Datadogのアドベントカレンダー書くぞーと思った際に、いいネタ無いかなと振り返ったところ結構前にやったことですが、タイトルの件を思い出したので書いていきます。
シンプルな内容ですが参考になる人がいれば幸いです。
https://qiita.com/advent-calendar/2022/datadog
Datadogの利用状況
弊社では監視環境にDatadogの以下機能を利用しています
- AWSのメトリクスを連携し監視
- EKS(kubernates)のpod監視(Prometheus / Grafanaから移行)
- Node.jsのアプリケーションに対しAPMで監視
- これはマジで便利
- 全体的にざっくりSLOの導入
- Lambdaから送信したカスタムメトリクスを使った監視 ←今日書くこと
導入してないもの
- ログ監視
- ログが多く費用が高いため見送り
- アプリケーションエラーに関してはSentryを使用しているのでそこまで不便していない
- RUM
- いずれ導入したい気もする
- 死活監視
- 今まで使っていたMackerelのほうが安かったので継続(小声)
背景
弊社では自動車ローンにおいて、与信補強のために起動制御が可能なIoTデバイスを車に取り付け、万が一滞納が合った際などは遠隔でエンジン始動ができないようにし、返済を促したり、安全に回収できたりします。
IoTデバイスには4Gなどのキャリア回線を使い通信しており、サービスの特性上IoTデバイスと疎通が取れていることは重要です。
このため極稀ですが、キャリアの通信障害などが起因で疎通している台数(接続台数)が減ることがあります。
※日本では少ないですが、弊社が展開しているアジア各国では年1,2回くらい通信障害が発生している印象です。通信障害も連絡ベースでの対応と、日本とは品質が異なります。
BtoBtoCのビジネスモデルのため、ファイナンス(ローン)を提供している先から、「今日接続できないデバイス多いんだけど」となるとサービスの信用が落ちてしまいます。
監視を行い、こういった通信障害などの接続台数減に社内で気づき、通信キャリアに問い合わせし先手で対応できることが重要です。
データの特性上、全体のアクセス数などはALBなどの1次データからすぐに確認ができます。ただし以下のような切り口での分析は工夫が必要です。
- 各国毎デバイスで分けたい
- 接続台数を見たいので、例えばこの1時間に接続している台数を見たい
- 日中と夜で接続台数が異なる国があるので、閾値だけではなく傾向を考慮した監視を行いたい
若干回りくどいですが、タイトルのような形で実現していきます。
実現方法
逆順に遡っていきます
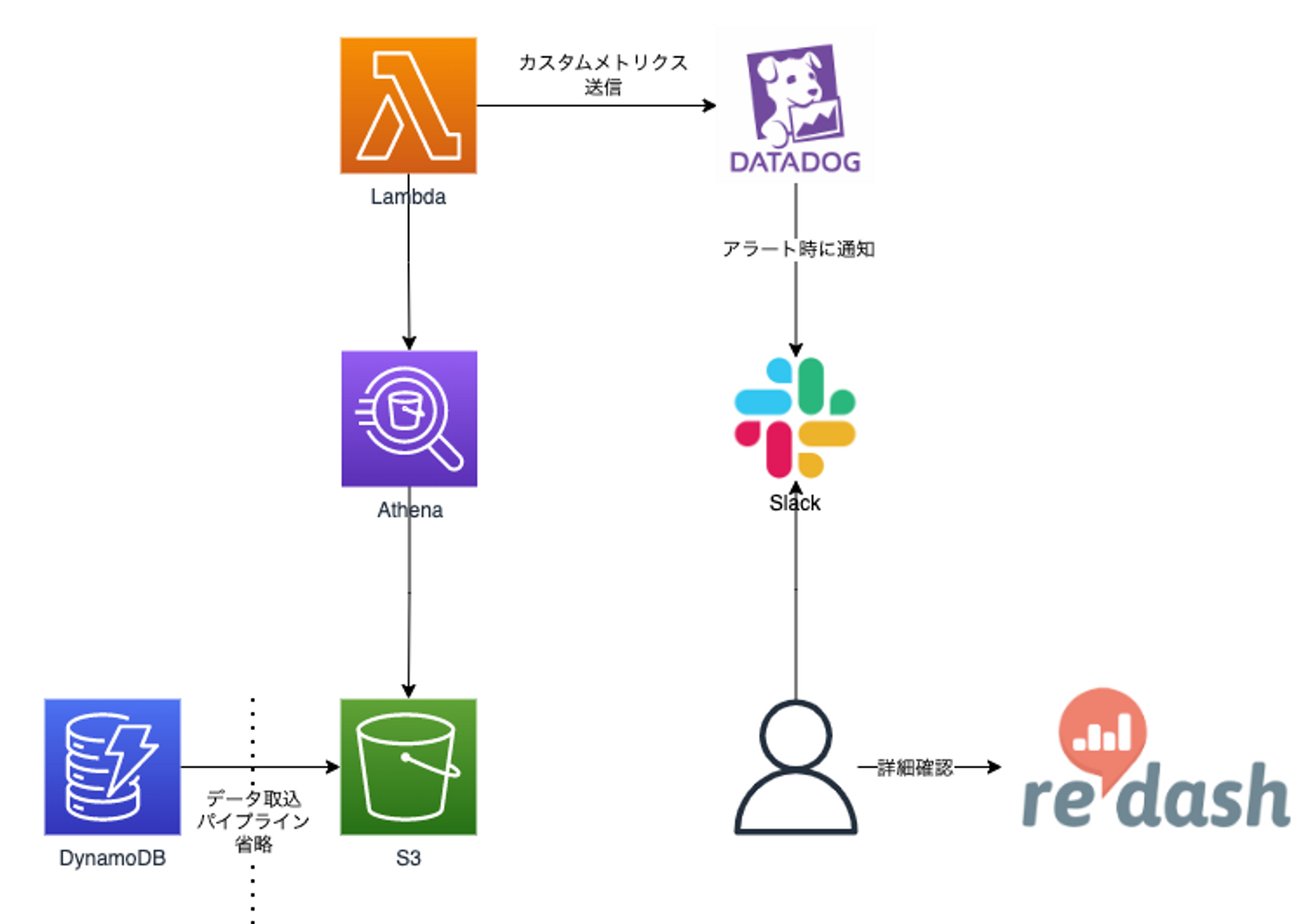
ざっくり構成図
異常検知
異常検知は、傾向や、季節的な曜日や時間帯のパターンを考慮しながらメトリクスの挙動が過去のものとは異なる期間を認識するアルゴリズム機能です。これは、しきい値ベースのアラート設定では監視することが困難な強い傾向や反復パターンを持つメトリクスに適しています。
異常検知モニター より
こういった過去のパターンを考慮した監視は、自前でやるには別途サーバーが必要になるし、ロジック周りの保証も手間がかかるので、SaaSでシュッとできるのはかなりありがたい。
ALBの全体アクセス数も異常検知でモニタリングしています。
Slackの通知
モニター設定時簡単にできます。
ここで特記するのは、Datadogアカウントを持っている人はDatadogで確認できるのですが、他の社員は確認できないため、構成図のように、全社メンバーが利用できるRedashのリンクをアラート文に仕込むことで確認ができるようにしています。
※アカウントには料金はかからないですが、不特定多数の社員が見るので登録する運用は手間になってしまいます。
Datadogへのカスタムメトリクス送信
カスタムメトリクス に記載のように、いろんな手法でカスタムメトリクスを送信することができます。
ライブラリを使った上で、metric, value, tagsを送信すれば良い感じに実現できます。
カスタムメトリクス数に応じて若干料金が発生しますが、1ホストあたり100までなどと含まれているケースもあるので、料金表を確認しましょう。
今回のように1時間に1回数件のカスタムメトリクスだと追加費用無しで実現できるケースが多いかと思います。
DD_API_KEYはLambdaの環境変数に仕込みます。

Lambda(Python)からAthenaの実行
弊社ではデータレイクにAthena+S3を使っているので、良い感じにアクセスし、SQLを実行します。
pyathenaを使うと簡単にできます。
後はAthena諸々にアクセスできるIAMロールをLambdaに割り当てます
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:BatchCreatePartition",
"glue:GetDatabase",
"s3:GetObjectAcl",
"s3:GetObject",
"glue:GetPartition",
"glue:GetTables",
"glue:GetPartitions",
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload",
"athena:*",
"glue:GetDatabases",
"glue:GetTable"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::datalake-bukect-name/*",
"arn:aws:s3:::aws-athena-query-results-ap-northeast-1-xxxxxxxx/*"
]
},
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:xxxxxxxx:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:xxxxxxxx:log-group:/aws/lambda/*"
]
}
]
}
Lambdaで実行するPythonプログラム
上記を踏まえ完成したプログラムがこちらです。※一部伏せています
ちなみに取ってきたデータに対してはpandasライブラリを使いよしなに使い、カスタムメトリクスを送信する形式に整えています。
(丁度pandasを学習をしていたので良かった!!!)
lambda_function.py
import json
from datadog_lambda.metric import lambda_metric
from datadog_lambda.wrapper import datadog_lambda_wrapper
from pyathena import connect
import pandas as pd
@datadog_lambda_wrapper
def lambda_handler(event, context):
# 1時間前のcountry毎、device毎の接続数をカウントする。
sql = '''\
SELECT c.countryname,\
count(DISTINCT m.deviceid) device_cnt\
FROM ...\
WHERE ...\
GROUP BY 1\
'''
## Athenaクエリ結果保存先のS3を指定する。認証情報はIAMロールで当てているため記載していない。
conn = connect(s3_staging_dir='s3://aws-athena-query-results-ap-northeast-1-xxxxxxxxx/')
df = pd.read_sql(sql, conn)
# mccs_connection_count
metric = "mccs.connection.hour.count" ##mccsは弊社のデバイス名
for countryname,device_cnt in zip(df['countryname'], df['device_cnt']):
## 各国ごとにtagを付与しdatadogへ送信
country = 'country:' + countryname
value = device_cnt
lambda_metric(metric, value, tags=[country,"env:production"])
return {
'statusCode': 200,
'body': json.dumps('Successful push of metrics to Datadog')
}
ライブラリを使うためにLambdaにレイヤーを設定します。

バージョンが変わっていくので、ある日突然参照できなくなる事があるので、zipに固めたほうがいいかもしれない。
結果
こんな感じに過去のパターンから逸脱すると、アラートとなりSlackに通知が飛びます。
※諸々の事情から夜間の接続が落ちる国、落ちない国があります。
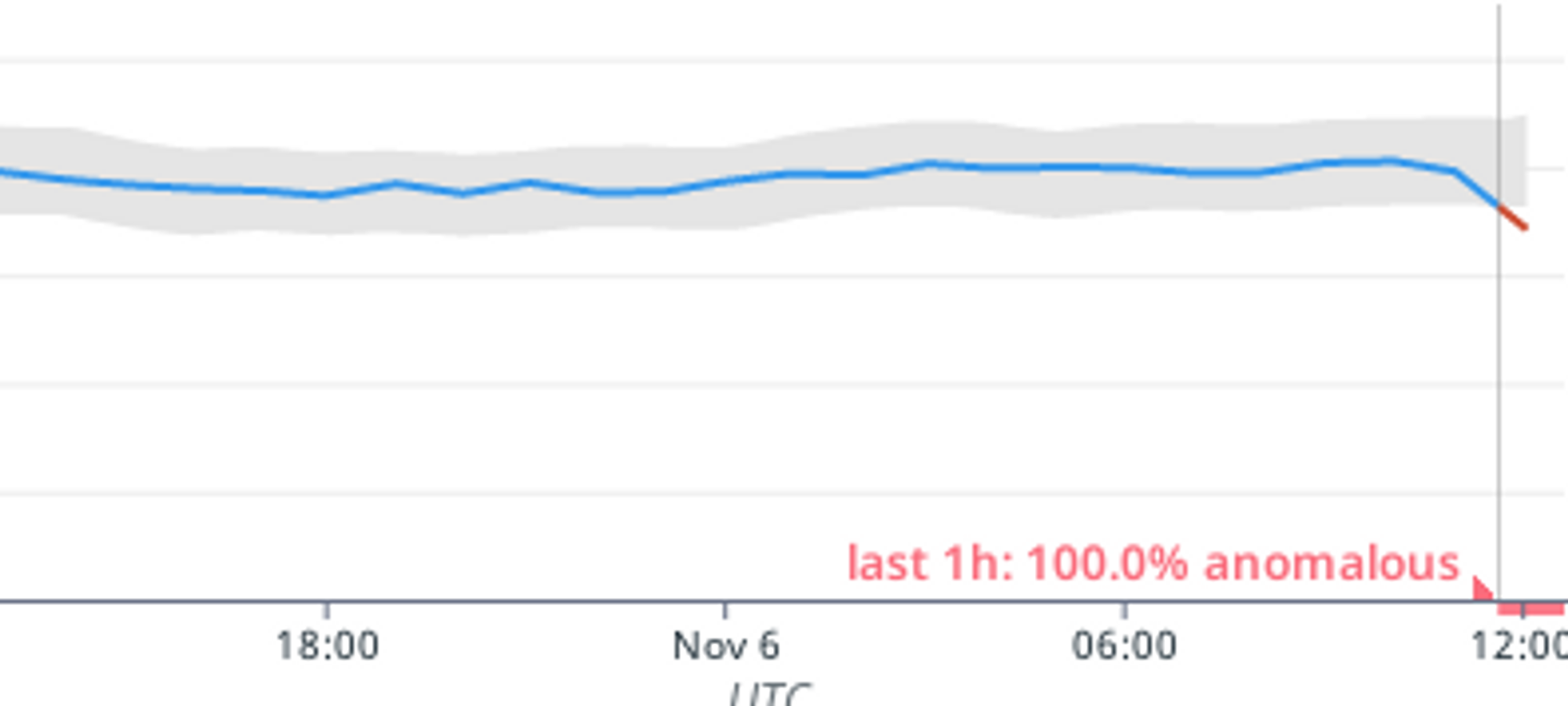
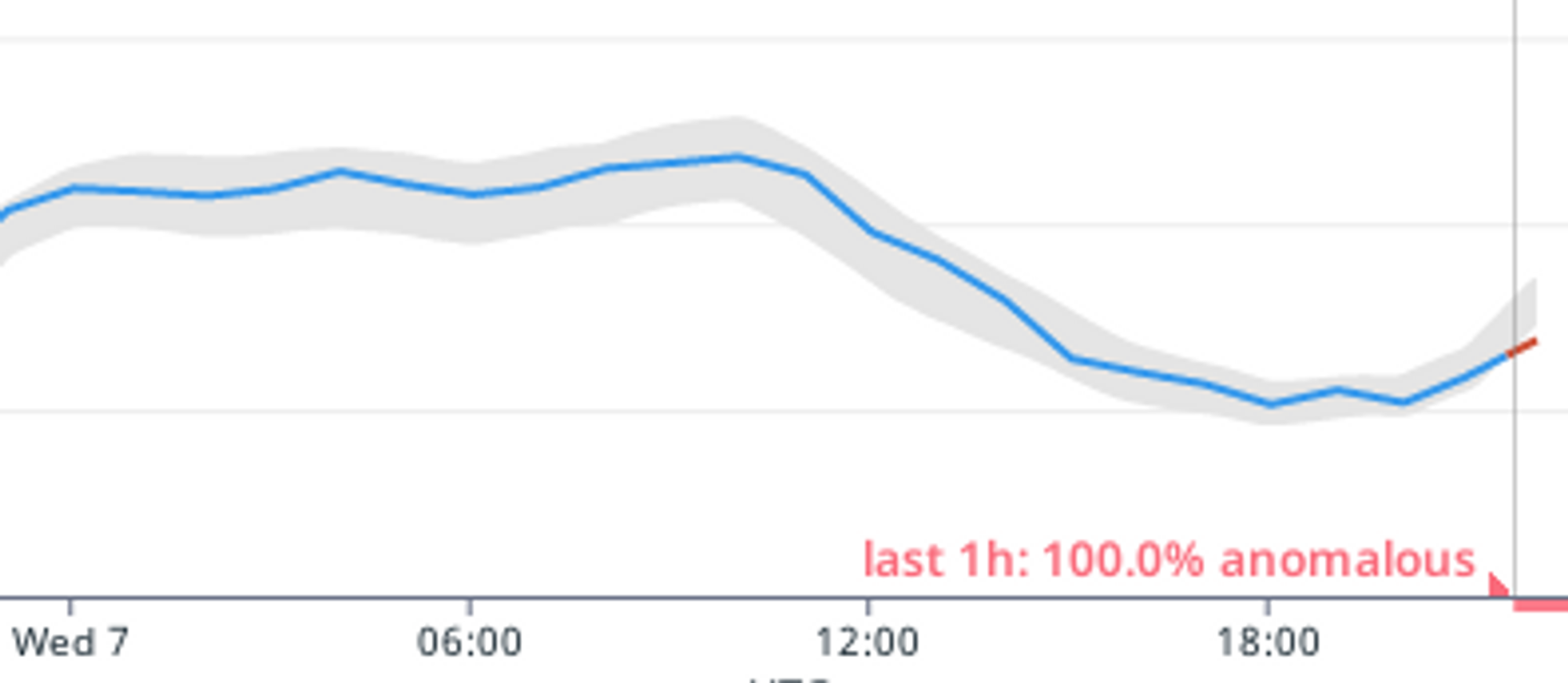
局所的な接続台数ダウンだと拾いきれない場合もごく稀にありますが、それなりの逸脱であればアラートとなります。
先述の通り、国によっては一部地域で通信障害になり、キャリアに連絡しないと対応が後回しにされたり、そもそもキャリアが気づいていなかったりすることもあるため、自発的に対応ができるようになったのはかなりサービス品質アップに貢献できたかなと思います。
やってることはシンプルなので記事にするか迷いましたが、ちょっとした集計値等をパターン監視したい場合に参考になれば幸いです。