Cloud docsで紹介されているチュートリアル データ・ガバナンス・チュートリアル: 360 度ビューの構成を実際にやってみました。この記事は、Cloud docsの手順に画面イメージを追加することで、より操作感をつかみやすくすることを目的としています。
Cloud docsへのリンク:
データ・ガバナンス・チュートリアル: 360 度ビューの構成
注)当記事の画面イメージは2023年2月時点のものであり、今後変更される場合があります。
このチュートリアルでは、データ・ファブリック評価版のデータ・ガバナンスのユース・ケースを使って、お客様の360度ビューを構成し、お客様を探求します。 このチュートリアルの目的は、お客様データをクレジット・スコア・データと組み合わせて、データ全体のエンティティーを解決し、統合されたお客様の360 度ビューを作成すること、およびキャンペーンでターゲットとする最も価値の高いお客様を特定し、提供する最適な金利を決定することです。
ゴールデンバンクは住宅ローン金利の引き下げキャンペーンを実行しようとしています。データ・エンジニアは、IBM Match 360 を使用して、お客様の360度ビューのためのデータのセットアップ、マップ、およびモデル化を行う必要があります。
これは技術プレビューであり、実稼働環境での使用はまだサポートされていません。
準備1: Match 360環境を用意する
Cloud Pak for Data as a Service に登録し、データ・ガバナンスのユース・ケースに必要なサービスをプロビジョンします。
Match 360 サービスは、ダラス・リージョンでのみ使用可能です。リージョンはダラスを選択してください。
Cloud Pak for Data as a Serviceのプロビジョン
- Cloud Pak for Data as a Serviceに登録済みの場合は、ログインしてください。
- Cloud Pak for Data as a Serviceに未登録の場合は、こちらから登録します。
- 「無料評価版」をクリックします。

- リージョンに「ダラス」を選択し、利用規約に同意し、「データ使用ポリシー (Cookieの使用を含む) を読みました。」にチェックをします。IBMidをお持ちでない場合は、「IBM Cloudアカウントの作成」をクリックします。すでにIBMidをお持ちのIBMidを使う場合は、「IBMidを使用してログイン」をクリックします。

- プロビジョニングが完了すると、IBM Cloud Pak for Dataホーム画面が表示されます。
- Cloud Pak for Data ナビゲーション・メニューから、 「サービス」>「サービス・インスタンス」を選択すると、初期状態でプロビジョンされているインスタンスを確認できます。

IBM Cloud Pak for Data as a Serviceのご説明および詳細の手順については、 こちらもご参照ください。
必要なサービスのプロビジョン
以下のステップにしたがって、必要なサービスをプロビジョンします。
- Cloud Pak for Dataで、ダラス・リージョンにいることを確認します。 そうでない場合は、地域ドロップダウンをクリックし、「ダラス」を選択します。

- Cloud Pak for Data ナビゲーション・メニューから、 「サービス」>「サービス・インスタンス」を選択します。

- 「製品」 ドロップダウン・ボックスを使用して、
IBM Match 360 with Watsonサービス・インスタンスが存在するかどうかを判別します。 - IBM Match 360 サービス・インスタンスが存在しない場合は、「サービスの追加」をクリックします。
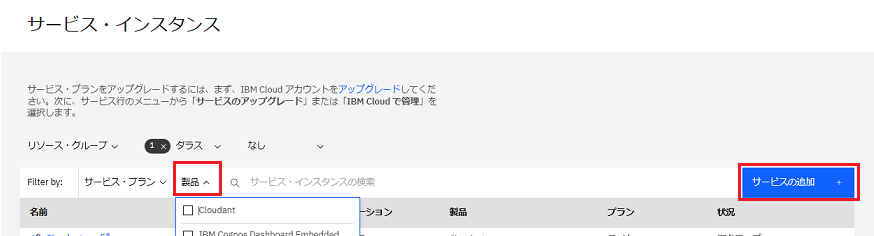
a. 「IBM Match 360 with Watson」を選択します。

b. リージョンは 「ダラス」を選択します。
c. 「ライト」プランを選択します。
d. オプション: IBM Match 360 with Watson サービス・インスタンスの名前を入力します。
e. 「作成」をクリックします。

- これらのステップを繰り返して、以下のサービスを検証またはプロビジョンします:
- Watson Knowledge Catalog
- Cloud Object Storage

準備2: サンプル・プロジェクトを作成する
このチュートリアルのサンプル・プロジェクトを作成します。
- ギャラリーのData Governance サンプル・プロジェクト にアクセスします。
Cloud Pak for Dataのナビゲーションメニューから、「Gallery」を選択し、Data Governance サンプル・プロジェクトにアクセスすることもできます。 - 「プロジェクトの作成」をクリックします。

- プロジェクトを Cloud Object Storage インスタンスに関連付けるように求められたら、リストから Cloud Object Storage インスタンスを選択します。
- 「作成」をクリックします。

- プロジェクトのインポートが完了するまで待ってから、 「新規プロジェクトの表示」 をクリックして、プロジェクトと資産が正常に作成されたことを確認します。
注: 初めてプロジェクトにアクセスする場合は、プロジェクトのツアーが必要かどうかを尋ねるガイド・ツアーが表示されます。 ここでは、「Maybe Later (後で実行)」をクリックしてください。 - 「資産」タブをクリックして、プロジェクトの資産を表示します。
注: このユース・ケースに含まれているチュートリアルを示すガイド・ツアーが表示される場合があります。ガイド・ツアーのリンクから、これらのチュートリアルの説明が開きます。

タスク 1: カタログの作成
マスター・データおよびマッチング実行後データにアクセスするには、カタログが必要です。 Watson Knowledge Catalog ライト・プランでは、2つのカタログを作成できます。
既に 2つのカタログを作成済みの場合は、既存のカタログの 1つを使用します。使用するカタログの編集者役割を持っていることを確認します。
- Cloud Pak for Data ナビゲーション・メニュー から、 「カタログ」>「すべてのカタログを表示」 を選択します。
- このチュートリアルで使用したいカタログを開きます。
- 「アクセス制御」 タブをクリックします。
- アカウントに
編集者役割があることを確認します。 役割がビューアーの場合は、管理者に連絡して編集者役割を要求してください。
カタログを新規作成する場合は、以下のステップにしたがってカタログを作成します。
-
Cloud Pak for Data ナビゲーション・メニューから、 「カタログ」>「すべてのカタログを表示」を選択します。
-
「カタログ」ページで、「新規カタログ」をクリックします。

-
「名前」には、次に表示されているとおりにカタログ名をコピー・アンド・ペーストします。先頭にも末尾にもスペースは付けません。
Data governance Catalog -
「データ保護およびデータ・ロケーション・ルールの適用」を選択し、その他のフィールドについてはデフォルトを受け入れます。「ルール適用を永続的に有効にしますか?」というプロンプトには「OK」をクリックします。

-
「作成」をクリックします。カタログが作成されると、作成された新規カタログ
Data governance Catalogが開きます。
進行状況の確認
以下のイメージは、作成されたカタログを示しています。カタログが作成されたので、マスター・データをセットアップし、データ資産を追加することができます。

タスク 2: 資産をセットアップしてマスター・データに追加する
統合するすべてのデータ資産をマスター・データに追加する必要があります。データのソースには、コンピュータのハードディスクを含むソースや、プロジェクトやカタログのデータ資産を使用することができます。
-
Cloud Pak for Data ナビゲーション・メニューから、 「データ」>「マスター・データ」を選択します。

-
マスター・データのセットアップをまだ実施していない場合は、 「マスター・データのセットアップ」 をクリックし、必要なプロジェクトとサービスをマスター・データに関連付けるための次の手順を実行します。既にセットアップ済みの場合は、「構成に移動」をクリックして、次のステップに進みます。
a. Cloud Object Storage サービス・インスタンスを選択し、 次へをクリックしてください。

b. 「Data Governance」 プロジェクトを選択し、 「次へ」をクリックします。

c. 「Data governance Catalog」という名前のカタログを選択し、「完了」をクリックします。

d. 「構成を続行」をクリックして、セットアップを完了します。

-
「データ資産から開始」をクリックしてください。

-
「データの追加」をクリックします。
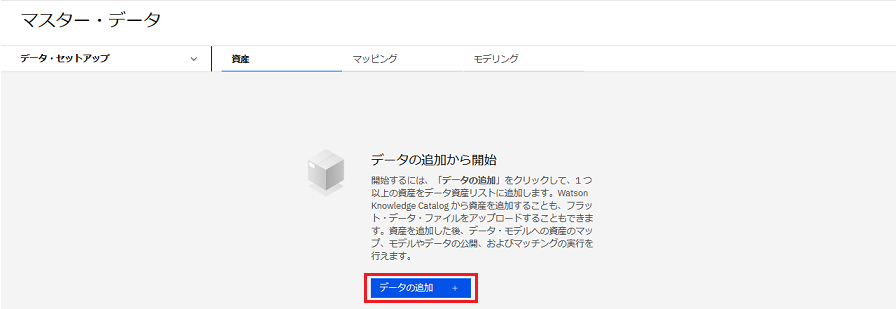
-
プロジェクト内の 3 つのデータ資産を挿入します。
a. (非表示になっている場合は)「データの検索と追加」アイコンをクリックして、 「データ・アセット」 パネルを開きます。
b. 「プロジェクト」タブを選択します。
c. プロジェクト内の各ファイルの上にカーソルを移動し、 Campaign Prospects.csv、 Customers.csv、および Experiancc.csvの 「挿入」 アイコンをクリックします。
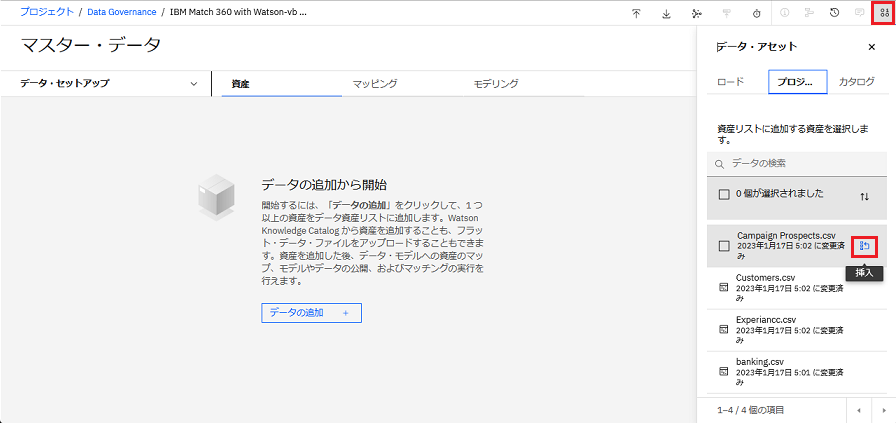
挿入した資産が「資産」タブに表示されます。

-
Personレコード・タイプをデータ資産に割り当てます。レコード タイプは、アセットが含むデータのタイプに関する情報を提供します。IBM Match 360 がデータに最も適合するモデルの部分を見つけることができるように、各資産にはレコード・タイプが割り当てられている必要があります。
a. Campaign Prospects.csv、 Customers.csv、Experiancc.csv それぞれについて、資産のチェック・ボックスを選択し、 「資産プロパティーの設定」をクリックします。

b. 資産ごとに、 「データ資産タイプの選択」 ドロップダウン・メニューをクリックし、Personデータ資産タイプを選択し、「保存」をクリックします。
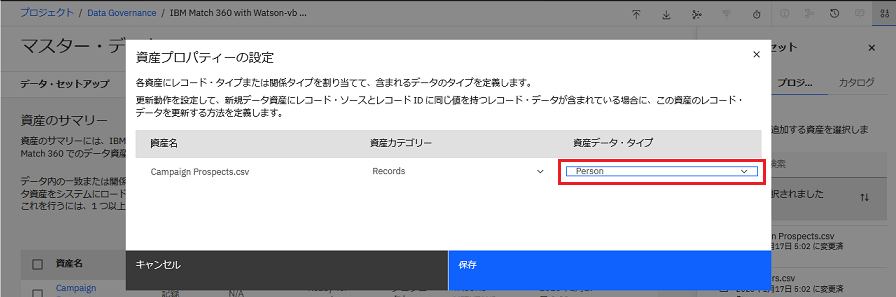
進行状況の確認
以下のイメージは、マスター・データに追加された資産を示しています。 マスター・データをセットアップして 3 つのデータ資産を追加したので、データ資産の属性のマッピングを開始する準備ができました。

タスク 3: データ資産属性のマップ
IBM Match 360 がすべてのデータのマッチングを実行するためには、各データセットのどの列を IBM Match 360 が理解する特定の属性にマッピングするかを指定する必要があります。以下の手順にしたがって、データ資産の属性をマッピングしてください。
- 「マッピング」 タブをクリックして、データ資産の列から適切な属性へのマッピングを開始します。
- 資産リスト パネルで、「Campaign Prospects.csv」を選択してください。

- データの列をIBM Match 360データ・モデルの属性に自動的にマップする
自動マップを行いたい場合は、データのプロファイルを作成する必要があります。データのプロファイルを作成するには、「プロファイル」 をクリックし、プロンプトが出されたら 「プロファイル作成の開始」をクリックします。プロファイル作成には 2 分から 5 分かかります。 データのプロファイル作成が終了すると、「プロファイル作成が完了しました (Profiling is complete)」 というメッセージが表示されます。 - プロファイル作成が完了したら、プロンプトで 「はい、自動マップします」 をクリックするか、資産のマッピング・メニューから 「自動マップ」 をクリックして、データの列を自動的にマップできます。
-
表1: Campaign Prospects.csv 推奨マッピングにしたがって、ステータスが 「マップされていない」 または正しくマップされていないすべての列を手動でマップしてください。
- 列を属性にマップするには、例 1: 既存の属性をマップするを実行します。
- 列を除外するには、例 2: マッピングから列を除外するを実行します。
- 資産内のすべての列のがマップされると「マッピング完了」のプロンプトが出るので、「次のデータ資産をマップ」をクリックします。
- 同様に、Customers.csv アセットと Experiancc.csv アセットに対して タスク 3 を繰り返します。Customers.csv 資産は、表2: Customers.csv 推奨マッピング、Experiancc.csv 資産は表3: Experiancc.csv 推奨マッピングを参照し、すべての列をIBM Match 360 データ・モデルにマップします。
例 1: 既存の属性をマップする
この例では、Campaign Prospects.csvデータ資産のソース列を既存の属性にマップする方法について説明します。IBM Match 360では、データ・セット内の列のマップ先として選択できる、一般的な属性が提供されています。
- 「legal_name.full_name」という名前の列をクリックします。
- 「マッピング・ターゲット」 パネルで、検索フィールドに「Legal name - Full name」と入力します。

- 「データ・モデルにマップして保存」をクリックして、列を属性にマップします。 列は 「マップ済み」 および 「マップ先: Legal name - Full name」として表示されます。


これらのステップを繰り返して、データ資産の他の列をIBM Match 360の提供する属性にマップできます。
例 2: マッピングから列を除外する
この例では、データ資産マッピングから列を除外する方法について説明します。ある列がマッチング・プロセス中、IBM Match 360 にとって有用でない場合、またはある列をマッチング・データ出力に含めたくない場合は、その列をマッピングから除外することができます。
- 「Source」という名前の列をクリックします。
- 「マッピングからこの列を除外」チェックボックスにチェックを入れます。

- 「データ・モデルにマップして保存」をクリックして、列を属性にマップします。この列は「除外済み」と表示されます。
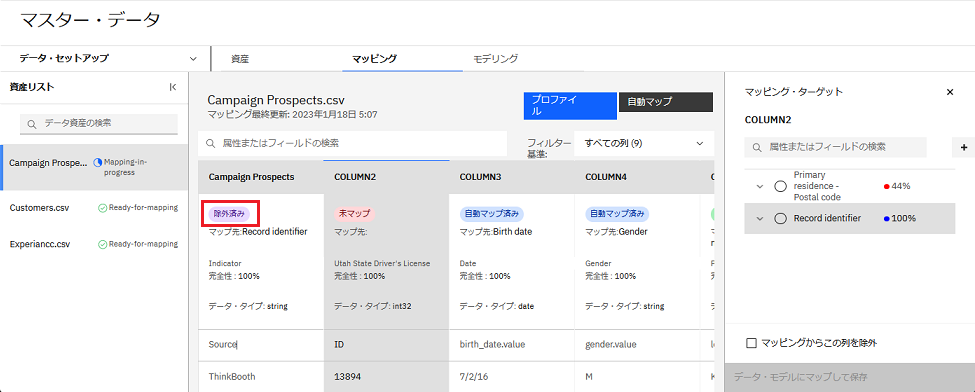
これらのステップを繰り返して、データ資産の他の列を除外することができます。
表1: Campaign Prospects.csv 推奨マッピング
| 列 | ターゲット | 方法 |
|---|---|---|
| Source | マッピングからこの列を除外 | マッピングから列を除外する |
| ID | マッピングからこの列を除外 | マッピングから列を除外する |
| birth_date.value | Birth date | 既存の属性をマップする |
| gender.value | Gender | 既存の属性をマップする |
| legal_name.full_name | Legal name - Full name | 既存の属性をマップする |
| mobile_telephone.phone_number | Home telephone - Phone number | 既存の属性をマップする |
| personal_email.email_id | Personal email - Email address | 既存の属性をマップする |
| Lead Quality | マッピングからこの列を除外 | マッピングから列を除外する |
| Product Interest | マッピングからこの列を除外 | マッピングから列を除外する |
表2: Customers.csv 推奨マッピング
| 列 | ターゲット | 方法 |
|---|---|---|
| Customer Number | マッピングからこの列を除外 | マッピングから列を除外する |
| NAME | Legal name - Full name | 既存の属性をマップする |
| COUNTRY | マッピングからこの列を除外 | マッピングから列を除外する |
| STREET_ADDRESS | Primary residence - Address line 1 | 既存の属性をマップする |
| CITY | Primary residence - City | 既存の属性をマップする |
| STATE | Primary residence - State/Province value | 既存の属性をマップする |
| ZIP_CODE | Primary residence - Postal code | 既存の属性をマップする |
| EMAIL_ADDRESS | Personal email - Email address | 既存の属性をマップする |
| PHONE_NUMBER | Home telephone - Phone number | 既存の属性をマップする |
| GENDER | Gender | 既存の属性をマップする |
| CREDITCARD_NUMBER | マッピングからこの列を除外 | マッピングから列を除外する |
表3: Experiancc.csv 推奨マッピング
| 列 | ターゲット | 方法 |
|---|---|---|
| source | マッピングからこの列を除外 | マッピングから列を除外する |
| Experian_ID | マッピングからこの列を除外 | マッピングから列を除外する |
| birth_date.value | Birth date | 既存の属性をマップする |
| gender.value | Gender | 既存の属性をマップする |
| home_telephone.phone_number | Home telephone - Phone number | 既存の属性をマップする |
| legal_name.given_name | Legal name - Given name | 既存の属性をマップする |
| legal_name.last_name | Legal name - Last name | 既存の属性をマップする |
| mobile_telephone.phone_number | Mobile telephone - Phone number | 既存の属性をマップする |
| personal_email.email_id | Personal email - Email address | 既存の属性をマップする |
| primary_residence.address_line1 | Primary residence - Address line 1 | 既存の属性をマップする |
| primary_residence.address_line2 | Primary residence - Address line 2 | 既存の属性をマップする |
| primary_residence.city | Primary residence - City | 既存の属性をマップする |
| primary_residence.province_state | マッピングからこの列を除外 | マッピングから列を除外する |
| primary_residence.zip_postal_code | Primary residence - Postal code | 既存の属性をマップする |
| Credit score | マッピングからこの列を除外 | マッピングから列を除外する |
| CREDITCARD_NUMBER | マッピングからこの列を除外 | マッピングから列を除外する |
タスク 4: データ・モデルの公開とマッチングの実行
データ・モデルは、データ資産のすべての列を属性にマップした後に作成されます。公開されたデータ・モデルは、IBM Match 360がすべてのデータ・ソースから単一のエンティティーを解決するために使用されます。以下の手順にしたがって、データ・モデルを公開してください。
- 最後のデータ・セットの最後の列をマップした後、表示されるウィンドウで 「モデルの公開」 をクリックするか、 「モデルの公開 (Publish model)」 アイコン をクリックします。 このオプションは、3 つのデータ資産のすべての列のマッピングが完了した後に表示されます。 モデルの公開には最大 1 分かかります。 データ・モデルが正常に公開されると、通知
Model publishedを受け取ります。

- 「すべてのデータを公開 (Publish all data)」 アイコンをクリックし、 「データの公開 」をクリックして、マップされたデータ資産をマッピングに基づいてIBM Match 360 データ・モデルにロードします。資産の状況が
Publishing dataからReady to matchに変わります。 データがサービスにロードされるまでに 5 分から 10 分かかります。


進行状況の確認
以下のイメージは、データ・モデルが正常に公開されたことを示す、サービスにロードされたデータ資産としてリストされているデータ資産を示しています。 次に、マッチングを実行できます。
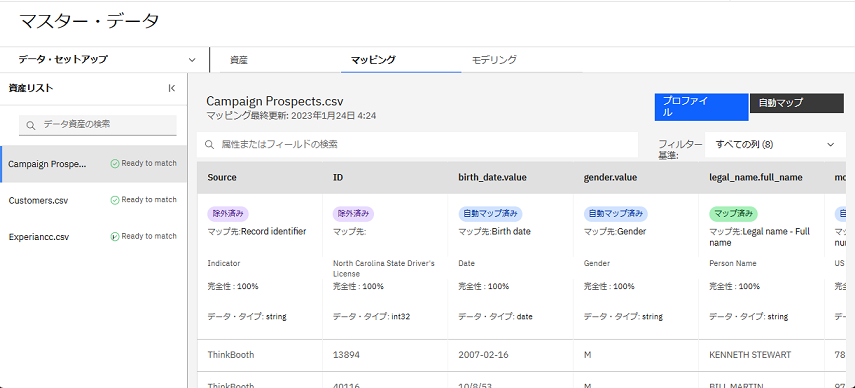
マッチング・セットアップの完了およびマッチングの実行
IBM Match 360 は、公開されたデータ・モデルを使用して、データ・ソースのすべてのレコードを単一のエンティティーに統合し、より完全なレコードを持つデータ資産を作成します。以下のステップにしたがって、マッチングを実行してください。
- 「データ・セットアップ」ドロップダウンをクリックし、メニューから「マッチング・セットアップ」を選択します。
- 「Match Settings」 タブを選択します。「属性の選択」パネルが表示されますので、「了解」をクリックします。ここでは、マッチング・アルゴリズムを支援するために、生年月日、E メール・アドレス、電話番号などのレコードを相互に区別するのに役立つ属性を選択できます。このチュートリアルでは、既に選択されているデフォルト属性を受け入れるため、何も変更しません。

- 「マッチング結果」タブを選択し、「マッチングの実行」をクリックします。 マッチング・プロセスが完了し、マッチング結果が表示されると、通知を受け取ります。

進行状況の確認
以下のイメージは、マッチングを実行した後の結果を示しています。 データ・モデルを公開してマッチングを実行したので、マッチング実行後データをカタログに公開する準備ができました。

タスク 5: マッチング実行後データをカタログに公開する
5-1. IBM Match 360 の接続資産を作成する
プロジェクト内のマッチング実行後データにアクセスするには、IBM Match 360への接続資産を作成する必要があります。IBM Match 360 接続資産は、IBM Match 360 サービスとマッチング実行後データを、接続されたデータ資産に接続します。以下の手順にしたがって、接続資産を作成してください。
-
Cloud Pak for Data ナビゲーション・メニュー ナビゲーション・メニューから、 「プロジェクト」>「すべてのプロジェクトの表示」 を選択します。
-
「Data Governance」 プロジェクトを選択します。
-
「資産」タブを選択し、「新規資産」をクリックします。

-
「データ・アクセス・ツール」 セクションで、「接続」を選択し、「IBM Match 360」接続タイプを選択します。

-
「選択」をクリックして、 IBM Match 360 サービス・インスタンスの接続を追加します。
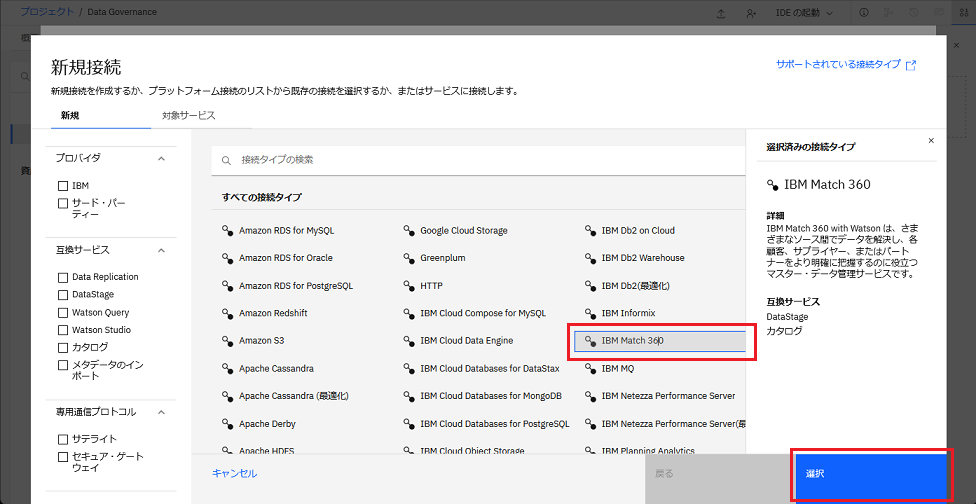
-
接続の作成パネルで、名前に「Match 360 Connection」を入力します。
-
IBM Match 360 with Watson サービス・インスタンスの CRN を取得します:
a. IBM Cloud コンソール・リソース・リスト・ページから、 「AI/機械学習」をクリックしてAI/機械学習サービス・インスタンスのリストを展開します。
b.IBM Match 360 with Watsonの製品列をクリックします。
c. 開いた詳細パネルで、選択した IBM Match 360 with Watson サービスの CRN のクリップボードにコピーアイコンをクリックします。

-
「接続の詳細」に、 IBM Match 360 with Watson サービス・インスタンスに対応する CRN を貼り付けます。
-
IBM Match 360 API キーを作成します:
a. IBM Cloud コンソールから、 「管理」> 「アクセス(IAM)」をクリックします。
b. 「API キー」ページをクリックします。
c. 「IBM Cloud API キー」が選択されていることを確認し、「作成」をクリックします。

d. 名前および説明を入力します。
e. 「作成」をクリックします。
f. API キーをコピーします 。
g. 今後使用するために API キーをダウンロードします。

-
作成した API キーを 「資格情報」 フィールドに入力します。
-
「接続のテスト」をクリックし、「テストは正常に終了しました。」となることを確認のうえ、「作成」をクリックします。

-
「ロケーションと主権を設定せずに接続を作成しますか?」の確認パネルで、「作成」をクリックします。
進行状況の確認
IBM Match 360 接続資産ができました。この接続から接続データ資産を作成できます。
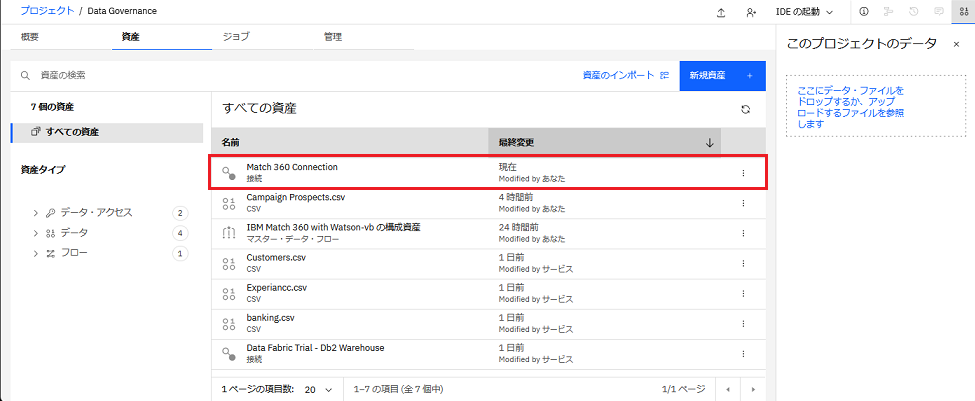
5-2. 接続済みデータ資産のインポート
次に、IBM Match 360 接続を使用して、 IBM Match 360から統合データの接続データ資産を作成します。以下の手順を実行して、接続データ資産を作成します。
- 「資産のインポート」をクリックします。

- 「資産のインポート」 ページで、 「接続データ」を選択します。

- 「Match 360 Connection」>「person」>「person_entity」を選択します。
- 「インポート」をクリックします。

進行状況の確認
以下のイメージは、接続データ資産を示しています。統合されたマッチング済みデータの接続データ資産が作成されたので、その資産をカタログに公開できます。

5-3. カタログへ接続済みデータ資産を公開する
以下のステップにしたがって、統合されたマッチング済みデータをそのカタログに公開します。
- Data Governanceプロジェクトで、「資産」 タブが表示されていることを確認します。
- 接続されたデータ資産 「person_entity」のオーバーフローメニューをクリックし、 「カタログに公開」を選択します。

- 使用するカタログをリストから選択します。
- 「公開」をクリックしてデフォルト値を使用し、接続データ資産をカタログに公開します。

- カタログ内の資産を表示するには、 Cloud Pak for Data ナビゲーション・メニュー ナビゲーション・メニューから、 「カタログ」>「すべてのカタログを表示」を選択します。
- 接続データ資産を公開したカタログ(今回は「Data governance Catalog」)をクリックします。
- カタログで、「person_entity」接続データ資産をクリックします。

- 「名前の編集」 アイコンをクリックし、接続されているデータ資産の名前「Golden Bank 360 View」を入力し「適用」をクリックします。

- 「資産」タブをクリックして、データをプレビューします。
進行状況の確認
以下のイメージは、カタログ内のデータ資産を示しています。

ゴールデンバンクのデータ・エンジニアは、 IBM Match 360 を使用して、お客様の360 度ビューのためにデータをセットアップ、マップ、およびモデル化することに成功しました。 その後、組織内の他のユーザーがアクセスできるように、マッチング実行後データの完全な360 度ビューをカタログに公開しました。
タスク 6: マッチング実行後データのプレビュー
モデルまたはデータの変更を IBM Match 360 に公開し、マッチング・パラメーターを設定してマッチングを実行したら、マスター・データ・エクスプローラーを使用してマッチング・データを照会することができます。マスター・データ・エクスプローラーを使用すると、マッチング結果を検索、表示、比較、および編集することができます。
さて、ゴールデンバンクのデータ・アナリストとして、IBM Match 360の結果を分析、調査、および検証し、マーケティング・キャンペーンでターゲットとするのに最適なお客様を特定および選択する必要があります。以下の手順にしたがって、マッチングされたデータを調査し、調整します。
- Cloud Pak for Data ナビゲーション・メニュー ナビゲーション・メニューから、 「データ」>「マスター・データ」を選択します。
- 「マスター・データの検索」をクリックします。

- 検索バーに「Branden Banks」を入力し、「Enter」キーを押して、検索条件として Branden Banksを追加します。この検索では、Branden Banks に対して 2 つのエンティティーが表示されます。最初の列の数値 1 は、このエンティティーが1つのソース・レコードで構成されていることを示し、最初の列の数値 2 は、このエンティティーが別の2つのソース・レコードで構成されていることを意味します。

- 矢印アイコンをクリックして、両方のエンティティーを展開します。Branden Banks のこれらの別個のエンティティーは 1 人の可能性が高いことがわかります。これらのエンティティーを単一のエンティティーに結合するには、マッチング・アルゴリズムを調整します。

タスク 7: マッチング・アルゴリズムのチューニングとマッチングの実行
マッチング実行後データを探索した後、より良い結果を得るために、マッチング・アルゴリズムを微調整して再度マッチングを実行することが必要になる場合があります。
- 「マスター・データ・エクスプローラー」 ドロップダウンをクリックし、メニューから 「マッチング・セットアップ」 を選択します。
- 「Match Settings」タブを選択し、「Algorithm Tuning」 を選択します。

- 「オートリンクしきい値」 をクリックして、テキスト・フィールドに「20」と入力します。しきい値を20に下げることでソース全体のレコード間の全体的なマッチングが増えます。

- 「しきい値の適用」>「次へ」>「マッチングの実行」 をクリックして、調整したアルゴリズムでマッチングを実行します。

- 「マッチング結果」タブをクリックします。 マッチングが完了すると、結果が表示されます。
進行状況の確認
以下のイメージは、マスター・データ・エクスプローラーの検索結果を示しています。 次に、マッチング実行後データを再度表示して、微調整によって結果がどのように変化したかを確認できます。

タスク 8: マッチング結果に関する洞察の取得
マスター・データ・エクスプローラーに戻って、アルゴリズムのチューニングによってマッチング結果がどのように変更されたかを確認できます。
- 「マッチング・セットアップ」 ドロップダウンをクリックし、メニューから 「マスター・データ・エクスプローラー」 を選択します。
- 検索バーに「Branden Banks」を入力し、「Enter」キーを押して、検索条件として Branden Banksを追加します。 表示されているエンティティーに関連付けられている番号 3 は、3 つのレコードがエンティティー
Branden Banksを構成していることを意味します。これらのレコードは、アルゴリズムのチューニング(オートリンクしきい値を20に変更したこと)前は複数のエンティティーに分割されていたものです。

- エンティティーの最初の列の行を展開して、レコードを表示します。 このエンティティーにマッチした 3 つのレコードがあることがわかります。
進行状況の確認
以下のイメージは、マスター・データ・エクスプローラーの検索結果を示しています。 次に、マッチング結果を視覚化することで洞察を得ることができます。

タスク 9: エンティティーのレコードの視覚化
チューニングしたマッチング結果をノードとして視覚化して、洞察を得ることもできます。
- 「グラフの表示」をクリックして、照会されたエンティティーを構成しているレコードを確認します。

- personエンティティーに接続されているいずれかのノードをクリックすると、そのエンティティーに関連付けられている詳細が表示されます。 ここから、どのレコードが照会のどのエンティティーに関連付けられているかを視覚化して手動で変更し、必要に応じて修正することができます。
進行状況の確認
以下の画像は、検索結果をグラフで示しています。

データ・アナリストは、 IBM Match 360 の結果を分析、検討、検証して、マーケティング・キャンペーン・オファーのターゲットにする最適な顧客を特定し、選択しました。
クリーンアップ (オプション)
データ・ガバナンスのユース・ケースのチュートリアルを再実行する場合は、以下の成果物を削除します。
| 成果物 | 削除方法 |
|---|---|
| データ・ガバナンス・カタログ | カタログの削除 |
| データ・ガバナンス・サンプル・プロジェクト | プロジェクトの削除 |