著者: 伊藤 雅博, 株式会社日立製作所
はじめに
機械学習システムを継続的に運用するための取り組みとしてMLOps (Machine Learning Operations)が注目を集めています。MLOpsの運用サイクルの1ステップとして、機械学習を利用したいシステムに対して、機械学習モデルを用いた予測機能を提供するサービング(Serving)があります。
サービングは、データサイエンティストが作成した機械学習モデルを本番環境へ導入する際に、必ず求められる要件です。本投稿では、機械学習システムの全体像とサービングの位置づけ、およびサービングシステムの構成を紹介します。
機械学習システムの全体像
MLOpsを考慮した機械学習システムの例を以下の図に示します。
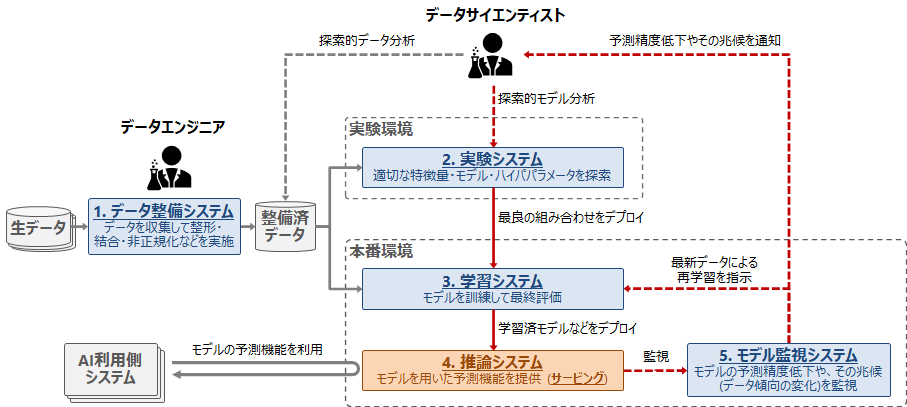
図の機械学習システムは、下記5つのサブシステムから構成されます。
1. データ整備システム
データ整備システムでは、機械学習に必要な生データを収集して、集約・結合・非正規化などを行い、データサイエンティストがデータを扱いやすいように整備します(いわゆるデータエンジニアリング)。ここでは、大量のデータを加工するためのデータ処理基盤や、データを蓄積して提供するためのデータレイク・データウェアハウスの整備が必要となります。
2. 実験システム
実験システムでは、データサイエンティストが実験を繰り返して、機械学習モデルの作成に必要な特徴量、モデル、ハイパパラメータなどを探索します。実験では、整備済みのデータから特徴量の作成に必要な項目を抽出したり(探索的データ分析)、適切なモデルの選択・モデルのハイパパラメータ探索・モデルの訓練と検証(探索的モデル分析)などを行います。実験時のソースコードや検証結果は実験管理システムに記録していきます。
3. 学習システム
実験で優秀なモデルが作成できたら、そこで使用した特徴量とモデル、ハイパパラメータなどを使用して、モデルの最終的な訓練を行います。訓練したモデルはテストデータで最終評価を行い、評価指標に問題がなければ推論システムにデプロイします。
4. 推論システム(サービング)
推論システムでは、機械学習を利用したい外部システムに対して、機械学習モデルを用いた予測機能を提供(サービング)します。本投稿では、このサービングについて詳しく紹介していきます。
5. モデル監視システム
一般的にモデルの予測精度は時間が経過するにつれて低下するため、定期的な再学習が必要となります。そのためには、モデルの予測精度の低下やその兆候(入力データ分布の変化など)を監視する仕組みが必要となります。また、予測精度が低下してきたらアラートを上げたり、最新データでモデルを再学習する仕組みも必要となります。
機械学習システムを継続的に運用するためには、上記のような運用サイクルを回せるシステムを構築する必要があります。この一連の運用サイクルを実現する取り組みがMLOpsです。
MLOpsを実現するためのプラットフォーム
MLOpsを実現できる統合的な機械学習プラットフォームはいくつか存在します。例えばクラウドサービスのAmazon SageMaker、Azure ML Services、Google AI Platformなどです。OSSではKubernetes環境向けのKubeflowがあります。
なお、本投稿では上記のようなプラットフォームは使用せず、小規模なシステムを想定して、個別のOSSを組み合わせたシンプルなサービング方式を紹介します。
OSSの主要なサービングフレームワーク
機械学習モデルのサービングに必要な機能を持つフレームワーク(以下、サービングFW)を紹介します。サービングFWは大きく分けて、機械学習フレームワーク(以下、機械学習FW)に付属するものと、複数の機械学習FWに対応したものがあります。
機械学習FWに付属する主要なサービングFWを以下に示します。
| サービングFW | 対応する機械学習FW/フォーマット |
|---|---|
| TensorFlow Serving | TensorFlow |
| TorchServe | PyTorch |
複数の機械学習FWに対応した主要なサービングFWを以下に示します。
| サービングFW | 対応する機械学習FW/フォーマット |
|---|---|
| Openscoring | PMML |
| Multi Model Server | MXNet, ONNX など |
| NVIDIA Triton Inference Server | TensorFlow, PyTorch, ONNX-Runtimeなど |
| BentoML | scikit-learn, TensorFlow, PyTorch, XGBoost など |
| Cortex | scikit-learn, TensorFlow, PyTorch など |
| Redis-AI (Redis上で動作) | TensorFlow, PyTorch, ONNX-Runtime など |
| KFServing (Kubernetes上で動作) | scikit-learn, TensorFlow, PyTorch, XGBoost, ONNX-Runtime など |
| Seldon Core (Kubernetes上で動作) | scikit-learn, TensorFlow, PyTorch, XGBoost など |
ただし、用途によってはサービングFWは多機能すぎることも多いです。また、KFServingやSeldon Coreを導入する場合はKubernetesクラスタが必要となります。なお、本投稿では上記のようなサービングFWは使⽤せず、個別のOSSを組み合わせたシンプルなサービング⽅式を紹介します。
推論システムの構成
サービングを行う推論システムには以下の要素が必要です。
- 学習済みの機械学習モデル
- 学習済みモデルに入力する特徴量作成の処理
- 外部システムから学習済みモデルを利用するためのインタフェース(I/F)
推論システムで学習済みモデルを利用する際は、学習時と同じ形式に変換したデータを入力する必要があります。つまり、推論システムでは学習済みモデルに加えて特徴量作成の処理も必要となります。
学習時と予測時で特徴量作成の処理を共通化するには、下記2種類の方法があります。
- 特徴量作成処理を学習・推論システムの外側に配置して共通化する
- 特徴量作成処理と学習済みモデルの組を推論システムに移植する(本投稿で紹介する方法)
前者の方法では、データ整備システム側で特徴量作成して特徴量ストア(Feature store)に格納しておき、そこから学習・推論システムにデータを提供します。
後者の方法では、学習システムで作成した特徴量作成処理と学習済みモデルの組を「予測パイプライン」として抽出して、推論システムに移植(デプロイ)します。本投稿では、この方法を紹介します。
まとめると、推論システムに必要な要素は、以下の2点となります。
- (1) 予測パイプラインの作成とデプロイ
- (2) 予測機能を提供するインタフェース
推論システムに必要な構成要素を以下の図に示します。
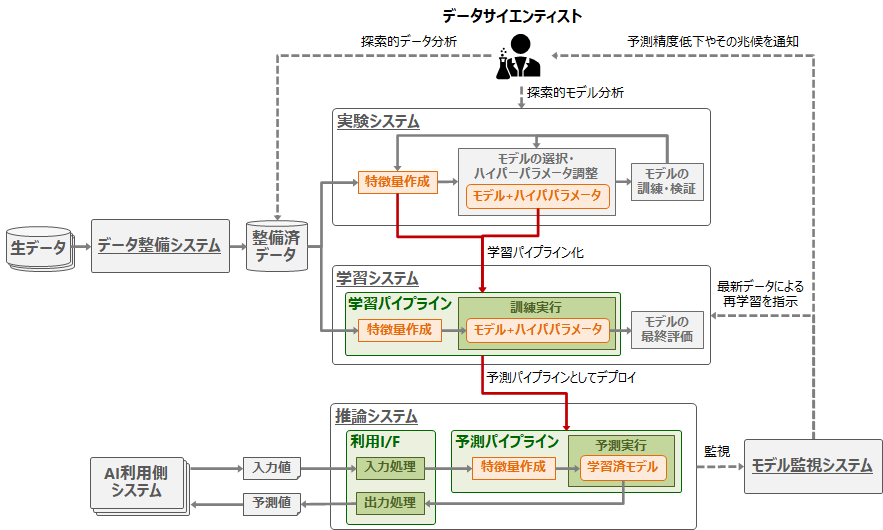
(1) 予測パイプラインの作成とデプロイ
予測パイプラインの作成方法
最初に、実験システムで作成した特徴量作成処理と学習済みモデルの組を「学習パイプライン」として抽出して、学習システムで訓練・評価します。そして、訓練済みの学習パイプラインを「予測パイプライン」として推論システムにデプロイします。
予測パイプラインの作成方法は、学習と推論で使用する機械学習FWの組み合わせによって以下のように変わります。
学習と推論で同じ機械学習FWを使用する場合
一番簡単なのは、機械学習FWの機能を使用して、モデルに特徴量作成処理を追加した予測パイプラインを作成する方法です。この方法が可能である主要な機械学習FWを以下に示します。これらの機械学習FWでは、モデルへの入力データに対する前処理として、特徴量作成処理を組み込むことが可能です。
|機械学習FW|方法|
|:---|:---|:---|
|scikit-learn|scikit-learn pipelineという機能で任意の前処理をモデルに組み込み可能|
|TensorFlow|tf.functionという機能で任意の前処理をモデルに組み込み可能|
|PyTorch|torch-model-archiverツールでモデルと任意の前処理をまとめて、TorchServeというサービングFWにデプロイ可能|
|Spark ML|Spark ML pipelinesという機能で任意の前処理をモデルに組み込み可能|
どの機械学習FWを使用すべきかは用途によります。例えば学習対象が数値データならscikit-learn、画像や音声データなら深層学習が可能なTensorFlowやPyTorchが広く使用されています。学習に必要なデータ量が膨大な場合は、並列分散処理が可能なSparkが必要となることもあります。
学習と推論で異なる機械学習FWを使用する場合
学習時と推論時で異なる機械学習FWを利用したい場合もあります。例えば、学習用データ量が膨大なためSparkでモデルを学習したが、Sparkクラスタの維持コストは高いため、推論は単体のサーバで実施したいケースです。なお、学習と違い推論処理は状態を持たないため、大量のデータを推論処理したい場合はサーバの台数を増やすだけで処理を並列化できます。
学習時と推論時で異なる機械学習FWを利用する場合は、予測パイプラインを機械学習向けのフォーマットに変換するか、ランタイム化して推論システムに移植します。
以下に主要な機械学習向けフォーマットを示します。PMMLは、1997年に公開された機械学習モデル向けのフォーマットで、モデルと前処理・後処理をXMLで表現できます。PFAは、2015年公開されたPMMLの後継となるフォーマットであり、モデルと処理をJSON/YAMLで表現します。例えばPMMLの場合、Sparkクラスタで学習したSpark ML pipelinesを、JPMML-SparkMLというツールを利用してPMML 形式で出力すれば、Openscoring というJava製のRESTサーバでサービングできます。
| フォーマット | 機械学習FWと変換ツール | 推論実行基盤 |
|---|---|---|
| PMML (Predictive Model Markup Language) | Spark (JPMML-SparkMLで変換)、scikit-learn、R、XGBoost、LightGBMなど多数 | Openscoring (Java製のREST I/F付サーバ)など多数 |
| PFA (Portable Format for Analytics) | Spark (Aardpfarkで変換)、scikit-learn (Titusで変換)、R (Aureliusで変換)など | Hadrian (Scala(JVM)で実行)、Titus (Pythonで実行) |
以下に主要な機械学習向けランライムの一覧を示します。ONNXはニューラルネットワーク向けのランタイムであり、2018年にMicrosoftがOSS化しました。MLeapは、元々Spark向けに開発されたランタイムであり、現在はAmazon SageMakerでも使用されています。
| ランタイム | 機械学習FW | 推論実行基盤 |
|---|---|---|
| ONNX(Open Neural Network Exchange) | scikit-learn、TensorFlow、PyTorchなど多数 | ONNX Runtime (Python/C#/C/C++で実行)、ONNX Runtime Server (C++製の高性能サーバ) |
| MLeap | Spark、scikit-learn、TensorFlowなど | MLeap Runtime (Scalaで実行)、MLeap Serving (Spring Bootで実行) |
なお、いずれのフォーマット/ランタイムも、機械学習FWがサポートする全種類のモデルに対応しているとは限らないため注意が必要です。
予測パイプラインのデプロイ方法
モデルを定期的に再学習する場合、推論システムを止めずに何度もデプロイできる仕組みがあると便利です。予測パイプラインのソースやバイナリを手動でそのまま移植することも可能ですが、予測パイプラインの作成とデプロイを自動化する場合は、いわゆるCI/CDの仕組みが必要となります。
(2) 予測機能を提供するインタフェース
学習済みモデルを利用するシステムに対して、予測機能を提供するインタフェースを用意する必要があります。ここでは、以下の4つの推論方式に合わせたインタフェースを紹介します。
- バッチ推論
- リアルタイム推論
- ストリーミング推論
- エッジ推論
バッチ推論
バッチ推論では、蓄積した大量データをまとめて予測処理を行います(例:日次バッチ処理)。この場合、データをRDB(PostgreSQL、MySQLなど)やCSVファイルに蓄積しておき、それを推論システムが読み出して処理します。この場合、RDBやファイルシステムが推論システムとのインタフェースとなります。以下にバッチ推論システムの例を示します。
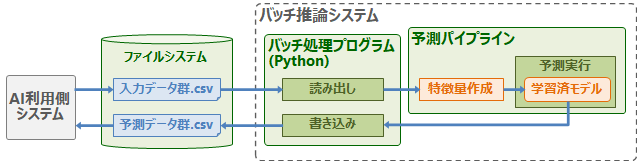
リアルタイム推論
リアルタイム推論では、1~数件のデータから即座に予測結果を取得します(例:Web広告)。予測をリアルタイムに行うため、予測機能を低レイテンシで利用できるWeb API(REST/gRPCなど)のようなインタフェースが必要となります。以下にリアルタイム推論システムの例を示します。
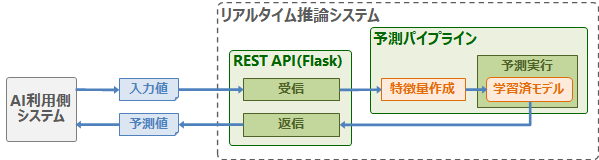
ストリーミング推論
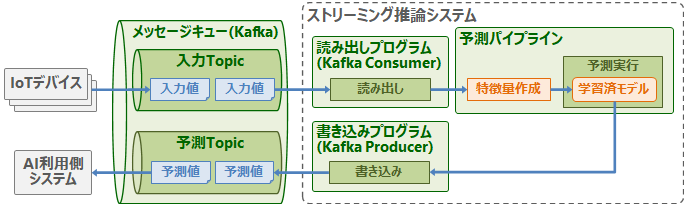
ストリーミング推論では、大量発生するデータを順次予測処理します。これはリアルタイム推論と異なり非同期処理となります(例:センタデータからの異常検知)。この場合、メッセージキュー(MQTT/Kafka/Redisなど)などをインタフェースにします。以下にストリーミング推論システムの例を示します。大量のIoTデバイスが生成するセンサデータに対してリアルタイムに異常検知処理を行いたい場合、センサデータを一旦メッセージキューで受け止めて、それを非同期に推論処理します。
エッジ推論
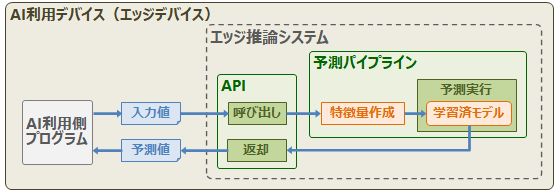
エッジ推論では、センサやモバイル機器に推論システムを直接組み込むことで、ネットワーク介さず即座に予測結果を取得します(例:スマートフォンのカメラによる顔認識)。推論処理をエッジデバイスに組み込む場合は、APIを用意して予測パイプラインのプログラムを呼び出します。
おわりに
本投稿では、MLOpsの運用サイクルの1ステップであるサービングについて紹介しました。サービングでは予測パイプラインの構築・デプロイと、予測パイプラインを利用するためのインタフェースが必要となります。
次の投稿では、実際にscikit-learn pipelinesとFlaskを使用してリアルタイム推論システムを構築する例を紹介します。