Google のファイル判定プログラム Magika を Python から C# に移植する過程を共有する記事の第5回目です。
前回は移植作業の効率を上げるために GitHub Copilot を使ってみました。今回はクラスライブラリ完成までを目指して作りこみを進めていきます。
目次
- Day 1 : まずは Magika の中身を見てみよう
- Day 2 : C# で 概念実証コードを書いてみる
- Day 3 : C# クラスライブラリとして Magika を移植していく
- Day 4 : GitHub Copilot を使って作業効率アップ
- Day 5 : クラスライブラリとしての Magika を完成させる
- Day 6 : コンソールアプリを作成する
- Day 7 : 移植したMagikaをビルドし、動作確認する
クラスライブラリとしての Magika を完成させる
GitHub Copilot の助けも借りつつ、根気よく移植を続けていきます。
機械学習モデルによる推論処理
周辺の処理の移植が進み、いよいよ Magika のキモである機械学習モデルによる推論処理の移植に取りかかります。概念実証コードで ONNX Runtime を使って推論処理を行う基本的な流れは分かっていますが、実際の Python 版 Magika の推論処理はもう少し複雑になっているので、それを C# でどう表現するかが課題です。
まずは ONNX 形式の機械学習モデルを読み込んで、推論セッションを初期化する部分。ここは簡単です。
private InferenceSession InitOnnxSession()
{
var modelPath = $".\models\standard_v1\model.onnx";
var onnxSession = new InferenceSession(modelPath);
return onnxSession;
}
頭を悩ませたのが実際に推論を行う部分。Python 版 Magika の_get_raw_predictionsメソッドの移植です。
概念実証では単一の入力から単一の出力を得るだけの簡単なコードで済ませていましたが、オリジナルの Magika では高速化のためにバッチ処理が組み込まれており、複数ファイルの情報を一度にまとめて入力し、一回の推論実行で多数のファイルの判定処理を一気に行う形になっています。
X = np.array(X_bytes).astype(np.float32)
raw_predictions_list = []
samples_num = X.shape[0]
max_internal_batch_size = 1000
batches_num = samples_num // max_internal_batch_size
for batch_idx in range(batches_num):
start_idx = batch_idx * max_internal_batch_size
end_idx = min((batch_idx + 1) * max_internal_batch_size, samples_num)
batch_raw_predictions = self._onnx_session.run(
["target_label"], {"bytes": X[start_idx:end_idx, :]}
)[0]
raw_predictions_list.append(batch_raw_predictions)
return np.concatenate(raw_predictions_list)
変数Xが多次元配列(NDArray)になっていて、バッチサイズにあわせてX[start_idx:end_idx, :]でスライスして推論処理の入力としているようです。
機械学習モデルでバッチ推論をするという概念が良くわかっておらず「え?そんなことできるの?」という感じでしたし、NDArrayという NumPy に特有の型、多次元配列という直感的ではない構造にも惑わされ、この処理の内容を理解するのにかなり苦戦しました。
さらにこれを C# でどう表現するかも難しい問題でした。C# の ONNX Runtime では入力は単純な配列ではなくTensor<T>やNamedOnnxValueという独自のデータ型で扱う必要があるため、これらを使って多次元配列をどう表現するのか、調べてもほとんど情報が見つかりません。
さらにInferenceSession.Run()メソッドも Python 版では一種類しかないのに対し、C# 版では複数のオーバーロード(17種類!)が用意されており、どれを使えばいいのかもわかりませんでした。
最終的に、いろいろ試しながら以下のようなコードでバッチ推論を実現することができました。
Memory<float> X = XBytes.Select(b => (float)b).ToArray().AsMemory();
List<float[]> rawPredictionsList = [];
int _input_column_size = 512 * 3;
int _output_column_size = 113;
int samplesNum = features.Count;
int maxInternalBatchSize = 1000;
int batchesNum = samplesNum / maxInternalBatchSize;
for (int batchIdx = 0; batchIdx < batchesNum; batchIdx++)
{
int startIdx = _input_column_size * batchIdx * maxInternalBatchSize;
int endIdx = Math.Min((batchIdx + 1) * maxInternalBatchSize, samplesNum);
int count = endIdx - startIdx;
List<NamedOnnxValue> input = [];
Tensor<float> dt = new DenseTensor<float>(
X.Slice(startIdx, _input_column_size * count),
[count, _input_column_size],
false
);
input.Add(NamedOnnxValue.CreateFromTensor("bytes", dt));
using var batchRawPredictions = this._onnx_session.Run(
outputNames: ["target_label"],
inputs: input
);
foreach (var rawPreds in batchRawPredictions[0].AsEnumerable<float>().Chunk(_output_column_size))
{
rawPredictionsList.Add(rawPreds);
}
}
return rawPredictionsList;
200 個のファイルを 100 個ごとに 2 回に分けてバッチ処理するケースを考えてみます。
まず、判定する 200 個のファイルそれぞれから抽出した 1536 バイトの特徴量(Features)を全て単一の float 型の配列Xにまとめておきます。Python 版とは違い多次元配列ではなく普通の一次元配列です。この時点でXの要素数は1536 * 200 = 307200あります。
次に、バッチごとに一回の推論で使うだけのTensor<float>型のデータを作成します。DenseTensor(Memory<T>, ReadOnlySpan<Int32>, Boolean)コンストラクタを使用します。
コンストラクタの第一引数にはXから一回のバッチで使用する分のデータをスライスで取り出して渡します(Xの最初から100 * 1536 = 153600個のデータ)。
第二引数には各次元のサイズを Span 指定します。第一引数のデータは全部で153600個あるけど、これは10 * 15360でも30 * 5120でもなく、100 * 1536ですよと教えてあげているようなイメージです。
あとはTensor<float>をNamedOnnxValue型に変換してList<>に格納し、InferenceSession.Run()メソッドで推論処理を行います。どのオーバーロードを使うかは、どういう方式で推論結果を受け取るかの違いくらいで、どれを使ってもあまり問題にはならないようです。Python 版と最も近いRun(IReadOnlyCollection<NamedOnnxValue> inputs, IReadOnlyCollection<string> outputNames)を使っています。
単一入力の場合は 113 要素数の float 配列が出力されましたが、バッチ処理の場合は 100 個のファイルを一度に推論させる例で100 * 113要素数の float 配列が出力されます。これをChunk()を使って 113 要素ずつ分割すれば、それぞれのファイルに対する 113 個の要素の float 配列を取り出すことができます。
Logger の実装
ロギングのための Logger の実装方法について検討します。
オリジナルの Magika では、ログ情報をstderrに出力するだけの非常にシンプルな Logger を独自実装しています(その名もSimpleLogger)
class SimpleLogger:
"""
We implement a simple logger to not rely on additional python packages,
e.g., rich. This is written in way that, by default, log messages (e.g.,
debug/info/...) are sent to stderr.
"""
C# ではどういう実装が一般的なのか調べてみると、同様に独自 Logger を実装している例も多いようですが、お作法としてはILoggerインターフェースを使用するのが良いようです。
ILoggerインターフェースを使うと、ログの出力先を柔軟に変更できるなどのメリットがあるようです。(ふわっとした理解)
コンソールにログを出力するだけならコードもわりとシンプルです。
using ILoggerFactory factory = LoggerFactory.Create(builder => builder.AddConsole());
ILogger logger = factory.CreateLogger("Category");
logger.LogInformation("Hello World! Logging is {Description}.", "fun");
ということで最初はILoggerを使って実装する方針で書き始めたのですが、いざ実装してみるといくつか問題が見えてきました。
1. コンソールログの表示形式がPython版と異なる
ILoggerでコンソールにログ出力すると、出力が2行になります。
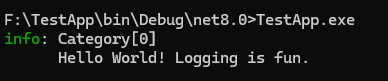
Python 版 Magika のログ出力をなるべくそのまま再現したいと考えていたので、この表示は気になりました。
2. デフォルトのログレベル問題
ILoggerを使うと、デフォルトでInformationレベル以上のログが表示されるようになっています。一方でオリジナルの Magika ではverboseやdebugを明示的に指定しないとInformationログは表示されません。この差異をスマートに吸収する方法が思いつきませんでした。
結局これらの問題をうまいこと何とかする方法がわからず、そこまでILoggerにこだわる理由もなかったので、Python 版 Magika のSimpleLoggerをほぼそのまま C# に移植することにしました。
ただ、一つオリジナルから変更したのがログの出力先で、エラー出力stderrではなく標準出力stdoutに変えています。これは PowerShell から呼び出す際のことを考えてそうしています。
というのも、PowerShell のエラーハンドリングはやや特殊な形になっていて、実行する外部プログラムがstderrに何らかのメッセージを出力すると実行に失敗したとみなし、例外を発生させるのです。そのため、本当にエラーが発生した場合はともかく、そうではないログ出力にまでstderrを使うのは避けた方が良いと考えています。
def warning(self, msg: str) -> None:
if logging.WARNING >= self.level:
if self.use_colors:
self.raw_print(f"{colors.YELLOW}WARNING: {msg}{colors.RESET}")
else:
self.raw_print(f"WARNING: {msg}")
internal void Warning(string message)
{
if (this.LogLevel <= LogLevel.Warning)
{
if (this.useColors)
{
Console.WriteLine(WARN_MSG_COLOR, message);
}
else
{
Console.WriteLine(WARN_MSG, message);
}
}
}
続く
クラスライブラリとしての Magika の移植が完了しました。実際には細かいバグ修正や各種プラットフォームでのテストなどがまだまだ残っている状態ですが、とりあえず開発環境では動いているので一段落とします。
次回はこのクラスライブラリ版 Magika を使って、コマンドラインから実行できる Magika コンソールアプリを作成していきます。