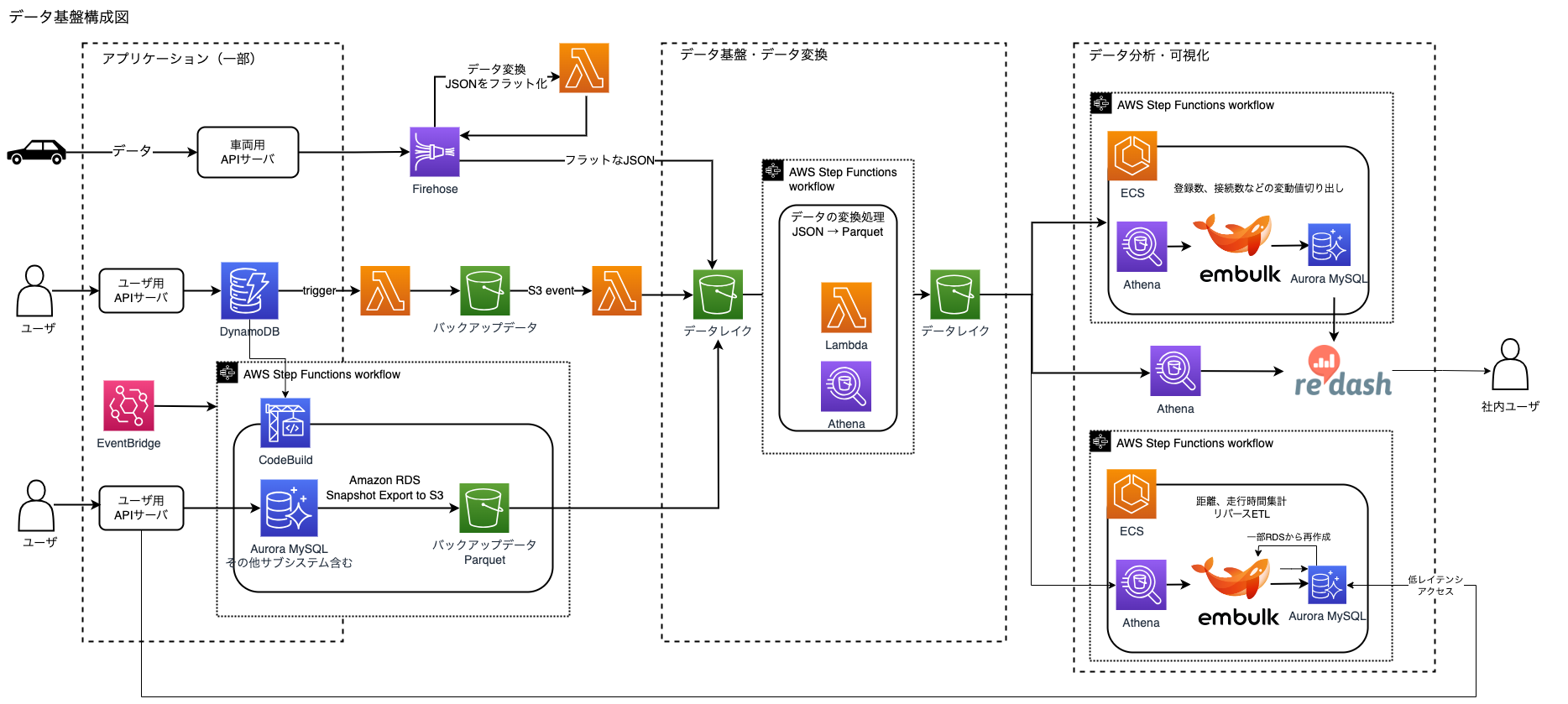
移行直前の構成図を置いておきます。
Snowflakeを選んだ理由
- 勢いがあるので、一応比較したけどSnowflakeありきでやった部分は大きい
- Redshift Serverlessを一応触ったが、使いにくい & 課金が1分単位で微妙
- BigQueryに関してはデータはAWSにあるので、この2024年のタイミングで選定する理由が無い
移行プロジェクト概要
- 期間
- 2024/1 机上比較
- 2024/2-6 メイン機能の構築 & 評価
- 2024/6-7 サブ機能の構築 & 評価
- 2024/8-9 並行稼働、切り替え
- メンバー
- 私:メイン担当
- 業務委託メンバー(月40h):主にサポート
- (パイプライン含むクエリのマイグレーションを中心に色々)
- 上司(現行のデータ基盤を作った人):壁打ち役、CTOへの報告などの後押し
- 既存のつらみも分かっているので、Snowflakeへの移行を前向きに支えて頂きました
構成紹介
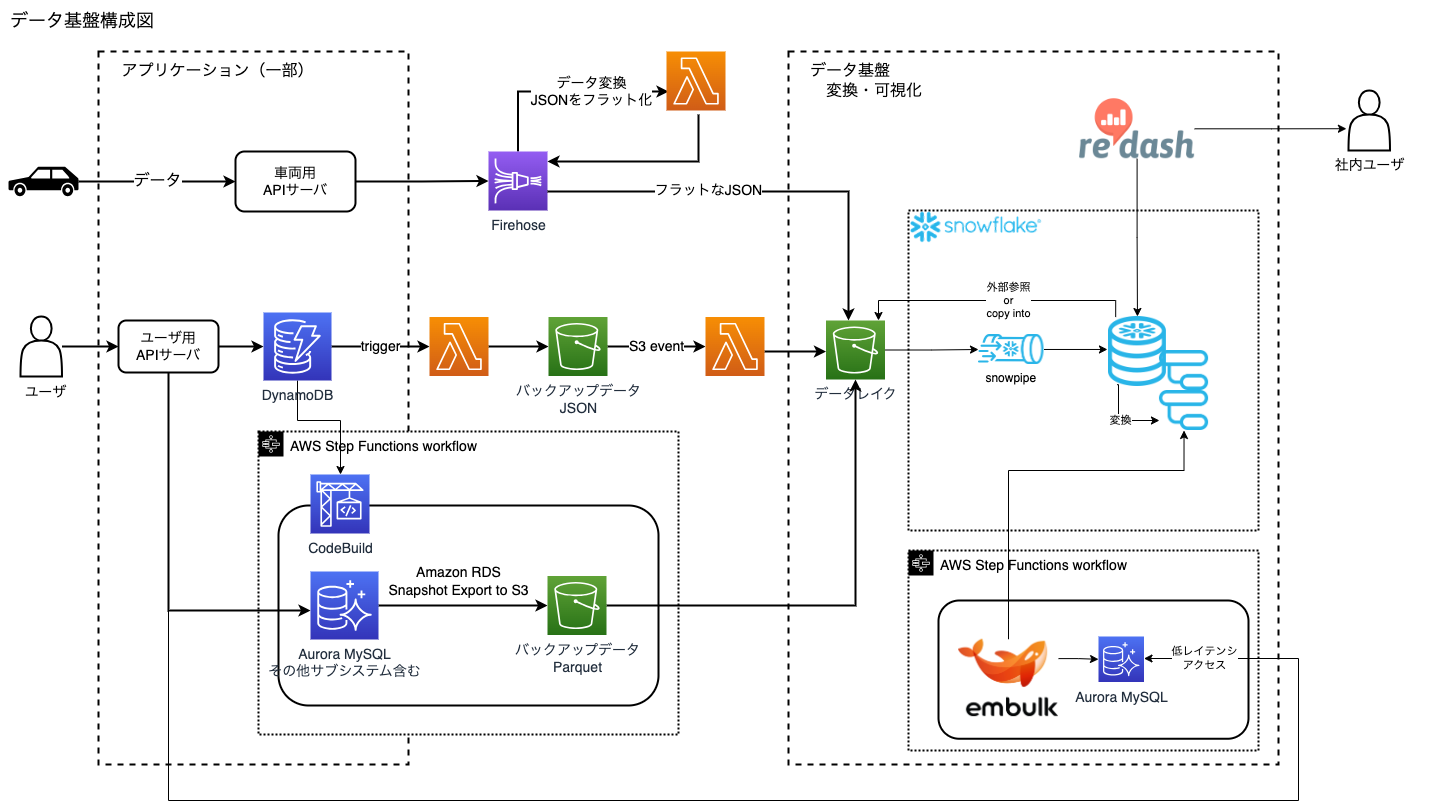
構成図もうちょっとかっこよく書きたい気もする
(※)細かい部分は AthenaからSnowflakeへ移行するときの躓きポイント集 にもあるので、読んでみてください。
- 基本設定
- Standard Edition
- 検証の末マテリアライズドビューの出番があまり無さそうなので、コスト的に
- ネットにある設定を踏襲するものの、権限に関してはSnowflakeに直接ログインするユーザーは多くないので、ACCOUNTADOMINNのまま
- Redash用のユーザーに関しては、READONLYの権限を作成し、各国で分かれているスキーマごとにいい感じの権限を割り当て。追加されたものも恒久的に反映される設定に
- 大文字小文字を区別しない設定に (Athenaを踏襲)
- (ALTER ACCOUNT SET QUOTED_IDENTIFIERS_IGNORE_CASE = TRUE;)
- redashの移行や下記心地(””を入れる煩わしさ)を考慮
- ウェアハウスは基本一番下のX-Small、速さを求めるようにMediumを用意
- Google WorkspaceにSSOログインできるように設定
- Standard Edition
- 取り込み編
- S3に集めるところまではAthenaの構成を踏襲
- csv:外部テーブル
- 外部テーブルはS3通知も使いつつtaskでREFRESHを実行(※)
- rds exportのparaquat:外部テーブル or truncate & copy into
- taskで使われるテーブルを中心にSnowflake内に取り込んでいる
- 外部テーブルはS3通知も使いつつtaskでREFRESHを実行(※)
- iotデータのjson:snowpipe + taskで別テーブルに整形
- その他dynamodbのjson:外部テーブル & S3通知
- 変換 task
- ワークフローはSnowflakeのtaskでdagを組んで良しとした
- 毎時と日毎を共存させるのが少し面倒だった(※)
- ワークフローはSnowflakeのtaskでdagを組んで良しとした
- その他処理(構成図に乗せてないサブ的な処理)
- Pythonの処理はうまくSnowflakeに乗せきれず、Lambda Pythonからsnowflakeにアクセスし動かす形で更新
- AWS Lambdaでpython-snowflake-connectorを使う の通りにLayerを作れば簡単。
- これ → LambdaでSQLの結果をDatadogにメトリクスとして送信し異常検知を行う
- 異常検知機能も組めるのでSnowflake内に作れそうな気もするけど、移行してしまった今、直近は作らない気がする
- 会社HPに総走行距離を出すやつ。内部ではクエリの結果をs3に置いている
- https://www.global-mobility-service.com/
- 最近総走行距離が10億km突破した🎉
- Pythonの処理はうまくSnowflakeに乗せきれず、Lambda Pythonからsnowflakeにアクセスし動かす形で更新
- 通知
- slack通知を実装(※)
- タスクの失敗
- 最新のデータが来てない
- slack通知を実装(※)
移行周り
- IoTデータ(S3に日毎のプレフィックスにjsonで保存されている)はシンプルに取り込みました。ウェアハウスを上げると数時間くらいで取り込めた記憶
- データマート、リバースETLデータ:EmbulkでSnowflakeに接続し粛々と取り込みました。躓きポイントに書き忘れましたが、ここのODBC接続も苦戦したような気がする…
- 件数が多いやつはタイムアウトするので、期間を区切ってシェルスクリプトで順番に実行しました。(EmbulkやらMySQLの設定を変更してもタイムアウトするのが直せなかった…)
- timestamp型に対してdateでbetweenすると最終日の0:00 00以外対象外になるので注意が必要です。。
- 1ヶ月くらいは並行稼働させて両者が生成した変換結果を比較して問題ないか比較しました
- 割とこの段階になって作ったクエリのボロが発覚してバタバタしました…
- Redash移行:クエリIDを変えないように、stagingでクエリを用意し、300件弱を手動で粛々と移行
- 移行対象は直近3ヶ月で3回以上閲覧 or 1回以上の閲覧かつtagが付与されているものとしました
- 移行後パラパラと追加対応が必要な場面もありましたが、バタバタするほどではなかったです
- カラムが大文字になるので、Redashのグラフ等を再定義する必要があり大変でした(*)
- 切り替えについて
- ユーザーから見える部分はRedashだったので上記のように徐々に編集で変えていく
- リバースETL:並行稼働中はstaging環境に流し込む形で動作確認し、切り替え日に本番もSnowflakeから流し込む形に変更
コスト話
みんな気になるコスト話
具体的な金額は控えますが、移行前の費用と比べて、1.3倍位になりました汗
(ちなみに当初の見込みは1.05倍程度でした)
データ基盤の運用負荷が下がった点を踏まえると十分ペイできますし、先々の活用の可能性を踏まえると十分安いです。
とはいえコスト増加の分も活用していくことが求められています。
もう少し詳細を書くと
- メインのS3 + Athenaの費用が無くなった
- データマート用のRDSが無くなった
- リバースETL用のRDSは低レイテンシーが必要なのでなくせなかったが、現在は流し込みだけになったのでゆくゆくはプラットフォームのDBに統合したい
- プラットフォームから日毎、月ごと、合計の走行距離などが参照されるが、古い日毎のデータはいらなくなる(Snowflakeのみに全期間あれば良い)
- リバースETL用のRDSは低レイテンシーが必要なのでなくせなかったが、現在は流し込みだけになったのでゆくゆくはプラットフォームのDBに統合したい
- クエリに関しては試験段階でも早くなったり遅くなったのもあり、見積もりきれない部分があり、最終的に想定より増加という結果に
更にいうと試算時はEnterprise Editionでした。検証しているうちにマテリアライズドビューが必須の場面が無く、コスト面でStandard Editionにしました。それでも超えてしまった…
外部テーブルの運用についてはマテリアライズドビューを挟んだほうが楽になる気はしますが、マテリアライズドビューも動くときに費用がかかるので見送った形になります。
またIoTデータの更新は基本時系列だけど電波状況により遅延データがあるので、一定期間再作成という既存の運用を引き継ぐことにしました。試せてないのであれですが、マテリアライズドビューにすると更新負荷が高いと思います
マテリアライズドビューは裏でいい感じに動くので、コストを読めないのがなかなか難しい。
(動かせばコスト内訳で多少分かるようになっているはずです)
Snowflakeにして良かったこと
移行を考えるきっかけになった課題がすべて解消されました。
- 運用工数削減
- 分析パイプラインがシンプルになった
- RDSをデータマートとリバースETL用に2台あったのが1台に
- Embulkの変換処理がSnowflake内になってシンプルに
- 追加の分析テーブル作るのも楽
- テーブルやカラムの追加もGlueよりは楽なような気がする
- terraform化が後回しになっているのでこれから改善な部分もある
- 分析パイプラインがシンプルになった
- 分析面
- 適宜ウェアハウスを変えることで時短
- データが1箇所にまとまったことでjoin等々しやすい
- 今まで3箇所に別れていたのでRedashのquery_rezultsを駆使していた
- 分析の幅が広がる
- マーケットプレイスから色んなデータが無料/有料 で使える
- GISを始め豊富な関数+Athenaに比べ知見が多い
- SnowflakeのコミュニティSnowVillageが活発
- LLM/MLが使える(Snowflake Cortex)
- SnowparkやStreamlit on Snowflakeが使える
感想
Snowflakeを使い始めたときは、お作法的なところをいきなり突きつけられポカーンとしていました。stageを作ってcopy intoするところ。ここも奥が深くて、ちゃんと定義をベタ書きする例も多いのですが、INFER_SCHEMA使えば省略できたり。
いよいよ実運用のために定期取り込みを考えるのですが、snowpipeや外部テーブルにしても選択肢が色々ある中で使ってみると挙動が色々あったりして苦しみました。
taskもstep functionからの移行なので、どこまで作り込めるかがよくわからない中、日毎と毎時の共存や、DAGをどう組むのか、そのために空taskを用意したり。
そういえばAthenaでS3にデータを集める構成にしていたので、その部分をそっくりそのまま使えたのはだいぶ楽でした。
大文字小文字を区別しない設定で進むかどうかはRedashの躓きもありながら、最後まで不安は残りました。
ほぼ1人で淡々とやる形だったので、悩んだり詰まったりするともろに進まなくなりスケジュールが想定より押して行きました…それでも1つ1つ潰していくことで移行前と同等の環境を作り出すことができ、ようやく無事に切り替えが完了しスタートアップにしては長めだったプロジェクトも一段落できました。
社外へのアウトプットが終わり、残るはサボっていたterraform化になります。
これで当社のデータ活用は次のステップへ進みます。クラウド破産に気を付けて活用していきます!