やりたいこと
Dr.Sum ver.5.6からpython連携機能が追加されました。
Dr.Sumの中に入っている大量のデータを機械学習に突っ込むことができます。
今回は、scikits-learnライブラリのボストンの不動産価格サンプルを使ってDeep Neural Network (DNN)を使って価格を予測してみます。
※ 本記事はDr.Sumのpython 連携機能にフォーカスしているので手法についてはあまり触れません。
学習
スクリプト
Dr.Sumのpython連携機能では、SQL文からpythonの関数を実行します。
デバッグにはDr.Sum内のpython環境を利用する必要がありますが、少し横着をしてローカルのpython環境でデバッグできるようにしています。
import io
import pandas as pd
from sklearn.model_selection import train_test_split
import joblib
MODEL_SAVE_PATH_FOR_DEBUG = "./" # デバッグ中のモデルの保存場所
MODEL_STATUS_COLUMNS = ["parameter name", "value"] # アウトプットのカラム
SCHEMA = ['description VARCHAR', 'value VARCHAR'] # アウトプットのカラムが少なかったり、カスタマイズする場合は自分で作る。['カラム名 VARCHER/NUMERIC']のフォーマットで作成
# 結果表スキーマ取得関数
def model_status(input_schema):
return SCHEMA
# ODBC接続でDr.Sum内のデータをインポート
def import_data():
import pyodbc
con = pyodbc.connect(DRIVER="Dr.Sum 5.6 ODBC Driver",
HOST="nn.nn.nn.nn", DATABASE="DBNAME", trusted_connection="yes",
user="ID", password="PW", port = "6001"
)
TBL = "boston_train"
query = "SELECT * FROM {tbl} ;".format(tbl=TBL)
train_data = pd.read_sql(query, con)
return train_data
# 処理関数
def train(context, input, *args):
if(len(args) == 0):
args = [0, "relu", 10000]
elif(len(args) != 3):
raise Exception("Arguments were incorrectly set. Follow as args=[0,'relu',10000] or None. ")
# 訓練データとバリデーション用データを8:2で分割
X_train, X_val, y_train, y_val = train_test_split(
input.drop("MEDV", axis = 1).values,
input["MEDV"].values,
test_size=0.2, random_state=0
)
from sklearn.neural_network import MLPRegressor
# DNN回帰モデル
model = MLPRegressor(
solver="adam",
random_state=args[0],
activation = args[1],
learning_rate = "adaptive",
hidden_layer_sizes=(3,),
max_iter=args[2],
early_stopping = True
)
model.fit(X_train, y_train) # 学習
y_pred = model.predict(X_val) # 予測
score = model.score(X_val, y_val) # 評価
# アウトプットとなるdataframeを定義
model_status = pd.DataFrame(columns = MODEL_STATUS_COLUMNS)
# モデルのパラメータをアウトプットとして追加する。
for param_name, value in model.get_params().items():
model_status.loc[param_name] = [param_name, value]
# 訓練データでの決定係数及びバリデーション用のデータの決定係数をアウトプットに追加
model_status.loc["train data"] = ["train data", model.score(X_train, y_train)]
model_status.loc["validation data"] = ["validation data", model.score(X_val, y_val)]
print(model_status)
# モデルの保存
if(context.__class__.__name__ == "Context"): # SQLから実行された場合
stream = io.BytesIO()
joblib.dump(model, stream)
context.write_remote_file(f"PY_DATA_ROOT/model_DNN.sav", stream.getvalue())
else: # ローカルのpython環境から実行された場合=デバッグ中
filename = MODEL_SAVE_PATH_FOR_DEBUG + 'model_DNN.sav'
joblib.dump(model, filename)
return model_status
def main():
train_data = import_data()
result = train("dummy", train_data)
if __name__ == "__main__":
main()
SQL文は以下です。
SELECT
*
FROM
udtf::serial_py(
boston_train,
py_file_path='PY_SCRIPT_ROOT/train.py',
func_name='train',
args=[0, "relu", 10000],
schema_func_name='model_status'
) TU
SQL文からpythonが実行される際は、結果表スキーマ取得関数(model_status関数)と処理関数(train関数)が実行され、main関数は実行されません。
また、処理関数の第一引数にはContext型の変数が入ります(デバッグ中は"dummy"文字列を指定しています。)。
さらに、処理関数の第三引数にはパラメータをリスト形式で指定できます。参照する際にはargs[0]といった形で記述します。
今回のargsには[random_state=0, activation="relu", max_iter=10000]と指定しています。
実行
上記のpythonスクリプトを [Dr.Sum 5.6インストールフォルダ]\Server\samples\udtf-py\script 配下に置き、SQLを実行します。
出力には、モデルのパラメータを出力しています。
末尾に、学習データとバリデーションデータに対する決定係数を出力しています。
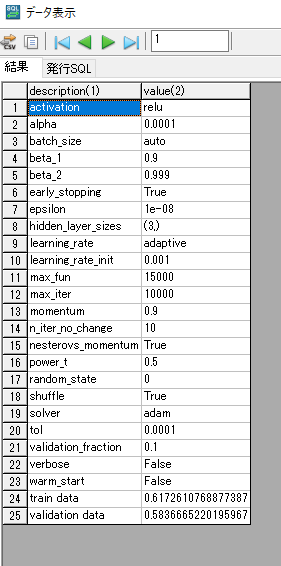
学習データでさえ決定係数が61とあまり精度は良くないです。。。
予測
スクリプト
保存したモデルをロードして予測するだけです。
import pandas as pd
import joblib, io
MODEL_SAVE_PATH_FOR_DEBUG = "./" # デバッグ中のモデルの保存場所
TARGET_COLUMN_SCHEMA = 'MEDV NUMERIC' # 目的変数のカラム名と型。['カラム名 VARCHER/NUMERIC']のフォーマットで作成
# 結果表スキーマ取得関数
def predict_schema(input_schema):
# 予測フェーズでは入力のスキーマに予測結果をくっつけるので、加工してスキーマにする
schema = []
for column in input_schema:
schema.append(column.split("(")[0])
schema.append(TARGET_COLUMN_SCHEMA)
return schema
# 本来は↓
# return ['CRIM NUMERIC', 'ZN NUMERIC', 'INDUS NUMERIC', 'CHAS NUMERIC', 'NOX NUMERIC', 'RM NUMERIC', 'AGE NUMERIC', 'DIS NUMERIC', 'RAD NUMERIC', 'TAX NUMERIC', 'PTRATIO NUMERIC', 'B NUMERIC', 'LSTAT NUMERIC', 'MEDV NUMERIC']
# Dr.SumとODBC接続して、boston_trainテーブルの内容を取り込む
def import_data():
import pyodbc
con = pyodbc.connect(DRIVER="Dr.Sum 5.6 ODBC Driver",
HOST="nn.nn.nn.nn", DATABASE="DBNAME", trusted_connection="yes",
user="ID", password="PW", port = "6001"
)
TBL = "boston_test"
query = "SELECT * FROM {tbl} ;".format(tbl=TBL)
test_data = pd.read_sql(query, con)
return test_data
def predict(context, input):
if(context.__class__.__name__ == "Context"): # SQLから実行された場合
load_stream = io.BytesIO(context.read_remote_file(f"PY_DATA_ROOT/model_DNN.sav"))
model = joblib.load(load_stream)
else: # ローカルのpython環境から実行された場合=デバッグ中
file_name = MODEL_SAVE_PATH_FOR_DEBUG + 'model_DNN.sav'
model = joblib.load(file_name)
y_pred = model.predict(input.values) # 予測
output = input.assign(MEDV = y_pred)
return output
if __name__ == "__main__":
test_data = import_data()
result = predict("dummy", test_data) # デバッグ中は第一引数はContextではないので、ダミーデータを入れる。
print(result)
SELECT
*
FROM
udtf::serial_py(
boston_test,
py_file_path='PY_SCRIPT_ROOT/predict.py',
func_name='predict',
schema_func_name='predict_schema'
) TU
実行
テスト用のデータに、予測値(MEDV)をくっつけたテーブルがアウトプットになります。

まとめ
Dr.Sum 5.6から追加されたpython連携機能を使って不動産価格を予測しました。
SQLで実行する際にパラメータ(args)を指定できるのはいいですね。
本来はエミュレータというDr.Sum内のpython独自で使えるライブラリを使ってデバッグします。(過去の記事をご参照)
おそらく推奨された方法では無いですが、一応ローカルのpython環境でもデバッグできます。