Google が 2023年の2月に GitHub で公開した Magika というプロジェクトがあります。
主に Python で書かれたプログラムなのですが、今回これを自身の勉強のために C# に移植してみましたので、その過程を記録したいと思います。
過程には興味がないので結果だけ知りたいという方は、以下のリポジトリをご覧ください。
目次
- Day 1 : まずは Magika の中身を見てみよう
- Day 2 : C# で 概念実証コードを書いてみる
- Day 3 : C# クラスライブラリとして Magika を移植していく
- Day 4 : GitHub Copilot を使って作業効率アップ
- Day 5 : クラスライブラリとしての Magika を完成させる
- Day 6 : コンソールアプリを作成する
- Day 7 : 移植したMagikaをビルドし、動作確認する
Magika の紹介
Magika は Google が開発した、機械学習を利用してファイルの内容を分析してファイル形式を判定するというプログラムです。GitHub 上でOSSとして公開されています。
例えばそのファイルが ZIP ファイルなのか、あるいは Word の docx ファイルなのかを判定したり、テキストファイルだとして、Markdown 形式のテキストなのか、JavaScript のソースコードなのかを判定することができます。
ファイル形式の判定というと、ファイルの拡張子から判定したり、ファイルを読み取ってそれぞれのファイル形式に固有のヘッダ情報などから判定するという方法が一般的ですが、Magika は機械学習を利用して判定するという点が特徴です。
判定できるファイル形式は 100 以上、判定精度は 99 % 以上と謳われているほか、機械学習というと動作が遅いイメージがありますが、1ファイルあたり約 5 ms という高速な判定が可能とされています。
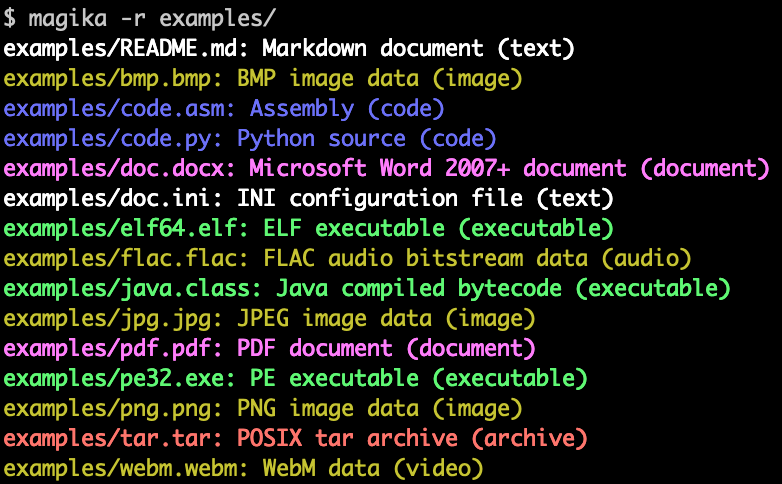
- Magika の実行例 (Magika の GitHub レポジトリより引用)
どうして C# に移植することにしたのか
Magika が公開されたというニュースを見て面白そうだったので、さっそく自分のPC上で試してみようと思いました。
ところがオリジナルの Magika は Python で書かれているため、まず Python をインストールしなければなりません。一般的なエンジニアなら自分の PC に Python くらい入っているのは当たり前なのかもしれませんが、Python に明るくない私はこの時点で「えー...」となってしまいました。
さらにいうと、私は主に PowerShell 使いなので Magika を PoweShell から呼び出したい。しかし PowerShell から Python を呼び出すというのは(もちろん可能ですが)ちょっと面倒です。PowerShell から呼び出すのであれば、せめて EXE 形式のシングルバイナリか .NET (C#) で開発されたライブラリがあると理想です。
ちょうど Python や C# を勉強してみたいと思っていたところだし、機械学習にも興味がありましたので、ないなら作ってしまおうということで Magika の C# への移植に挑戦してみることにしました。
Magika は Apache 2.0 でライセンスされており、一定の条件下で再配布や改変が可能です。
私のプログラミングスキル
まず、簡単に私の現在のプログラミングスキルについて紹介しておきます。
- IT 系エンジニアではありますが職業プログラマーではありません。
- 主に PowerShell を使います。そこそこ書けるほうだと思っています。モジュールとかも作って GitHub で公開したりしています。
- PowerShell から呼び出す目的でごく簡単な C# のライブラリを書いたことはありますが、体系的に学んだことはありません。
- Python は せいぜい Hello World くらいしか書いたことがありません。
- 機械学習のことは全然わかりません。
- Day 0 : まずは Magika の中身を見てみよう
移植作業を始める前に、まずは Magika の中身を見てどのように動作しているのかを理解することから始めます。あまり複雑だとそもそも自分のスキルでは移植できないですし。
Magika のメインプログラムはレポジトリ内の /python/magika/magika.py ファイルに書かれています。割とシンプルな内容なので Python に明るくない私でもだいたい雰囲気で読めました。
動作フローを流し読みした結果、大きく分けて 2 つの処理があることがわかりました。
1. ファイルの内容を抽出する
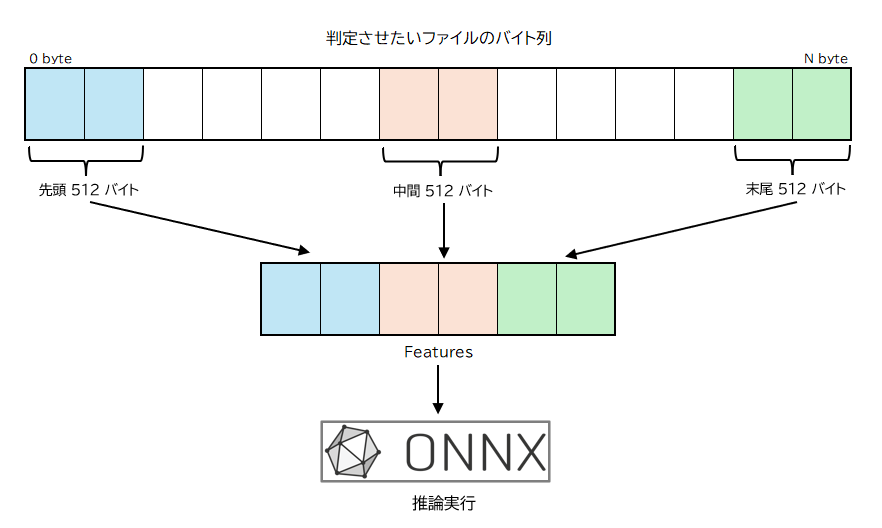
判定したいファイルのデータをすべて機械学習モデルに渡すのではなく、ファイルの一部のみを抽出して渡しています。ざっくり言うとファイルの先頭 512 バイト、中間部分の 512 バイト、末尾の 512 バイトを抽出して連結した 1536 バイトの配列を用意している感じです。Magika のプログラム内ではこの 1536 バイトの配列を Features という名前で扱っています。
実際にはファイル読み込み前に存在判定をしたり、サイズが1536バイトに満たない小さいファイルの場合は 整数値 256 で埋めるなどのいくつかの処理が入ります。
2. 機械学習モデルにデータを渡して判定させる
実際のファイル形式の判定はややこしいプログラム処理を行うのではなく、事前に学習された機械学習モデルにデータを渡して判定させるだけですので、プログラムコードとしては極めて簡素です。機械学習の用語でこの判定処理のことを「推論」(Inference) と呼ぶようです。
機械学習モデルは Magika のレポジトリ内の /python/magika/models/standard_v1/model.onnx というファイルに保存されています。
# magika.py から推論部分のみ抜粋
## モデルを読み込んでセッションを初期化
onnx_session = rt.InferenceSession(self._model_path)
self._onnx_session = self._init_onnx_session()
## 推論を実行
batch_raw_predictions = self._onnx_session.run(
["target_label"], {"bytes": X[start_idx:end_idx, :]}
)[0]
先に用意した Features (1536バイトの配列) を機械学習モデルに入力して「推論」を実行させると、113 個の要素を持つ float 型の配列が出力されます。この配列の各要素がそれぞれのファイル形式に対応しており、その値が高いほどそのファイル形式である確率が高いということになります。つまり、この配列の中で最も値が高い要素のインデックス番号を探すことで、そのファイル形式を判定することができるというわけです。
各要素とファイル形式の対応は/python/magika/models/standard_v1/model_config.jsonで定義されています。
# 113個の要素を持つ配列が機械学習モデルから出力される
# それぞれの要素がファイル形式に対応している
[
0.142, # ai
0.031, # pdf
0.186, # docx
...
0.950, # html -> この要素の値が全体で最も大きいので html である確率が高い
...
0.008 # zip
0.238 # svg
]
ONNX 形式の機械学習モデル?
Magika ( Python 版) ではONNX 形式の機械学習モデルが使用されています。ONNXって?
機械学習モデルを作成するためのフレームワークには TensorFlow とか PyTorch とかいろいろな種類がありますが、どのフレームワークで作成されたモデルでも、最終的にこの ONNX 形式に変換しておけば ONNX Runtime という共通のライブラリで実行できて便利、という仕組みのようです。(読み方は「オニキス」らしい)
ONNX Runtime 自体もオープンソースで公開されており、Python、C#、Javaなどいろいろな言語で利用できます。CUDA 版を使うと NVIDIA の GPU を使って高速に推論を実行できるとかいろいろバリエーションもあるようですが、Magika で使用されているモデルは軽量なので通常の CPU で十分高速に動作します。
ここまでの Magika の動作概要を図にするとこんな感じでしょうか。
続く
とりあえず初日はここまで。次回は実際に C# のコードを書きながら ONNX Runtime を使ってオリジナルの Magika と同じようなことができるか試してみます。