はじめに
- 本記事では、2025/7/17(米国時間)にオラクル社により発表されたSQLcl搭載のMCPサーバについてご紹介します。
- こちらの記事での使用方法はあくまでも一例となりますので、他の使用方法などにご興味がある場合は公式マニュアルをご覧ください。
SQLclとは
SQLclとは、Oracle DB向けのJavaベースのコマンドライン・インターフェースです。
Oracle DBを普段から使用している方は通常コマンドラインより操作を行う場合、SQL*Plusを用いた接続を行うことが多いと思いますが、SQLclでは従来のSQL*Plusの仕様を内包しつつ、インライン修正、履歴保存機能の強化等々、複数の機能を内包した上位互換のインターフェースとなります。
MCPサーバとは
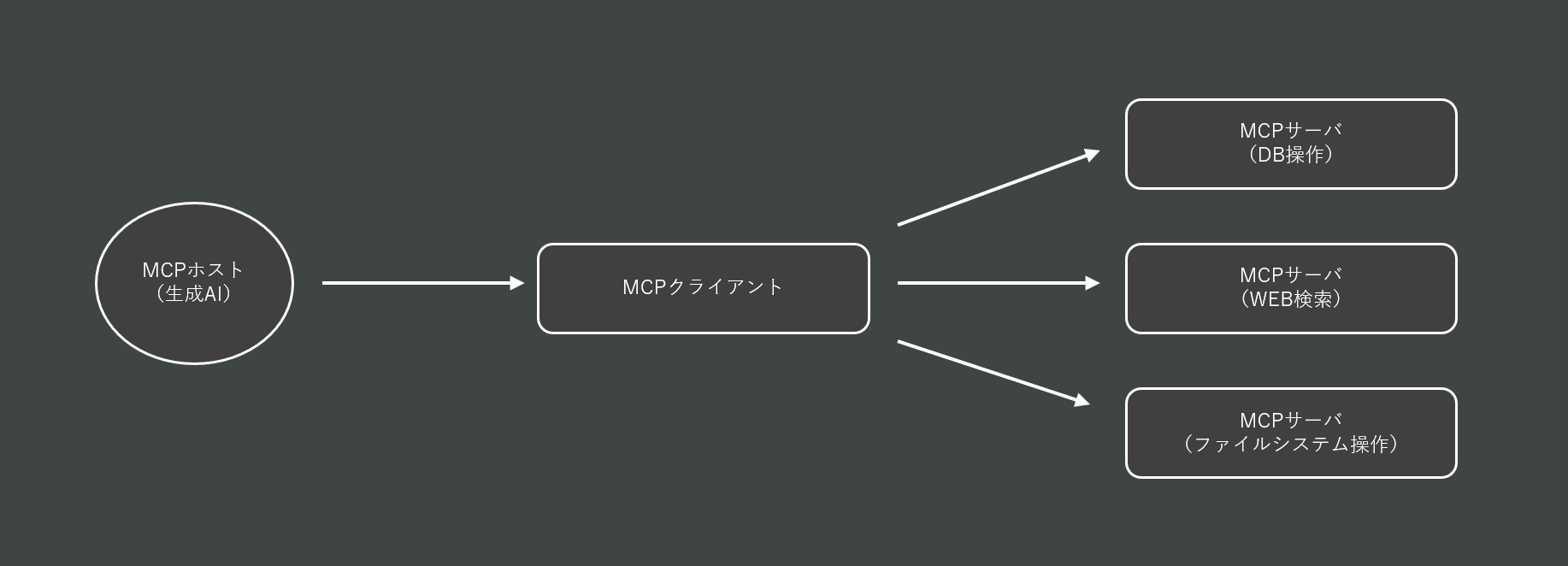
MCPとはModel Context Protocolの略であり、生成AI(エージェント)が最終回答を生成するまでに必要となるコンテキストの提供を補助するプロトコルのことです。
MCPの登場により、外部ツールとの連携が各段に行いやすくなり、生成AI(エージェント)による複雑なタスク処理が今まで以上に容易に実行できるようになりました。
MCP登場以前では、生成AI(エージェント)に対して「指定のDB内の情報を取り出したうえでその値を書き換え、VIEWを作成しなさい」といった内容を投げたとしても生成AI(エージェント)自身で実行することはできませんでした。(他の外部サービスを使用する場合は自前で事前に実装する必要がありました)
しかし、MCP登場後はこの個所の連携を自動で行ってくれる機能がサーバより提供されるようになったため、上記のような質問を投げかけたとしても正常に動作し、最終的なVIEWの作成まで行ってくれるようになりました。
SQLclにおいて提供されるMCPサーバについて

MCPサーバ内にて提供される機能は1つではありません。各サーバは1つ以上の関数(TOOL)を提供しており、生成AIはそのTOOL群のDESCRIPTION(説明文)を読むことで適切なTOOLを組み合わせて使用しています。
SQLclにて提供されているTOOLは以下の通りです。
| TOOL名 | 説明文(翻訳) |
|---|---|
| list-connections | マシンに保存されているすべての Oracle データベース接続を検出し、一覧表示します。 |
| connect | 指定した名前付き接続の 1 つへの接続を確立します。 |
| disconnect | 現在アクティブな Oracle データベース接続を終了します。 |
| run-sql | 接続されたデータベースに対して標準の SQL クエリと PL/SQL コード ブロックを実行します。 |
| sqlcl | SQLcl 固有のコマンドと拡張機能を実行します。 |
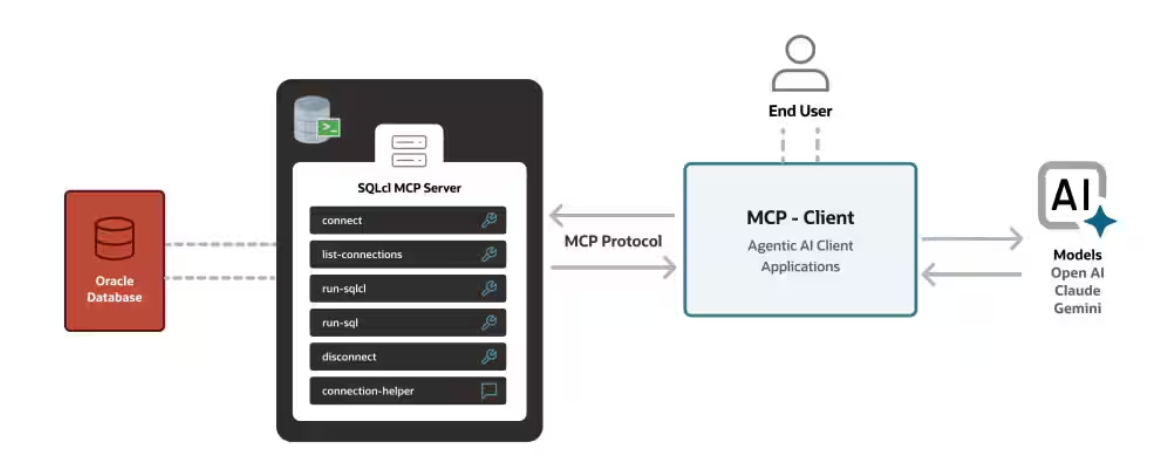
また、Oracle社のブログページでは下記の画像にて説明が行われています。生成AIの位置が上記の画像と左右逆になっていますが、どちらも同じことを意味しているため、見比べて理解を深めていただければと思います。
環境説明
- Python(ver.3.11)実行環境(OCI Data Science)
※Compute Serverのjupyter notebookと同義の環境 - DB(Autonomous Database 23ai)
- 生成AI(OCI 生成AIサービス[cohere.command-a-03-2025])
- SQLcl(ver.25.2.2)
- JDK(ver.21)
※SQLcl自体の使用はJavaのversionが11以上であれば使用可能ですが、mcpサーバの機能は17以上でないと使用不可のため、17以上のversionをインストールしています。
Javaのインストール
まずはJavaのインストールから開始します。OCI Data Scienceではデフォルトでver.11のJavaがインストールされていますが、このままではMCPサーバが機能しないため、必要なversionをインストールします。
bash
# デフォルトのJavaのversionを確認
java -version
# 使用可能なjdkのversionを確認
sudo dnf search jdk
# 出てきた中で17以上のversionを選択してインストール(※今回はOracle社のver.24をインストール)
sudo dnf install oracle-java-jdk-release-el8.x86_64 -y
sudo dnf install jdk-24-headful.x86_64 -y
# Javaのバージョン確認
java -version
※この際にversionが11より変化していない場合のみ、以下のコマンド実行
# JavaのPath変更によるバージョン変更
sudo alternatives --config java ★複数選択肢が表示されるため、適切なものを数字で指定する
java -version
SQLclのインストール
Javaのインストール完了後、SQLclのインストールも行います。
bash
# wgetコマンドを用いて/tmp配下に最新のSQLclをダウンロード
sudo wget https://download.oracle.com/otn_software/java/sqldeveloper/sqlcl-latest.zip -P /tmp
# zipファイルの権限変更
sudo chmod 777 /tmp/sqlcl-latest.zip
# datascienceユーザ(デフォルト・ユーザ)のホーム・ディレクトリにてzipファイル解凍
※datascienceユーザの所有物として解凍するため、sudoは不要
unzip /tmp/sqlcl-latest.zip -d /home/datascience
# 解凍確認
cd /home/datascience&&ls -l
Autonomous Databaseの接続確認
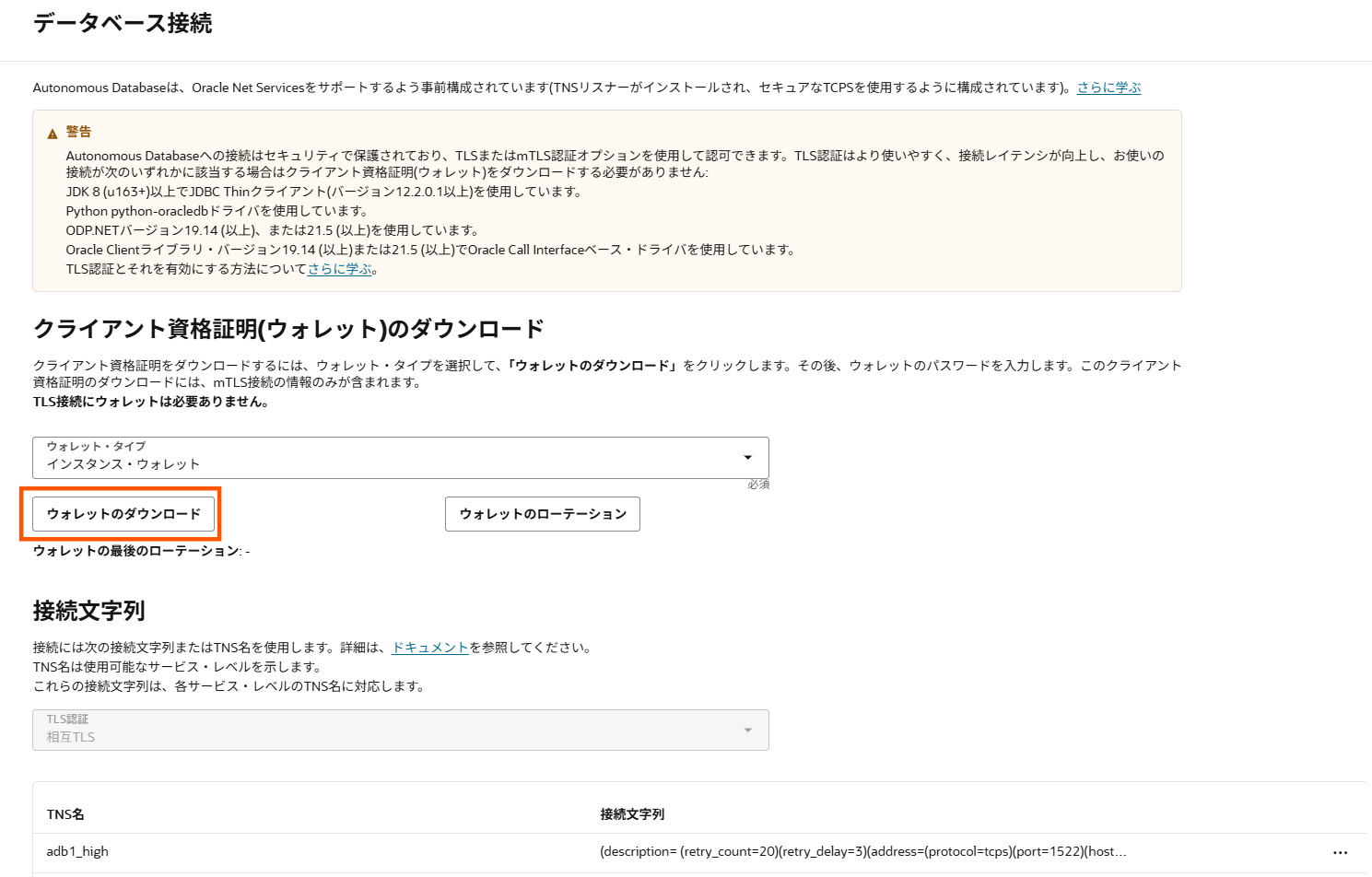
Autonomou Database(以下、ADB)に接続するためにはWALLETが必要になるため、ADBのページの「データベース接続」を押下し、WALLETのダウンロードを行います。
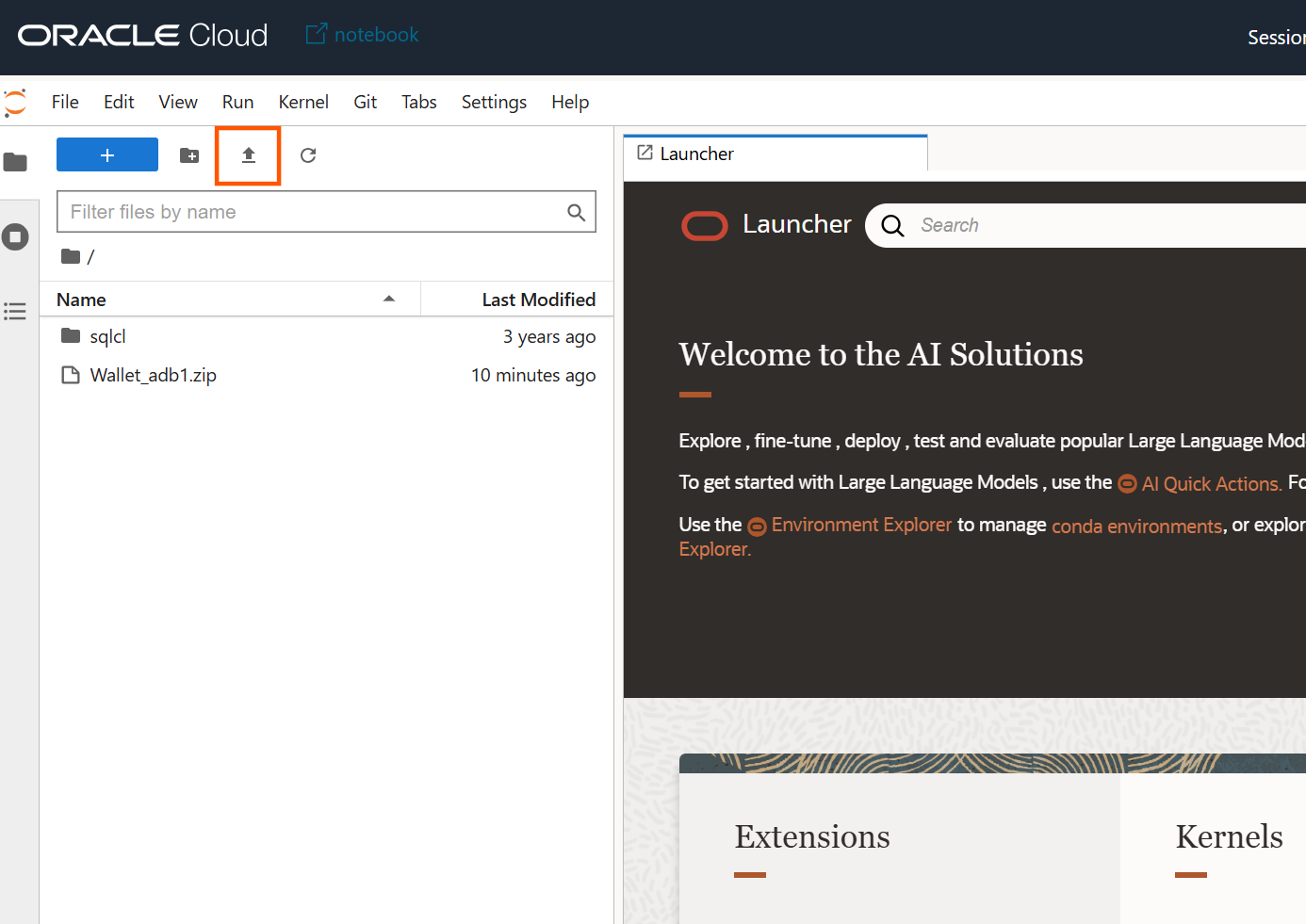
ダウンロードしたWALLETはOCI Data Scienceのページ左側のボタンよりアップロードします。
アップロードが完了すると、下画像の通り、画面上にWALLETのzipファイルが表示されます。
準備が整ったため、SQLclのクライアントからADBに対して接続を行います。
※本記事での接続ユーザはADMIN、接続に使用するネットサービス名はadb1_highです。必要に応じて読み替えてください。
bash
/home/datascience/sqlcl/bin/sql -cloudconfig /home/datascience/Wallet_adb1.zip admin/{パスワード}@adb1_high
なお、デフォルトでは接続時に以下のwarningが表示されます。
WARNING: A restricted method in java.lang.System has been called
WARNING: java.lang.System::load has been called by org.fusesource.jansi.internal.JansiLoader in an unnamed module (file:/home/datascience/sqlcl/lib/jansi.jar)
WARNING: Use --enable-native-access=ALL-UNNAMED to avoid a warning for callers in this module
WARNING: Restricted methods will be blocked in a future release unless native access is enabled
現状では放置しておいても動作しますが、表示させたくない場合は以下のコマンドを実行し、その後に改めてADBに対して接続を行ってください。
bash
export JAVA_TOOL_OPTIONS="--enable-native-access=ALL-UNNAMED"
正常に接続できることを確認した場合、この接続に名前を付けて保存します。SQLclでは接続情報を保存しておくことで容易に接続を切り替えられる機能があります。また、後述しますが、ここで保存した接続は後程のMCPサーバ呼び出し時に使用されます。
SQL> conn -save {保存名} -savepwd -cloudconfig /home/datascience/Wallet_adb1.zip admin/{パスワード}@adb1_high
また、最初にアップロードしたWALLETファイルは一度接続情報を保存すると必要なくなります(削除しても問題ありません)。理由は、ホーム・ディレクトリ配下の.dbtools/connectionsの下に保存した接続毎にディレクトリが作成され、その配下にWALLETの内容がコピーされるからです。
bash
ls -l /home/datascience/.dbtools/connections/o4_CDDXFxbt4Ent-zjMeIg
total 56
-rw-------. 1 datascience users 3005 Aug 25 11:08 README
-rw-------. 1 datascience users 409 Aug 25 11:08 credentials.sso
-rw-------. 1 datascience users 5349 Aug 25 11:08 cwallet.sso
-rw-------. 1 datascience users 80 Aug 25 11:08 dbtools.properties
-rw-------. 1 datascience users 5304 Aug 25 11:08 ewallet.p12
-rw-------. 1 datascience users 5710 Aug 25 11:08 ewallet.pem
-rw-------. 1 datascience users 3191 Aug 25 11:08 keystore.jks
-rw-------. 1 datascience users 691 Aug 25 11:08 ojdbc.properties
-rw-------. 1 datascience users 114 Aug 25 11:08 sqlnet.ora
-rw-------. 1 datascience users 1240 Aug 25 11:08 tnsnames.ora
-rw-------. 1 datascience users 2056 Aug 25 11:08 truststore.jks
最後にSQLcl内のMCPサーバが正常に起動するか確認します。
こちらは常時起動しておく必要はないため、確認後にCtrl+Cで抜けておいてください。
bash
/home/datascience/sqlcl/bin/sql -mcp
Picked up JAVA_TOOL_OPTIONS: --enable-native-access=ALL-UNNAMED
---------- MCP SERVER STARTUP ----------
MCP Server started successfully on Mon Aug 25 11:19:19 UTC 2025
Press Ctrl+C to stop the server
----------------------------------------
OCI利用のセットアップ
OCIの生成AIを利用する場合、先にprofileの設定が必要になります。profileとは、OCIに接続するための認証情報のことです。この情報を基に該当ユーザの、テナンシー、リージョン...が指定され、その箇所のリソースにアクセスを行います。(下記ではoci-cliのセット・アップ方式を採用していますが、oci-cliを用いなくとも自身でファイル、鍵を用意してもらっても構いません)
また、下記のコマンドを実行する前に事前にOCIコンソールより以下の情報取得をお願いします。
- ユーザのOCID
- テナンシーのOCID
- リージョン名
bash
# oci-cliライブラリのインストール
pip install -U pip
pip install -U oci-cli
# oci設定(以下、デフォルト設定で良い場合はエンターを押下)
oci setup config
Enter a location for your config [/home/datascience/.oci/config]:
Enter a user OCID:XXX
Enter a tenancy OCID:XXX
Enter a region by index or name(e.g.
1: af-johannesburg-1, 2: ap-batam-1, 3: ap-chiyoda-1, 4: ap-chuncheon-1, 5: ap-chuncheon-2,
6: ap-dcc-canberra-1, 7: ap-dcc-gazipur-1, 8: ap-delhi-1, 9: ap-hyderabad-1, 10: ap-ibaraki-1,
11: ap-melbourne-1, 12: ap-mumbai-1, 13: ap-osaka-1, 14: ap-seoul-1, 15: ap-seoul-2,...
76: us-sanjose-1, 77: us-somerset-1, 78: us-thames-1): 13
Do you want to generate a new API Signing RSA key pair? (If you decline you will be asked to supply the path to an existing key.) [Y/n]: Y
Enter a directory for your keys to be created [/home/datascience/.oci]:
Enter a name for your key [oci_api_key]:
Enter a passphrase for your private key ("N/A" for no passphrase): "N/A"
Repeat for confirmation: "N/A"
Do you want to write your passphrase to the config file? (If not, you will need to enter it when prompted each time you run an oci command) [y/N]: y
# ホーム・ディレクトリ配下の.oci以下のconfigファイル及び、鍵ペアが作成されていることを確認
ls -l ~/.oci
total 12
-rw-------. 1 datascience users 324 Aug 25 11:52 config
-rw-------. 1 datascience users 1897 Aug 25 11:52 oci_api_key.pem
-rw-------. 1 datascience users 451 Aug 25 11:52 oci_api_key_public.pem
#pubicキー( oci_api_key_public.pem)のみホーム・ディレクトリにコピー
cp ~/.oci/oci_api_key_public.pem ~
ホーム・ディレクトリに持ってきた公開鍵を用いてOCIコンソールより鍵の追加を行います。これにより、GUIから操作するユーザは登録した公開鍵とペアーになる秘密鍵を用いてOCIのリソースにアクセスできるようになります。まずはローカル環境に公開鍵をダウンロードします。ダウンロードは以下の方法にて行ってください。
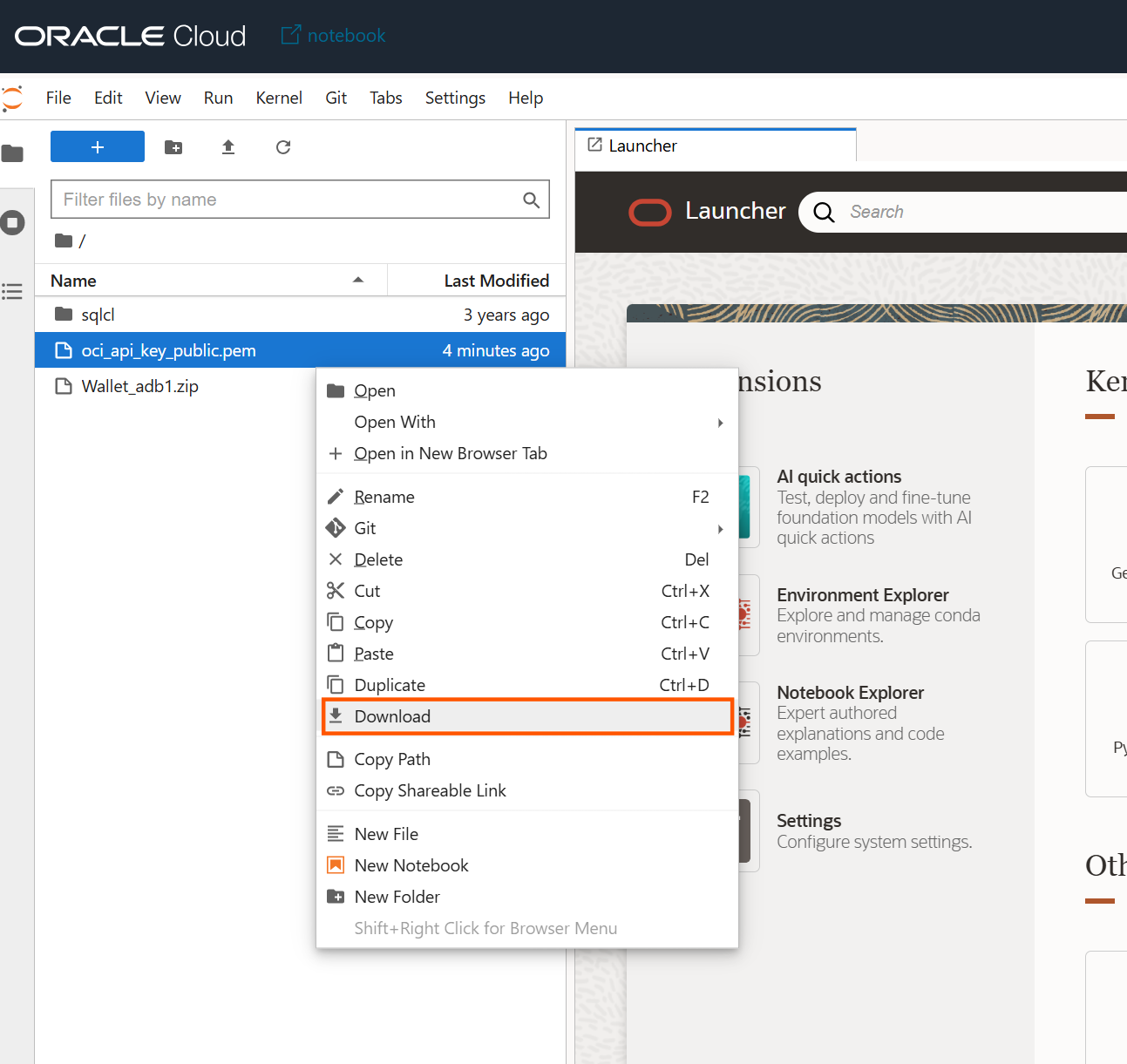
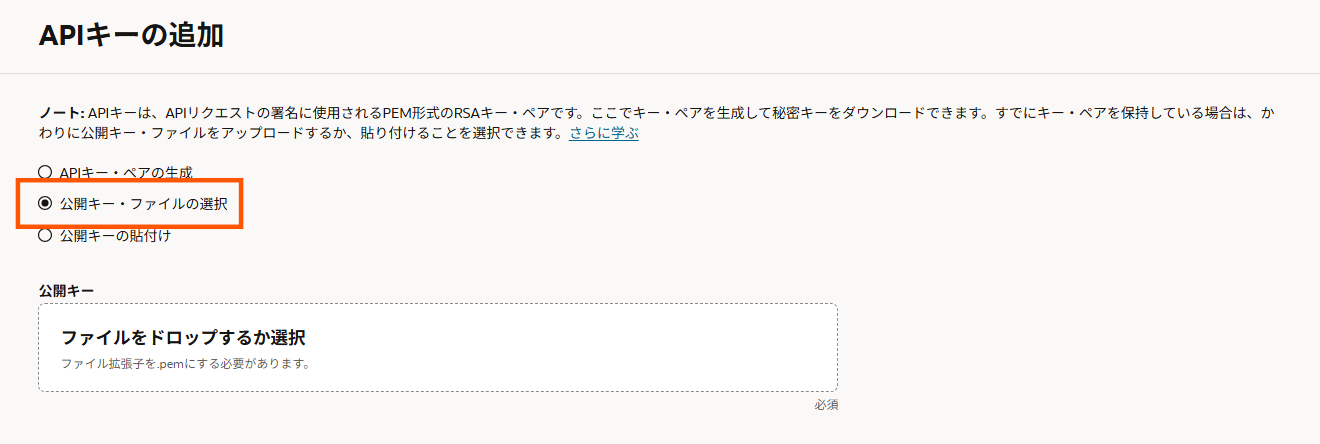
次にOCIコンソールの右上の人型マークより、「ユーザー設定」⇒「トークンおよびキー」⇒「APIキー」と進み、「APIキーの追加」を押下します。APIキーとしては既にローカル環境に保持している公開鍵を登録するため、「公開キー・ファイルの選択」を選び、公開鍵をアップロードします。
生成AI利用の設定ファイルのセットアップ
上記の設定ファイルでOCIのリソースにアクセスするためのセットアップは行うことができましたが、これだけではOCI上で提供される生成AI(LLM)を使用することはできません。どのプロバイダーの、どのモデルを使用するのか等設定する必要があります。datascienceユーザのホーム・ディレクトリ内に.envファイルを作成し、その中に各種設定情報を記述します。.envファイルを記述する前に事前に使用できるモデルの情報をOCIコンソールより取得します。
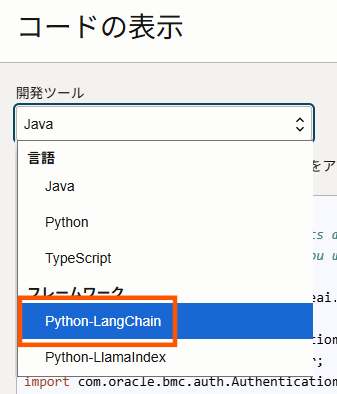
「生成AI」⇒「チャット」のページより使用したいモデルを選択後、「コードの表示」を選択します。

次に「開発ツール」より、「Python-LangChain」を選択します。こちらに必要な情報が記載されているため、確認後.envファイルを修正します。
bash
vi .env(※"xxxx"の箇所は各自読み替えてください)
# cohere.command-a-03-2025 v1.0
#----------------------------------
MODEL_ID = "xxxx"
END_POINT = "xxxx"
COMPARTMENT_ID = "xxxx"
PROVIDER = "xxxx"
AUTH_TYPE = "API_KEY"
AUTH_PROFILE = "DEFAULT"
#----------------------------------
requirements.txtの設定
上記までのセットアップで必要な設定は完了しました。最後にPythonコードの実行に必要となるライブラリ一覧をOSにインストールします。(本環境ではなるべくわかりやすくするため、仮想環境は用いずに実行しています)
bash
vi requirements.txt
asyncio
dotenv
langgraph
langchain_core
langchain_community
langchain_mcp_adapters
その後、保存したrequirements.txtを指定して、中のライブラリを一斉にインストールします。
bash
pip install -Ur requirements.txt
Pythonの実行
Pythonを実行するためのipynbファイルを作成します。フォルダ内にて右クリックを行い、「New Notebook」を選択します。(デフォルトの名前を変更する場合は、作成されたファイルを選択後、Renameを選んでください)

notebookの作成が完了したら、以下のコードを貼り付けます。
# --- ライブラリ読み込み ---
import sys
import os
import asyncio
from pprint import pprint
from dotenv import load_dotenv
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import HumanMessage
from langchain_community.chat_models import ChatOCIGenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.tools import load_mcp_tools
# --- 環境変数定義 ---
load_dotenv()
# --- main処理定義 ---
async def main(query: str):
# --- LLMモデル定義 ---
try:
llm = ChatOCIGenAI(
model_id=os.environ.get("MODEL_ID"),
service_endpoint=os.environ.get("END_POINT"),
compartment_id=os.environ.get("COMPARTMENT_ID"),
provider=os.environ.get("PROVIDER"),
auth_type=os.environ.get("AUTH_TYPE"),
auth_profile=os.environ.get("AUTH_PROFILE"),
model_kwargs={
"temperature": 0,
"max_tokens": 600,
"frequency_penalty": 0,
"presence_penalty": 0,
"top_p": 0.75
}
)
except Exception as e:
print(f"モデルの初期化に失敗しました: {e}")
return
# --- Prompt ---
prompt = """
あなたは優秀なAIアシスタントです。
質問の意図を理解し、段階的に思考することで質問に対して的確に回答することが出来ます。
与えられた質問を回答するために必要なツールを各MCPサーバより適切に選択し、質問意図に即した回答を行ってください。
思考途中で回答を行うことを放棄してはいけません。必ず最終的な回答を提示しなさい。
回答を生成までに失敗した場合は他のアプローチで成功できないか深く考えながら最終回答を導いてください。
最終回答が作成できた場合、その回答が質問者の欲しい情報であるかを考え、不必要な情報である場合は再度回答を生成しなさい。
DB接続時は"list_connections"の情報を基に接続しなさい。
"connect"で接続したDBへのセッションを必ず用いて"run_sql"を実行しなさい。
"""
# --- MCPサーバ実行 ---
try:
client = MultiServerMCPClient(
{
"sqlcl": {
"command": "/home/datascience/sqlcl/bin/sql",
"args": ["-mcp"],
"transport": "stdio",
}
}
)
except Exception as e:
print(f"MCPサーバの起動に失敗しました:{e}")
return
try:
# --- セッションを作成 ---
async with client.session("sqlcl") as session:
# ツール読み込み
tools = await load_mcp_tools(session)
# ツール名変換("-"を"_"に置換)
for tool in tools:
tool.name = tool.name.replace("-", "_")
print("使用できるツールは以下の通りです")
pprint([t.name for t in tools])
# ReActエージェント作成
graph = create_react_agent(llm, tools=tools, prompt=prompt)
print("ReActエージェントを作成しました")
# 質問を含むメッセージ作成
inputs = {"messages": [HumanMessage(content=query)]}
# エージェントのストリーム応答を受け取り表示
async for s in graph.astream(inputs, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
except Exception as e:
print(f"エラーが発生しました:{e}")
return
コードの解説
まず初めに先ほどrequirements.txtを基にインストールしたライブラリ一覧を読み込みます。(記載されていないものはデフォルトでインストールされているライブラリです)
# --- ライブラリ読み込み ---
import sys
import os
import asyncio
from pprint import pprint
from dotenv import load_dotenv
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import HumanMessage
from langchain_community.chat_models import ChatOCIGenAI
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain_mcp_adapters.tools import load_mcp_tools
次にLLMの使用に必要となる環境変数一覧を.envファイルより読み込みます。
# --- 環境変数定義 ---
load_dotenv()
上記で読み込んだ情報を基に使用するLLMを定義します。
# --- LLMモデル定義 ---
try:
llm = ChatOCIGenAI(
model_id=os.environ.get("MODEL_ID"),
service_endpoint=os.environ.get("END_POINT"),
compartment_id=os.environ.get("COMPARTMENT_ID"),
provider=os.environ.get("PROVIDER"),
auth_type=os.environ.get("AUTH_TYPE"),
auth_profile=os.environ.get("AUTH_PROFILE"),
model_kwargs={
"temperature": 0,
"max_tokens": 600,
"frequency_penalty": 0,
"presence_penalty": 0,
"top_p": 0.75
}
)
except Exception as e:
print(f"モデルの初期化に失敗しました: {e}")
return
上記で定義したLLMに渡すプロンプトを定義します。なお、プロンプトの記載は必須ではないのですが、記載していた方が精度が高くなるため、記述しています。
# --- Prompt ---
prompt = """
あなたは優秀なAIアシスタントです。
質問の意図を理解し、段階的に思考することで質問に対して的確に回答することが出来ます。
与えられた質問を回答するために必要なツールを各MCPサーバより適切に選択し、質問意図に即した回答を行ってください。
思考途中で回答を行うことを放棄してはいけません。必ず最終的な回答を提示しなさい。
回答を生成までに失敗した場合は他のアプローチで成功できないか深く考えながら最終回答を導いてください。
最終回答が作成できた場合、その回答が質問者の欲しい情報であるかを考え、不必要な情報である場合は再度回答を生成しなさい。
DB接続時は"list_connections"の情報を基に接続しなさい。
"connect"で接続したDBへのセッションを必ず用いて"run_sql"を実行しなさい。
"""
使用するMCPサーバの定義を記載します。
# --- MCPサーバ実行 ---
try:
client = MultiServerMCPClient(
{
"sqlcl": {
"command": "/home/datascience/sqlcl/bin/sql",
"args": ["-mcp"],
"transport": "stdio",
}
}
)
except Exception as e:
print(f"MCPサーバの起動に失敗しました:{e}")
return
クライアント ⇔ サーバ間でセッションを開きます。
また、その際に使用できるTOOLの情報を読み込みます。
# --- セッションを作成 ---
async with client.session("sqlcl") as session:
# ツール読み込み
tools = await load_mcp_tools(session)
こちらはOCIの生成AI特有の事象だと思いますが、後ほどLLMにTOOLの情報を渡す際にTOOL名に"-"が含まれている場合、正常に動作しないといった事象が見受けられました。"_"に変換して渡すことで正常に動作したため、このコードを入れています。
# ツール名変換("-"を"_"に置換)
for tool in tools:
tool.name = tool.name.replace("-", "_")
print("使用できるツールは以下の通りです")
pprint([t.name for t in tools])
こちらでReActのエージェントを作成し、質問文(質問文はmain関数の引数にて受け取ります)を与えることでエージェントの思考(messages)をストリーム表示させるようにしています。
# ReActエージェント作成
graph = create_react_agent(llm, tools=tools, prompt=prompt)
print("ReActエージェントを作成しました")
# 質問を含むメッセージ作成
inputs = {"messages": [HumanMessage(content=query)]}
# エージェントのストリーム応答を受け取り表示
async for s in graph.astream(inputs, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
MCPサーバの検証
上記までがコードの説明になります。それでは上記で定義したmain関数に質問文(引数)を渡して回答できるか検証してみましょう。
事前にADMINユーザのスキーマに3行3列のテーブル(TEST_TABLE)を作成しておきます。
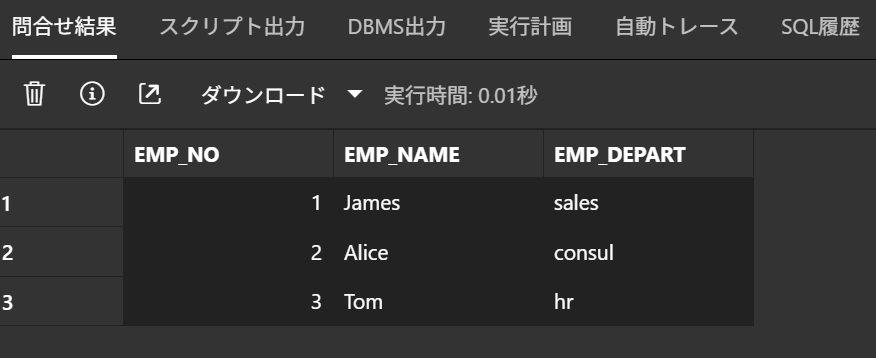
このテーブルのデータに対して、指定した条件通りに取得できるか検証します。
試しに"ADMINユーザのスキーマ内のTEST_TABLEより、EMP_NOが2の人の名前を教えて"と質問してみます。main関数を呼び出すコードは以下の通りです。
余談ですが、OCI Data Science環境に限らず一般的なJupyter notebookのセル内ではevent loopがデフォルトで存在しています。仮に下記のコマンドをasyncio.run(main(question))とした場合、既にイベントループが存在する旨のエラーが発生します。
question = "ADMINユーザのスキーマ内のTEST_TABLEより、EMP_NOが2の人の名前を教えて"
await main(question)
結果は以下の通りです。
順番としては
①ADBに接続するためにlist_connectionsより接続に必要な接続情報を取得
(※本記事の冒頭で紹介した、保存された接続名が取得されます。本記事では接続名をmcp_connectで保存しています)
②list_connectionsより取得できた情報を基にconnectを実行
(生成AI(エージェント)からは接続時の引数(Args)としてconnection_nameの値にmcp_connectを指定する指示が出ている)
③上記で確立したセッションにて、run-sqlの実行
(引数(Args)としてsqlの値にSELECT NAME FROM ADMIN.TEST_TABLE WHERE EMP_NO = 2;を指定する指示が出ている)
④run-sqlの失敗確認&リトライ
TEST_TABLEにはname列が存在しないため、エラーとなる。それを回避するためにselect文内を*(全ての意)にして情報取得が行える形に修正して再度run-sqlを実行
⑤上記の情報を基に最終的な回答を提出
EMP_NOが2の人の名前はAliceです。
の順で最終的な回答を導き出しています。
応答結果
使用できるツールは以下の通りです
['list_connections', 'connect', 'disconnect', 'run_sqlcl', 'run_sql']
ReActエージェントを作成しました
================================ Human Message =================================
ADMINユーザのスキーマ内のTEST_TABLEより、EMP_NOが2の人の名前を教えて
================================== Ai Message ==================================
まず、利用可能な接続を確認します。次に、適切な接続を選択してデータベースに接続し、指定されたクエリを実行します。
Tool Calls:
list_connections (1df03a87b9a144b9820b3debbd07670b)
Call ID: 1df03a87b9a144b9820b3debbd07670b
Args:
================================= Tool Message =================================
Name: list_connections
mcp_connect
================================== Ai Message ==================================
利用可能な接続はmcp_connectのみです。この接続を使用してデータベースに接続し、指定されたクエリを実行します。
Tool Calls:
connect (533ec5c449304352a59cd47b904228a5)
Call ID: 533ec5c449304352a59cd47b904228a5
Args:
connection_name: mcp_connect
================================= Tool Message =================================
Name: connect
["### DATABASE CONNECTION ESTABLISHED ###\nSuccessfully connected to: mcp_connect", "\n### DATABASE ENVIRONMENT CONTEXT ###\n", "1. Oracle Database Version: \n23.0.0.0.0", "2. Access Mode: \nThe Oracle database is currently in 'READ WRITE' mode", "3. NLS Parameters: \nThe current Oracle database uses the following NLS configuration:\nDatabase character set:{"results":[{"columns":[{"name":"PARAMETER","type":"VARCHAR2"},{"name":"VALUE","type":"VARCHAR2"}],"items":\n[\n{"parameter":"NLS_CHARACTERSET","value":"AL32UTF8"}\n]}]}\n\n Full NLS parameters: \n{"results":[{"columns":[{"name":"PARAMETER","type":"VARCHAR2"},{"name":"VALUE","type":"VARCHAR2"}],"items":\n[\n{"parameter":"NLS_RDBMS_VERSION","value":"23.0.0.0.0"}\n,{"parameter":"NLS_NCHAR_CONV_EXCP","value":"FALSE"}\n,{"parameter":"NLS_LENGTH_SEMANTICS","value":"BYTE"}\n,{"parameter":"NLS_COMP","value":"BINARY"}\n,{"parameter":"NLS_DUAL_CURRENCY","value":"$"}\n,{"parameter":"NLS_TIMESTAMP_TZ_FORMAT","value":"DD-MON-RR HH.MI.SSXFF AM TZR"}\n,{"parameter":"NLS_TIME_TZ_FORMAT","value":"HH.MI.SSXFF AM TZR"}\n,{"parameter":"NLS_TIMESTAMP_FORMAT","value":"DD-MON-RR HH.MI.SSXFF AM"}\n,{"parameter":"NLS_TIME_FORMAT","value":"HH.MI.SSXFF AM"}\n,{"parameter":"NLS_SORT","value":"BINARY"}\n,{"parameter":"NLS_DATE_LANGUAGE","value":"AMERICAN"}\n,{"parameter":"NLS_DATE_FORMAT","value":"DD-MON-RR"}\n,{"parameter":"NLS_CALENDAR","value":"GREGORIAN"}\n,{"parameter":"NLS_NUMERIC_CHARACTERS","value":".,"}\n,{"parameter":"NLS_NCHAR_CHARACTERSET","value":"AL16UTF16"}\n,{"parameter":"NLS_CHARACTERSET","value":"AL32UTF8"}\n,{"parameter":"NLS_ISO_CURRENCY","value":"AMERICA"}\n,{"parameter":"NLS_CURRENCY","value":"$"}\n,{"parameter":"NLS_TERRITORY","value":"AMERICA"}\n,{"parameter":"NLS_LANGUAGE","value":"AMERICAN"}\n]}]}\n20 rows selected. \n\n\n This is important for correctly interpreting data formats, encodings, and locale-specific behavior.\n", "Here’s the Oracle database context you need: version, open mode, and NLS parameters. Use this information to run the following queries accurately and ensure they align with the database’s current environment and settings."]
================================== Ai Message ==================================
データベースへの接続に成功しました。次に、ADMINユーザのスキーマ内のTEST_TABLEより、EMP_NOが2の人の名前を取得するクエリを実行します。
Tool Calls:
run_sql (52a8d366e06a48a790e2670867b36f62)
Call ID: 52a8d366e06a48a790e2670867b36f62
Args:
sql: SELECT NAME FROM ADMIN.TEST_TABLE WHERE EMP_NO = 2;
================================= Tool Message =================================
Name: run_sql
Error starting at line : 2 in command -
SELECT NAME FROM ADMIN.TEST_TABLE WHERE EMP_NO = 2
Error at Command Line : 2 Column : 8
Error report -
SQL Error: ORA-00904: "NAME": invalid identifier
https://docs.oracle.com/error-help/db/ora-00904/00904. 00000 - "%s: invalid identifier"
*Cause: The identifier or column name entered was invalid.
*Action: Ensure the following
More Details :
https://docs.oracle.com/error-help/db/ora-00904/
================================== Ai Message ==================================
クエリの実行中にエラーが発生しました。エラーメッセージによると、"NAME"というカラムが存在しないようです。そのため、クエリを修正して再度実行します。
Tool Calls:
run_sql (248c157387614a1ab22c432e5a31ffe7)
Call ID: 248c157387614a1ab22c432e5a31ffe7
Args:
sql: SELECT * FROM ADMIN.TEST_TABLE WHERE EMP_NO = 2;
================================= Tool Message =================================
Name: run_sql
"EMP_NO","EMP_NAME","EMP_DEPART"
2,"Alice","consul"
================================== Ai Message ==================================
EMP_NOが2の人の名前はAliceです。次に、以下のような少々適当な質問を投げてみます。このような指示でも正確に対応することが出来るか検証してみます。
question = """
James、Kenny、Juneの3名の数学、英語、理科の成績を管理するための
表を作成して。
また、kennyの成績のみ既に判明しており11点、22点、33点であった。
この情報も入れておいて。
最終的に作成した表の情報を全て見せて。
"""
await main(question)
結果は以下の通りです。
順番としては
①ADBに接続するためにlist_connectionsより接続に必要な接続情報を取得
②list_connectionsより取得できた情報を基にconnectを実行
(生成AI(エージェント)からは接続時の引数(Args)としてconnection_nameの値にmcp_connectを指定する指示が出ている)
③上記で確立したセッションにて、run-sqlの実行
(引数(Args)としてsqlの値にCREATE TABLE scores ( name VARCHAR2(50), math NUMBER, english NUMBER, science NUMBER )を指定する指示が出ている)
④上記で作成した表に対して、run-sqlの実行
(引数(Args)としてsqlの値にINSERT INTO scores (name, math, english, science) VALUES ('kenny', 11, 22, 33)を指定する指示が出ている)
⑤表の全データに対して、run-sqlの実行
(引数(Args)としてsqlの値にSELECT * FROM scoresを指定する指示が出ている)
⑥上記の情報を基に最終的な回答を提出
以下が作成した表の情報です。 NAME,MATH,ENGLISH,SCIENCE kenny,11,22,33
の順で最終的な回答を導き出しています。
応答結果
使用できるツールは以下の通りです
['list_connections', 'connect', 'disconnect', 'run_sqlcl', 'run_sql']
ReActエージェントを作成しました
================================ Human Message =================================
James、Kenny、Juneの3名の数学、英語、理科の成績を管理するための
表を作成して。
また、kennyの成績のみ既に判明しており11点、22点、33点であった。
この情報も入れておいて。
最終的に作成した表の情報を全て見せて。
================================== Ai Message ==================================
まずは、list_connectionsツールで接続可能なデータベースを確認します。
次に、connectツールでデータベースに接続します。
run_sqlツールで、James、Kenny、Juneの3名の数学、英語、理科の成績を管理するための表を作成します。
さらに、run_sqlツールで、kennyの成績を挿入します。
最後に、run_sqlツールで、表の情報を全て取得します。
Tool Calls:
list_connections (7c778fa7accd41939fe5c342ec9ed61b)
Call ID: 7c778fa7accd41939fe5c342ec9ed61b
Args:
================================= Tool Message =================================
Name: list_connections
mcp_connect
================================== Ai Message ==================================
接続可能なデータベースはmcp_connectであることがわかりました。
次に、connectツールでデータベースに接続します。
Tool Calls:
connect (3106c96e76354fe6b2f2005c9d1361aa)
Call ID: 3106c96e76354fe6b2f2005c9d1361aa
Args:
connection_name: mcp_connect
================================= Tool Message =================================
Name: connect
["### DATABASE CONNECTION ESTABLISHED ###\nSuccessfully connected to: mcp_connect", "\n### DATABASE ENVIRONMENT CONTEXT ###\n", "1. Oracle Database Version: \n23.0.0.0.0", "2. Access Mode: \nThe Oracle database is currently in 'READ WRITE' mode", "3. NLS Parameters: \nThe current Oracle database uses the following NLS configuration:\nDatabase character set:{"results":[{"columns":[{"name":"PARAMETER","type":"VARCHAR2"},{"name":"VALUE","type":"VARCHAR2"}],"items":\n[\n{"parameter":"NLS_CHARACTERSET","value":"AL32UTF8"}\n]}]}\n\n Full NLS parameters: \n{"results":[{"columns":[{"name":"PARAMETER","type":"VARCHAR2"},{"name":"VALUE","type":"VARCHAR2"}],"items":\n[\n{"parameter":"NLS_RDBMS_VERSION","value":"23.0.0.0.0"}\n,{"parameter":"NLS_NCHAR_CONV_EXCP","value":"FALSE"}\n,{"parameter":"NLS_LENGTH_SEMANTICS","value":"BYTE"}\n,{"parameter":"NLS_COMP","value":"BINARY"}\n,{"parameter":"NLS_DUAL_CURRENCY","value":"$"}\n,{"parameter":"NLS_TIMESTAMP_TZ_FORMAT","value":"DD-MON-RR HH.MI.SSXFF AM TZR"}\n,{"parameter":"NLS_TIME_TZ_FORMAT","value":"HH.MI.SSXFF AM TZR"}\n,{"parameter":"NLS_TIMESTAMP_FORMAT","value":"DD-MON-RR HH.MI.SSXFF AM"}\n,{"parameter":"NLS_TIME_FORMAT","value":"HH.MI.SSXFF AM"}\n,{"parameter":"NLS_SORT","value":"BINARY"}\n,{"parameter":"NLS_DATE_LANGUAGE","value":"AMERICAN"}\n,{"parameter":"NLS_DATE_FORMAT","value":"DD-MON-RR"}\n,{"parameter":"NLS_CALENDAR","value":"GREGORIAN"}\n,{"parameter":"NLS_NUMERIC_CHARACTERS","value":".,"}\n,{"parameter":"NLS_NCHAR_CHARACTERSET","value":"AL16UTF16"}\n,{"parameter":"NLS_CHARACTERSET","value":"AL32UTF8"}\n,{"parameter":"NLS_ISO_CURRENCY","value":"AMERICA"}\n,{"parameter":"NLS_CURRENCY","value":"$"}\n,{"parameter":"NLS_TERRITORY","value":"AMERICA"}\n,{"parameter":"NLS_LANGUAGE","value":"AMERICAN"}\n]}]}\n20 rows selected. \n\n\n This is important for correctly interpreting data formats, encodings, and locale-specific behavior.\n", "Here’s the Oracle database context you need: version, open mode, and NLS parameters. Use this information to run the following queries accurately and ensure they align with the database’s current environment and settings."]
================================== Ai Message ==================================
データベースへの接続が完了しました。
次に、run_sqlツールで、James、Kenny、Juneの3名の数学、英語、理科の成績を管理するための表を作成します。
表の名前はscores、列はname、math、english、scienceとします。
nameはVARCHAR2(50)、math、english、scienceはNUMBER型とします。
Tool Calls:
run_sql (7e8f434a4fa34a939d7c3a2d56924d0c)
Call ID: 7e8f434a4fa34a939d7c3a2d56924d0c
Args:
sql: CREATE TABLE scores (
name VARCHAR2(50),
math NUMBER,
english NUMBER,
science NUMBER
)
================================= Tool Message =================================
Name: run_sql
Table SCORES created.
================================== Ai Message ==================================
表の作成が完了しました。
次に、run_sqlツールで、kennyの成績を挿入します。
nameはkenny、mathは11、englishは22、scienceは33とします。
Tool Calls:
run_sql (f97b0d8f1ac3452a92506f23dbabb484)
Call ID: f97b0d8f1ac3452a92506f23dbabb484
Args:
sql: INSERT INTO scores (name, math, english, science)
VALUES ('kenny', 11, 22, 33)
================================= Tool Message =================================
Name: run_sql
1 row inserted.
================================== Ai Message ==================================
kennyの成績の挿入が完了しました。
次に、run_sqlツールで、表の情報を全て取得します。
Tool Calls:
run_sql (fe70a13f57bb402eaeef477e42893dc6)
Call ID: fe70a13f57bb402eaeef477e42893dc6
Args:
sql: SELECT * FROM scores
================================= Tool Message =================================
Name: run_sql
"NAME","MATH","ENGLISH","SCIENCE"
"kenny",11,22,33
================================== Ai Message ==================================
以下が作成した表の情報です。
NAME,MATH,ENGLISH,SCIENCE
kenny,11,22,33まとめ
いかがだったでしょうか。個人的には、MCPサーバはまだまだ未発達の技術ではあるものの、創意工夫により更なるDatabaseの可能性を広げてくれる技術だと感心しました。
今回は1つのMCPサーバのみで完結させる形で記述しましたが、当技術が真価を発揮するのは複数のMCPサーバが組み合わさった時であるため、次回以降にその手順もご紹介できればと思います。長々と記述しましたが、最後までご覧いただき、誠にありがとうございました。