はじめに
先に、異なるシステムから、本来同じ意味を指すのにそれぞれ異なるコードが振られたトランザクションデータが発生するというシチュエーションにおいて、それらのコードを名寄せした話を投稿しました。Levenshteinのratioで文字列間の類似度を測り、コード変換マスタを作成するという話です。
その際、「ratio >= 0.4」としてマスタを作成するように設定しました。しかしこのパラメータの妥当性は、将来にわたって保証されるものではありません。今後投入されるトランザクションデータに、どういった値が入ってくるかが読めないからです。
そのため、パラメータ設定の妥当性をチェックを、場合によっては過去に遡って行なえる仕組みを構築する必要があり、本記事ではその際の話をしたいと思います。
なお、今回はDr.Sum成分が多めです。
元記事にも記載していますが、理想的には各システムでデータ入力時にバリデーションチェックを行なうべきです。今回は諸般の事情でそういったことはできないという前提でお読みください。
やるべきこと
目的は「パラメータ設定の妥当性をチェック」ですので、「ratio >= 0.4」の条件で絞り込む前の結果が欲しいところです。元記事から、コードと共に再掲します。
import pandas as pd
import Levenshtein as ls
df = pd.DataFrame(pd.read_csv('C:/temp/CROSS_JOIN.csv', dtype=object), columns=['地球連邦コード', '地球連邦会社名', 'ジオンコード', 'ジオン会社名'] )
df['distance'] = df.apply(lambda x : ls.distance(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
df['ratio'] = df.apply(lambda x : ls.ratio(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
print(df.drop_duplicates())

この内容で単純に蓄積していても意味不明なので、処理日列を追加します。
from datetime import datetime
now = datetime.now()
df['day'] = pd.to_datetime(now.strftime('%Y%m%d'))
print(df.drop_duplicates())

とりえあず最低限の情報はこれで出揃ったと思いますので、あとはこれをCSVファイルとして出力したものをDr.Sumの履歴テーブルに追加追加でインポートし、さらに「ratio >= 4」で絞り込んだ結果だけをコード変換マスタとして利用すれば良さそうです。
df.drop_duplicates().to_csv('C:/temp/Leven.csv')
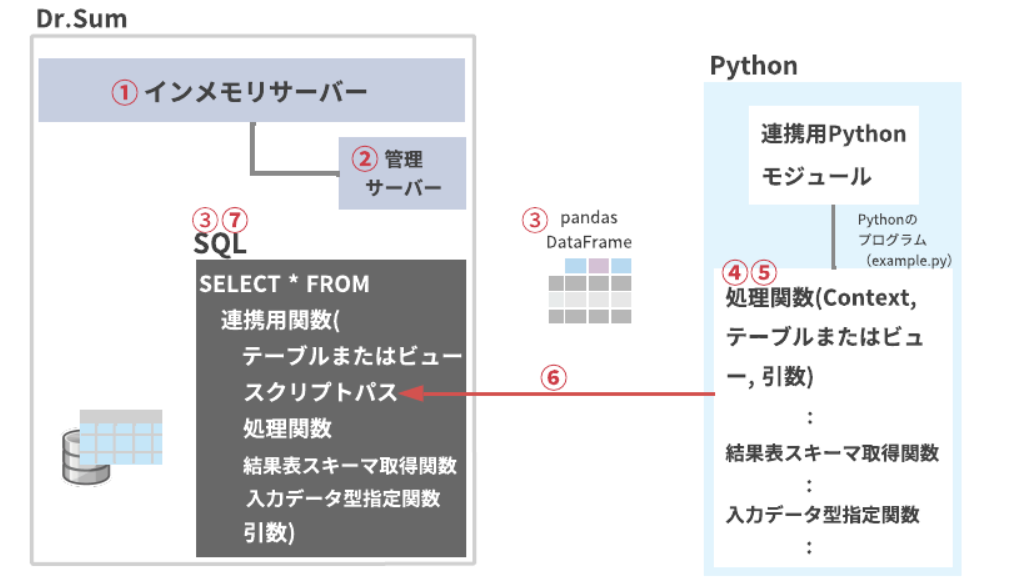
Dr.Sum ScriptとPythonの連携
と、ここまでやって、Dr.Sumの次の機能に気づきました。
ここまでのやり方では、
- 各システムのトランザクションデータから[会社名]と[コード]をCROSS JOINした結果をCSVファイルに出力
- CSVファイルをPandasでDataFrameとして読み込む
- Python-Levenshteinで会社名間の類似度を算出
- 処理日付を付加したDataframeをCSVとして出力
- CSVをDr.Sumで取り込んで履歴テーブルおよびコード変換マスタテーブルにインポート
という流れですが、この場合、1→2、および4→5の際に、前段処理でcsvが出力されるのを監視して、生成/更新されたタイミングで後続処理が実行されるようにする必要があります。csvファイル経由の疎結合ゆえですね。
システム屋としては、batでbatをcallするとか、JP1を使うとかの話になると思いますが、上記機能を使えばどうやらDr.Sum上でも全ての処理を同期的に実行できそうです。
今回のプロジェクトではDr.Sumをデータ分析基盤として利用していたので、Dr.Sum側に処理を寄せられるのなら都合が良いです。
Dr.SumとPythonの連携のPython側
Python連携機能については上記公式マニュアルの他、こういった記事もあります。ただし、私はPythonを使ったちゃんとしたシステム開発に明るくないので、デバッグやメイン関数はともかく、エミュレータとかスタブとか処理方式とかの用語が怒濤のように押し寄せ、正直ちんぷんかんぷんでした。
が、結論からすると、Dr.SumのSQLとPythonの二者間の世界においては、Python側に最低限「処理関数」と「結果表スキーマ取得関数」があれば大丈夫そうでした。
なので細かいところは無視するとして、今回はこの2つだけをPython側で記述します。
処理関数
処理関数のシグネチャは次のとおりです。
def <関数名>(context: Context, input: pandas.DataFrame, *args)
とくに引数として新たに渡したい値は無いので、実際の記述としては次のようになるでしょう。
def name_identification(context, input):
df = pd.DataFrame(input, columns=['地球連邦コード', '地球連邦会社名', 'ジオンコード', 'ジオン会社名'], dtype = 'object')
df['distance'] = df.apply(lambda x : ls.distance(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
df['ratio'] = df.apply(lambda x : ls.ratio(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
now = datetime.now()
df['day'] = pd.to_datetime(now.strftime('%Y%m%d'))
return df
これまでcsvファイルからDataFrameを作っていたのを、Dr.Sumから渡される「input」表に変更し、最後にDataFrame(df)をreturnします。
結果表スキーマ取得関数
次に、結果表スキーマ取得関数のシグネチャは次のとおりです。
def <関数名>(input_schema: List[<str>])
Dr.SumがPythonから結果表を受け取る際に、結果表のスキーマ情報が明示的に必要というわけですね。
def get_schema(input_schema):
return ['地球連邦コード VARCHAR', '地球連邦会社名 VARCHAR', 'ジオンコード VARCHAR', 'ジオン会社名 VARCHAR', 'distance NUMERIC', 'ratio NUMERIC', 'day DATE']
このように全カラムを列挙しても良いし、
def get_schema(input_schema):
return input_schema + ['distance NUMERIC', 'ratio NUMERIC', 'day DATE']
と、input表のスキーマ+追加カラムという形で定義しても良いようです。
Python側全体
全体としては、次のようになりました。
「コード名寄せ.py」として保存しておきましょう。
import Levenshtein as ls
import pandas as pd
from datetime import datetime
def name_identification(context, input):
df = pd.DataFrame(input, columns=['地球連邦コード', '地球連邦会社名', 'ジオンコード', 'ジオン会社名'], dtype = 'object')
df['distance'] = df.apply(lambda x : ls.distance(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
df['ratio'] = df.apply(lambda x : ls.ratio(x['地球連邦会社名'], x['ジオン会社名']), axis=1)
now = datetime.now()
df['day'] = pd.to_datetime(now.strftime('%Y%m%d'))
return df
def get_schema(input_schema):
return input_schema + ['distance NUMERIC', 'ratio NUMERIC', 'day DATE']
Dr.SumとPythonの連携のDr.Sum側
続いて、Dr.Sum側を作ります。Dr.Sum側は、「Dr.Sum Script」という機能を用いて作成します。
この機能については「データ準備作業で実施するバッチ処理やデータ加工処理を支援するためのプログラム群です」と説明があるのですが、Dr.SumにおけるPL/SQL(的なもの)という理解が私にはいちばんしっくりきました。
まずはDBへ接続します。
CONNECT("宇宙世紀DB") {
}
次に、CROSSJOINした結果表を、先ほどのコード名寄せ.pyで定義したLeven関数に渡します。Pythonにテーブルデータを渡すには、Dr.Sumのテーブル関数を使ったSQLを実行します。
ここのマニュアルを見ると、Pythonに渡すためのテーブル関数にはserial_py parallel_py grouped_parallel_pyの3つありそうです。これが「処理方式」に関係しているようで、字面を見ても、シリアルで処理するかパラレルで処理するかといったところのようですね。今回についてはパラレルで実行する必要性は感じないので、serial_pyを使います。
serial_pyの書式は次のとおりです。
udtf::serial_py(
<input> --Pythonに渡すDr.Sumのテーブル名
<py_file_path> --実行するPythonファイルパス
<func_name> --実行するPython側の処理関数名
[<schema_func_name>] --実行するPython側の結果表スキーマ取得関数名
[<sort_column>] --Pythonにテーブルデータを渡す際のソート項目を指定
[<input_py_type_func_name>] --実行するPython側の入力データ型指定関数名
[<args>] --実行するPython側の処理関数に渡す引数
[<additional_py_paths>] --実行するPython側でPythonファイルをimportする場合のPythonファイルのあるパス
) <エイリアス名>
省略可能な引数のうち、schema_func_nameは、結果表を受け取るために必要で、他は必要ありません。
SQL部分は次のように記述しました。CROSSJOINした「WITH1」テーブルをPythonに渡します。
WITH WITH1 AS
(
SELECT
DISTINCT
T1.コード AS 地球連邦コード,
T1.会社名 AS 地球連邦会社名,
T2.コード AS ジオンコード,
T2.会社名 AS ジオン会社名
FROM
地球連邦 T1
CROSS JOIN
ジオン T2
)
SELECT
地球連邦コード,
地球連邦会社名,
ジオンコード,
ジオン会社名,
distance AS レーベンシュタイン距離,
ratio AS レーベンシュタイン類似度,
day AS 処理実行日
FROM
udtf::serial_py
(
WITH1,
py_file_path='PY_SCRIPT_ROOT/コード名寄せ.py',
func_name='name_identification',
schema_func_name='get_schema'
) SQ
どのコマンドを使うべきか
さて、SQLは完成しましたが、これをどうするべきでしょうか。
最初に思ったのはSQLを実行して結果表を後続処理で利用する、もしくはSET_FROM_QUERYでテーブル型変数に投入して後続の処理で利用する、のいずれかでした。
ただ、SQLについては、クエリで受け取った結果表を後続で利用することができませんでした。おそらくSELECTではなくDELETE,INSERT,UPDATEあたりやDDLの使用が想定されていると思われます。また、SET_FROM_QUERYで投入できるテーブル型変数も、利用用途としてはほぼFOREACHなどのカーソル制御用のようで、SQLのFROM句に指定するなどの使い方はできませんでした。
そのため、いったんワークテーブルに入れるしかありません。EXPORT_WKがそれにあたります。
EXPORT_WKは、ワークテーブル名を生成する関数を併用して以下のように使用します。
SET() {
$temp1 = generate_wkname("work1");
}
EXPORT_WK($ENV_CURRENT_DB,
$work1,
$_EXPORT_MODE_TRUNCATE,
$_ERROR_MODE_INTERRUPTED,
$_TABLE_CREATE_MODE_NORMAL) {
--ここにSQLを記述する
}
ワークテーブルに結果表が投入されさえすれば、あとは単純に
- ワークテーブル→履歴テーブル(追加)
- ワークテーブル→コード変換マスタ(洗替)
の2つの処理を行なうだけです。
ちょっと長いですが、完成系がこちらです。
CONNECT("宇宙世紀DB") {
}
SET() {
$work1 = generate_wkname("work1");
}
EXPORT_WK($ENV_CURRENT_DB,
$work1,
$_EXPORT_MODE_TRUNCATE,
$_ERROR_MODE_INTERRUPTED,
$_TABLE_CREATE_MODE_NORMAL) {
WITH WITH1 AS
(
SELECT
DISTINCT
T1.コード AS 地球連邦コード,
T1.会社名 AS 地球連邦会社名,
T2.コード AS ジオンコード,
T2.会社名 AS ジオン会社名
FROM
地球連邦 T1
CROSS JOIN
ジオン T2
)
SELECT
地球連邦コード,
地球連邦会社名,
ジオンコード,
ジオン会社名,
distance AS レーベンシュタイン距離,
ratio AS レーベンシュタイン類似度,
day AS 処理実行日
FROM
udtf::serial_py
(
WITH1,
py_file_path='PY_SCRIPT_ROOT/コード名寄せ.py',
func_name='name_identification',
schema_func_name='get_schema'
) SQ
}
//SELECTの結果表を"コード名寄せ履歴"テーブルに追加で投入
EXPORT($ENV_CURRENT_DB,
"コード名寄せ履歴",
$_EXPORT_MODE_APPEND,
$_ERROR_MODE_INTERRUPTED,
$_TABLE_CREATE_MODE_NORMAL) {
SELECT
*
FROM
${work1}
}
//SELECTの結果表を"コード変換マスタ"テーブルに洗替で投入
EXPORT($ENV_CURRENT_DB,
"コード変換マスタ",
$_EXPORT_MODE_TRUNCATE,
$_ERROR_MODE_INTERRUPTED,
$_TABLE_CREATE_MODE_NORMAL) {
SELECT
地球連邦コード,
地球連邦会社名,
ジオンコード,
ジオン会社名
FROM
${work1}
WHERE
レーベンシュタイン類似度 >= 0.4
}
おわりに
Dr.Sum Scriptを使うと、Dr.Sum側でのインポートやデータ加工処理とPythonで行なう処理をシームレスに繋げることができるので、ジョブ管理ツールの用意が無くても、ジョブの管理がちょっと便利になります。
なお、本記事では「ratio >= 0.4」で絞り込む前の結果を全て蓄積することを「履歴の蓄積」と呼んでいますが、おそらくここまで読んでいただいた大半の方は「で、蓄積するだけしといてどうすんの?」と思われたことでしょう。それはそうです。
次回、そのあたりのことをお話しできればと思います。