はじめに
Apache Sparkの初心者がPySparkで、DataFrame API、SparkSQL、Pandasを動かしてみた際のメモです。
Hadoop、Sparkのインストールから始めていますが、インストール方法等は何番煎じか分からないほどなので自分用のメモの位置づけです。
環境
お試し用に以下のバージョンのHadoop(HDFS)とSparkをインストールします。
・Apache Hadoop 3.1.1
・Apache Spark 2.3.2
OSはCentOS 7.4を使用します。
お試しですので、Hadoopは疑似分散を使用します。
HadoopはSpark付属のものでも良かったのですが、今回は別にインストールしています。
Sparkはスタンドアロンモードを使用します。
JDKインストール
最初にOpenJDK 8をインストールします。
# yum -y install java-1.8.0-openjdk-devel
# java -version
openjdk version "1.8.0_191"
OpenJDK Runtime Environment (build 1.8.0_191-b12)
OpenJDK 64-Bit Server VM (build 25.191-b12, mixed mode)
JAVA_HOMEを設定し、PATHにJavaのパスを追加しています。
# echo "export JAVA_HOME=$(readlink -e $(which java)|sed 's:/bin/java::')" > /etc/profile.d/java.sh
# echo "PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile.d/java.sh
# source /etc/profile
Hadoopインストール
Hadoopを疑似分散モードでインストールします。
以下のサイト・投稿を参考にしています。
- Hadoop: Setting up a Single Node Cluster.
- @IT Hadoopの疑似分散モードと完全分散モードを試す
- Hadoop 2.7.1を擬似分散モードで動かす
- hadoopを疑似分散で動かす
- Apache Hadoopのインストール手順
まず、Hadoopのモジュールを以下からダウンロードします。
http://hadoop.apache.org/releases.html
以下の3.1.1.をダウンロードし、「/opt」以下に展開しました。
# tar xvzf hadoop-3.1.1.tar.gz -C /opt
# ln -s /opt/hadoop-3.1.1 /opt/hadoop
HDFSのデータ用ディレクトリを作成します。
# mkdir -p /var/hadoop/data
必要な環境変数を定義します。
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
Hadoop/Spark用のユーザ(Hadoop)を作成します。
# useradd -s /bin/bash -m hadoop -p XXXXXXXX ※XXXXXXXXはパスワード(任意)を指定してください
# chown -R hadoop:hadoop /opt/hadoop-3.1.1
# chown -R hadoop:hadoop /opt/hadoop
# chown -R hadoop:hadoop /var/hadoop/data
# su - hadoop
擬似分散モードで動かすための設定の以下のファイルを修正します。
・HDFS用のディレクトリを/var/hadoop/dataに指定
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/data</value>
</property>
</configuration>
・今回は1ノードのためレプリケーションを"1"に設定
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Hadoop は SSH 経由でホストを操作するので、"ssh localhost" でパスフレーズなしでログインできる必要があります。
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
$ chmod 600 ~/.ssh/authorized_keys
パスフレーズなしで設定できることを確認します。
$ ssh localhost
ファイルシステムをフォーマット
$ hdfs namenode -format
WARNING: /opt/hadoop/logs does not exist. Creating.
2018-10-19 23:00:14,379 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = sparkserver1/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.1
~省略~
2018-10-19 23:00:32,388 INFO common.Storage: Storage directory /var/hadoop/data/dfs/name has been successfully formatted.
~省略~
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at sparkserver1/127.0.0.1
************************************************************/
HDFSの起動
$ start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [sparkserver1]
jpsでDataNode、NameNode、SecondaryNameNodeの3つのプロセスが起動していることを確認します。
$ jps
21505 DataNode
21829 Jps
21388 NameNode
21709 SecondaryNameNode
HDFSを参照できることを確認するために以下のコマンドを実行します。
フォーマット直後のため、結果は何も表示されません。
$ hadoop fs -ls /
Apache Sparkのインストール
以下を参考にしています。
Spark Standalone Mode
Apache Spark で分散処理入門
以下から、version 2.3.2をダウンロードし、インストールします。
package typeは、既にHadoopをインストールしているため、Hadoopを含まない「Pre-build with user-provided Apache Hadopp」を選択しています。

「/opt」以下に展開しました。
# tar xvzf spark-2.3.2-bin-without-hadoop.tgz -C /opt
# ln -s /opt/spark-2.3.2-bin-without-hadoop /opt/spark
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
export SPARK_HOME=/opt/spark
# chown -R hadoop:hadoop /opt/spark-2.3.2-bin-without-hadoop
# chown -R hadoop:hadoop /opt/spark
# su - hadoop
「Using Spark's "Hadoop Free" Build」に記載されていましたが、HadoopなしのSparkをインストールする場合は、以下のようにSPARK_DIST_CLASSPATHにHadoopのクラスパスを設定します。
$ cp -p /opt/spark/conf/spark-env.sh.template /opt/spark/conf/spark-env.sh
$ vi /opt/spark/conf/spark-env.sh
export SPARK_DIST_CLASSPATH=`hadoop classpath`
Sparkを起動します。
$ start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-sparkserver1.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-sparkserver1.out
Sparkを起動すると、Spark-UIも利用できるようになります。
http://[Sparkが起動しているサーバのIPアドレス]:8080/
いよいよPySparkを使う
HDFS上のCSVを読み込んで、PySparkからデータを操作しています。
データを準備する
まずは手頃なCSVファイルが欲しかったので、kaggleから以下のデータをダウンロードしました。

データは以下のように、パン屋さんのお客さんごとの購入物になっています。
PySparkで商品ごとの売り上げを集計してみます。
PySparkといっても色々やり方があるようで、DataFrame API、SparkSQL、Pandasの3つで同じように試してみます。
Date,Time,Transaction,Item
2016-10-30,09:58:11,1,Bread
2016-10-30,10:05:34,2,Scandinavian
2016-10-30,10:05:34,2,Scandinavian
2016-10-30,10:07:57,3,Hot chocolate
2016-10-30,10:07:57,3,Jam
2016-10-30,10:07:57,3,Cookies
2016-10-30,10:08:41,4,Muffin
2016-10-30,10:13:03,5,Coffee
2016-10-30,10:13:03,5,Pastry
2016-10-30,10:13:03,5,Bread
2016-10-30,10:16:55,6,Medialuna
2016-10-30,10:16:55,6,Pastry
2016-10-30,10:16:55,6,Muffin
DataFrame API
以下を参考にしています。
Spark SQLとDataFrame API入門
PySparkのチートシート
まずは、HDFS にディレクトリを作成し、サンプルデータのCSVファイルを格納します。
$ hadoop fs -mkdir /data/
$ hadoop fs -put BreadBasket_DMS.csv /data/
$ hadoop fs -ls /data
Found 1 items
-rw-r--r-- 1 hadoop supergroup 710518 2018-10-21 02:56 /data/BreadBasket_DMS.csv
PySparkを起動します。
$ pyspark --name sample-app --master spark://localhost:7077
まず、HDFS上のCSVファイルを読み込んで、最初の5行を表示します。
from pyspark.sql.types import *
struct = StructType([
StructField('bb_date', DateType(), False),
StructField('bb_time', StringType(), False),
StructField('bb_tran', IntegerType(), False),
StructField('bb_item', StringType(), False)
])
df = spark.read.csv('hdfs://localhost:9000/data/BreadBasket_DMS.csv', schema=struct)
df.show(5)
+----------+--------+-------+-------------+
| bb_date| bb_time|bb_tran| bb_item|
+----------+--------+-------+-------------+
| null| null| null| null|
|2016-10-30|09:58:11| 1| Bread|
|2016-10-30|10:05:34| 2| Scandinavian|
|2016-10-30|10:05:34| 2| Scandinavian|
|2016-10-30|10:07:57| 3|Hot chocolate|
+----------+--------+-------+-------------+
only showing top 5 rows
最初のnullはCSVのヘッダのようです。集計に影響はないのでこのまま進めます。
次に、商品ごとにグルーピングし、売上をカウントして降順に並び替えます。
>>> df.groupBy('bb_item').count().sort('count', ascending=False).show(5)
+-------+-----+
|bb_item|count|
+-------+-----+
| Coffee| 5471|
| Bread| 3325|
| Tea| 1435|
| Cake| 1025|
| Pastry| 856|
+-------+-----+
only showing top 5 rows
トップはCoffeeで、5471杯の売り上げでした。
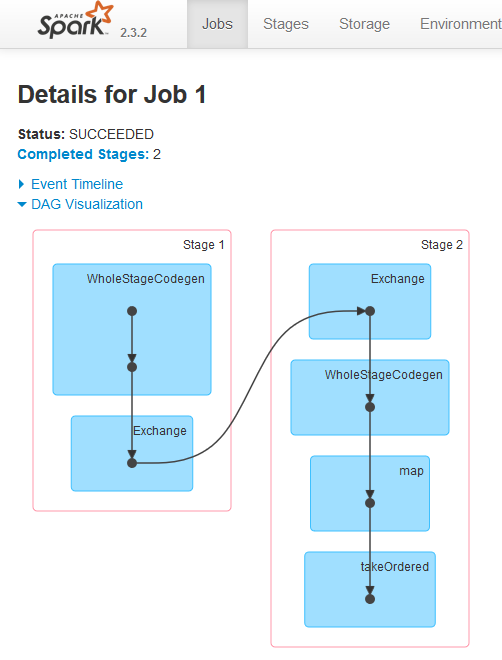
SparkUIではDAGが以下のように表示できます。
SparkSQL
次にSparkSQLで同様のことを試してみます。
CSVファイルを読み込むところは同じです。
struct = StructType([
StructField('bb_date', DateType(), False),
StructField('bb_time', StringType(), False),
StructField('bb_tran', IntegerType(), False),
StructField('bb_item', StringType(), False)
])
df = spark.read.csv('hdfs://localhost:9000/data/BreadBasket_DMS.csv', schema=struct)
bbという一時的なテーブルを作成し、最初の5行を表示しています。
>>> df.registerTempTable('bb')
>>> spark.sql('select * from bb').show(5)
+----------+--------+-------+-------------+
| bb_date| bb_time|bb_tran| bb_item|
+----------+--------+-------+-------------+
| null| null| null| null|
|2016-10-30|09:58:11| 1| Bread|
|2016-10-30|10:05:34| 2| Scandinavian|
|2016-10-30|10:05:34| 2| Scandinavian|
|2016-10-30|10:07:57| 3|Hot chocolate|
+----------+--------+-------+-------------+
only showing top 5 rows
最後に集計しています。当然ですが、DataFrame APIを用いた時と同じ結果になっています。
>>> spark.sql('select bb_item, count(*) as n from bb group by bb_item order by n desc').show(5)
+-------+----+
|bb_item| n|
+-------+----+
| Coffee|5471|
| Bread|3325|
| Tea|1435|
| Cake|1025|
| Pastry| 856|
+-------+----+
only showing top 5 rows
Pandas
最後はPandasで試してみます。
Pandasは、Pythonでのデータ解析に関する機能を提供するライブラリです。
以下を参考にしました。
Pandas 公式チートシートを翻訳しました
https://qiita.com/ysdyt/items/9ccca82fc5b504e7913a
まずは、pipが入っていなかったのでインストールして、そのままPandasもインストールします。
# wget https://bootstrap.pypa.io/get-pip.py
# python get-pip.py
# pip install pandas
PySparkで、最初にCSVファイルを読み込んでいます。DataFrame API、SparkSQLではHDFSから読み込んでいたのですが、Pandasでは若干面倒なようなので今回はローカルファイルから読み込んでいます。
import pandas as pd
names = ['bb_date', 'bb_time', 'bb_tran', 'bb_item']
pandasdf = pd.read_csv('/tmp/BreadBasket_DMS.csv', names=names)
最初の5行を表示。
>>> pandasdf.head(5)
bb_date bb_time bb_tran bb_item
0 Date Time Transaction Item
1 2016-10-30 09:58:11 1 Bread
2 2016-10-30 10:05:34 2 Scandinavian
3 2016-10-30 10:05:34 2 Scandinavian
4 2016-10-30 10:07:57 3 Hot chocolate
最後に集計結果を表示します。
>>> pandasdf['bb_item'].value_counts().head(5)
Coffee 5471
Bread 3325
Tea 1435
Cake 1025
Pastry 856
Name: bb_item, dtype: int64
最後に
最後にpyファイルで実行しようとしたが失敗。
pythonファイルは以下のとおり。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
names = ['bb_date', 'bb_time', 'bb_tran', 'bb_item']
pandasdf = pd.read_csv('/tmp/BreadBasket_DMS.csv', names=names)
pandasdf['bb_item'].value_counts().head(5)
これをpysparkで実行しようとすると、spark-submitを使えと怒られる。
pyspark --name sample-app --master spark://localhost:7077 sample.py
Running python applications through 'pyspark' is not supported as of Spark 2.0.
Use ./bin/spark-submit <python file>
spark-submitで実行すると、エラーにはならなかったが、結果が表示されず。これはまた今度調べてみよう。
$ spark-submit --name sample-app --master spark://localhost:7077 sample.py
2018-10-21 06:49:39 WARN Utils:66 - Your hostname, sparkserver1 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
2018-10-21 06:49:39 WARN Utils:66 - Set SPARK_LOCAL_IP if you need to bind to another address
2018-10-21 06:49:40 WARN NativeCodeLoader:60 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-10-21 06:49:40 INFO ShutdownHookManager:54 - Shutdown hook called
2018-10-21 06:49:40 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-0edd9099-fe73-4ebb-b7dd-5b9b9cc7829e