こちらのアドベントカレンダーの記事です。
近々書くような気がするので、先駆けてアドベントカレンダー駆動で書いていきます。
スタートアップのデータ基盤に興味がある人には刺さるかもしれません。
TL;DR
- 2020年に構築した弊社のS3+Athena構成のデータ基盤の限界が近い
- 構築当時に比べてデータ基盤の選択肢色々増えて嬉しい
- 2024/1~3にかけてSnowflake or Redshift Serverlessの検証をします
現在のデータ基盤の構成
タイトルの通りS3 + Athenaを中心にAWSの細かいサービスを使っています
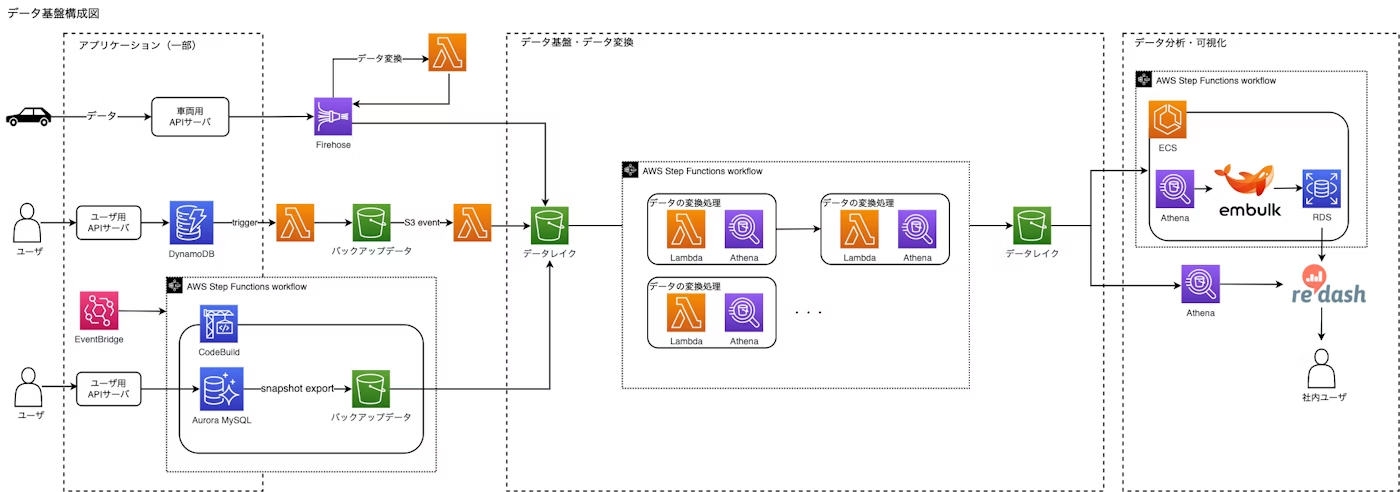
使用技術
- S3
- Athena
- Glue
- GlueETLは費用の面で使わず他のサービスを組み合わせる形で内製
- Firehose
- Lambda(Python)
- Codebuild
- Step Functions / EventBridge
- ECS on Embulk (Athena→MySQL or MySQL→MySQL)
- (図にはないが)AppFlowにてSalesforce→S3
- Redash
詳しくはこの記事や、登壇資料をご参照ください。改めて見ると複雑。。
グローバルIoTスタートアップにおける2年強に及ぶちょうど良いデータ基盤への歩み
現在の利用状況とか
- メインのIoTデータが数10億行ある
- データエンジニア(兼データアナリスト) 2人
- 自分 ※2021年にJoin。インフラと兼務
- マネージャー ※現在の基盤を構築した。現在はデータ基盤部分にはほとんど工数を割いてない。
- クエリを書く人
- コアメンバー 〜3人 ※データエンジニア2名+業務委託のアナリスト1名なので常時書いてるわけではない
- 書けるメンバー 〜10人 ※SQL勉強会を通じ事業サイドにも数名書ける人がいる
- まだまだRedashで不都合がない
- ダッシュボード利用状況
- まだまだ浸透が必要な部分はありますが、ある程度データ活用されています
- 経営会議の報告資料に使われている
- 事業内のKPIとして参照されている
- IoT端末の改善するために使われている
- まだまだ浸透が必要な部分はありますが、ある程度データ活用されています
- データマート層のRDSに格納した統計値をメインサービスで扱うようになった
データ分析環境の移り変わり
2020年当初はデータ分析基盤といってもそんなに選択肢が無かった気がします。
(自分は2021年からウォッチしだしたのであれですが)
だいたいこの3つの選択肢だったのではないでしょうか。
- S3 + Athena (+Glue)
- AWSを使っているスタートアップとかでそこまでパフォーマンス不要で費用優先
- Redshift
- AWSを使っていてお金に余裕がある
- BigQuery
- GCPを使ってる
- AWSを使っていてもS3 + Athena構成では満足できないor楽に構築したい
ちなみにこれより前になるとApache Hadoopが主流だったようなことを聞いたことがあります。
個人的な感覚ですが、徐々にAWSを使っているところでもBigQueryがベストプラクティスのようになり、TroccoなどのETLしてくれるSaaSが普及しシュッと作るならこれみたいなAWS使っててもBigQueryみたいな時期が2021-2022あたり
Snowflakeやdatabricksなどのデータ基盤専用の会社が目立ち始め、AWSでもRedshift Serverlessなども出てきてRedshift ProvisionedやBigQueryからの移行話も聞こえるようになってきたのがここ1年な気がします。
マテリアライズドビューなどが充実してきてETLではなくELTというのが現実味が増してきました。
(個人的にはリッチなBIの一分機能はここで満たされ、まだまだRedashを使い続けそうな気がします)
このあたりの情報は勉強会Data Engineering Study に大変助けられており、風音屋の横山さん(ゆずたそさん)、Troccoを提供しているprimeNumber 小林さんには感謝です。
そして最近DMBOKを買いました。分厚すぎる。。。(まだ数ページしか読んでない)
目まぐるしくデータ基盤のトレンドが変化する中、2022年は今更BigQueryではない気がするし、2023年は色々出てきてるな…でもそこまで大きな不満無いかも…という中で現在の構成につらみも徐々に出てきてそろそろ本格的に考えてもいいかもとなってきました。
ELTを始めとする魅力的な機能も増えつつ、コスト的にもそんなに変わらない”雰囲気”があり、もはや世のデータ基盤が成長してきたことで、移行しないほうが損な状況になった気がします。
現在の構成のつらみ
- ともかく間をつなぐLambdaやらCodebuildが多く、修正のときに触る箇所が多く認知負荷にも繋がっている
- 他のソフトウェアエンジニアにもテーブル追加時の反映などを任せたいが、任せにくく属人化している
- 自分自身最初は “完全理解”した状態で、修正を経てちょっとデキル状態に。
- メインのIoTデータの変換が複雑
- コンテナ→Firehose+Lambda(jsonをフラット化しParquet形式でS3に保存)→
Athenaでカラム追加やカラム名変更し使いやすい形に加工→
Embulkで集計値を再度RDSにinsert- window関数のlagを使う場面がありつつ、時系列データながら送信が遅れてくるデータもあり、そこを考慮していくとより沼になっていく。
- lagを使うと1件目がnullにることを構築時のクエリが考慮して無く、発覚時にAthenaで加工の部分を全件やり直すことになった。
- 諸々のETLも場合によっては全件作り直しが必要
- コンテナ→Firehose+Lambda(jsonをフラット化しParquet形式でS3に保存)→
- 件数が多いのでクエリの内容によってはいい感じに範囲を切らないと結果が来るまで、10分以上かかってしまう。
- 15分越えたあたりからAthenaの実行自体エラーになってしまうときもある
- 集計値は期間を区切って実行するETLを用意しないと出せない
- データ分析の成熟により高度な分析をするために、多数のwindow関数を使うようになりクエリコストが上がってきたのも大きい
次期データ基盤への移行検討
冒頭書いたように、2024/1~3にかけてSnowflake or Redshift Serverlessの検証をします
大体の基準
- 費用面
- できれば既存と同じくらいに収まって欲しい
- Athena → (ETL) → RDSをELTのマテリアライズドビューで無くしたい
- パフォーマンス、費用面、運用面
- たまに行うIoTデータに対しての重いクエリのレスポンスを早めたい
- (ELTのパフォーマンスが出れば大丈夫)
- どちらも自在にサイズを変えられるので大丈夫そう
- 属人性を減らしたい
- Lambda,Codebuildを減らしたい
- コードベースで容易にテーブル追加の反映をしたい(Glueカタログがつらい)
データ基盤って利用状況や内部のメンバーの構成によっても選択基準が変わってくるので選定が難しいなと思いつつ、そもそも限られた人(検証メンバーは自分のみ)、期間で決めきる必要があり、純粋に最近のデータ基盤に魅力を感じてワクワクする面もありつつ、決めるという億劫さもあります。
Athena → (ETL) → RDSの部分を置き換えられるかがかなりキーになってきます。パフォーマンス的に代替できるかという部分と、置き換えたときの費用がどっちが安いかという部分になります。ここが中々判断しにくそう。。。
Lambda,Codebuild周りは、今までAWS内に寄せてやってきたわけですし、できないこともない領域なので、Troccoなどのサービスを新たに入れる可能性は低い気がします。できれば基板側でややこしい変換を吸収してもらい自然となくなればいいなと思いつつ、前段の転送が残るのはやむを得ない気がします。
ぼちぼち検証項目とかを作っていくわけですが、それに先立ちましてアドベントカレンダー駆動でそれに被る部分を文章化しました。
おわりに
S3 + Athena構成を取っている企業は少数派で、登壇とかでは話題に上がらず、たまにテックブログなどで見かける程度で、心細さを感じていました。
先述のようにデータ基盤は企業によって重視する部分が全く異なり、まだまだデータエンジニアというコミュニティ自体も小さく探り探りやっている企業も多いような気がします。
弊社はこれから検証を始めていくタイミングですが、なにかの参考になれば幸いです。
ぜひコメントもお待ちしています(本記事のコメントやXにて)
移行が完了したあたりでまた書ければと思います。
弊社現在エンジニア採用しているので興味があれば覗いてみてください。