Excelの限界
弊社の某プロダクトでは個々の契約の利用料金は自動的に算出しているのですが、
それ以上の粒度、例えば四半期や通期の売上総額や、各メニュー毎の売上等の集計には(多くの企業でそうであるように)Excelが用いられています。
Excelは誰でも直感的な操作が可能な素晴らしいものですが、その反面いろいろな制約があります。
- 扱えるデータが小さい
- データの再利用性が低い
10万行くらいで操作性的にかなりしんどく、100万行を超えると物理的に扱うことができません。また、データの参照と加工が一体化しており直感的な反面、長期的な再利用が難しく、長期間にわたる集計を行うのは重労働になりがちです。いきおい長期的なデータを様々な角度から自由に分析する、というのはなかなか難しくなります。
今回は、私が担当している某プロダクトの売上等のデータを長期的に集積し、統計処理や可視化を行うための基盤を試作してみました。
(なお、この記事に出てくる数字やグラフの値は全部ダミーデータです!)
目的
今回の目的はこの2点です。
- 某プロダクトの短期的/長期的な売上情報を分析しやすい状態にすること
- 様々なロールの社内関係者から分析結果を参照しやすい状態で提供すること。
- 他方で、閲覧権限の無い人には見えないようにすること
集計のリアルタイム性とかは気にしない方向。
構成

最近社内でGCPを使えるようになったので、基盤にはBigqueryを使います。
BigqueryはGCPの目玉機能の一つで、莫大なデータを投げ込んでも
速度をほとんど落とさずにクエリ結果を返してくれるというものです。
何百万行もあるデータでも2, 3秒でselect結果が返ってきます。
ホワイトペーパーでは350億行のフルスキャンを数十秒(!)で完了する、と報告されています。
(今回扱うデータは多く見積もってもN千万行のオーダーなので若干オーバースペックな感じもありますが... 物は試し、です。)
Cloud Storageに処理済みのCSVを投げ込むと、Cloud Functionでイベントを受け取って自動的にBigQueryに格納するようにしました。
可視化は迷ったのですがとりあえずG SuiteのColaboratoryを使っています。
Colaboratoryは平たく言えばGoogleが改造したJupyter Notebookで、Pythonでデータの加工や可視化をインタラクティブに行える優れものです。
(Chrome Extensionとしても配布されているようなので、ぜひ触って見てください。)
Jupyterのサーバを立てたり、同じJupyter派生のGCP DataLabを使うという選択肢もあったのですが、G Suiteの認証情報でアクセス権を管理できるのでシンプルにできそう、という理由でColaboratoryを選びました。
今後、エンタープライズ向けのBIツール等が導入されたら置き換えても良いと思います。
各処理の詳細
非正規化
元データは、顧客への請求に用いられる階層状の明細データです。

これはAWSの明細書ですが、こんな感じのでもう少し階層の深いデータを想像していただければ。これをBigQueryへの格納に適した形に加工します。
普通の業務用DBを相手にしていると「エンティティ毎にテーブルを分割して、正規化して..」と考えがちですし、一般的なDWHでもスタースキーマなどディメンジョンテーブルは最低限用意することが多いのですが、BigQueryでは処理の並列化と相性のよい"非"正規化されたデータの投入が推奨されているようです。
今回は階層状のXMLをElement毎に分解し、各行に重複を厭わず属性情報をつけていくことにしました。
匿名化
この種の統計処理には顧客やリソースを特定するための各種のIDは全く必要ないため、セキュリティの観点からも全て削ぎ落とし、値や品目、販売種別など分析に必要なデータのみを残します。
テーブルの分割
Bigqueryは莫大なデータを溜め込んでも保存は安いのですが、クエリでスキャンした容量に応じて課金されるという(ちょっと怖い)課金体系になっています。
where句やlimit句をつけても、指定したカラムのデータは全てスキャンされてしまうため、対策としてテーブルの(特に日単位時系列での)分割が推奨されています。
今回のデータは月毎のデータなので、各月の1日の日付をつけたテーブルを月ごとに作っていくことにします。
可視化
データの投入が終わったらデータの可視化です。
Colaboratoryの中で、bigqueryから必要な範囲のテーブル/カラムを読み出して、
pandasに格納して諸々の集計処理を行います。
(多量の処理であれば、bigquery側で集計させても良いと思います)
集計結果はこんな感じの画面になります。
 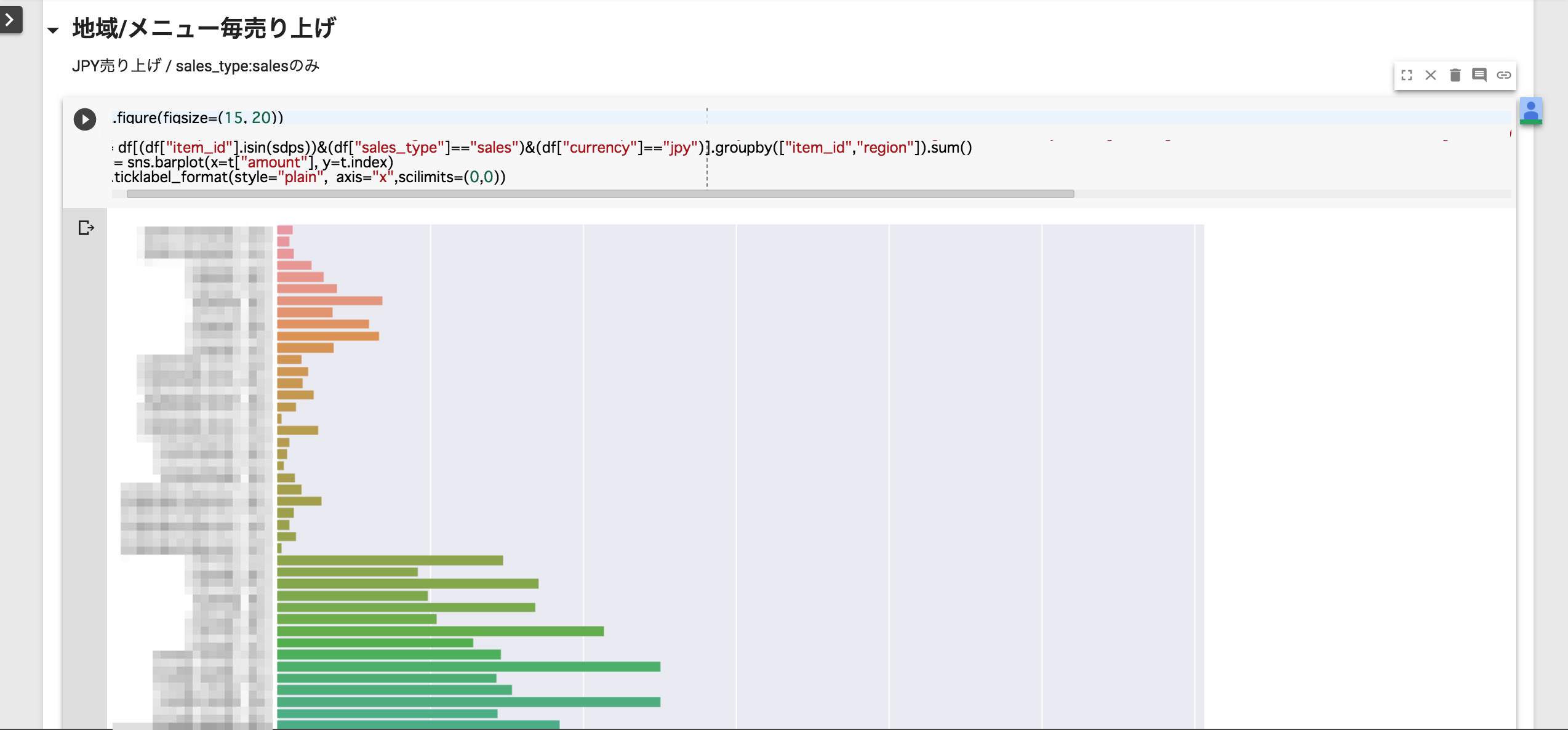

(※データや分布は全てダミーデータです。)
グラフ描画は何でも良いのですが、自分の使い慣れているseabornを使っています。
これで、各種データを自由に切ったり貼ったり統計取ったり推定したりできる環境が整いました。
Colaboratoryのノート(とBigqueryへの)アクセス権をG Suiteで管理すれば、閲覧できる人を任意に制御できます。
今後について
一通りデータ分析を実行できる環境が整ったので、周囲の人から使いやすくしていきたい。
- Colaboratoryでコードは非表示にできるオプションができると嬉しい
- 定点観測的な統計値の観測は自分が解析コードを書いて閲覧権限で配布すれば行けそうだけど、
コード書かないメンバがアドホックな解析をしたいときにデータを部分的に取得する方法を整備する