
TL;DR;
メトリクスを収集したりグラフやアラートを作成するたびにインフラエンジニア待ちになってしまう状況を打開するため、
アプリにPrometheusメトリクスエンドポイントを生やして、それをPrometheusやDatadogで自動発見・スクレープさせます。
この記事ではDatadogを使います。DatadogによるKubernetesモニタリング全般について知りたい方には、@spesnovaさんの「Monitoring Kubernetes with Datadog」をおすすめします。
お急ぎの方に: アプリ側の設定手順
この記事の中ほどに書きました!
Prometheusエンドポイントを生やして、Pod Annotationをつけるだけです。
まえおき1: なぜPrometheus"や"Datadogなのか
Prometheusといっても、Prometheus自体とPrometheusがスクレープしにくるメトリクス公開用エンドポイント(スクレープ対象のアプリの:24231/metrics)とは別なので、それを区別して説明します。
Prometheusエンドポイントは簡単に生やせる
まず、Datadogにはdogstatsdにstatsdメトリクスを送るというメトリクス収集方法が標準で用意されていますが、それなのにあえてPrometheusエンドポイントを用意する理由の一つは、Prometheus関連の充実したライブラリを利用して簡単にメトリクスを公開するためです。
例えば、golang製のGRPCサーバの場合、go-grpc-prometheusというミドルウェアを組み込むだけでスループット等のメトリクスを自動的に計測して公開してくれます。
特定ベンダのメトリクス公開・収集仕様にロックインされない
もう一つの理由がこれです。
例えばDatadogを採用するとした場合、Datadognメトリクス収集エージェント(dogstatsd)のプロトコルdogstatsdは、statsdの機能を一部落として拡張したものです。そのため、dogstatsdでメトリクスを集めるインフラを組んでしまった場合、Datadog以外に移行するのが難しくなってしまいます。少ない労力でベンダーロックインを避けられるなら、それに越したことはないですよね。
そういう意味では、バックエンドはPrometheusでも他のSaaSでもなんでもよくて、Prometheusメトリクスを技術的に、または現実的な手間でスクレープできるようなバックエンドを採用するとよいでしょう。その具体例が、PrometheusやDatadogです。
Auto-Discovery機能の有無
オートスケーリングが当たり前の環境や、Microservicesアーキテクチャと各チームがインフラをセルフサービスするような環境にある場合、監視対象のアプリケーションは日常的に増減します。そのたびにインフラエンジニアが呼び出されて、モニタリングシステムの設定ファイルなどを変更するのは面倒ですよね?
Auto-Discovery機能のあるモニタリングシステムを採用すれば、アプリケーションが増減したタイミングでメトリクスの収集対象を自動的に追加・削除してくれます。より具体的には、今回はPrometheusメトリクスを公開するアプリをKubernetes上で運用する前提なので、Podが増減したらそのPrometheusメトリクスを自動的に収集してほしいということになります。
DatadogやPrometheusにはAuto-Discovery機能があります。
Datadog: https://docs.datadoghq.com/guides/autodiscovery/
後述しますが、Prometheusには任意のアプリのメトリクスを自動スクレープするような機能は2017/12現在存在しないようです(まだ信じられないので、実はあるということであればどなたかご指摘いただければと)。
この記事を公開した時点では、PrometheusにはAuto-Discovery機能がないと書いていたのですが、間違いでした。実際には、Service DiscoveryをPodに対して有効化するという方法があるようです。(@shmurata さん情報より。ありがとうとございます!)
参照: https://qiita.com/mumoshu/items/9fb7988ccbefa88b61cd#comment-99d56d5b415e574a758a
まえおき2: なぜPrometheusよりDatadogか
メトリクス、トレース、ログを一つのサービスで一元管理したい・運用工数を節約したい
Prometheusを採用する場合、例えば
- 基本的なグラフ作成とメトリクス収集、アラート設定はPrometheus
- 分散ログはEKF(Elasticsearch + Kibana Fluentd)
- 分散トレースはZipkinやJaeger
というような構成になると思います。
これはもちろんソフトウェアライセンス費用・サポート費用、将来の拡張性などの意味では良い判断だと思います。
一方で、
- アラートを受けたときに、その原因調査のために3つもサービスを行ったり来たりするのは面倒
- 人が少ない場合にセルフホストしてるサービスの運用保守に手間をかけたくない
などの思いもあると思います。
そういう場合にあえてSaaSを採用するという判断はありえます。
2017/12現在、Prometheusのマネージドサービスの定番は存在しないため、そういう場合にはDatadog一択になってしまいます。
dd-agentのセットアップ手順
dd-agentのインストール
dd-agentのhelm chartはかなり機能も多く良くできているので、それを使います。
参照: Datadog AgentをKubernetesにインストールするときのベスト・プラクティス - Qiita
Prometheus checkのインストール
今回利用するPrometheus checkはdd-agentに同梱されていないので、何らかの形でdd-agentにインストールする必要があります。幸い、dd-agentを再作成しなくてもConfigMapから任意のCheckをロードさせることができるので、その方法を使います。
$ curl -o prometheus.py https://raw.githubusercontent.com/latency-at/datadog-agent-prometheus/master/check.d/prometheus.py
$ k get configmap datadog-datadog-checksd -o yaml> datadog-datadog-checksd.configmap.yaml
$ k create configmap datadog-datadog-checksd --dry-run -o yaml --from-file prometheus.py | k apply -f -
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
configmap "datadog-datadog-checksd" configured
カスタムcheckをdd-agentにロードさせるために、一旦dd-agentを再起動します。
$ kubectl delete pod $(k get po | grep datadog-datadog | cut -d ' ' -f 1)
スクレープ対象のメトリクスを見てみる
Prometheus EndpointはHTTPで、基本的には/metricsのパスでメトリクスを公開するので、試しにcurlで何が公開されているのか、本当に公開されているのかを確認してみます。
まず、適当なPodを起動してcurlをインストールして、
root@xenial-1512636123:/# apt-get update -y && apt-get install curl
対象のPod IPを確認して、
$ k get po -o wide | grep fluentd
fluentd-cloud-logging-7630p 1/1 Running 0 2m 10.2.37.28 ip-10-0-0-221.ap-northeast-1.compute.internal
fluentd-cloud-logging-9mwxs 1/1 Running 0 4m 10.2.91.80 ip-10-0-0-26.ap-northeast-1.compute.internal
fluentd-cloud-logging-fgs52 1/1 Running 0 4m 10.2.23.121 ip-10-0-0-82.ap-northeast-1.compute.internal
fluentd-cloud-logging-hr309 1/1 Running 0 2m 10.2.63.82 ip-10-0-0-140.ap-northeast-1.compute.internal
fluentd-cloud-logging-llhm6 1/1 Running 0 4m 10.2.6.24 ip-10-0-0-47.ap-northeast-1.compute.internal
対象PodIP:/metricsに対してHTTP GETリクエストを送ってみます。
root@xenial-1512636123:/# curl 10.2.37.28:24231/metrics
# TYPE fluentd_status_buffer_queue_length gauge
# HELP fluentd_status_buffer_queue_length Current buffer queue length.
fluentd_status_buffer_queue_length{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",plugin_category="output",type="datadog_log"} 0.0
fluentd_status_buffer_queue_length{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",plugin_category="output",type="datadog_log"} 0.0
# TYPE fluentd_status_buffer_total_bytes gauge
# HELP fluentd_status_buffer_total_bytes Current total size of queued buffers.
fluentd_status_buffer_total_bytes{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",plugin_category="output",type="datadog_log"} 7235.0
fluentd_status_buffer_total_bytes{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",plugin_category="output",type="datadog_log"} 0.0
# TYPE fluentd_status_retry_count gauge
# HELP fluentd_status_retry_count Current retry counts.
fluentd_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",plugin_category="output",type="null"} 0.0
fluentd_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",plugin_category="output",type="datadog_log"} 0.0
fluentd_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",plugin_category="output",type="datadog_log"} 0.0
# TYPE fluentd_output_status_buffer_queue_length gauge
# HELP fluentd_output_status_buffer_queue_length Current buffer queue length.
fluentd_output_status_buffer_queue_length{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 0.0
fluentd_output_status_buffer_queue_length{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_buffer_total_bytes gauge
# HELP fluentd_output_status_buffer_total_bytes Current total size of queued buffers.
fluentd_output_status_buffer_total_bytes{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 7235.0
fluentd_output_status_buffer_total_bytes{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_retry_count gauge
# HELP fluentd_output_status_retry_count Current retry counts.
fluentd_output_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 0.0
fluentd_output_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 0.0
fluentd_output_status_retry_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_num_errors gauge
# HELP fluentd_output_status_num_errors Current number of errors.
fluentd_output_status_num_errors{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 0.0
fluentd_output_status_num_errors{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 0.0
fluentd_output_status_num_errors{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_emit_count gauge
# HELP fluentd_output_status_emit_count Current emit counts.
fluentd_output_status_emit_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 18.0
fluentd_output_status_emit_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 92.0
fluentd_output_status_emit_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_emit_records gauge
# HELP fluentd_output_status_emit_records Current emit records.
fluentd_output_status_emit_records{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 18.0
fluentd_output_status_emit_records{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 548.0
fluentd_output_status_emit_records{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_write_count gauge
# HELP fluentd_output_status_write_count Current write counts.
fluentd_output_status_write_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 0.0
fluentd_output_status_write_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 30.0
fluentd_output_status_write_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_rollback_count gauge
# HELP fluentd_output_status_rollback_count Current rollback counts.
fluentd_output_status_rollback_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 0.0
fluentd_output_status_rollback_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 0.0
fluentd_output_status_rollback_count{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
# TYPE fluentd_output_status_retry_wait gauge
# HELP fluentd_output_status_retry_wait Current retry wait
fluentd_output_status_retry_wait{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04fd9fa3c",type="null"} 0.0
fluentd_output_status_retry_wait{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b8d3494",type="datadog_log"} 0.0
fluentd_output_status_retry_wait{host="fluentd-cloud-logging-7630p",plugin_id="object:3fb04b9396f4",type="datadog_log"} 0.0
Podに所定のAnnotationをつける
今回はPrometheusチェックを使うので、Prometheusチェックを自動設定するようなAnnotationをつける。
DatadogのAutoDiscovery一般のAnnotationの書き方は公式ドキュメントにあります。
今回利用するPrometheusチェックを利用する場合は、以下のようなAnnotationになります。基本的に、アプリによらずこの内容をそのまま書けば問題ないはずです。
piVersion: extensions/v1beta1
kind: ...
metadata:
# ...
spec:
template:
metadata:
# ...
annotations:
service-discovery.datadoghq.com/fluentd-cloud-logging.check_names: '["prometheus"]'
service-discovery.datadoghq.com/fluentd-cloud-logging.init_configs: '[{}]'
service-discovery.datadoghq.com/fluentd-cloud-logging.instances: '[{"target":"http://%%host%%:24231/metrics"}]'
Annotationを付与する場合のハマりどころ
ひとつ注意点として、Datadogのエージェントである通称dd-agentは、以下のタイミングでオートディスカバリーを実行します。
- 新たにPodが作成されたとき
- dd-agentが起動・再起動したとき
裏を返すと、以下のタイミングではオートディスカバリーが実行されません。
- すでにあるPodをkubectl edit/applyなどで変更したとき
そのため、annotationはPod作成時につけましょう。Pod作成後につけた場合、Podを一度削除して作り直せばオートディスカバリが発動します。
dd-agentのprometheus checkが有効化されているか見てみる
Auto Discoveryが動作した場合、自動的にPrometheus checkが有効化されるはずなので、それを確認する。
dd-agentでどのようなcheckが動いているかはdatadog-agent infoコマンドをコンテナ上で実行するとわかる。
dd-agentは通常DaemonSetで1ホストあたり1 Podスケジュールしてあるはずなので、以下のように全dd-agentに対してコマンドを実行して確認する。
$ for pod in $(k get po | grep datadog | cut -d ' ' -f 1); do echo pod: $pod; k exec -it $pod -- sh -c 'service datadog-agent info | grep prometheus -C 3'; done
pod: datadog-datadog-4vplw
Defaulting container name to datadog.
Use 'kubectl describe pod/datadog-datadog-4vplw' to see all of the containers in this pod.
2017-12-07 13:49:39,786 | WARNING | dd.collector | utils.service_discovery.config(config.py:31) | No configuration backend provided for service discovery. Only auto config templates will be used.
Checks
======
prometheus (custom)
-------------------
- instance #0 [OK]
- Collected 32 metrics, 0 events & 0 service checks
2017-12-07 13:49:40,449 | WARNING | dd.dogstatsd | utils.service_discovery.config(config.py:31) | No configuration backend provided for service discovery. Only auto config templates will be used.
pod: datadog-datadog-8nwzv
Defaulting container name to datadog.
Use 'kubectl describe pod/datadog-datadog-8nwzv' to see all of the containers in this pod.
Checks
======
prometheus (custom)
-------------------
- instance #0 [OK]
- Collected 32 metrics, 0 events & 0 service checks
*snip*
prometheus (custom)が今回利用したPrometheus checkなので、それがChecks以下に表示されていて、instance #0が [OK]となっていて、"Collected xx metrics"のように収集したメトリクス数が非ゼロになっていればOK。
Checks以下にprometheus (custom)があれば良い理由は、そもそもAuto Discoveryの過程で何がエラーが出て(その場合、collector.logにエラーがでているはず。詳細は本記事の最下部「トラブルシューティング」を参照)いたら、ここにprometheusが表示されないはずだからです。
また、instance #0が[OK]となっている必要がある理由は、今回annotationで一つだけcheckを指示したので、そのただ一つのcheckのインデックスが0だからです。
そして、"Collected xx metrics"の数値が非ゼロになっていれば良い理由は、checkが実行されて、正常にPrometheus endpointにアクセスできていて、Prometheus endpointが一つ以上メトリクスを公開しているのであれば、この値が増えているはずだからです。増えていないということは何かエラーが起きているか、エンドポイントはあるがメトリクスが一つも公開されていない、というようなことしか考えられません。
Datadogにメトリクスが届いていることを確認する
DatadogのMetrics Explorerで今回スクレープするメトリクス名を部分一致で検索してみます。
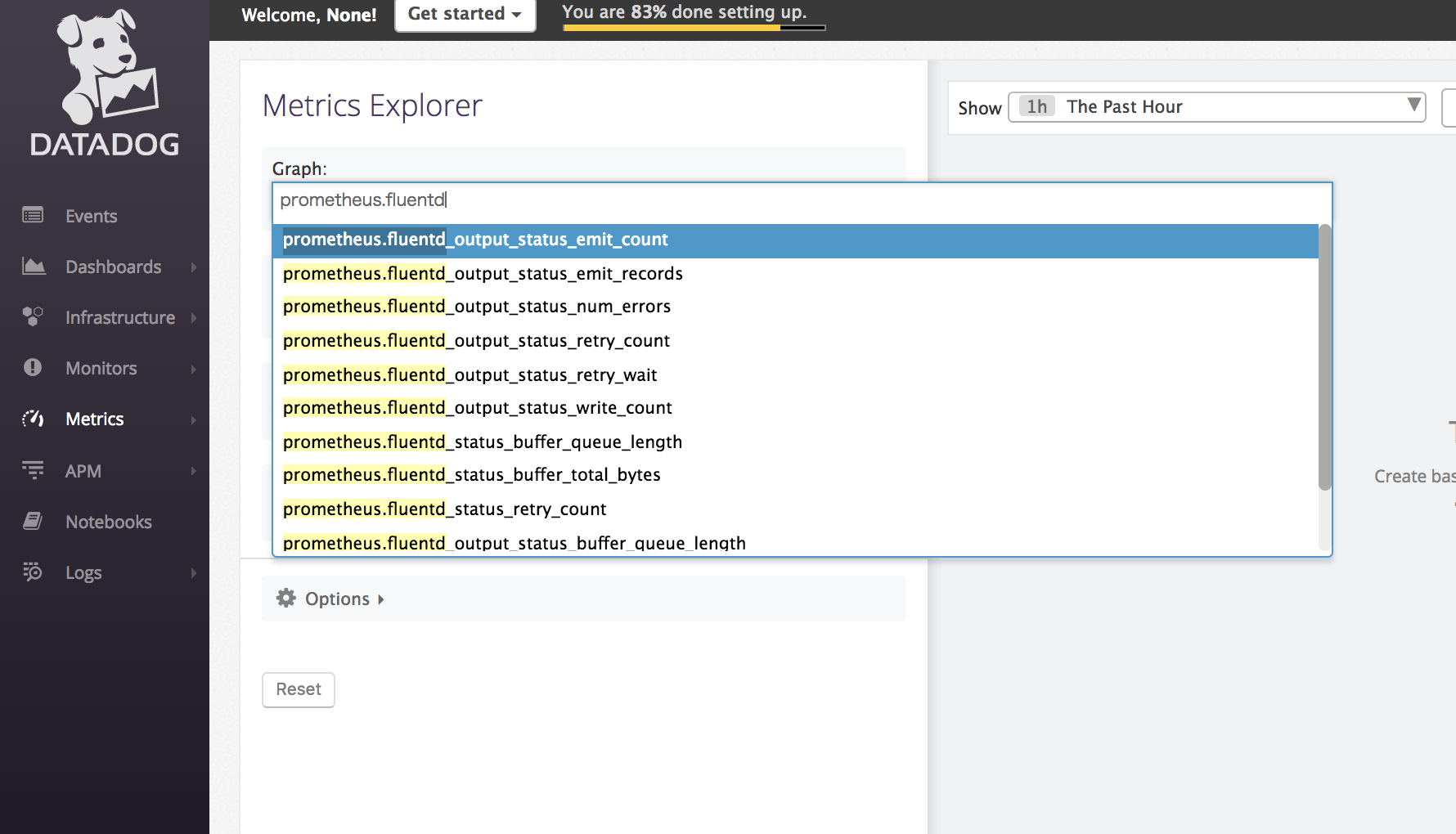
このようにメトリクス名の補完候補が出るのであれば、その名前のメトリクスがDatadogに送られてきているということは確かなので成功。
Datadogに届いたメトリクスをグラフにしてみる
Metrics ExplorerのGraph欄で今回送信したメトリクスをすべて選択してグラフにしてみます。
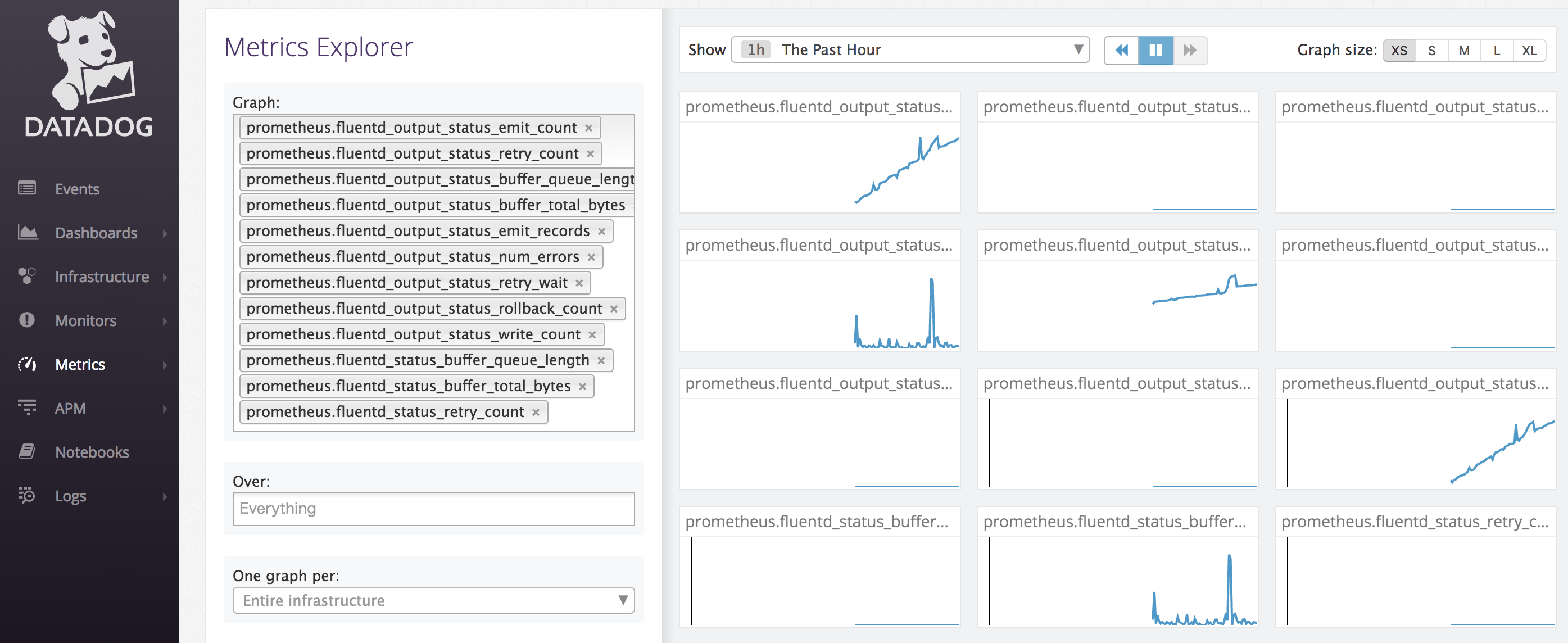
想定したグラフが描画されていれば、意図どおりアプリのメトリクスをdd-agentに自動発見・スクレープさせることができたといえます。
Datadogならではの機能を活かす
Datadogの特徴の一つは、メトリクスのタグ付けの柔軟性です。
※Prometheusにはrelabellinという機能があって、メトリクスのメタデータであるlabel(Datadogのtagに相当)をスクレイプ時につけ直すことができます。kubenetes_sd_configでも利用できるのですが、設定方法を確認した限りでは、任意のlabelを一律でつける方法は、調べた限りでは存在しないようです(?)
たとえば、あるdatadog-agentが収集するメトリクスには一律でenv:testとkube_cluster:myclusterのようなタグをつけることができます。それぞれ、「test環境のメトリクスだけ絞り込みたい」「myclusterというKubernetesクラスタにデプロイされたアプリからのメトリクスだけ絞り込みたい」というユースケースを実現できて便利です。
Pod Annotationを利用する場合
Prometheus Checkの実装であるprometheus.pyにこのPRの変更を適用した上で、以下のような実装で実現できます。
# ...
spec:
# ...
template:
metadata:
annotations:
service-discovery.datadoghq.com/fluentd-cloud-logging.check_names: '["prometheus"]'
service-discovery.datadoghq.com/fluentd-cloud-logging.init_configs: '[{}]'
service-discovery.datadoghq.com/fluentd-cloud-logging.instances: '[{"target":"http://%%host%%:24231/metrics",
"tags":["env:test","kube_cluster:mycluster"]}]'
dd-agentレベルで設定する場合
dd-agentコンテナのTAGSという環境変数にkey1:val1,key2:val2のような文字列を設定すれば実現できます。
まとめ
Datadogを使ってアプリのメトリクスを自動的にスクレープする方法を説明しました。
アプリ側はPrometheusエンドポイントを生やして、KubernetesのPodに所定のAnnotationをつけるだけという簡単さです。メトリクスを収集するためだけにいちいちインフラエンジニアが呼び出されることもなくなって楽になりますね!
一方のDatadogは親しみやすいUIのおかげで、誰でもグラフやアラートの作成ができます。こちらもグラフやアラートの作成をするたびにインフラエンジニアが登場する必要がなくなり楽になりますね!
サービス、アプリケーション監視のセルフサービス化を進めたい方は、ぜひ試してみてください。
付録: トラブルシューティング
PrometheusメトリクスがDatadogに取り込まれない
Prometheusチェックはdd-agentのcollectorというコンポーネントによって実行されるので、dd-agentのcollector.logに何かエラーが出ていないか確認してみてください。
$ for pod in $(k get po | grep datadog | cut -d ' ' -f 1); do echo pod: $pod; k exec -it $pod -- sh -c 'cat /var/log/datadog/collector.log | tail -n 30'; done
collector.logにCould not decode the JSON configuration template for the entity ``
所定のannotationでJSONが書かれていることが期待される場所に、JSONとしてパースできない内容が入ってしまっている場合のエラー。
2017-12-07 12:54:31 UTC | WARNING | dd.collector | utils.service_discovery.config(config.py:31) | No configuration backend provided for service discovery. Only auto config templates will be used.
2017-12-07 12:54:31 UTC | WARNING | dd.collector | utils.service_discovery.config(config.py:31) | No configuration backend provided for service discovery. Only auto config templates will be used.
2017-12-07 12:54:31 UTC | WARNING | dd.collector | collector(kubeutil.py:277) | Couldn't find the agent pod and namespace, using the default.
2017-12-07 12:54:31 UTC | ERROR | dd.collector | utils.service_discovery.abstract_config_store(abstract_config_store.py:238) | Could not decode the JSON configuration template for the entity mumoshu/kube-fluentd:1.0.0-0.9.10-rc.17...
Traceback (most recent call last):
File "/opt/datadog-agent/agent/utils/service_discovery/abstract_config_store.py", line 230, in _extract_template
check_names = json.loads(source_dict[key_prefix + CHECK_NAMES])
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/simplejson/__init__.py", line 505, in loads
return _default_decoder.decode(s)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/simplejson/decoder.py", line 370, in decode
obj, end = self.raw_decode(s)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/simplejson/decoder.py", line 400, in raw_decode
return self.scan_once(s, idx=_w(s, idx).end())
JSONDecodeError: Expecting ',' delimiter or ']': line 1 column 14 (char 13)
2017-12-07 12:54:36 UTC | WARNING | dd.collector | checks.docker_daemon(docker_daemon.py:641) | Unable to report cgroup metrics: Cannot report on bogus pid(0)
3つのannotationの値にJSONエラーがないか調べてみましょう。
collector.logにConnectionError: HTTPConnectionPool(host='10.2.63.85', port=24321): Max retries exceeded with url: /metrics
instances annotationに記載したスクレープ先のポート番号が違う場合のエラー(この例だと、24321ではなく、正しくは24231)
Traceback (most recent call last):
File "/opt/datadog-agent/agent/checks/__init__.py", line 795, in run
self.check(copy.deepcopy(instance))
File "/etc/dd-agent/checks.d/prometheus.py", line 68, in check
instance=instance)
File "/etc/dd-agent/checks.d/prometheus.py", line 48, in process
content_type, data = self.poll(endpoint, headers=headers)
File "/opt/datadog-agent/agent/checks/prometheus_check.py", line 301, in poll
req = requests.get(endpoint, headers=headers)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/requests/api.py", line 70, in get
return request('get', url, params=params, **kwargs)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/requests/api.py", line 56, in request
return session.request(method=method, url=url, **kwargs)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/requests/sessions.py", line 475, in request
resp = self.send(prep, **send_kwargs)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/requests/sessions.py", line 596, in send
r = adapter.send(request, **kwargs)
File "/opt/datadog-agent/embedded/lib/python2.7/site-packages/requests/adapters.py", line 487, in send
raise ConnectionError(e, request=request)
ConnectionError: HTTPConnectionPool(host='10.2.63.85', port=24321): Max retries exceeded with url: /metrics (Caused by NewConnectionError('<requests.packages.urllib3.connection.HTTPConnection object at 0x7fa268bb7f90>: Failed to establish a new connection: [Errno 111] Connection refused',))
補足: Prometheusではできないの?
ちょっと信じがたいけど、少なくともDatadogほどの気軽さではできないみたい?
NodeやWell-KnownなKubernetesコンポーネントを自動発見するようなものは機能もIssueもあったが、ユーザがデプロイした任意のアプリのメトリクスを自動発見するものが見つけられなかった。
きっとできるようになるとは思いますが、今のところDatadog一択です。
この記事を公開した時点では、PrometheusにはAuto-Discovery機能がないと書いていたのですが、間違いでした。実際には、Service DiscoveryをPodに対して有効化するという方法があるようです。(@shmurata さん情報より。ありがとうとございます!)
参照: https://qiita.com/mumoshu/items/9fb7988ccbefa88b61cd#comment-99d56d5b415e574a758a
以下、調べたことを貼っておくので、どなたか詳しい方補足いただけるとうれしいです ![]()
-
KubernetesのPrometheus DiscoveryというIssue
-
PrometheusにKubernetes Discoveryという機能が以前追加された
- これはnodeやpodのメトリクスを自動的に発見、スクレープできるという話
- podで動くアプリケーションプロセスのメトリクスを自動的に発見する仕組みはない
-
SOでPrometheusのpushgatewayをアプリケーションのsidecarにして、そこから送れば、という提案があるが、Prometheus開発者は推奨していない
- あと、自動発見とはいえない
補足: 今後の課題
今回利用したPrometheus checkはカスタムタグに対応していないようなので、メトリクスをPod名やDeployment名などのKubernetesならではのメタデータで検索・絞込・まとめたりすることができません。Datadogの良さはカスタムタグに柔軟に対応してくれることなので、これでは片手落ちな感じ・・・。
Issueはあるので、気になる方は+1をお願いします ![]()